原创博客,转载请联系博主!
转眼快两个月没有更新自己的博客了。
一来感觉自己要学的东西还是太多,与其花几个小时写下经验分享倒不如多看几点技术书。
二来放眼网上已经有很多成熟的中文文章介绍这些用法,自己赘述无异重造车轮。
所以,既然开始打算要写,就希望可以有一些与众不同的用法和新意,可以给大家一点启发。
使用Java中成型的框架来帮助我们开发并发应用即可以节省构建项目的时间,也可以提高应用的性能。
Java对象实例的锁一共有四种状态:无锁,偏向锁,轻量锁和重量锁。原始脱离框架的并发应用大部分都需要手动完成加锁释放,最直接的就是使用synchronized和volatile关键字对某个对象或者代码块加锁从而限制每次访问的次数,从对象之间的竞争也可以实现到对象之间的协作。但是这样手动实现出来的应用不仅耗费时间而且性能表现往往又有待提升。顺带一提,之前写过一篇文章介绍我基于Qt和Linux实现的一个多线程下载器(到这里不需要更多了解这个下载器,请直接继续阅读),就拿这个下载器做一次反例:
首先,一个下载器最愚蠢的问题之一就是把下载线程的个数交由给用户去配置。比如一个用户会认为负责下载的线程个数是越多越好,干脆配置了50个线程去下载一份任务,那么这个下载器的性能表现甚至会不如一个单进程的下载程序。最直接的原因就是JVM花费了很多计算资源在线程之间的上下文切换上面,对于一个并发的应用:如果是CPU密集型的任务,那么良好的线程个数是实际CPU处理器的个数的1倍;如果是I/O密集型的任务,那么良好的线程个数是实际CPU处理器个数的1.5倍到2倍(具体记不清这句话是出于哪里了,但还是可信的)。不恰当的执行线程个数会给线程抖动,CPU抖动等隐患埋下伏笔。如果,重新开发那么我一定会使用这种线程池的方法使用生产者和消费者的关系模式,异步处理HTTP传输过来的报文。
其次,由于HTTP报文的接受等待的时间可能需要等待很久,然而处理报文解析格式等等消耗的计算资源是相当较小的。同步地处理这两件事情必然会使下载进程在一段时间内空转或者阻塞,这样处理也是非常不合理的。如果重新开发,一定要解耦HTTP报文的接收和HTTP报文的解析,这里尽管也可以使用线程池去进行处理,显而易见由于这样去做的性能提升其实是很小的,所以没有必要去实现,单线程也可以快速完成报文的解析。
Okay,回到主题,总而言之是线程之间的上下文切换导致了性能的降低。那么具体应该怎么样去做才可以减少上下文的切换呢?
1. 无锁并发编程
多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash算法取模分段,不同的线程去处理不同段的数据。
2. CAS算法
Java的Atomic包内使用CAS算法来更新数据,而不需要加锁(但是线程的空转还是存在)。
3. 使用最少线程
避免创建不需要的线程,比如任务很少,但是创建很多线程来处理,这样会造成大量线程都处于等待状态。
4. 协程
在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
总的来说使用Java线程池会带来以下3个好处:
1. 降低资源消耗: 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
2. 提高响应速度: 当任务到达时,任务可以不需要等到线程创建就能立即执行。
3. 提高线程的可管理性: 线程是稀缺资源,如果无限制的创建。不仅仅会降低系统的稳定性,使用线程池可以统一分配,调优和监控。但是要做到合理的利用线程池。必须对于其实现原理了如指掌。
线程池的实现原理如下图所示:
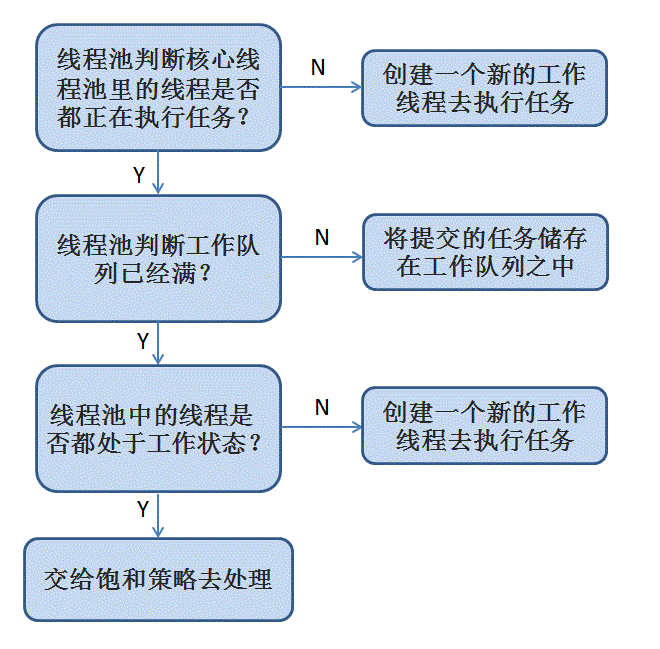
Executor框架的两级调度模型:
在HotSpot VM线程模型中,Java线程被一对一的映射为本地操作系统线程,Java线程启动时会创建一个本地操作系统线程,当该Java线程终止时,这个操作系统也会被回收。操作系统会调度并将它们分配给可用的CPU。
在上层,Java多线程程序通常把应用分解为若干个任务,然后把用户级的调度器(Executor框架)将这些映射为固定数量的线程;在底层,操作系统内核将这些线程映射到硬件处理器上。这种两级调度模型实质是一种工作单元和执行机制的解偶。
Fork/Join框架的递归调度模型:
要提高应用程序在多核处理器上的执行效率,只能想办法提高应用程序的本身的并行能力。常规的做法就是使用多线程,让更多的任务同时处理,或者让一部分操作异步执行,这种简单的多线程处理方式在处理器核心数比较少的情况下能够有效地利用处理资源,因为在处理器核心比较少的情况下,让不多的几个任务并行执行即可。但是当处理器核心数发展很大的数目,上百上千的时候,这种按任务的并发处理方法也不能充分利用处理资源,因为一般的应用程序没有那么多的并发处理任务(服务器程序是个例外)。所以,只能考虑把一个任务拆分为多个单元,每个单元分别得执行最后合并每个单元的结果。一个任务的并行拆分,一种方法就是寄希望于硬件平台或者操作系统,但是目前这个领域还没有很好的结果。另一种方案就是还是只有依靠应用程序本身对任务经行拆封执行。
Fork/Join模型乍看起来很像借鉴了MapReduce,但是具体不敢肯定是什么原因,实际用起来的性能提升是远不如Executor的。甚至在递归栈到了十层以上的时候,JVM会卡死或者崩溃,从计算机的物理原理来看,Fork/Join框架实际效能也没有想象中的那么美好,所以这篇只稍微谈一下,不再深究。
Executor框架主要由三个部分组成:任务,任务的执行,异步计算的结果。
主要的类和接口简介如下:
1. Executor是一个接口,它将任务的提交和任务的执行分离。
2. ThreadPoolExecutor是线程池的核心,用来执行被提交的类。
3. Future接口和实现Future接口的FutureTask类,代表异步计算的结果。
4. Runnable接口和Callable接口的实现类,都可以被ThreadPoolExecutor或其他执行。
先看一个直接的例子(用SingleThreadExecutor来实现,具体原理下面会阐述):
1 public class ExecutorDemo { 2 3 4 public static void main(String[] args){ 5 6 //ExecutorService fixed= Executors.newFixedThreadPool(4); 7 ExecutorService single=Executors.newSingleThreadExecutor(); 8 //ExecutorService cached=Executors.newCachedThreadPool(); 9 //ExecutorService sched=Executors.newScheduledThreadPool(4);11 12 Callable<String> callable=Executors.callable(new Runnable() {13 @Override14 public void run() {15 for(int i=0;i<100;i++){16 try{17 System.out.println(i);18 }catch(Throwable e){19 e.printStackTrace();20 }21 }22 }23 },"success");24 //这里抖了个机灵,用Executors工具类的callable方法将一个匿名Runnable对象装饰为Callable对象作为参数25 Future<String> f=single.submit(callable);26 try {27 System.out.println(f.get());28 single.shutdown();29 }catch(Throwable e){30 e.printStackTrace();31 }32 }33 }
如代码中所示,常用一共有四种Exector实现类通过Executors的工厂方法来创建Executor的实例,其具体差别及特点如下所示:
1. FixedThreadPool
这个是我个人最常用的实现类,在Java中最直接的使用方法就是和 Runtime.getRuntime().availableProcessors() 一起使用分配处理器个数个的Executor。内部结构大致如下:
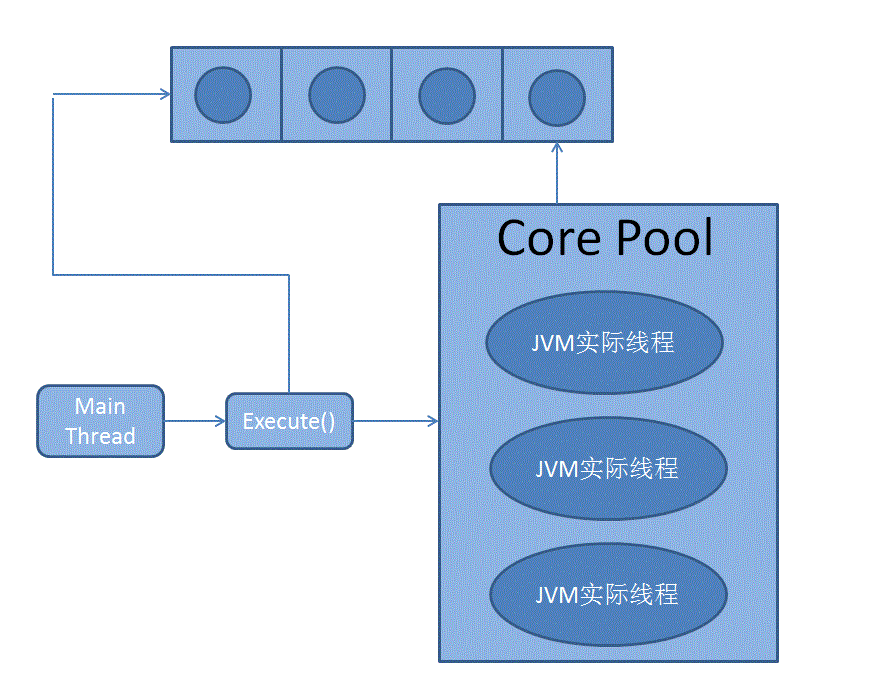
创造实例的函数为: Executors.newFixedThreadPool(int nThread);
在JDK1.7里java.util.concurrent包中的源码中队列使用的是new LinkedBlockingQueue<Runnable>,这是一个无界的队列,也就是说任务有可能无限地积压在这个等待队列之中,实际使用是存在一定的隐患。但是构造起来相当比较容易,我个人建议在使用的过程之中不断查询size()来保证该阻塞队列不会无限地生长。
2. SingleThreadExecutor
和 Executors.newFixedThreadPool(1) 完全等价。
3. CachedThreadPool
和之前两个实现类完全不同的是,这里使用SynchronousQueue替换LinkedBlockingQueue。简单提一下SynchronousQueue是一个没有容量的队列,一个offer必须对应一个poll,当然所谓poll操作是由实际JVM工作线程来进行的,所以对于使用开发者来讲,这是一个会因为工作线程饱和而阻塞的线程池。(这个和java.util.concurrent.Exchanger的作用有些相似,但是Exchanger只是对于两个JVM线程的,而SynchronousQueue的阻塞机制是多个生产者和多个消费者而言的。)
4. ScheduledThreadPoolExecutor
这个实现类内部使用的是DelayQueue。DelayQueue实际上是一个优先级队列的封装。时间早的任务会拥有更高的优先级。它主要用来在给定的延迟之后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor比Timer更加灵活,而且可以有多个后台线程在构造函数之中指定。
Future接口和ListenableFurture接口
Future接口为异步计算取回结果提供了一个存根(stub),然而这样每次调用Future接口的get方法取回计算结果往往是需要面临阻塞的可能性。这样在最坏的情况下,异步计算和同步计算的消耗是一致的。Guava库中因此提供一个非常强大的装饰后的Future接口,使用观察者模式为在异步计算完成之后马上执行addListener指定一个Runnable对象,从实现“完成立即通知”。这里提供一个有效的Tutorial :http://ifeve.com/google-guava-listenablefuture/