�����һ����localģʽ����eclipse����һ����sparkӦ�ó����ڱ������в��ԡ�
1.�������°��scala for eclipse�汾��ѡ��windows 64λ��������ַ��http://scala-ide.org/download/sdk.html
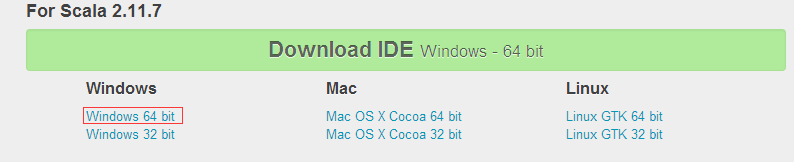
���غú��ѹ��D�̣���ѡ�����ռ䡣

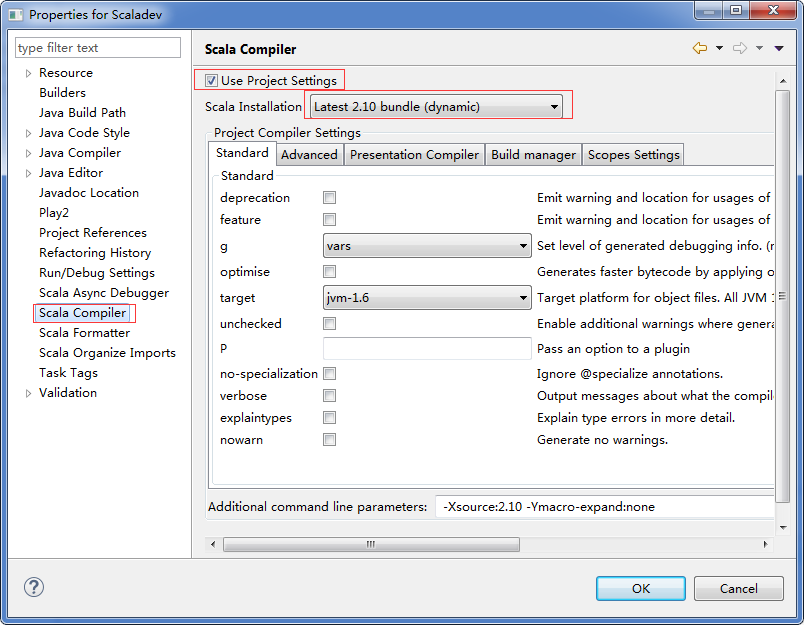
Ȼ��һ��������ĿScalaDev,�һ���Ŀѡ��Properties���ڶԻ�����ѡ��Scala Compiler��������ҳǩ�й�ѡUse Project Settings��Scala Installation���ok���������á�
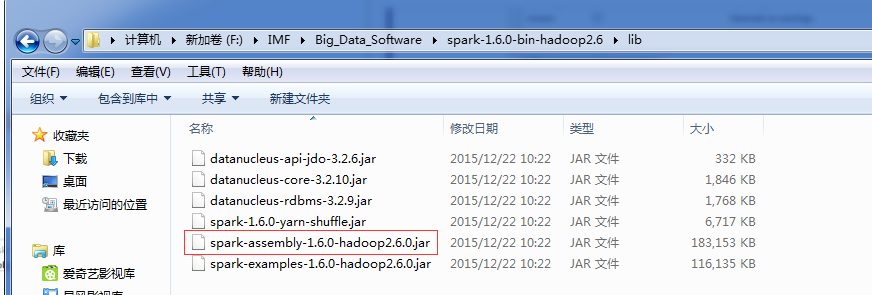
2.����spark1.6.0��jar�ļ�����spark-assembly-1.6.0-hadoop2.6.0.jar�������ӵ���Ŀ�С�
spark-assembly-1.6.0-hadoop2.6.0.jar��spark-1.6.0-bin-hadoop2.6.tgz���е�lib���档
�һ�ScalaDev��Ŀѡ��Build Path->Configure Build Path
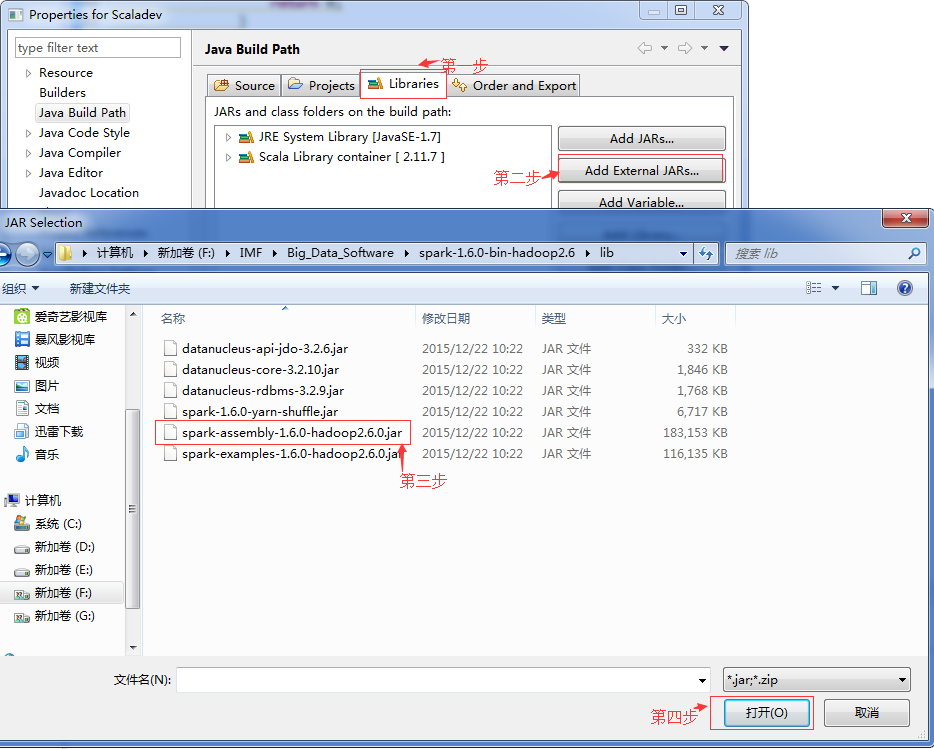
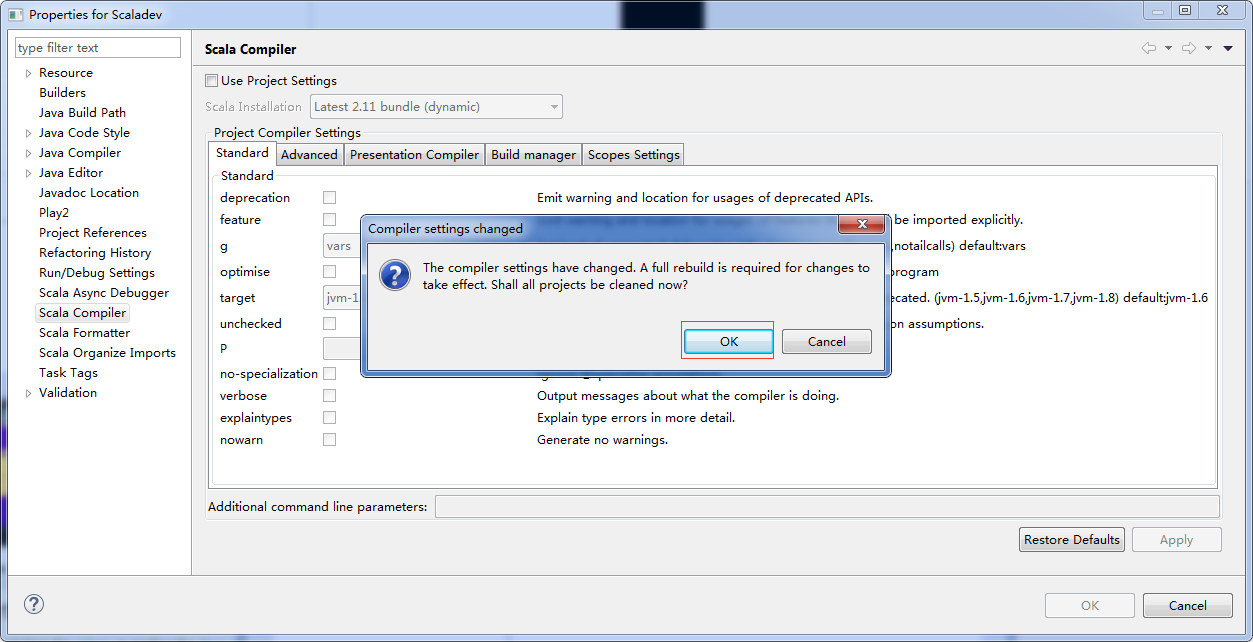
ע�������ѡ����Scala InstallationΪLatest2.11 bundle��dynamic����Ŀ�ᱨ���µĴ���ScalaDev�����ϳ���һ����棬�鿴Problems�����ԭ����scala����汾��spark�IJ�һ�µ��¡�
More than one scala library found in the build path (D:/eclipse/plugins/org.scala-lang.scala-library_2.11.7.v20150622-112736-1fbce4612c.jar, F:/IMF/Big_Data_Software/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar).At least one has an incompatible version. Please update the project build path so it contains only one compatible scala library.
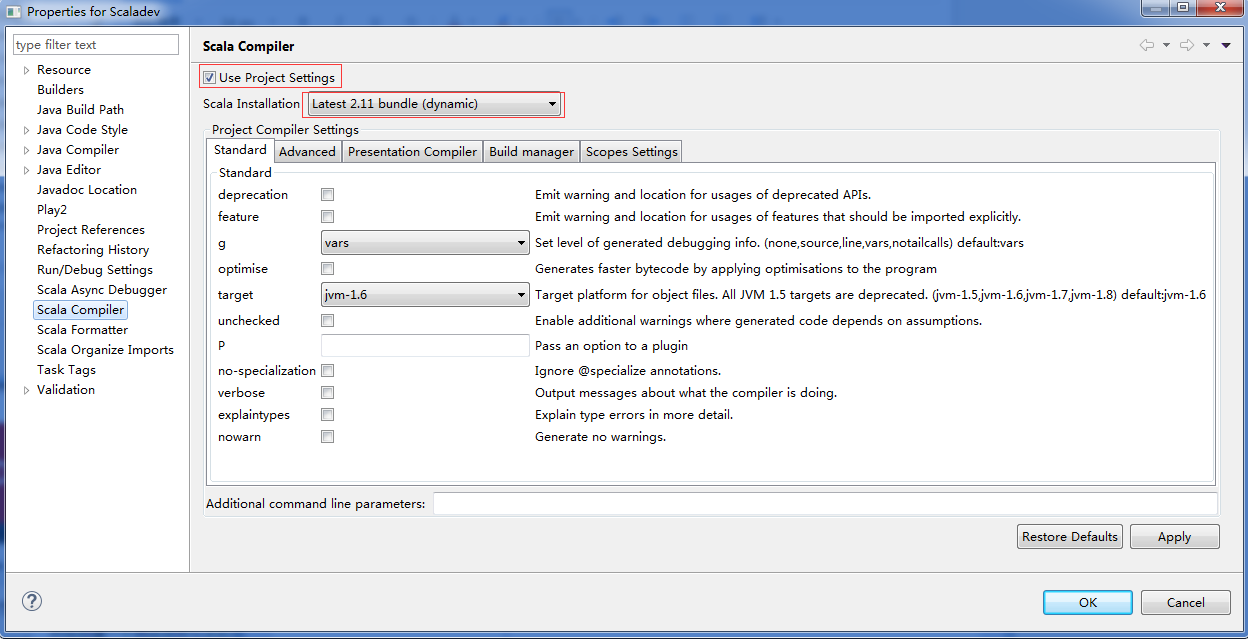
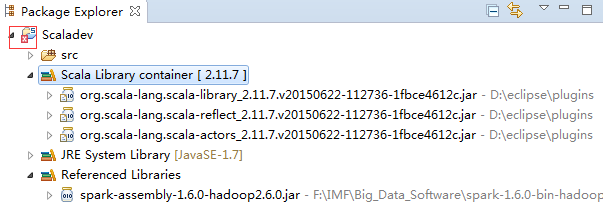
����������һ�Scala Library Container->Properties���ڵ�������ѡ��Latest 2.10 bundle��dynamic�������漴�ɡ�
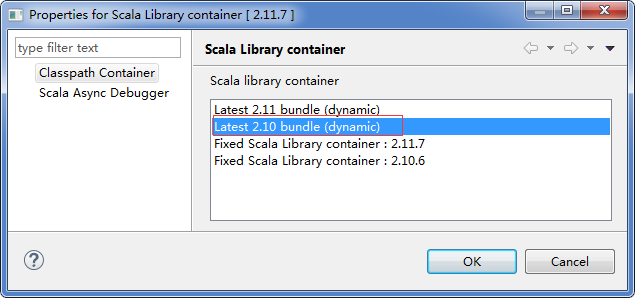
3.��src�´���spark���̰�������������ࡣ
ѡ����ĿNew -> Package����com.imf.spark��;
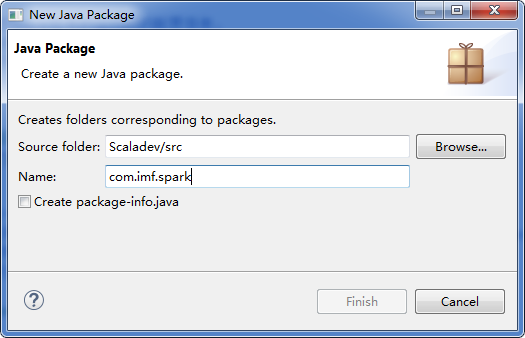
ѡ��com.imf.spark����������Scala Object;
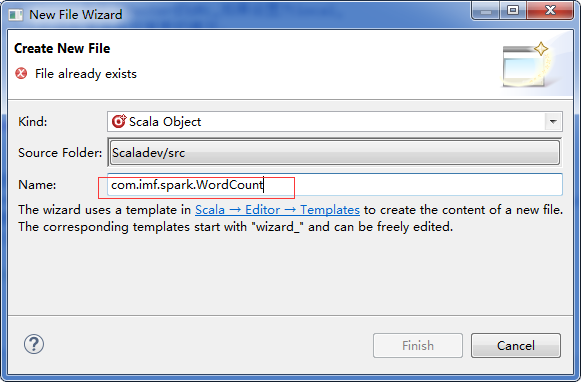
���Գ���ǰ��Ҫ��spark-1.6.0-bin-hadoop2.6Ŀ¼�е�README.md�ļ�������D://testspark//Ŀ¼�У��������£�
package com.imf.sparkimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/** * �û�scala�������ز��Ե�spark wordcount���� */object WordCount { def main(args: Array[String]): Unit = { /** * 1.����Spark�����ö���SparkConf������Spark���������ʱ��������Ϣ�� * ���磺ͨ��setMaster�����ó���Ҫ���ӵ�Spark��Ⱥ��Master��URL,�������Ϊlocal, * �����Spark�����ڱ������У��ر��ʺ��ڻ������������dz��������� */ //����SparkConf���� val conf = new SparkConf() //����Ӧ�ó������ƣ��ڳ������еļ�ؽ�����Կ������� conf.setAppName("My First Spark App!") //����localʹ�����ڱ������У�����Ҫ��װSpark��Ⱥ conf.setMaster("local") /** * 2.����SparkContext���� * SparkContext��spark�������й��ܵ�Ψһ��ڣ������Dz���Scala,java,python,R�ȶ�������һ��SprakContext * SparkContext�������ã���ʼ��sparkӦ�ó�����������Ҫ�ĺ������������DAGScheduler,TaskScheduler,SchedulerBackend * ͬʱ���Ḻ��Spark������Masterע�����ȣ� * SparkContext������Ӧ�ó�������Ϊ������Ҫ��һ������ */ //ͨ������SparkContext����ͨ������SparkConfʵ������Spark���еľ��������������Ϣ val sc = new SparkContext(conf) /** * 3.���ݾ������ݵ���Դ��HDFS,HBase,Local,FS,DB,S3�ȣ�ͨ��SparkContext������RDD�� * RDD�Ĵ������������ַ�ʽ�������ⲿ��������Դ������HDFS��������Scala���ϡ���������RDD������ * ���ݻᱻRDD���ֳ�Ϊһϵ�е�Partitions,���䵽ÿ��Partition����������һ��Task�Ĵ������룻 */ //��ȡ�����ļ���������һ��partition val lines = sc.textFile("D://testspark//README.md",1) /** * 4.�Գ�ʼ��RDD����Transformation����Ĵ���������map,filter�ȸ߽����ı�ɣ������о�������ݼ��� * 4.1.��ÿһ�е��ַ�����ֳɵ������� */ //��ÿһ�е��ַ������в�ֲ��������еIJ�ֽ��ͨ��flat�ϲ���һ����ļ��� val words = lines.flatMap { line => line.split(" ") } /** * 4.2.�ڵ��ʲ�ֵĻ����϶�ÿ������ʵ������Ϊ1��Ҳ����word => (word,1) */ val pairs = words.map{word =>(word,1)} /** * 4.3.��ÿ������ʵ������Ϊ1������ͳ��ÿ���������ļ��г��ֵ��ܴ��� */ //����ͬ��key����value���ۻ�������Local��Reducer����ͬʱReduce�� val wordCounts = pairs.reduceByKey(_+_) //��ӡ��� wordCounts.foreach(pair => println(pair._1+":"+pair._2)) sc.stop() }}���н����
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties16/01/26 08:23:37 INFO SparkContext: Running Spark version 1.6.016/01/26 08:23:42 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable16/01/26 08:23:42 ERROR Shell: Failed to locate the winutils binary in the hadoop binary pathjava.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:355) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:370) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:363) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) at org.apache.hadoop.security.Groups.parseStaticMapping(Groups.java:104) at org.apache.hadoop.security.Groups.<init>(Groups.java:86) at org.apache.hadoop.security.Groups.<init>(Groups.java:66) at org.apache.hadoop.security.Groups.getUserToGroupsMappingService(Groups.java:280) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:271) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:248) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:763) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:748) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:621) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2136) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2136) at scala.Option.getOrElse(Option.scala:120) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2136) at org.apache.spark.SparkContext.<init>(SparkContext.scala:322) at com.dt.spark.WordCount$.main(WordCount.scala:29) at com.dt.spark.WordCount.main(WordCount.scala)16/01/26 08:23:42 INFO SecurityManager: Changing view acls to: vivi16/01/26 08:23:42 INFO SecurityManager: Changing modify acls to: vivi16/01/26 08:23:42 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(vivi); users with modify permissions: Set(vivi)16/01/26 08:23:43 INFO Utils: Successfully started service 'sparkDriver' on port 54663.16/01/26 08:23:43 INFO Slf4jLogger: Slf4jLogger started16/01/26 08:23:43 INFO Remoting: Starting remoting16/01/26 08:23:43 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.100.102:54676]16/01/26 08:23:43 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 54676.16/01/26 08:23:43 INFO SparkEnv: Registering MapOutputTracker16/01/26 08:23:43 INFO SparkEnv: Registering BlockManagerMaster16/01/26 08:23:43 INFO DiskBlockManager: Created local directory at C:\Users\vivi\AppData\Local\Temp\blockmgr-5f59f3c2-3b87-49c5-a1ae-e21847aac44b16/01/26 08:23:43 INFO MemoryStore: MemoryStore started with capacity 1813.7 MB16/01/26 08:23:43 INFO SparkEnv: Registering OutputCommitCoordinator16/01/26 08:23:43 INFO Utils: Successfully started service 'SparkUI' on port 4040.16/01/26 08:23:43 INFO SparkUI: Started SparkUI at http://192.168.100.102:404016/01/26 08:23:43 INFO Executor: Starting executor ID driver on host localhost16/01/26 08:23:43 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 54683.16/01/26 08:23:43 INFO NettyBlockTransferService: Server created on 5468316/01/26 08:23:43 INFO BlockManagerMaster: Trying to register BlockManager16/01/26 08:23:43 INFO BlockManagerMasterEndpoint: Registering block manager localhost:54683 with 1813.7 MB RAM, BlockManagerId(driver, localhost, 54683)16/01/26 08:23:43 INFO BlockManagerMaster: Registered BlockManager16/01/26 08:23:46 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 153.6 KB, free 153.6 KB)16/01/26 08:23:46 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 13.9 KB, free 167.6 KB)16/01/26 08:23:46 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:54683 (size: 13.9 KB, free: 1813.7 MB)16/01/26 08:23:46 INFO SparkContext: Created broadcast 0 from textFile at WordCount.scala:3716/01/26 08:23:47 WARN : Your hostname, vivi-PC resolves to a loopback/non-reachable address: fe80:0:0:0:5937:95c4:86da:2f43%30, but we couldn't find any external IP address!16/01/26 08:23:48 INFO FileInputFormat: Total input paths to process : 116/01/26 08:23:48 INFO SparkContext: Starting job: foreach at WordCount.scala:5616/01/26 08:23:48 INFO DAGScheduler: Registering RDD 3 (map at WordCount.scala:48)16/01/26 08:23:48 INFO DAGScheduler: Got job 0 (foreach at WordCount.scala:56) with 1 output partitions16/01/26 08:23:48 INFO DAGScheduler: Final stage: ResultStage 1 (foreach at WordCount.scala:56)16/01/26 08:23:48 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)16/01/26 08:23:48 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)16/01/26 08:23:48 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:48), which has no missing parents16/01/26 08:23:48 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.0 KB, free 171.6 KB)16/01/26 08:23:48 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 173.9 KB)16/01/26 08:23:48 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:54683 (size: 2.3 KB, free: 1813.7 MB)16/01/26 08:23:48 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:100616/01/26 08:23:48 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount.scala:48)16/01/26 08:23:48 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks16/01/26 08:23:48 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2119 bytes)16/01/26 08:23:48 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)16/01/26 08:23:48 INFO HadoopRDD: Input split: file:/D:/testspark/README.md:0+335916/01/26 08:23:48 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id16/01/26 08:23:48 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id16/01/26 08:23:48 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap16/01/26 08:23:48 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition16/01/26 08:23:48 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id16/01/26 08:23:48 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2253 bytes result sent to driver16/01/26 08:23:48 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 177 ms on localhost (1/1)16/01/26 08:23:48 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool 16/01/26 08:23:48 INFO DAGScheduler: ShuffleMapStage 0 (map at WordCount.scala:48) finished in 0.186 s16/01/26 08:23:48 INFO DAGScheduler: looking for newly runnable stages16/01/26 08:23:48 INFO DAGScheduler: running: Set()16/01/26 08:23:48 INFO DAGScheduler: waiting: Set(ResultStage 1)16/01/26 08:23:48 INFO DAGScheduler: failed: Set()16/01/26 08:23:48 INFO DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:54), which has no missing parents16/01/26 08:23:48 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.5 KB, free 176.4 KB)16/01/26 08:23:48 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1581.0 B, free 177.9 KB)16/01/26 08:23:48 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:54683 (size: 1581.0 B, free: 1813.7 MB)16/01/26 08:23:48 INFO SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:100616/01/26 08:23:48 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount.scala:54)16/01/26 08:23:48 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks16/01/26 08:23:48 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, partition 0,NODE_LOCAL, 1894 bytes)16/01/26 08:23:48 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)16/01/26 08:23:48 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks16/01/26 08:23:48 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 2 mspackage:1For:2Programs:1processing.:1Because:1The:1cluster.:1its:1[run:1APIs:1have:1Try:1computation:1through:1several:1This:2graph:1Hive:2storage:1["Specifying:1To:2page](http://spark.apache.org/documentation.html):1Once:1"yarn":1prefer:1SparkPi:2engine:1version:1file:1documentation,:1processing,:1the:21are:1systems.:1params:1not:1different:1refer:2Interactive:2R,:1given.:1if:4build:3when:1be:2Tests:1Apache:1./bin/run-example:2programs,:1including:3Spark.:1package.:11000).count():1Versions:1HDFS:1Data.:1>>>:1programming:1Testing:1module,:1Streaming:1environment:1run::1clean:11000::2rich:1GraphX:1Please:3is:6run:7URL,:1threads.:1same:1MASTER=spark://host:7077:1on:5built:1against:1[Apache:1tests:2examples:2at:2optimized:1usage:1using:2graphs:1talk:1Shell:2class:2abbreviated:1directory.:1README:1computing:1overview:1`examples`:2example::1##:8N:1set:2use:3Hadoop-supported:1tests](https://cwiki.apache.org/confluence/display/SPARK/Useful+Developer+Tools).:1running:1find:1contains:1project:1Pi:1need:1or:3Big:1Java,:1high-level:1uses:1<class>:1Hadoop,:2available:1requires:1(You:1see:1Documentation:1of:5tools:1using::1cluster:2must:1supports:2built,:1system:1build/mvn:1Hadoop:3this:1Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version):1particular:2Python:2Spark:13general:2YARN,:1pre-built:1[Configuration:1locally:2library:1A:1locally.:1sc.parallelize(1:1only:1Configuration:1following:2basic:1#:1changed:1More:1which:2learning,:1first:1./bin/pyspark:1also:4should:2for:11[params]`.:1documentation:3[project:2mesos://:1Maven](http://maven.apache.org/).:1setup:1<http://spark.apache.org/>:1latest:1your:1MASTER:1example:3scala>:1DataFrames,:1provides:1configure:1distributions.:1can:6About:1instructions.:1do:2easiest:1no:1how:2`./bin/run-example:1Note:1individual:1spark://:1It:2Scala:2Alternatively,:1an:3variable:1submit:1machine:1thread,:1them,:1detailed:2stream:1And:1distribution:1return:2Thriftserver:1./bin/spark-shell:1"local":1start:1You:3Spark](#building-spark).:1one:2help:1with:3print:1Spark"](http://spark.apache.org/docs/latest/building-spark.html).:1data:1wiki](https://cwiki.apache.org/confluence/display/SPARK).:1in:5-DskipTests:1downloaded:1versions:1online:1Guide](http://spark.apache.org/docs/latest/configuration.html):1comes:1[building:1Python,:2Many:1building:2Running:1from:1way:1Online:1site,:1other:1Example:1analysis.:1sc.parallelize(range(1000)).count():1you:4runs.:1Building:1higher-level:1protocols:1guidance:2a:8guide,:1name:1fast:1SQL:2will:1instance::1to:14core:1:67web:1"local[N]":1programs:2package.):1that:2MLlib:1["Building:1shell::2Scala,:1and:10command,:2./dev/run-tests:1sample:116/01/26 08:23:48 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1165 bytes result sent to driver16/01/26 08:23:48 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 61 ms on localhost (1/1)16/01/26 08:23:48 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool 16/01/26 08:23:48 INFO DAGScheduler: ResultStage 1 (foreach at WordCount.scala:56) finished in 0.061 s16/01/26 08:23:48 INFO DAGScheduler: Job 0 finished: foreach at WordCount.scala:56, took 0.328012 s16/01/26 08:23:48 INFO SparkUI: Stopped Spark web UI at http://192.168.100.102:404016/01/26 08:23:48 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!16/01/26 08:23:48 INFO MemoryStore: MemoryStore cleared16/01/26 08:23:48 INFO BlockManager: BlockManager stopped16/01/26 08:23:48 INFO BlockManagerMaster: BlockManagerMaster stopped16/01/26 08:23:48 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!16/01/26 08:23:48 INFO SparkContext: Successfully stopped SparkContext16/01/26 08:23:48 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.16/01/26 08:23:48 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.16/01/26 08:23:48 INFO ShutdownHookManager: Shutdown hook called16/01/26 08:23:48 INFO ShutdownHookManager: Deleting directory C:\Users\vivi\AppData\Local\Temp\spark-56f9ed0a-5671-449a-955a-041c63569ff2
˵��������������д����Ǽ���hadoop�����ã���Ϊ�����ڱ��أ����Ҳ����ģ�����Ӱ����ԡ�
�����֣��й�Spark��һ�ˣ�Spark��̫�о�ԺԺ������ϯר��
DT���������
��������http://weibo.com.ilovepains/
�ֻ���18610086859
QQ��1740415547
��ϵ����18610086859@126.com