ʹ��eclipse������hadoop��ҵ�Ƿdz�����ģ�ɢ����ǰҲ����eclipse������hadoop������һֱû�������˽�eclipse���Ե�һЩģʽ����Щʱ��Ҳ���һЩĪ��������쳣������ľ����������
 ?
?

- java.lang.RuntimeException:?java.lang.ClassNotFoundException:?com.qin.sort.TestSort$SMapper??
- ????at?org.apache.hadoop.conf.Configuration.getClass(Configuration.java:857)??
- ????at?org.apache.hadoop.mapreduce.JobContext.getMapperClass(JobContext.java:199)??
- ????at?org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:718)??
- ????at?org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)??
- ????at?org.apache.hadoop.mapred.Child$4.run(Child.java:255)??
- ????at?java.security.AccessController.doPrivileged(Native?Method)??
- ????at?javax.security.auth.Subject.doAs(Subject.java:415)??
- ????at?org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)??
java.lang.RuntimeException: java.lang.ClassNotFoundException: com.qin.sort.TestSort$SMapper at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:857) at org.apache.hadoop.mapreduce.JobContext.getMapperClass(JobContext.java:199) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:718) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364) at org.apache.hadoop.mapred.Child$4.run(Child.java:255) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:415) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
����쳣����Ī�������һ���������Լ���MR�����������Mapper���ڲ��࣬����һ���г��ͱ�����쳣��˵�Ҳ�������࣬Ȼ��Ͱٰ�������⣬������ȥ��Ҳû�ҳ�������Ȼ��
��ʵ�Ⲣ���dz�������⣬���Ƕ�eclipse�ĵ���ģʽ�����˽�����⣬eclipse������hadoop�ܵ���˵��2��ģʽ����һ�־���Localģʽ��Ҳ�б���ģʽ���ڶ��־���������ʽ�����ϼ�Ⱥģʽ�������б���ģʽ��ʱ�����ᱻ�ύ��Hadoop��Ⱥ�ϣ����ǻ��ڵ�����ģʽ�ܵģ����ǵ�����ģʽ�����еĽ�������Ǵ洢��HDFS�ϵģ�ֻ����û������hadoop��Ⱥ����Դ��������ģʽ��Ҫ�ύjar����hadoop��Ⱥ�ϣ����һ������ʹ��local���������ǵ�MR�����Ƿ��ܹ��������У�
�������������£�����Localģʽ�ܵ�һ��������ҵ��
?- �������ݣ�??
- a?784??
- b?12??
- c?-11??
- dd?99999??
�������ݣ�a 784b 12c -11dd 99999
����Դ�룺
?- package?com.qin.sort;??
- ??
- import?java.io.IOException;??
- ??
- import?org.apache.hadoop.conf.Configuration;??
- import?org.apache.hadoop.fs.FileSystem;??
- import?org.apache.hadoop.fs.Path;??
- import?org.apache.hadoop.io.IntWritable;??
- import?org.apache.hadoop.io.LongWritable;??
- import?org.apache.hadoop.io.Text;??
- import?org.apache.hadoop.io.WritableComparator;??
- import?org.apache.hadoop.mapred.JobConf;??
- import?org.apache.hadoop.mapreduce.Job;??
- import?org.apache.hadoop.mapreduce.Mapper;??
- import?org.apache.hadoop.mapreduce.Reducer;??
- import?org.apache.hadoop.mapreduce.lib.input.FileInputFormat;??
- import?org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;??
- ??
- ??
- ???
- /**?
- ?*?���������?
- ?*?MR��ҵ��?
- ?*??
- ?*?QQ��������Ⱥ��324714439?
- ?*?@author?qindongliang?
- ?*??
- ?*??
- ?*?**/??
- public?class?TestSort?{??
- ??????
- ??????
- ????/**?
- ?????*?Map��?
- ?????*??
- ?????*?**/??
- ????private?static?class?SMapper?extends?Mapper<LongWritable,?Text,?IntWritable,?Text>{??
- ??????????
- ????????private?Text?text=new?Text();//���??
- ?????????private?static?final?IntWritable?one=new?IntWritable();??
- ??????????
- ????????@Override??
- ????????protected?void?map(LongWritable?key,?Text?value,Context?context)??
- ????????????????throws?IOException,?InterruptedException?{??
- ????????????String?s=value.toString();??
- ????????????//System.out.println("abc:?"+s);??
- ????????//??if((s.trim().indexOf("?")!=-1)){??
- ?????????????String?ss[]=s.split("?");??
- ?????????????one.set(Integer.parseInt(ss[1].trim()));//??
- ?????????????text.set(ss[0].trim());????
- ?????????????context.write(one,?text);??
- ????????}??
- ????}??
- ??????
- ????/**?
- ?????*?Reduce��?
- ?????*?
- ?????*?*/??
- ?????private?static?class?SReduce?extends?Reducer<IntWritable,?Text,?Text,?IntWritable>{??
- ?????????private?Text?text=new?Text();??
- ?????????@Override??
- ????????protected?void?reduce(IntWritable?arg0,?Iterable<Text>?arg1,Context?context)??
- ????????????????throws?IOException,?InterruptedException?{??
- ???????????????
- ???????????????
- ?????????????for(Text?t:arg1){??
- ?????????????????text.set(t.toString());??
- ??????????????????
- ?????????????????context.write(text,?arg0);??
- ?????????????}???
- ????????}??
- ?????}??
- ???????
- ?????/**?
- ??????*?�������?
- ??????*??
- ??????*?**/??
- ?????private?static?class?SSort?extends?WritableComparator{??
- ???????????
- ?????????public?SSort()?{??
- ?????????????super(IntWritable.class,true);//ע���������??
- ????????}??
- ?????????@Override??
- ????????public?int?compare(byte[]?arg0,?int?arg1,?int?arg2,?byte[]?arg3,??
- ????????????????int?arg4,?int?arg5)?{??
- ????????????/**?
- ?????????????*?����������Ĺؼ�����-���ǽ���?
- ?????????????*?*/??
- ????????????return?-super.compare(arg0,?arg1,?arg2,?arg3,?arg4,?arg5);//ע��ʹ�ø�������ɽ���??
- ????????}??
- ???????????
- ?????????@Override??
- ????????public?int?compare(Object?a,?Object?b)?{??
- ???????
- ????????????return????-super.compare(a,?b);//ע��ʹ�ø�������ɽ���??
- ????????}??
- ???????????
- ???????????
- ?????}??
- ??????
- ?????/**?
- ??????*?main����?
- ??????*?*/??
- ?????public?static?void?main(String[]?args)?throws?Exception{??
- ?????????String?inputPath="hdfs://192.168.75.130:9000/root/output";???????
- ??????????String?outputPath="hdfs://192.168.75.130:9000/root/outputsort";??
- ??????????JobConf?conf=new?JobConf();??
- ????????//Configuration?conf=new?Configuration();??
- ???????????//������ļ���ַǰ�Զ����ӣ�hdfs://master:9000/??
- ?????????//?conf.set("fs.default.name",?"hdfs://192.168.75.130:9000");??
- ??????????//ָ��jobtracker��ip�Ͷ˿ںţ�master��/etc/hosts�п�������??
- ????????//??conf.set("mapred.job.tracker","192.168.75.130:9001");??
- ?????????//?conf.get("mapred.job.tracker");??
- ?????????System.out.println("ģʽ��??"+conf.get("mapred.job.tracker"));??
- ????????//??conf.setJar("tt.jar");??
- ??????????FileSystem??fs=FileSystem.get(conf);??
- ??????????Path?pout=new?Path(outputPath);??
- ??????????if(fs.exists(pout)){??
- ??????????????fs.delete(pout,?true);??
- ??????????????System.out.println("���ڴ�·��,?�Ѿ�ɾ��......");??
- ??????????}?????????????
- ??????????Job?job=new?Job(conf,?"sort123");???
- ??????????job.setJarByClass(TestSort.class);??
- ??????????job.setOutputKeyClass(IntWritable.class);//����map��reduce���K,V������??
- ??????????FileInputFormat.setInputPaths(job,?new?Path(inputPath));??//����·��??
- ??????????FileOutputFormat.setOutputPath(job,?new?Path(outputPath));//���·��????
- ??????????job.setMapperClass(SMapper.class);//map��??
- ??????????job.setReducerClass(SReduce.class);//reduce��??
- ??????????job.setSortComparatorClass(SSort.class);//������??
- //??????????job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);??
- //????????job.setOutputFormatClass(TextOutputFormat.class);??
- ??????????System.exit(job.waitForCompletion(true)???0?:?1);????
- ???????????
- ???????????
- ????}??
- ??????
- ??
- }??
package com.qin.sort;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.io.WritableComparator;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * ��������� * MR��ҵ�� * * QQ��������Ⱥ��324714439 * @author qindongliang * * * **/public class TestSort { /** * Map�� * * **/ private static class SMapper extends Mapper<LongWritable, Text, IntWritable, Text>{ private Text text=new Text();//��� private static final IntWritable one=new IntWritable(); @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String s=value.toString(); //System.out.println("abc: "+s); // if((s.trim().indexOf(" ")!=-1)){ String ss[]=s.split(" "); one.set(Integer.parseInt(ss[1].trim()));// text.set(ss[0].trim()); context.write(one, text); } } /** * Reduce�� * * */ private static class SReduce extends Reducer<IntWritable, Text, Text, IntWritable>{ private Text text=new Text(); @Override protected void reduce(IntWritable arg0, Iterable<Text> arg1,Context context) throws IOException, InterruptedException { for(Text t:arg1){ text.set(t.toString()); context.write(text, arg0); } } } /** * ������� * * **/ private static class SSort extends WritableComparator{ public SSort() { super(IntWritable.class,true);//ע��������� } @Override public int compare(byte[] arg0, int arg1, int arg2, byte[] arg3, int arg4, int arg5) { /** * ����������Ĺؼ�����-���ǽ��� * */ return -super.compare(arg0, arg1, arg2, arg3, arg4, arg5);//ע��ʹ�ø�������ɽ��� } @Override public int compare(Object a, Object b) { return -super.compare(a, b);//ע��ʹ�ø�������ɽ��� } } /** * main���� * */ public static void main(String[] args) throws Exception{ String inputPath="hdfs://192.168.75.130:9000/root/output"; String outputPath="hdfs://192.168.75.130:9000/root/outputsort"; JobConf conf=new JobConf(); //Configuration conf=new Configuration(); //������ļ���ַǰ�Զ����ӣ�hdfs://master:9000/ // conf.set("fs.default.name", "hdfs://192.168.75.130:9000"); //ָ��jobtracker��ip�Ͷ˿ںţ�master��/etc/hosts�п������� // conf.set("mapred.job.tracker","192.168.75.130:9001"); // conf.get("mapred.job.tracker"); System.out.println("ģʽ�� "+conf.get("mapred.job.tracker")); // conf.setJar("tt.jar"); FileSystem fs=FileSystem.get(conf); Path pout=new Path(outputPath); if(fs.exists(pout)){ fs.delete(pout, true); System.out.println("���ڴ�·��, �Ѿ�ɾ��......"); } Job job=new Job(conf, "sort123"); job.setJarByClass(TestSort.class); job.setOutputKeyClass(IntWritable.class);//����map��reduce���K,V������ FileInputFormat.setInputPaths(job, new Path(inputPath)); //����·�� FileOutputFormat.setOutputPath(job, new Path(outputPath));//���·�� job.setMapperClass(SMapper.class);//map�� job.setReducerClass(SReduce.class);//reduce�� job.setSortComparatorClass(SSort.class);//������// job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);// job.setOutputFormatClass(TextOutputFormat.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
��ӡ������£�
?- ģʽ��??local??
- ���ڴ�·��,?�Ѿ�ɾ��......??
- WARN?-?NativeCodeLoader.<clinit>(52)?|?Unable?to?load?native-hadoop?library?for?your?platform...?using?builtin-java?classes?where?applicable??
- WARN?-?JobClient.copyAndConfigureFiles(746)?|?Use?GenericOptionsParser?for?parsing?the?arguments.?Applications?should?implement?Tool?for?the?same.??
- WARN?-?JobClient.copyAndConfigureFiles(870)?|?No?job?jar?file?set.??User?classes?may?not?be?found.?See?JobConf(Class)?or?JobConf#setJar(String).??
- INFO?-?FileInputFormat.listStatus(237)?|?Total?input?paths?to?process?:?1??
- WARN?-?LoadSnappy.<clinit>(46)?|?Snappy?native?library?not?loaded??
- INFO?-?JobClient.monitorAndPrintJob(1380)?|?Running?job:?job_local1242054158_0001??
- INFO?-?LocalJobRunner$Job.run(340)?|?Waiting?for?map?tasks??
- INFO?-?LocalJobRunner$Job$MapTaskRunnable.run(204)?|?Starting?task:?attempt_local1242054158_0001_m_000000_0??
- INFO?-?Task.initialize(534)?|??Using?ResourceCalculatorPlugin?:?null??
- INFO?-?MapTask.runNewMapper(729)?|?Processing?split:?hdfs://192.168.75.130:9000/root/output/sort.txt:0+28??
- INFO?-?MapTask$MapOutputBuffer.<init>(949)?|?io.sort.mb?=?100??
- INFO?-?MapTask$MapOutputBuffer.<init>(961)?|?data?buffer?=?79691776/99614720??
- INFO?-?MapTask$MapOutputBuffer.<init>(962)?|?record?buffer?=?262144/327680??
- INFO?-?MapTask$MapOutputBuffer.flush(1289)?|?Starting?flush?of?map?output??
- INFO?-?MapTask$MapOutputBuffer.sortAndSpill(1471)?|?Finished?spill?0??
- INFO?-?Task.done(858)?|?Task:attempt_local1242054158_0001_m_000000_0?is?done.?And?is?in?the?process?of?commiting??
- INFO?-?LocalJobRunner$Job.statusUpdate(466)?|???
- INFO?-?Task.sendDone(970)?|?Task?'attempt_local1242054158_0001_m_000000_0'?done.??
- INFO?-?LocalJobRunner$Job$MapTaskRunnable.run(229)?|?Finishing?task:?attempt_local1242054158_0001_m_000000_0??
- INFO?-?LocalJobRunner$Job.run(348)?|?Map?task?executor?complete.??
- INFO?-?Task.initialize(534)?|??Using?ResourceCalculatorPlugin?:?null??
- INFO?-?LocalJobRunner$Job.statusUpdate(466)?|???
- INFO?-?Merger$MergeQueue.merge(408)?|?Merging?1?sorted?segments??
- INFO?-?Merger$MergeQueue.merge(491)?|?Down?to?the?last?merge-pass,?with?1?segments?left?of?total?size:?35?bytes??
- INFO?-?LocalJobRunner$Job.statusUpdate(466)?|???
- INFO?-?Task.done(858)?|?Task:attempt_local1242054158_0001_r_000000_0?is?done.?And?is?in?the?process?of?commiting??
- INFO?-?LocalJobRunner$Job.statusUpdate(466)?|???
- INFO?-?Task.commit(1011)?|?Task?attempt_local1242054158_0001_r_000000_0?is?allowed?to?commit?now??
- INFO?-?FileOutputCommitter.commitTask(173)?|?Saved?output?of?task?'attempt_local1242054158_0001_r_000000_0'?to?hdfs://192.168.75.130:9000/root/outputsort??
- INFO?-?LocalJobRunner$Job.statusUpdate(466)?|?reduce?>?reduce??
- INFO?-?Task.sendDone(970)?|?Task?'attempt_local1242054158_0001_r_000000_0'?done.??
- INFO?-?JobClient.monitorAndPrintJob(1393)?|??map?100%?reduce?100%??
- INFO?-?JobClient.monitorAndPrintJob(1448)?|?Job?complete:?job_local1242054158_0001??
- INFO?-?Counters.log(585)?|?Counters:?19??
- INFO?-?Counters.log(587)?|???File?Output?Format?Counters???
- INFO?-?Counters.log(589)?|?????Bytes?Written=26??
- INFO?-?Counters.log(587)?|???File?Input?Format?Counters???
- INFO?-?Counters.log(589)?|?????Bytes?Read=28??
- INFO?-?Counters.log(587)?|???FileSystemCounters??
- INFO?-?Counters.log(589)?|?????FILE_BYTES_READ=393??
- INFO?-?Counters.log(589)?|?????HDFS_BYTES_READ=56??
- INFO?-?Counters.log(589)?|?????FILE_BYTES_WRITTEN=135742??
- INFO?-?Counters.log(589)?|?????HDFS_BYTES_WRITTEN=26??
- INFO?-?Counters.log(587)?|???Map-Reduce?Framework??
- INFO?-?Counters.log(589)?|?????Map?output?materialized?bytes=39??
- INFO?-?Counters.log(589)?|?????Map?input?records=4??
- INFO?-?Counters.log(589)?|?????Reduce?shuffle?bytes=0??
- INFO?-?Counters.log(589)?|?????Spilled?Records=8??
- INFO?-?Counters.log(589)?|?????Map?output?bytes=25??
- INFO?-?Counters.log(589)?|?????Total?committed?heap?usage?(bytes)=455475200??
- INFO?-?Counters.log(589)?|?????Combine?input?records=0??
- INFO?-?Counters.log(589)?|?????SPLIT_RAW_BYTES=112??
- INFO?-?Counters.log(589)?|?????Reduce?input?records=4??
- INFO?-?Counters.log(589)?|?????Reduce?input?groups=4??
- INFO?-?Counters.log(589)?|?????Combine?output?records=0??
- INFO?-?Counters.log(589)?|?????Reduce?output?records=4??
- INFO?-?Counters.log(589)?|?????Map?output?records=4??
ģʽ�� local���ڴ�·��, �Ѿ�ɾ��......WARN - NativeCodeLoader.<clinit>(52) | Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWARN - JobClient.copyAndConfigureFiles(746) | Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.WARN - JobClient.copyAndConfigureFiles(870) | No job jar file set. User classes may not be found. See JobConf(Class) or JobConf#setJar(String).INFO - FileInputFormat.listStatus(237) | Total input paths to process : 1WARN - LoadSnappy.<clinit>(46) | Snappy native library not loadedINFO - JobClient.monitorAndPrintJob(1380) | Running job: job_local1242054158_0001INFO - LocalJobRunner$Job.run(340) | Waiting for map tasksINFO - LocalJobRunner$Job$MapTaskRunnable.run(204) | Starting task: attempt_local1242054158_0001_m_000000_0INFO - Task.initialize(534) | Using ResourceCalculatorPlugin : nullINFO - MapTask.runNewMapper(729) | Processing split: hdfs://192.168.75.130:9000/root/output/sort.txt:0+28INFO - MapTask$MapOutputBuffer.<init>(949) | io.sort.mb = 100INFO - MapTask$MapOutputBuffer.<init>(961) | data buffer = 79691776/99614720INFO - MapTask$MapOutputBuffer.<init>(962) | record buffer = 262144/327680INFO - MapTask$MapOutputBuffer.flush(1289) | Starting flush of map outputINFO - MapTask$MapOutputBuffer.sortAndSpill(1471) | Finished spill 0INFO - Task.done(858) | Task:attempt_local1242054158_0001_m_000000_0 is done. And is in the process of commitingINFO - LocalJobRunner$Job.statusUpdate(466) | INFO - Task.sendDone(970) | Task 'attempt_local1242054158_0001_m_000000_0' done.INFO - LocalJobRunner$Job$MapTaskRunnable.run(229) | Finishing task: attempt_local1242054158_0001_m_000000_0INFO - LocalJobRunner$Job.run(348) | Map task executor complete.INFO - Task.initialize(534) | Using ResourceCalculatorPlugin : nullINFO - LocalJobRunner$Job.statusUpdate(466) | INFO - Merger$MergeQueue.merge(408) | Merging 1 sorted segmentsINFO - Merger$MergeQueue.merge(491) | Down to the last merge-pass, with 1 segments left of total size: 35 bytesINFO - LocalJobRunner$Job.statusUpdate(466) | INFO - Task.done(858) | Task:attempt_local1242054158_0001_r_000000_0 is done. And is in the process of commitingINFO - LocalJobRunner$Job.statusUpdate(466) | INFO - Task.commit(1011) | Task attempt_local1242054158_0001_r_000000_0 is allowed to commit nowINFO - FileOutputCommitter.commitTask(173) | Saved output of task 'attempt_local1242054158_0001_r_000000_0' to hdfs://192.168.75.130:9000/root/outputsortINFO - LocalJobRunner$Job.statusUpdate(466) | reduce > reduceINFO - Task.sendDone(970) | Task 'attempt_local1242054158_0001_r_000000_0' done.INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 100%INFO - JobClient.monitorAndPrintJob(1448) | Job complete: job_local1242054158_0001INFO - Counters.log(585) | Counters: 19INFO - Counters.log(587) | File Output Format Counters INFO - Counters.log(589) | Bytes Written=26INFO - Counters.log(587) | File Input Format Counters INFO - Counters.log(589) | Bytes Read=28INFO - Counters.log(587) | FileSystemCountersINFO - Counters.log(589) | FILE_BYTES_READ=393INFO - Counters.log(589) | HDFS_BYTES_READ=56INFO - Counters.log(589) | FILE_BYTES_WRITTEN=135742INFO - Counters.log(589) | HDFS_BYTES_WRITTEN=26INFO - Counters.log(587) | Map-Reduce FrameworkINFO - Counters.log(589) | Map output materialized bytes=39INFO - Counters.log(589) | Map input records=4INFO - Counters.log(589) | Reduce shuffle bytes=0INFO - Counters.log(589) | Spilled Records=8INFO - Counters.log(589) | Map output bytes=25INFO - Counters.log(589) | Total committed heap usage (bytes)=455475200INFO - Counters.log(589) | Combine input records=0INFO - Counters.log(589) | SPLIT_RAW_BYTES=112INFO - Counters.log(589) | Reduce input records=4INFO - Counters.log(589) | Reduce input groups=4INFO - Counters.log(589) | Combine output records=0INFO - Counters.log(589) | Reduce output records=4INFO - Counters.log(589) | Map output records=4
����������:
?- dd??99999??
- a???784??
- b???12??
- c???-11??
dd 99999a 784b 12c -11
����ģʽ����ͨ��֮�����ǾͿ��Կ��Dz���hadoop��Ⱥ��ģʽ���ܣ���ʱ����2�ַ�ʽ���������������£���һ�ǣ�Ϊ�˷��㽫������Ŀ���һ��jar�����ϴ���Linux�ϣ�Ȼ��ִ��shell���
bin/hadoop jar tt.jar com.qin.sort.TestSort
�����в��ԣ�ע�⣬ɢ����Ϊ�˷��㣬·����д���ڳ����������Ժ��治�����룬��������·������ʽ�Ŀ�����Ϊ������ԣ�һ���ͨ���ⲿ������ָ����������·����
�ڶ��ַ�ʽ��Ҳ�ȽϷ��㣬ֱ����eclipse���ύ��hadoop��Ⱥ��ҵ�У�������ʹ��ʹ��eclipse���ύ��ҵ��������Ҫ��������Ŀ���һ��jar����ֻ������ʱ��eclipse�������ύ��ҵ�ģ��������ǾͿ���Winƽ̨��ֱ���ύ����hadoop��ҵ�ˣ����������Ļ���ʹ���ϴ�jar���ķ�ʽ�����ڰ�������Ŀ���һ��jar����ɢ���ں�����ϴ�һ��ant�ű���ֱ��ִ�����Ϳ����ˣ������Ϳ�����������ϵ�������һ�𣬰�һ������Ŀ��Ϊһ�����壬��hadoop�ϣ�ֻ��Ҫָ��jar��ָ�����ȫ���ƣ������룬���·�����ɡ�ant�Ľű��������£�
?- <project?name="${component.name}"?basedir="."?default="jar">??
- ????<property?environment="env"/>??
- ????<!--?
- ????<property?name="hadoop.home"?value="${env.HADOOP_HOME}"/>?
- ????-->??
- ????<property?name="hadoop.home"?value="D:/hadoop-1.2.0"/>??
- ????<!--?ָ��jar��������?-->??
- ????<property?name="jar.name"?value="tt.jar"/>??
- ????<path?id="project.classpath">??
- ????????<fileset?dir="lib">??
- ????????????<include?name="*.jar"?/>??
- ????????</fileset>??
- ????????<fileset?dir="${hadoop.home}">??
- ????????????<include?name="**/*.jar"?/>??
- ????????</fileset>??
- ????</path>??
- ????<target?name="clean"?>??
- ????????<delete?dir="bin"?failonerror="false"?/>??
- ????????<mkdir?dir="bin"/>??
- ????</target>???
- ????<target?name="build"?depends="clean">??
- ????????<echo?message="${ant.project.name}:?${ant.file}"/>??
- ????????<javac?destdir="bin"?encoding="utf-8"?debug="true"?includeantruntime="false"?debuglevel="lines,vars,source">??
- ????????????<src?path="src"/>??
- ????????????<exclude?name="**/.svn"?/>??
- ????????????<classpath?refid="project.classpath"/>??
- ????????</javac>??
- ????????<copy?todir="bin">??
- ????????????<fileset?dir="src">??
- ????????????????<include?name="*config*"/>??
- ????????????</fileset>??
- ????????</copy>??
- ????</target>??
- ??????
- ????<target?name="jar"?depends="build">??
- ????????<copy?todir="bin/lib">??
- ????????????<fileset?dir="lib">??
- ????????????????<include?name="**/*.*"/>??
- ????????????</fileset>??
- ????????</copy>??
- ??????????
- ????????<path?id="lib-classpath">??
- ????????????<fileset?dir="lib"?includes="**/*.jar"?/>??
- ????????</path>??
- ??????????
- ????????<pathconvert?property="my.classpath"?pathsep="?"?>??
- ????????????<mapper>??
- ????????????????<chainedmapper>??
- ????????????????????<!--?�Ƴ�����·��?-->??
- ????????????????????<flattenmapper?/>??
- ????????????????????<!--?����libǰ?-->??
- ????????????????????<globmapper?from="*"?to="lib/*"?/>??
- ???????????????</chainedmapper>??
- ?????????????</mapper>??
- ?????????????<path?refid="lib-classpath"?/>??
- ????????</pathconvert>??
- ??????????
- ????????<jar?basedir="bin"?destfile="${jar.name}"?>??
- ????????????<include?name="**/*"/>??
- ????????????<!--?define?MANIFEST.MF?-->??
- ????????????<manifest>??
- ????????????????<attribute?name="Class-Path"?value="${my.classpath}"?/>??
- ????????????</manifest>??
- ????????</jar>??
- ????</target>??
- </project>??
<project name="${component.name}" basedir="." default="jar"> <property environment="env"/> <!-- <property name="hadoop.home" value="${env.HADOOP_HOME}"/> --> <property name="hadoop.home" value="D:/hadoop-1.2.0"/> <!-- ָ��jar�������� --> <property name="jar.name" value="tt.jar"/> <path id="project.classpath"> <fileset dir="lib"> <include name="*.jar" /> </fileset> <fileset dir="${hadoop.home}"> <include name="**/*.jar" /> </fileset> </path> <target name="clean" > <delete dir="bin" failonerror="false" /> <mkdir dir="bin"/> </target> <target name="build" depends="clean"> <echo message="${ant.project.name}: ${ant.file}"/> <javac destdir="bin" encoding="utf-8" debug="true" includeantruntime="false" debuglevel="lines,vars,source"> <src path="src"/> <exclude name="**/.svn" /> <classpath refid="project.classpath"/> </javac> <copy todir="bin"> <fileset dir="src"> <include name="*config*"/> </fileset> </copy> </target> <target name="jar" depends="build"> <copy todir="bin/lib"> <fileset dir="lib"> <include name="**/*.*"/> </fileset> </copy> <path id="lib-classpath"> <fileset dir="lib" includes="**/*.jar" /> </path> <pathconvert property="my.classpath" pathsep=" " > <mapper> <chainedmapper> <!-- �Ƴ�����·�� --> <flattenmapper /> <!-- ����libǰ --> <globmapper from="*" to="lib/*" /> </chainedmapper> </mapper> <path refid="lib-classpath" /> </pathconvert> <jar basedir="bin" destfile="${jar.name}" > <include name="**/*"/> <!-- define MANIFEST.MF --> <manifest> <attribute name="Class-Path" value="${my.classpath}" /> </manifest> </jar> </target></project>
������������ant�ű�֮�����ǵ���Ŀ�ͻᱻ���һ��jar������ͼ���£� 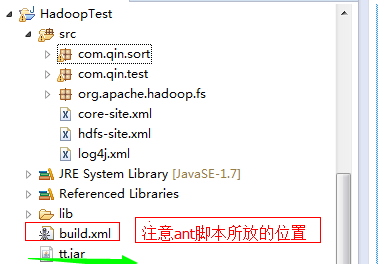
jar������֮�������Ȳ�����eclipse����ΰ���ҵ�ύ��hadoop��Ⱥ�ϣ�ֻҪ��main����Ĵ��룬�ԼӸĶ����ɣ�
?- ?/**?
- ??????*?main����?
- ??????*?*/??
- ?????public?static?void?main(String[]?args)?throws?Exception{??
- ?????????String?inputPath="hdfs://192.168.75.130:9000/root/output";???????
- ??????????String?outputPath="hdfs://192.168.75.130:9000/root/outputsort";??
- ??????????JobConf?conf=new?JobConf();??
- ?????????//Configuration?conf=new?Configuration();//����ʹ�����conf������Localģʽ??
- ?????????//�����srcĿ¼���У�mapred-site.xml�ļ����Ͳ�Ҫ���д���??
- ?????????//ע����д���Ҳ���ڷ�Localģʽ�²�ʹ��??
- ?????????conf.set("mapred.job.tracker","192.168.75.130:9001");??
- ?????????//?conf.get("mapred.job.tracker");??
- ?????????System.out.println("ģʽ��??"+conf.get("mapred.job.tracker"));??
- ?????????//?conf.setJar("tt.jar");?��Localģʽ��ʹ��??
- ??????????FileSystem??fs=FileSystem.get(conf);??
- ??????????Path?pout=new?Path(outputPath);??
- ??????????if(fs.exists(pout)){??
- ??????????????fs.delete(pout,?true);??
- ??????????????System.out.println("���ڴ�·��,?�Ѿ�ɾ��......");??
- ??????????}?????????????
- ??????????Job?job=new?Job(conf,?"sort123");???
- ??????????job.setJarByClass(TestSort.class);??
- ??????????job.setOutputKeyClass(IntWritable.class);//����map��reduce���K,V������??
- ??????????FileInputFormat.setInputPaths(job,?new?Path(inputPath));??//����·��??
- ??????????FileOutputFormat.setOutputPath(job,?new?Path(outputPath));//���·��????
- ??????????job.setMapperClass(SMapper.class);//map��??
- ??????????job.setReducerClass(SReduce.class);//reduce��??
- ??????????job.setSortComparatorClass(SSort.class);//������??
- //??????????job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);??
- //????????job.setOutputFormatClass(TextOutputFormat.class);??
- ??????????System.exit(job.waitForCompletion(true)???0?:?1);????
- ???????????
- ???????????
- ????}??
/** * main���� * */ public static void main(String[] args) throws Exception{ String inputPath="hdfs://192.168.75.130:9000/root/output"; String outputPath="hdfs://192.168.75.130:9000/root/outputsort"; JobConf conf=new JobConf(); //Configuration conf=new Configuration();//����ʹ�����conf������Localģʽ //�����srcĿ¼���У�mapred-site.xml�ļ����Ͳ�Ҫ���д��� //ע����д���Ҳ���ڷ�Localģʽ�²�ʹ�� conf.set("mapred.job.tracker","192.168.75.130:9001"); // conf.get("mapred.job.tracker"); System.out.println("ģʽ�� "+conf.get("mapred.job.tracker")); // conf.setJar("tt.jar"); ��Localģʽ��ʹ�� FileSystem fs=FileSystem.get(conf); Path pout=new Path(outputPath); if(fs.exists(pout)){ fs.delete(pout, true); System.out.println("���ڴ�·��, �Ѿ�ɾ��......"); } Job job=new Job(conf, "sort123"); job.setJarByClass(TestSort.class); job.setOutputKeyClass(IntWritable.class);//����map��reduce���K,V������ FileInputFormat.setInputPaths(job, new Path(inputPath)); //����·�� FileOutputFormat.setOutputPath(job, new Path(outputPath));//���·�� job.setMapperClass(SMapper.class);//map�� job.setReducerClass(SReduce.class);//reduce�� job.setSortComparatorClass(SSort.class);//������// job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);// job.setOutputFormatClass(TextOutputFormat.class); System.exit(job.waitForCompletion(true) ? 0 : 1); }
���г�����������£�
?- ģʽ��??192.168.75.130:9001??
- ���ڴ�·��,?�Ѿ�ɾ��......??
- WARN?-?JobClient.copyAndConfigureFiles(746)?|?Use?GenericOptionsParser?for?parsing?the?arguments.?Applications?should?implement?Tool?for?the?same.??
- INFO?-?FileInputFormat.listStatus(237)?|?Total?input?paths?to?process?:?1??
- WARN?-?NativeCodeLoader.<clinit>(52)?|?Unable?to?load?native-hadoop?library?for?your?platform...?using?builtin-java?classes?where?applicable??
- WARN?-?LoadSnappy.<clinit>(46)?|?Snappy?native?library?not?loaded??
- INFO?-?JobClient.monitorAndPrintJob(1380)?|?Running?job:?job_201403252058_0035??
- INFO?-?JobClient.monitorAndPrintJob(1393)?|??map?0%?reduce?0%??
- INFO?-?JobClient.monitorAndPrintJob(1393)?|??map?100%?reduce?0%??
- INFO?-?JobClient.monitorAndPrintJob(1393)?|??map?100%?reduce?33%??
- INFO?-?JobClient.monitorAndPrintJob(1393)?|??map?100%?reduce?100%??
- INFO?-?JobClient.monitorAndPrintJob(1448)?|?Job?complete:?job_201403252058_0035??
- INFO?-?Counters.log(585)?|?Counters:?29??
- INFO?-?Counters.log(587)?|???Job?Counters???
- INFO?-?Counters.log(589)?|?????Launched?reduce?tasks=1??
- INFO?-?Counters.log(589)?|?????SLOTS_MILLIS_MAPS=8498??
- INFO?-?Counters.log(589)?|?????Total?time?spent?by?all?reduces?waiting?after?reserving?slots?(ms)=0??
- INFO?-?Counters.log(589)?|?????Total?time?spent?by?all?maps?waiting?after?reserving?slots?(ms)=0??
- INFO?-?Counters.log(589)?|?????Launched?map?tasks=1??
- INFO?-?Counters.log(589)?|?????Data-local?map?tasks=1??
- INFO?-?Counters.log(589)?|?????SLOTS_MILLIS_REDUCES=9667??
- INFO?-?Counters.log(587)?|???File?Output?Format?Counters???
- INFO?-?Counters.log(589)?|?????Bytes?Written=26??
- INFO?-?Counters.log(587)?|???FileSystemCounters??
- INFO?-?Counters.log(589)?|?????FILE_BYTES_READ=39??
- INFO?-?Counters.log(589)?|?????HDFS_BYTES_READ=140??
- INFO?-?Counters.log(589)?|?????FILE_BYTES_WRITTEN=117654??
- INFO?-?Counters.log(589)?|?????HDFS_BYTES_WRITTEN=26??
- INFO?-?Counters.log(587)?|???File?Input?Format?Counters???
- INFO?-?Counters.log(589)?|?????Bytes?Read=28??
- INFO?-?Counters.log(587)?|???Map-Reduce?Framework??
- INFO?-?Counters.log(589)?|?????Map?output?materialized?bytes=39??
- INFO?-?Counters.log(589)?|?????Map?input?records=4??
- INFO?-?Counters.log(589)?|?????Reduce?shuffle?bytes=39??
- INFO?-?Counters.log(589)?|?????Spilled?Records=8??
- INFO?-?Counters.log(589)?|?????Map?output?bytes=25??
- INFO?-?Counters.log(589)?|?????Total?committed?heap?usage?(bytes)=176033792??
- INFO?-?Counters.log(589)?|?????CPU?time?spent?(ms)=1140??
- INFO?-?Counters.log(589)?|?????Combine?input?records=0??
- INFO?-?Counters.log(589)?|?????SPLIT_RAW_BYTES=112??
- INFO?-?Counters.log(589)?|?????Reduce?input?records=4??
- INFO?-?Counters.log(589)?|?????Reduce?input?groups=4??
- INFO?-?Counters.log(589)?|?????Combine?output?records=0??
- INFO?-?Counters.log(589)?|?????Physical?memory?(bytes)?snapshot=259264512??
- INFO?-?Counters.log(589)?|?????Reduce?output?records=4??
- INFO?-?Counters.log(589)?|?????Virtual?memory?(bytes)?snapshot=1460555776??
- INFO?-?Counters.log(589)?|?????Map?output?records=4??
ģʽ�� 192.168.75.130:9001���ڴ�·��, �Ѿ�ɾ��......WARN - JobClient.copyAndConfigureFiles(746) | Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.INFO - FileInputFormat.listStatus(237) | Total input paths to process : 1WARN - NativeCodeLoader.<clinit>(52) | Unable to load native-hadoop library for your platform... using builtin-java classes where applicableWARN - LoadSnappy.<clinit>(46) | Snappy native library not loadedINFO - JobClient.monitorAndPrintJob(1380) | Running job: job_201403252058_0035INFO - JobClient.monitorAndPrintJob(1393) | map 0% reduce 0%INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 0%INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 33%INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 100%INFO - JobClient.monitorAndPrintJob(1448) | Job complete: job_201403252058_0035INFO - Counters.log(585) | Counters: 29INFO - Counters.log(587) | Job Counters INFO - Counters.log(589) | Launched reduce tasks=1INFO - Counters.log(589) | SLOTS_MILLIS_MAPS=8498INFO - Counters.log(589) | Total time spent by all reduces waiting after reserving slots (ms)=0INFO - Counters.log(589) | Total time spent by all maps waiting after reserving slots (ms)=0INFO - Counters.log(589) | Launched map tasks=1INFO - Counters.log(589) | Data-local map tasks=1INFO - Counters.log(589) | SLOTS_MILLIS_REDUCES=9667INFO - Counters.log(587) | File Output Format Counters INFO - Counters.log(589) | Bytes Written=26INFO - Counters.log(587) | FileSystemCountersINFO - Counters.log(589) | FILE_BYTES_READ=39INFO - Counters.log(589) | HDFS_BYTES_READ=140INFO - Counters.log(589) | FILE_BYTES_WRITTEN=117654INFO - Counters.log(589) | HDFS_BYTES_WRITTEN=26INFO - Counters.log(587) | File Input Format Counters INFO - Counters.log(589) | Bytes Read=28INFO - Counters.log(587) | Map-Reduce FrameworkINFO - Counters.log(589) | Map output materialized bytes=39INFO - Counters.log(589) | Map input records=4INFO - Counters.log(589) | Reduce shuffle bytes=39INFO - Counters.log(589) | Spilled Records=8INFO - Counters.log(589) | Map output bytes=25INFO - Counters.log(589) | Total committed heap usage (bytes)=176033792INFO - Counters.log(589) | CPU time spent (ms)=1140INFO - Counters.log(589) | Combine input records=0INFO - Counters.log(589) | SPLIT_RAW_BYTES=112INFO - Counters.log(589) | Reduce input records=4INFO - Counters.log(589) | Reduce input groups=4INFO - Counters.log(589) | Combine output records=0INFO - Counters.log(589) | Physical memory (bytes) snapshot=259264512INFO - Counters.log(589) | Reduce output records=4INFO - Counters.log(589) | Virtual memory (bytes) snapshot=1460555776INFO - Counters.log(589) | Map output records=4
���ǿ��Կ���������������������������£�
?- dd??99999??
- a???784??
- b???12??
- c???-11??
dd 99999a 784b 12c -11
�����localģʽ�µ�һ��������һ����localģʽ��ͬ�ĵط��ǣ����ǿ�����http://192.168.75.130:50030/jobtracker.jsp������ҳ�����ҵ��ղ�ִ�е�����״������һ����Localģʽ�����г�����û�еġ�/size] 
[size=large]���ɢ���������£���ν�jar�����ϴ���Linux�ύ��ҵ��hadoop��Ⱥ�ϡ��ղţ������Ѿ���jar������ˣ�����ֻ���ϴ���linux�ϼ��ɣ� 
Ȼ��ʼִ��shell�������г���

���ˣ������Ѿ�������ִ�гɹ������һ����Ҫע����ǣ���ִ����������ʱ����������쳣��
?- java.lang.Exception:?java.io.IOException:?Type?mismatch?in?key?from?map:?expected?org.apache.hadoop.io.LongWritable,?recieved?org.apache.hadoop.io.IntWritable??
- ????at?org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:354)??
- Caused?by:?java.io.IOException:?Type?mismatch?in?key?from?map:?expected?org.apache.hadoop.io.LongWritable,?recieved?org.apache.hadoop.io.IntWritable??
- ????at?org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1019)??
- ????at?org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690)??
- ????at?org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80)??
- ????at?com.qin.sort.TestSort$SMapper.map(TestSort.java:51)??
- ????at?com.qin.sort.TestSort$SMapper.map(TestSort.java:1)??
- ????at?org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145)??
- ????at?org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764)??
- ????at?org.apache.hadoop.mapred.MapTask.run(MapTask.java:364)??
- ????at?org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:223)??
- ????at?java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)??
- ????at?java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334)??
- ????at?java.util.concurrent.FutureTask.run(FutureTask.java:166)??
- ????at?java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110)??
- ????at?java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603)??
- ????at?java.lang.Thread.run(Thread.java:722)??
java.lang.Exception: java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.LongWritable, recieved org.apache.hadoop.io.IntWritable at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:354)Caused by: java.io.IOException: Type mismatch in key from map: expected org.apache.hadoop.io.LongWritable, recieved org.apache.hadoop.io.IntWritable at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.collect(MapTask.java:1019) at org.apache.hadoop.mapred.MapTask$NewOutputCollector.write(MapTask.java:690) at org.apache.hadoop.mapreduce.TaskInputOutputContext.write(TaskInputOutputContext.java:80) at com.qin.sort.TestSort$SMapper.map(TestSort.java:51) at com.qin.sort.TestSort$SMapper.map(TestSort.java:1) at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:145) at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:764) at org.apache.hadoop.mapred.MapTask.run(MapTask.java:364) at org.apache.hadoop.mapred.LocalJobRunner$Job$MapTaskRunnable.run(LocalJobRunner.java:223) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471) at java.util.concurrent.FutureTask$Sync.innerRun(FutureTask.java:334) at java.util.concurrent.FutureTask.run(FutureTask.java:166) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1110) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:603) at java.lang.Thread.run(Thread.java:722)
����쳣�ij��֣��������Ϊ������û��ָ�������Key������Value������ָ�������Ͳ�һ�£����£�����ֻ��Ҫ��ȷ�����������Key����Value�����ͼ���.
?- job.setOutputKeyClass(IntWritable.class);??
- ???????????job.setOutputValueClass(Text.class);??
job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class);
������Ϳ����������������ˡ�