论文链接
动机
在很多困难场景下, 如大姿态, 基于深度学习的人脸识别性能会下降很多. 但我们观察到,在这些困难场景下, 如大姿态, 人脸的属性信息(facial attribute)如性别, 人种, 发色, 眉毛形状等是保持不变的. 很自然地,深度人脸识别的特征(FRF)和属性识别的特征(FAF)具备互补性. 融合这两种特征可以提高人脸识别率. 我们尝试了现有的融合策略,表现令人难以满意. 我们提出一种基于张量(tensor)的特征融合方式来融合FRF和FAF.

尽管每个维度的相似性得分各不相同,但是总的得分FRF、FAF保持相似,融合后更加相似。
贡献
- 这是第一项系统地调查和验证面部属性是各种重要线索的工作人脸识别方案。特别是,我们研究了极端姿势变化的人脸识别,即±90°;
- 提出一种基于张量的融合框架,使用TUCKER张量分解的方式降低待优化的tensor的维度;
- 实验结果表明融合功能比单个功能更好,从而证明面部属性第一次有助于面部识别。
测试的数据库:MultiPIE(交叉姿势,照明和表达)、CASIA NIR-VIS2.0(跨模态环境)和LFW(不受控制的环境)。
方法
两个特征用tensor连接可以用于特征融合,融合的效果取决于tensor参数优化的效果,但tensor的维度很高, 难以优化, 我们使用TUCKER张量分解的方式降低待优化的tensor的维度,即使这样优化仍然面临着求导及正则化设计的困难。我们发现这个tensor优化问题可以与一个two-stream gated的神经网络进行等价。发现这个等价后, 我们可以:
- 使用现有深度学习的优化工具进行优化, 如tensorflow, 而不需要手动设计复杂的tensor的优化。由于在tensorflow优化时可以用mini-batch, 这样我们的优化天然就是scalable的 ;
- 融合部分可以与特征学习的神经网络进行端到端的学习,这篇论文提供的一个insight是,将tensor和深度学习进行等价。 这样tensor领域的知识可以用来理解神经网络, 反之亦然。
相关工作
人脸表示的两种类型:手工特征和深度学习特征。
手工特征有LBP和Gabor滤波器等,对于不同的身份表现不同,对于个人内部变化的表示相对不变,但是手工特征在不受控的环境中表现不好。
一种方法是使用相当高维的特征(对特征进行密集采样),另一种方法是使用更好的度量学习方法(各种score函数)去增强特征表达。
1)使用面部属性的人脸识别
定义65个面部属性并提出二元属性分类器SVM预测他们的存在与否
训练数据使用精心设计的面部patch
融合以上输出的分类器分数(即属性向量)可用于人脸识别
2)特征融合方法
简单的融合方法可以分为特征级(早期融合)和分数级(后期融合)。分数级融合是融合相似性基于每个属性的计算得分,通过简单平均或堆叠另一个分类器。
子空间学习方法。首先连接特征,然后将连接的特征映射到子空间。
- 有监督。Linear Discriminant Analysis (LDA) 和 Locality Preserving Projections (LPP)
- 无监督。Canonical Correlational Analysis(CCA)和 Bilinear Models(BLM)
融合属性和识别功能(方法细节)
1)单一特征
我们从标准的多分类问题开始,假设我们有M个样本、C个身份类别,分别提取D维 FRF 特征 x(i)
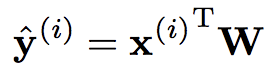 Eq.(1)
Eq.(1)
2)多重特征
假设我们除了D维FRF特征还有B维FAR特征 z(i)
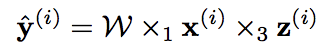 Eq.(2)
Eq.(2)
×表示点乘,下标标识W在哪个轴上运算,W的size是D × C × B。
3)优化
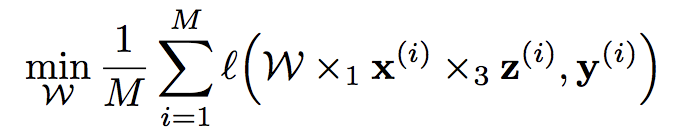 Eq.(3)
Eq.(3)
Tucker 分解:为了减少参数数量,我们设定了一个约束S。
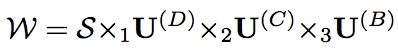 Eq.(4)
Eq.(4)
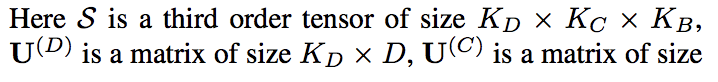
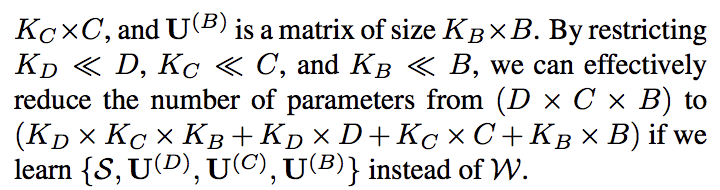
建模的灵活性在于我们有三个与轴对应的超参数KD、KC、KB。
灵感来自一个出名的分解CP对张量的所有轴都有一个超参数K

解释:
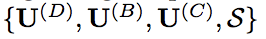 是要学的参数,
是要学的参数,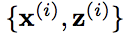 是特征,经过Eq.(7)的变换,得到fused feature是KC维。
是特征,经过Eq.(7)的变换,得到fused feature是KC维。
Kronecker product 克罗内克积 :参考博客
如果A是一个 m × n 的矩阵,而B是一个 p × q 的矩阵,克罗内克积A /otimes B则是一个 mp × nq 的分块矩阵
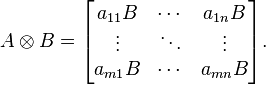
满足乘法交换律和结合律,并且置换等价,即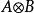 =
=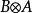
4)门控双流神经网络(GTNN)

5)网络结构
- LeanFace:用于face recognition

加Pooling和FC一共23层;
使用多任务损失:softmax loss和center loss联合训练;
激活函数是:maxout

假设网络第i层有2个神经元x1、x2,第i+1层的神经元个数为1个.原本只有一层参数,将ReLU或sigmoid等激活函数替换掉,引入Maxout,将变成两层参数,参数个数增为k倍。
优点:
-
Maxout的拟合能力非常强,几乎可以拟合任意的凸函数。
-
Maxout具有ReLU的所有优点,线性、不饱和性。
-
同时没有ReLU的一些缺点。如:神经元的死亡。
-
AttNet:用于属性检测
激活函数用的是Maxout
损失用的是 hingeloss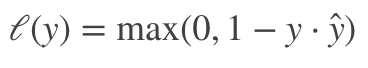
在[24]中,定义了40个面部属性的本体。 我们删除不是普遍存在的属性,例如’戴眼镜’和’微笑’,总共留下17个属性。
一旦训练了每个网络,从LeanFace(256D)和AttNet(256D)层提取的特征被提取为x和z,并输入到GTNN用于融合然后进行人脸识别

6)讨论
- 非线性:跟之前讨论过的基于平均、连接、子空间等方法不同的是,我们的方法是非线性的,对于复杂建模很有用;
- 高阶:考虑到了每对特征之间的所有交互;
实验
1)Multi-PIE数据集,包含4个不同会议、337个人的 750,000张不同图像,姿势,光照和表情变化丰富。在MPIE库上, 其中对大姿态(偏转超过45°)的提高最显著。


2)在近红外-可见光库(CASIA NIR-VIS 2.0)上取得了目前最高的99.94%的识别率.NIR(近红外图片)和VIS(可见光图片)来自不同的domain,通常大家认为应该使用domain adaptatino技术来NIR-VIS识别. 但我们的训练集全部来自VIS, 这说明只要训练集足够大(我们用了7M可见光图片),domain shift可以自然被解决, 因为大的VIS训练集能抓住足够多的细节, 这些细节NIR和VIS是共享的.
解释 领域自适应domain adaptatino:
迁移学习中的一种代表性方法,指的是利用信息丰富的源域样本来提升目标域模型的性能。
领域自适应问题中两个至关重要的概念:源域(source domain)表示与测试样本不同的领域,但是有丰富的监督信息;目标域(target domain)表示测试样本所在的领域,无标签或者只有少量标签。源域和目标域往往属于同一类任务,但是分布不同。
研究者提出了三种不同的领域自适应方法:1)样本自适应,对源域样本进行加权重采样,从而逼近目标域的分布。2)特征层面自适应,将源域和目标域投影到公共特征子空间。3)模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。

3)在LFW上我们取得了99.65%的识别率, 超过了google的facenet (99.63%)
