вЛАуЖјбдЃЌMySQL ЕФЕїгХПЩвдЗжЮЊСНИіВуУцЃЌвЛИіЪЧдкMySQLВуУцЩЯНјааЕФЕїгХЃЌБШШчSQLИФаДЃЌЫїв§ЕФЬэМгЃЌMySQLИїжжВЮЪ§ЕФХфжУЃЛСэвЛИіВуУцЪЧДгВйзїЯЕЭГЕФВуУцКЭгВМўЕФВуУцРДНјааЕїгХЁЃВйзїЯЕЭГЕФВуУцЕФЕїгХЃЌвЛАувЊЯШЖЈЮЛЕНЪЧФЧжжзЪдДГіЯжЦПОБ——CPUЁЂ ФкДцЁЂгВХЬЁЂЭјТчЃЌШЛКѓШыЪжЕїгХЁЃЫљвдЦфЪЕMySQL ЕФЕїгХЃЌЦфЪЕВЛЪЧФЧУДМђЕЅЃЌЫќвЊЧѓЮвУЧЖд гВМўЁЂOSЁЂMySQL Ш§епЖМОпгаБШНЯЩюШыЕФРэНтЁЃБШШч NUMA МмЙЙЕФCPUЪЧШчКЮЗжХфCPUЕФЃЌвдМАЪЧШчКЮЗжХфФкДцЕФЃЌШчКЮБмУтЕМжТSWAPЕФЗЂЩњЃЛLinux ЯЕЭГЕФIOЕїЖШЫуЗЈбЁдёФФвЛжж——CFQЁЂDEADLINEЁЂNOOPЁЂЛЙЪЧ ANTICIPATORYЃЛMySQLЕФredo logКЭundo logЫќУЧЕФаДФФИіЪЧЫГађаДЃЌФФИіЪЧЫцЛњаДЃП
ЫљвдЦфЪЕЃЌШчЙћЯывЊЖд MySQL НјааЕїгХЃЌвЊЧѓЮвУЧБиаыЖд гВМўКЭOSЃЌвдМАMySQLЕФФкВПЪЕЯждРэЃЌЖМвЊгаКмКУЕФеЦЮеЁЃБОЮФЙигкMySQLЕїгХЛљДЁжЎ CPUКЭНјГЬЁЃ
1. CPU МмЙЙжЎ NUMAКЭSMP
SMPЃКГЦЮЊЙВЯэФкДцЗУЮЪCPU(Shared Memory Mulpti Processors), вВГЦЮЊЖдГЦаЭCPUМмЙЙЃЈSymmetry Multi Processors)
NUMAЃКЗЧЭГвЛФкДцЗУЮЪ (Non Uniform Memory AccessЃЉ
ЫќУЧзюживЊЕФЧјБ№дкгкФкДцЪЧЗёАѓЖЈдкИїИіЮяРэCPUЩЯЃЌвдМАCPUШчКЮЗУЮЪФкДцЃК
SMPМмЙЙЕФCPUФкВПУЛгаАѓЖЈФкДцЃЌЫљгаЕФCPUељгУвЛИізмЯпРДЗУЮЪЫљгаЙВЯэЕФФкДцЃЌгХЕуЪЧзЪдДЙВЯэЃЌЖјШБЕуЪЧзмЯпељгУМЄСвЁЃЫцзХPCЗўЮё ЦїЩЯЕФCPUЪ§СПБфЖрЃЈВЛНіНіЪЧCPUКЫЪ§ЃЉЃЌзмЯпељгУЕФБзЖЫТ§Т§дНРДдНУїЯдЃЌгкЪЧIntelдкNehalem CPUЩЯЭЦГіСЫNUMAМмЙЙЃЌЖјAMDвВЭЦГіСЫЛљгкЯрЭЌМмЙЙЕФOpteron CPUЁЃ
NUMA зюДѓЕФЬиЕуЪЧв§ШыСЫnodeКЭdistanceЕФИХФюЃЌnodeФкВПгаЖрИіCPUЃЌвдМААѓЖЈЕФФкДцЁЃУПИіnodeЕФCPUКЭФкДцвЛАуЪЧЯрЕШЁЃdistanceетИіИХФюЪЧгУРДЖЈвхИїИіnodeжЎМфЕїгУзЪдДЕФПЊЯњЁЃNUMAМмЙЙжаФкДцКЭCPUЕФЙиЯЕШчЯТЭМЫљЪОЃК
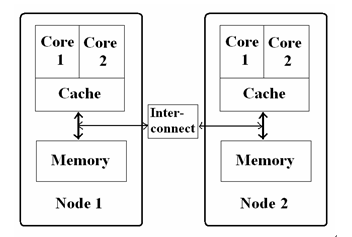
(nodeФкВПгаЖрИіCPUЃЌnodeФкВПгаФкДцЃЛУПСНИіnodeжЎМфга inter-connect)
NUMAМмЙЙЕФЬсГіЪЧЮЊСЫЪЪгІЖрCPUЃЌПЩвдПДЕНnodeФкВПЕФCPUЖдФкДцЕФЗУЮЪЗжГЩСЫСНжжЧщПіЃК
1ЃЉЖдnodeФкВПЕФФкДцЕФЗУЮЪЃЌвЛАуГЦЮЊ local accessЃЌЯдШЛЗУЮЪЫйЖШЪЧзюПьЕФЃЛ
2ЃЉЖдЦфЫќnodeжаЕФФкДцЕФЗУЮЪЃЌвЛАуГЦЮЊ remote accessЃЌвђЮЊвЊЭЈЙ§ inter-connectЃЌЫљвдЗУЮЪЫйЖШЛсТ§вЛаЉЃЛ
вђЮЊCPUКЭФкДцЪЧАѓЖЈЖјаЮГЩвЛИіnodeЃЌФЧУДОЭЩцМАЕНCPUШчКЮЗжХфЃЌФкДцШчКЮЗжХфЕФЮЪЬтЃК
1ЃЉNUMAЕФCPUЗжХфВпТдгаcpunodebindЁЂphyscpubindЁЃcpunodebindЙцЖЈНјГЬдЫаадкФГМИИіnodeжЎЩЯЃЌЖјphyscpubindПЩвдИќМгОЋЯИЕиЙцЖЈдЫаадкФФаЉКЫЩЯЁЃ
2ЃЉNUMAЕФФкДцЗжХфВпТдгаlocalallocЁЂpreferredЁЂmembindЁЂinterleaveЁЃlocalallocЙцЖЈНјГЬДгЕБЧАnodeЩЯЧыЧѓЗжХфФкДцЃЛЖјpreferredБШНЯПэЫЩЕижИЖЈСЫвЛИіЭЦМіЕФnodeРДЛёШЁФкДцЃЌШчЙћБЛЭЦМіЕФnodeЩЯУЛгазуЙЛФкДцЃЌНјГЬПЩвдГЂЪдБ№ЕФnodeЁЃmembindПЩвджИЖЈШєИЩИіnodeЃЌНјГЬжЛФмДгетаЉжИЖЈЕФnodeЩЯЧыЧѓЗжХфФкДцЁЃinterleaveЙцЖЈНјГЬДгЫљгаnodeЩЯвдRRЫуЗЈНЛжЏЕиЧыЧѓЗжХфФкДцЃЌДяЕНЫцЛњОљдШЕФДгИїИіnodeжаЗжХфФкДцЕФФПЕФЁЃ
NUMA МмЙЙЕМжТЕФЮЪЬт——SWAP
вђЮЊNUMAМмЙЙЕФCPUЃЌФЌШЯВЩгУЕФЪЧlocalallocЕФФкДцЗжХфВпТдЃЌдЫаадкБОnodeФкВПCPUЩЯЕФНјГЬЃЌЛсДгБОnodeФкВПЕФФкДцЩЯЗжХфФкДцЃЌШчЙћФкДцВЛзуЃЌдђЛсЕМжТswapЕФВњЩњЃЌбЯжигАЯьадФмЃЁЫќВЛЛсЯђЦфЫќnodeЩъЧыФкДцЁЃетЪЧЫћзюДѓЕФЮЪЬтЁЃ
ЫљвдЮЊСЫБмУтSWAPЕФВњЩњЃЌвЛЖЈвЊНЋNUMAМмЙЙCPUЕФФкДцЗжХфВпТдЩшжУЮЊЃКinterleave; етбљЩшжУЕФЛАЃЌШЮКЮНјГЬЕФФкДцЗжХфЃЌЖМЛсЫцЛњЯђИїИіnodeЩъЧыЃЌЫфШЛremote accessЛсЕМжТвЛЕуЕуЕФадФмЫ№ЪЇЃЌЕЋЪЧЫћЖХОјСЫSWAPЕМжТЕФбЯжиЕФадФмЫ№ЪЇЁЃЫљвд interleave ЦфЪЕЪЧНЋNUMAМмЙЙЕФИїИіnodeжаЕФФкДцЃЌгжжиаТащФтГЩСЫвЛИіЙВЯэЕФФкДцЃЌЕЋЪЧКЭSMPВЛЭЌЕФЪЧЃЌвђЮЊУПСНИіnodeжЎМфга inter-connect ЃЌЫљвдгжБмУтСЫSMPМмЙЙзмЯпељгУЕФШБЯнЁЃ
2. CPU КЭ Linux НјГЬ
НјГЬгІИУЪЧLinuxжазюживЊЕФвЛИіИХФюЁЃНјГЬдЫаадкCPUЩЯЃЌЪЧЫљгагВМўзЪдДЗжХфЕФЖдЯѓЁЃLinuxжагУвЛИіtask_structЕФНсЙЙРДУшЪіНјГЬЃЌУшЪіСЫНјГЬЕФИїжжаХЯЂЁЂЪєадЁЂзЪдДЁЃ
LinuxжаНјГЬЕФЩњУќжмЦкКЭЫќУЧЩцМАЕФЕїгУЃК
1ЃЉИИНјГЬЕїгУfork() ВњЩњвЛИіаТЕФздНјГЬЃЛ
2ЃЉзгНјГЬЕїгУexec() жИЖЈздМКвЊжДааЕФДњТыЃЛ
3ЃЉзгНјГЬЕїгУexit() ЭЫГіЃЌНјШыzombieзДЬЌЃЛ
4ЃЉИИНјГЬЕїгУwait()ЃЌЕШД§згНјГЬЕФЗЕЛиЃЌЛиЪеЦфЫљгазЪдДЃЛ
Thread:
ЪЧвЛИіжДааЕЅдЊЃЌЭЌвЛНјГЬжаЫљгаЯпГЬЃЌЙВЯэНјГЬЕФзЪдДЁЃЯпГЬвЛАуГЦЮЊ LWP(Light Weight Process)ЧсСПМЖНјГЬЁЃЫљвдЦкЯоЯпГЬУЛгаФЧУДЩёУиЃЌЮвУЧПЩвдНЋЦфЕБзіЬиЪтЕФНјГЬРДПДД§ЁЃ
НјГЬЕФгХЯШМЖКЭniceЃК
НјГЬЕФЕїЖШЃЌЩцМАЕННјГЬЕФгХЯШМЖЁЃгХЯШМЖЪЙгУnice levelРДБэЪОЃЌЦфжЕЗЖЮЇЃК19 ~ -20ЁЃжЕдНаЁЃЌгХЯШМЖдНДѓЃЌФЌШЯЮЊ0.
вЛАуШчЙћЮвУЧЯыНЕЕЭФГИіЯпГЬБЛЕїЖШЕФЦЕТЪЃЌОЭПЩвдЕїИпЫќЕФniceжЕ(дНniceЃЌОЭдНВЛЛсШЅељгУCPU)ЁЃ
НјГЬЕФ context switch:
НјГЬЩЯЯТЮФЧаЛЛЃЌЪЧвЛИіМЋЮЊживЊЕФИХФюЃЌвђЮЊЫћЖдадФмгАЯьМЋДѓЁЃНјГЬЕФЕїЖШЃЌМЖЩцМАЕННјГЬЩЯЯТЮФЕФЧаЛЛЁЃЩЯЯТЮФЧаЛЛЃЌЪЧжИНЋНјГЬЕФЫљгаЕФаХЯЂЃЌДгCPUЕФregisterжаflushЕНФкДцжаЃЌШЛКѓЛЛЩЯЦфЫќНјГЬЕФЩЯЯТЮФЁЃЦЕЗБЕФЩЯЯТЮФЧаЛЛЃЌНЋМЋДѓЕФгАЯьадФмЁЃ
CPUжаЖЯДІРэЃК
CPUЕФжаЖЯДІРэЪЧгХЯШМЖзюИпЕФШЮЮёжЎвЛЁЃжаЖЯЗжЮЊЃКhard interrupte КЭ soft interrupt.
вђЮЊжаЖЯЗЂЩњЃЌОЭЛсШЅдЫаажаЖЯДІРэГЬађЃЌвВОЭЕМжТСЫcontext switchЃЌЫљвдЙ§ЖрЕФжаЖЯвВЛсЕМжТадФмЕФЯТНЕЁЃ
НјГЬЕФИїжжзДЬЌ state:
НјГЬЕФИїжжзДЬЌЃЌвЛЖЈвЊИуЧхГўЫћУЧЕФКЌвхЃЌВЛШЛКѓУцНјГЬЕФ load average(topУќСюКЭuptimeУќСю)ЕШИїжжаХЯЂЛсПДВЛЖЎЁЃ
1ЃЉTASK_RUNNING: In this state, a process is running on a CPU or waiting to run in the queue (run queue).
2ЃЉTASK_STOPPED: A process suspended by certain signals (for example SIGINT, SIGSTOP) is in this state. The process is waiting to be
resumed by a signal such as SIGCONT.
3ЃЉTASK_INTERRUPTIBLE: In this state, the process is suspended and waits for a certain condition to be satisfied. If a process is in
TASK_INTERRUPTIBLE state and it receives a signal to stop, the process state is changed and operation will be interrupted. A typical
example of a TASK_INTERRUPTIBLE process is a process waiting for keyboard interrupt.
4ЃЉTASK_UNINTERRUPTIBLE: Similar to TASK_INTERRUPTIBLE. While a process in TASK_INTERRUPTIBLE state can be interrupted,
sending a signal does nothing to the process in TASK_UNINTERRUPTIBLE state. A typical example of a TASK_UNINTERRUPTIBLE
process is a process waiting for disk I/O operation.
5ЃЉTASK_ZOMBIE: After a process exits with exit() system call, its parent should know of the termination. In TASK_ZOMBIE state, a
process is waiting for its parent to be notified to release all the data structure.
Г§СЫ TASK_RUNNING жаЕФНјГЬПЩФмдкдЫаажЎЭтЃЌЦфЫќзДЬЌЕФНјГЬЖМУЛгадкдЫааЁЃЕЋЪЧЦфЪЕ TASK_UNINTERRUPTIBLE БШНЯЬиЪтЃЌЫќЦфЪЕПЩвдПДзіЪЧдкдЫааЕФЃЌвђЮЊЫћЪЧдкЕШД§ДХХЬВйзїЭъГЩЃЌЫљвдЦфЪЕДгЯЕЭГЕФНЧЖШЃЌЖјВЛЪЧДгНјГЬЕФНЧЖШЖјбдЃЌЦфЪЕЯЕЭГЪЧдкЮЊНјГЬдЫааЕФЁЃетвВОЭЪЧЮЊЪВУД load average жаЕФЪ§жЕЃЌЪЧАќРЈСЫ TASK_RUNNING КЭ TASK_UNINTERRUPTIBLE СНжжзДЬЌЕФНјГЬЕФЦНОљжЕЁЃ
НјГЬШчКЮЪЙгУФкДцЃК
НјГЬЕФдЫааЃЌБиаыЩъЧыКЭЪЙгУФкДцЃЌзюживЊЕФАќРЈЖбКЭеЛЃК
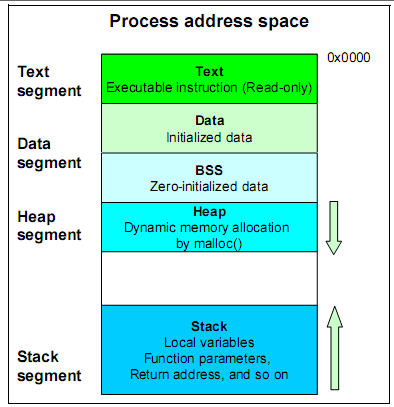
НјГЬЪЙгУЕФФкДцЃЌПЩвдгУ pmap, ps ЕШД§УќСюааРДВщПДЁЃдкКѓУцЛсгаеОУДЕФФкДцЕїгХЮФеТНщЩмЁЃ
CPU ЕїЖШЃК
ЧАУцНщЩмСЫCPUЕФЕїЖШЩцМАЕННјГЬЕФгХЯШМЖКЭnice level. LinuxжаНјГЬЕФЕїЖШЫуЗЈЪЧ O(1)ЕФЃЌЫљвдНјГЬЪ§СПЕФЖрЩйВЛЛсгАЯьНјГЬЕїЖШЕФаЇТЪЁЃ
НјГЬЕФЕїЖШЩцМАЕНСНИігХЯШМЖЪ§зщ(гХЯШМЖЖгСа)ЃКactive, expired ЁЃCPUАДеегХЯШМЖЕїЖШ active ЖгСажаЕФНјГЬЃЌЖгСажаЫљгаНјГЬЕїЖШЭъГЩжЎКѓЃЌНЛЛЛactiveЖгСаКЭexpiredЖгСаЃЌМЬајЕїЖШЁЃ
NUMAМмЙЙЕФCPUдкЕїЖШЪБЃЌвЛАуВЛЛсПхnodeНкЕуНјааЕїЖШЃЌГ§ЗЧвЛИіnodeНкЕуCPUГЌдиСЫВЂЧвЧыЧѓНјааИКдиОљКтЁЃвђЮЊПхnodeНкЕуCPUЕїЖШгАЯьадФмЁЃ
3. Linux ШчКЮЖШСП CPU
1ЃЉCPU utilizationЃКзюжБЙлзюживЊЕФОЭЪЧCPUЕФЪЙгУТЪЁЃШчЙћГЄЦкГЌЙ§80%ЃЌдђБэУїCPUгіЕНСЫЦПОБЃЛ
2ЃЉUser time: гУЛЇНјГЬЪЙгУЕФCPUЃЛИУЪ§жЕдНИпдНКУЃЌБэУїдНЖрЕФCPUгУдкСЫгУЛЇЪЕМЪЕФЙЄзїЩЯ
3ЃЉSystem time: ФкКЫЪЙгУЕФCPUЃЌАќРЈСЫгВжаЖЯЁЂШэжаЖЯЪЙгУЕФCPUЃЛИУЪ§жЕдНЕЭдНКУЃЌЬЋИпБэУїдкЭјТчКЭЧ§ЖЏВугіЕНЦПОБЃЛ
4ЃЉWaiting: CPUЛЈдкЕШД§IOВйзїЩЯЕФЪБМфЃЛИУЪ§жЕКмИпЃЌБэУїIOзгЯЕЭГгіЕНЦПОБЃЛ
5ЃЉIdel time: CPUПеЯаЕФЪБМфЃЛ
6ЃЉLoad average: the average of the sum of TASK_RUNNING and TASK_UNINTERRUPTIBLE processes. If processes that request CPU time are blocked (which means that the CPU has no time to process them), the load average will increase. On the other hand, if each
process gets immediate access to CPU time and there are no CPU cycles lost, the load will decrease.
7ЃЉContext Switch: ЩЯЯТЮФЧаЛЛЃЛ
ШчКЮМьВтCPUЃК
МьВтCPUЪЙгУЧщПізюКУЕФЙЄОпЪЧ top УќСюЃК
3.1 top УќСю ВщПДCPU аХЯЂ
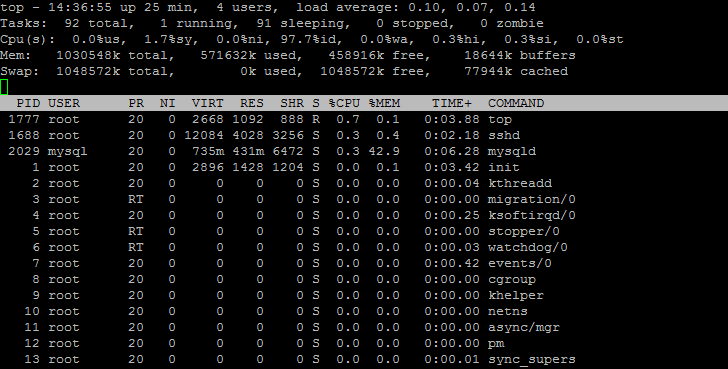
вЊЕїгХЃЌФЧУДОЭБиаыЖСЖЎ КмЖр УќСюааЙЄОпЕФЪфГіЁЃЩЯУцЕФtopУќСюАќРЈСЫКмЖрЕФаХЯЂЃК
ЕквЛааЃК
top - 14:35:55 up 25 min, 4 users, load average: 0.10, 0.07, 0.14
ЗжБ№БэЪОЕФЪЧЃКЕБЧАЯЕЭГЪБМфЃЛup 25 minБэЪОвбОЯЕЭГвбОдЫаа25ЗжжгЃЛ 4 usersЃКБэЪОЯЕЭГжага4ИіЕЧТМгУЛЇЃЛ
load average: ЗжБ№БэЪОзюНќ 1 ЗжжгЃЌ 5 ЗжжгЃЌ 15Зжжг CPUЕФИКдиЕФЦНОљжЕЁЃ
(load average: the average of the sum of TASK_RUNNING and TASK_UNINTERRUPTIBLE processes);
етвЛаазюживЊЕФОЭЪЧ load average
ЕкЖўааЃК
Tasks: 92 total, 1 running, 91 sleeping , 0 stopped, 0 zombie
ЗжБ№БэЪОЯЕЭГжаЕФНјГЬЪ§ЃКзмЙВ92ИіНјГЬЃЌ 1ИідкдЫааЃЌ91ИідкsleepЃЌ0Иіstopped, 0ИіНЉЪЌЃЛ
ЕкШ§ааЃК
Cpu(s): 0.0%us, 1.7 %sy, 0.0%ni, 97.7%id, 0.0%wa, 0.3%hi, 0.3%si, 0.0%st
етвЛааЬсЙЉСЫЙигкCPUЪЙгУТЪЕФзюживЊЕФаХЯЂЃЌЗжБ№БэЪО users time, system time, nice time, idle time, wait time, hard interrupte time, soft interrupted time, steal time; ЦфжазюжевЊЕФЪЧЃКusers time, system time, wait time ,idle time ЕШЕШЁЃnice time БэЪОгУгкЕїзМНјГЬnice levelЫљЛЈЕФЪБМфЁЃ
ЕкЫФааЃК
Mem: total, used ,free, buffers
ЬсЙЉЕФЪЧЙигкФкДцЕФаХЯЂЃЌвђЮЊLinuxЛсОЁСПЕФРДЪЙгУФкДцРДНјааЛКДцЃЌЫљвдетаЉаХЯЂУЛгаЖрДѓЕФМлжЕЃЌfreeЪ§жЕаЁЃЌВЂВЛДњБэДцдкФкДцЦПОБЃЛ
ЕкЮхааЃК
Swap: total, used, free ,cached
ЬсЙЉЕФЪЧЙигкswapЗжЧјЕФЪЙгУЧщПіЃЌетаЉаХЯЂвВУЛгаЬЋДѓЕФМлжЕЃЌвђЮЊLinuxЕФЪЙгУФкДцЕФЛњжЦОіЖЈЕФЁЃusedжЕКмДѓВЂВЛДњБэДцдкФкДцЦПОБЃЛ
ЪЃЯТЪЧЙигкУПИіНјГЬЪЙгУЕФзЪдДЕФЧщПіЃЌНјГЬЕФИїжжаХЯЂЃЌАДееЪЙгУCPUЕФЖрЩйХХађЃЌУПИізжЖЮЕФКЌвхШчЯТЃК
PID: БэЪОНјГЬIDЃЛUSER: БэЪОдЫааНјГЬЕФгУЛЇЃЛPRЃКБэЪОНјГЬгХЯШМЖЃЛNIЃКБэЪОНјГЬniceжЕЃЌФЌШЯЮЊ0ЃЛ
VIRTЃКThe total amount of virtual memory used by the task. It includes all code, data and shared libraries plus pages that have been swapped out. НјГЬеМгУЕФащФтФкДцДѓаЁЃЌАќРЈСЫswap outЕФФкДцpage;
RES: Resident size (kb)ЁЃThe non-swapped physical memory a task is using. НјГЬЪЙгУЕФГЃзЄФкДцДѓаЁЃЌУЛгаАќРЈswap outЕФФкДцЃЛ
SHRЃКShared Mem size (kb)ЁЃThe amount of shared memory used by a task. It simply reflects memory that could be potentially shared
with other processes. ЦфЪЕгІИУОЭЪЧЪЙгУ shmget() ЯЕЭГЕїгУЗжХфЕФЙВЯэФкДцЃЌПЩвддкЖрИіНјГЬжЎМфЙВЯэЗУЮЪЁЃ
S: БэЪОНјГЬДІгкФФжжзДЬЌЃКR: Running; S: sleeping; T: stoped; D: interrupted; Z:zomobie;
%CPU: НјГЬеМгУЕФCPUЃЛ
%MEMЃКНјГЬеМгУЕФФкДцЃЛ
%TIME+: НјГЬдЫааЪБМфЃЛ
COMMAND: НјГЬдЫааУќСюЃЛ
ЖСЖЎ top ЕШЯрЙиУќСюааЕФаХЯЂЪЧНјааЕїгХЕФЛљДЁЁЃЦфЪЕетаЉУќСюааЕФЪфГіЕФКЌвхЃЌдкman topжаЖМгаЪЧЗёЯъЯИЕФЫЕУїЁЃжЛвЊФЭаФПДЪжВсОЭааСЫЁЃ
ЩЯУцЕФ top УќСюФЌШЯЪЧвд НјГЬЮЊЕЅЮЛРДЯдЪОЕФЃЌЮвУЧвВПЩвдвдЯпГЬЮЊЕЅЮЛРДЯдЪОЃК top -H
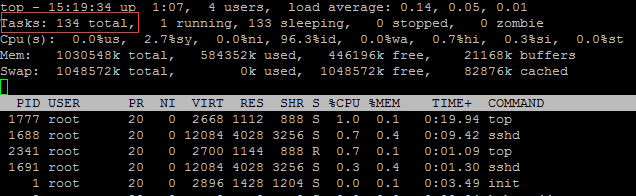
ПЩвдПДЕНвдЯпГЬЮЊЕЅЮЛЪЧЃЌTasks totolЪ§СПУїЯддіМгСЫЃЌга92діМгЕНСЫ 134ЃЌвђЮЊ mysqld ЪЧЯпГЬМмЙЙЕФЃЌКѓЬЈгаЖрИіКѓЬЈЯпГЬЁЃ
ШчЙћНіНіЯыВщПД CPU ЕФ load averageЃЌЪЙгУuptimeУќСюОЭааСЫЃК
[root@localhost ~]# uptime 15:26:59 up 1:15, 4 users, load average: 0.00, 0.02, 0.00
3.2 vmstat ВщПДCPU аХЯЂ
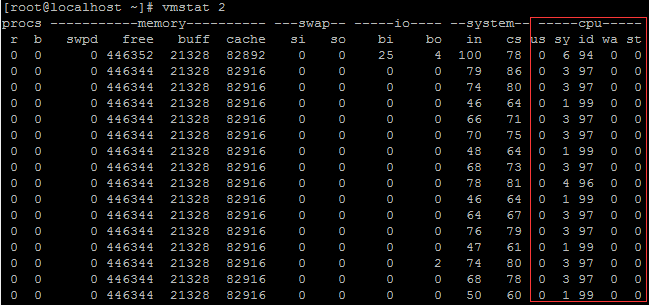
ЩЯУцИїИізжЖЮЕФКЌвхЃК
FIELD DESCRIPTION FOR VM MODE Procs r: The number of processes waiting for run time. b: The number of processes in uninterruptible sleep. Memory swpd: the amount of virtual memory used. free: the amount of idle memory. buff: the amount of memory used as buffers. cache: the amount of memory used as cache. inact: the amount of inactive memory. (-a option) active: the amount of active memory. (-a option) Swap si: Amount of memory swapped in from disk (/s). so: Amount of memory swapped to disk (/s). IO bi: Blocks received from a block device (blocks/s). bo: Blocks sent to a block device (blocks/s). System in: The number of interrupts per second, including the clock. cs: The number of context switches per second. CPU These are percentages of total CPU time. us: Time spent running non-kernel code. (user time, including nice time) sy: Time spent running kernel code. (system time) id: Time spent idle. Prior to Linux 2.5.41, this includes IO-wait time. wa: Time spent waiting for IO. Prior to Linux 2.5.41, included in idle. st: Time stolen from a virtual machine. Prior to Linux 2.6.11, unknown.
КЭCPUЯрЙиЕФаХЯЂга user time, system time, idle time, wait time, steal time;
СэЭтЬсЙЉСЫЙигкжаЖЯКЭЩЯЯТЮФЧаЛЛЕФаХЯЂЁЃSystem жаЕФinЃЌБэЪОУПУыЕФжаЖЯЪ§ЃЌcsБэЪОУПУыЕФЩЯЯТЮФЧаЛЛЪ§ЃЛ
ЦфЫќЕФзжЖЮЪЧЙигкФкДцКЭДХХЬЕФЁЃ
3.3 iostat УќСюВщПД CPU аХЯЂ
[root@localhost ~]# iostatLinux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU)avg-cpu: %user %nice %system %iowait %steal %idle 0.27 0.02 4.74 0.28 0.00 94.69Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtnscd0 0.01 0.08 0.00 536 0sda 1.64 42.27 8.97 290966 61720
[[email protected] ~]# iostat -c
Linux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.26 0.02 4.72 0.27 0.00 94.72
ЬсЙЉСЫcpuЕФЦНОљЪЙгУТЪЁЃ
3.4 ps УќСюВщПДФГИіНјГЬКЭФГИіЯпГЬЕФ CPU аХЯЂ
БШШчЮвЯыВщПД mysqld ЕФЯрЙиаХЯЂЃК
[root@localhost ~]# pidof mysqld2412[root@localhost ~]# ps -mp 2412 -o THREAD,pmem,rss,vsz,tid,pidUSER %CPU PRI SCNT WCHAN USER SYSTEM %MEM RSS VSZ TID PIDmysql 6.7 - - - - - 42.8 441212 752744 - 2412mysql 6.5 19 - - - - - - - 2412 -mysql 0.0 19 - - - - - - - 2414 -mysql 0.0 19 - - - - - - - 2415 -mysql 0.0 19 - - - - - - - 2416 -mysql 0.0 19 - - - - - - - 2417 -mysql 0.0 19 - - - - - - - 2418 -mysql 0.0 19 - - - - - - - 2419 -mysql 0.0 19 - - - - - - - 2420 -mysql 0.0 19 - - - - - - - 2421 -mysql 0.0 19 - - - - - - - 2422 -mysql 0.0 19 - - - - - - - 2423 -mysql 0.0 19 - - - - - - - 2425 -mysql 0.0 19 - - - - - - - 2426 -mysql 0.0 19 - - - - - - - 2427 -mysql 0.0 19 - - - - - - - 2428 -mysql 0.0 19 - - - - - - - 2429 -mysql 0.0 19 - - - - - - - 2430 -mysql 0.0 19 - - - - - - - 2431 -mysql 0.0 19 - - - - - - - 2432 -mysql 0.0 19 - - - - - - - 2433 -mysql 0.0 19 - - - - - - - 2434 -
ЯШЛёЕУ mysqld ЕФЛљДЁPID 2412ЃЌ
ШЛКѓВщПДЦфЯпГЬЕФаХЯЂЃКps -mp 2412-o THREAD,pmem,rss,vsz,tid,pid ( -p жИЖЈНјГЬPIDЃЌ -o жИЖЈЪфГіИёЪНЃЌВЮМћman ps)
ЕквЛСаОЭЪЧЙигкЯпГЬCPUЕФаХЯЂЁЃСэЭтЮвУЧвВПЩвдВщГіЪЧеМгаЕФCPUКмИпЕФЯпГЬЕФtidЁЃ
ЙигкpsЮвУЧвЛАуЪЙгУ ps -elf ЃЌ ШчЙћЯыВщПДЯпГЬЃЌПЩвд ps -elLfЃЌЦфжаЕФLБэЪО Leight weight processЧсСПМЖНјГЬЁЃ
3.5 mpstat(multi processor stat) УќСюВщПДЖрКЫCPUжаУПИіCPUКЫаФЕФаХЯЂ
[root@localhost ~]# mpstatLinux 2.6.32-504.el6.i686 (localhost.localdomain) 09/30/2015 _i686_ (1 CPU)04:11:50 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle04:11:50 PM all 0.26 0.02 4.30 0.27 0.26 0.15 0.00 0.00 94.74
етРявђЮЊащФтЛњжаЕФЕЅКЫCPUЃЌЫљвджЛЯдЪОallЃЌУЛгаЯдЪОЦфЫќКЫаФЕФCPUЪЙгУЧщПіЁЃ
4. CPU ЯрЙиЕїгХ
1ЃЉЪЙгУЩЯУцНщЩмЕФЙЄОпЃКtop, vmstat, iostat, ps -mp xxx -o, mpstat ЕШЃЌПЩвдШЗШЯЪЧЗёДцдк CPU ЦПОБЁЃШЛКѓШЗШЯ user time, system time, wait time, context switch......ФЧжжеМгУБШР§ИпЃЌШЗШЯЪЧФФИіНјГЬеМгУCPUИпЁЃШчЙћФмШЗШЯЪЧ mysqld ЕФЯрЙиНјГЬЃЌФЧУДОЭПЩвдДг mysql ЩЯШыЪжНјааЕїгХЁЃБШШчЪЙгУmysqlЕФУќСю show processlist ЃЛВщПДЪЧФФИіsqlЕМжТЕФЃЌевЕНsqlжЎКѓЃЌНјаагХЛЏЛђепжиаДЕШЕШЃЌЛђепНЋЦфЗХЕНslaveЩЯШЅдЫааЁЃ
2ЃЉШчЙћЪЧ ЗЧБиаыЕФНјГЬеМгУCPUЃЌФЧУДПЩвдЩБЕєЃЌШЛКѓЪЙгУcronШУЦфдкЗЧИпЗхЦкШЅжДааЃЛЛђепЪЙгУ renice УќСюНЕЕЭЦфгХЯШМЖЃЛ
[root@localhost ~]# renice -n -10 -p 20412041: old priority 10, new priority -10
НЋНјГЬ 2041 ЕФгХЯШМЖЩшжУЮЊ -10.
3ЃЉПЩвдИњзйНјГЬЃЌВщевдвђЃКstrace -aef -p spid -o file
[root@localhost ~]# strace -aef -p 2041 -o mysql.txtProcess 2041 attached - interrupt to quit^CProcess 2041 detached[root@localhost ~]# ll mysql.txt-rw-r--r-- 1 root root 10091 Sep 30 16:44 mysql.txt[root@localhost ~]# head mysql.txtread(0, "\33", 1) = 1read(0, "[", 1) = 1read(0, "A", 1) = 1write(1, "select version();", 17) = 17read(0, "\n", 1) = 1write(1, "\n", 1) = 1ioctl(0, SNDCTL_TMR_STOP or TCSETSW, {B38400 opost isig icanon echo ...}) = 0rt_sigprocmask(SIG_BLOCK, [HUP INT QUIT TERM CONT TSTP WINCH], [], 8) = 0rt_sigaction(SIGINT, {0x8053ac0, [INT], SA_RESTART}, NULL, 8) = 0rt_sigaction(SIGTSTP, {SIG_DFL, [], 0}, NULL, 8) = 0
4ЃЉЛЛИќКУЕФCPUЁЃ