这篇bolg讲一下,IDE开发的spark程序如何提交到集群上运行。
首先保证你的集群是运行成功的,集群搭建可以参考http://kevin12.iteye.com/blog/2273556
开发集群测试的spark wordcount程序;
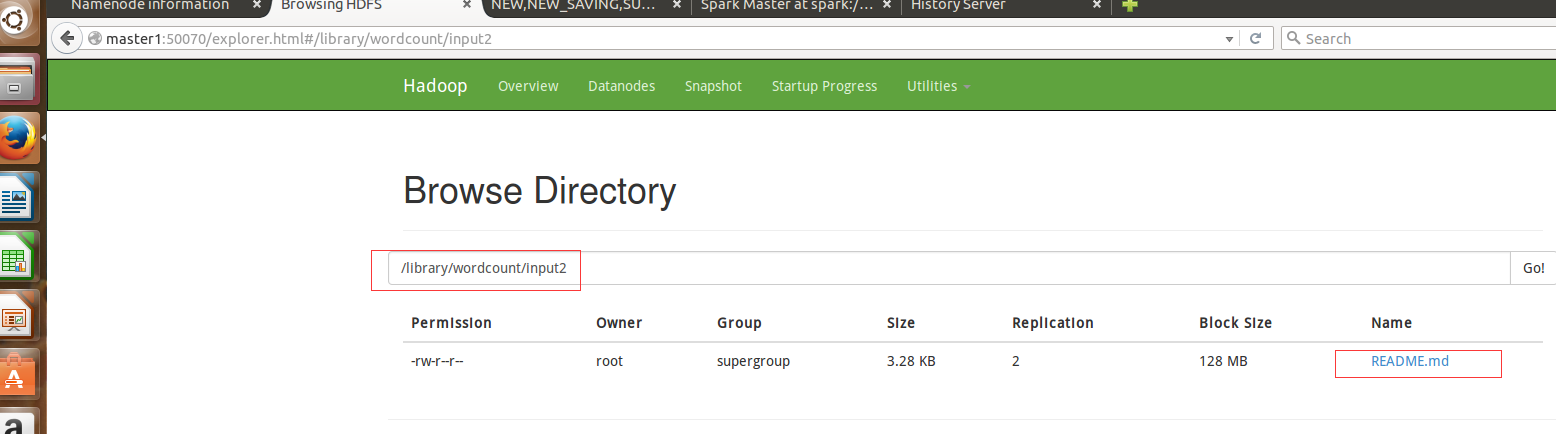
1.hdfs数据准备.
先将README.md文件上传到hdfs上的/library/wordcount/input2目录
root@master1:/usr/local/hadoop/hadoop-2.6.0/sbin# hdfs dfs -mkdir /library/wordcount/input2
root@master1:/usr/local/hadoop/hadoop-2.6.0/sbin# hdfs dfs -put /usr/local/tools/README.md /library/wordcount/input2
查看一下确保文件已经上传到hdfs上。
程序代码:
package com.imf.sparkimport org.apache.spark.SparkConfimport org.apache.spark.SparkContext/** * 用户scala开发集群测试的spark wordcount程序 */object WordCount_Cluster { def main(args: Array[String]): Unit = { /** * 1.创建Spark的配置对象SparkConf,设置Spark程序的运行时的配置信息, * 例如:通过setMaster来设置程序要链接的Spark集群的Master的URL,如果设置为local, * 则代表Spark程序在本地运行,特别适合于机器配置条件非常差的情况。 */ //创建SparkConf对象 val conf = new SparkConf() //设置应用程序名称,在程序运行的监控界面可以看到名称 conf.setAppName("My First Spark App!") /** * 2.创建SparkContext对象 * SparkContext是spark程序所有功能的唯一入口,无论是采用Scala,java,python,R等都必须有一个SprakContext * SparkContext核心作用:初始化spark应用程序运行所需要的核心组件,包括DAGScheduler,TaskScheduler,SchedulerBackend * 同时还会负责Spark程序往Master注册程序等; * SparkContext是整个应用程序中最为至关重要的一个对象; */ //通过创建SparkContext对象,通过传入SparkConf实例定制Spark运行的具体参数和配置信息 val sc = new SparkContext(conf) /** * 3.根据具体数据的来源(HDFS,HBase,Local,FS,DB,S3等)通过SparkContext来创建RDD; * RDD的创建基本有三种方式:根据外部的数据来源(例如HDFS)、根据Scala集合、由其他的RDD操作; * 数据会被RDD划分成为一系列的Partitions,分配到每个Partition的数据属于一个Task的处理范畴; */ //读取hdfs文件内容并切分成Pratitions //val lines = sc.textFile("hdfs://master1:9000/library/wordcount/input2") val lines = sc.textFile("/library/wordcount/input2")//这里不设置并行度是spark有自己的算法,暂时不去考虑 /** * 4.对初始的RDD进行Transformation级别的处理,例如map,filter等高阶函数的变成,来进行具体的数据计算 * 4.1.将每一行的字符串拆分成单个单词 */ //对每一行的字符串进行拆分并把所有行的拆分结果通过flat合并成一个大的集合 val words = lines.flatMap { line => line.split(" ") } /** * 4.2.在单词拆分的基础上对每个单词实例计数为1,也就是word => (word,1) */ val pairs = words.map{word =>(word,1)} /** * 4.3.在每个单词实例计数为1基础上统计每个单词在文件中出现的总次数 */ //对相同的key进行value的累积(包括Local和Reducer级别同时Reduce) val wordCounts = pairs.reduceByKey(_+_) //打印输出 wordCounts.collect.foreach(pair => println(pair._1+":"+pair._2)) sc.stop() }}2.打包程序
将程序打包成jar文件,并将jar文件复制到虚拟机的master1上的/usr/local/sparkApps目录下。
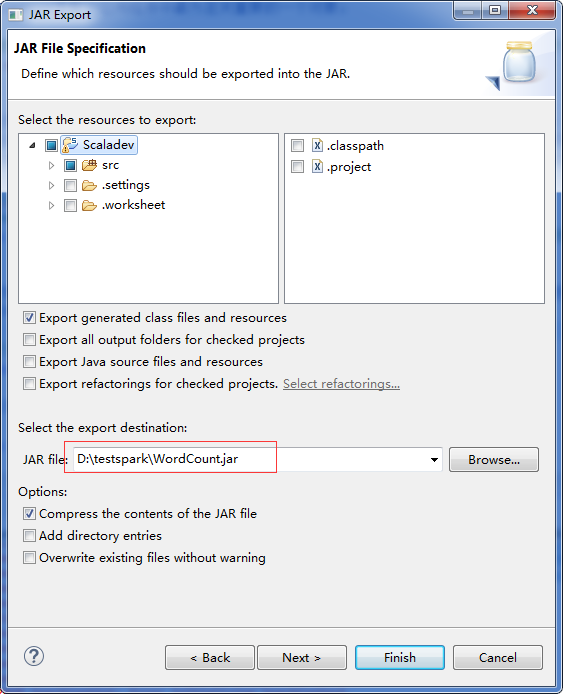
3.提交应用程序到集群中。
可以参考官方文档http://spark.apache.org/docs/latest/submitting-applications.html
第一次用的是下面的命令,结果运行不了,提示信息和命令如下:原因没有提交到集群中。
root@master1:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin# ./spark-submit \> --class com.imf.spark.WordCount_Cluster \> --master master spark://master1:7077 \> /usr/local/sparkApps/WordCount.jarError: Master must start with yarn, spark, mesos, or localRun with --help for usage help or --verbose for debug output
第二次修改命令如下,运行正常:
./spark-submit \--class com.imf.spark.WordCount_Cluster \--master yarn \/usr/local/sparkApps/WordCount.jar
运行结果如下:
root@master1:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin# ./spark-submit \> --class com.imf.spark.WordCount_Cluster \> --master yarn \> /usr/local/sparkApps/WordCount.jar16/01/27 07:21:55 INFO spark.SparkContext: Running Spark version 1.6.016/01/27 07:21:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable16/01/27 07:21:56 INFO spark.SecurityManager: Changing view acls to: root16/01/27 07:21:56 INFO spark.SecurityManager: Changing modify acls to: root16/01/27 07:21:56 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)16/01/27 07:21:57 INFO util.Utils: Successfully started service 'sparkDriver' on port 33500.16/01/27 07:21:57 INFO slf4j.Slf4jLogger: Slf4jLogger started16/01/27 07:21:57 INFO Remoting: Starting remoting16/01/27 07:21:58 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@192.168.112.130:40488]16/01/27 07:21:58 INFO util.Utils: Successfully started service 'sparkDriverActorSystem' on port 40488.16/01/27 07:21:58 INFO spark.SparkEnv: Registering MapOutputTracker16/01/27 07:21:58 INFO spark.SparkEnv: Registering BlockManagerMaster16/01/27 07:21:58 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-298b85db-a14e-448b-bf12-a76e7f9d3e6116/01/27 07:21:58 INFO storage.MemoryStore: MemoryStore started with capacity 517.4 MB16/01/27 07:21:59 INFO spark.SparkEnv: Registering OutputCommitCoordinator16/01/27 07:21:59 INFO server.Server: jetty-8.y.z-SNAPSHOT16/01/27 07:21:59 INFO server.AbstractConnector: Started SelectChannelConnector@0.0.0.0:404016/01/27 07:21:59 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.16/01/27 07:21:59 INFO ui.SparkUI: Started SparkUI at http://192.168.112.130:404016/01/27 07:21:59 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-1273b284-86a3-45a5-ab5f-7996b7f78a5f/httpd-c0ad1a3a-48fc-4aef-8ac1-ddc28159fe2c16/01/27 07:21:59 INFO spark.HttpServer: Starting HTTP Server16/01/27 07:21:59 INFO server.Server: jetty-8.y.z-SNAPSHOT16/01/27 07:21:59 INFO server.AbstractConnector: Started SocketConnector@0.0.0.0:4172216/01/27 07:21:59 INFO util.Utils: Successfully started service 'HTTP file server' on port 41722.16/01/27 07:21:59 INFO spark.SparkContext: Added JAR file:/usr/local/sparkApps/WordCount.jar at http://192.168.112.130:41722/jars/WordCount.jar with timestamp 145385051974916/01/27 07:22:00 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.112.130:803216/01/27 07:22:01 INFO yarn.Client: Requesting a new application from cluster with 3 NodeManagers16/01/27 07:22:01 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container)16/01/27 07:22:01 INFO yarn.Client: Will allocate AM container, with 896 MB memory including 384 MB overhead16/01/27 07:22:01 INFO yarn.Client: Setting up container launch context for our AM16/01/27 07:22:01 INFO yarn.Client: Setting up the launch environment for our AM container16/01/27 07:22:01 INFO yarn.Client: Preparing resources for our AM container16/01/27 07:22:02 INFO yarn.Client: Uploading resource file:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/lib/spark-assembly-1.6.0-hadoop2.6.0.jar -> hdfs://master1:9000/user/root/.sparkStaging/application_1453847555417_0001/spark-assembly-1.6.0-hadoop2.6.0.jar16/01/27 07:22:11 INFO yarn.Client: Uploading resource file:/tmp/spark-1273b284-86a3-45a5-ab5f-7996b7f78a5f/__spark_conf__2067657392446030944.zip -> hdfs://master1:9000/user/root/.sparkStaging/application_1453847555417_0001/__spark_conf__2067657392446030944.zip16/01/27 07:22:11 INFO spark.SecurityManager: Changing view acls to: root16/01/27 07:22:11 INFO spark.SecurityManager: Changing modify acls to: root16/01/27 07:22:11 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(root); users with modify permissions: Set(root)16/01/27 07:22:12 INFO yarn.Client: Submitting application 1 to ResourceManager16/01/27 07:22:12 INFO impl.YarnClientImpl: Submitted application application_1453847555417_000116/01/27 07:22:14 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:14 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: default start time: 1453850532502 final status: UNDEFINED tracking URL: http://master1:8088/proxy/application_1453847555417_0001/ user: root16/01/27 07:22:15 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:16 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:17 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:18 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:19 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:20 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:21 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:22 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:23 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:24 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:25 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:26 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:27 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:28 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:29 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:30 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:31 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:32 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:32 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(null)16/01/27 07:22:32 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> master1, PROXY_URI_BASES -> http://master1:8088/proxy/application_1453847555417_0001), /proxy/application_1453847555417_000116/01/27 07:22:32 INFO ui.JettyUtils: Adding filter: org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter16/01/27 07:22:33 INFO yarn.Client: Application report for application_1453847555417_0001 (state: ACCEPTED)16/01/27 07:22:34 INFO yarn.Client: Application report for application_1453847555417_0001 (state: RUNNING)16/01/27 07:22:34 INFO yarn.Client: client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.112.132 ApplicationMaster RPC port: 0 queue: default start time: 1453850532502 final status: UNDEFINED tracking URL: http://master1:8088/proxy/application_1453847555417_0001/ user: root16/01/27 07:22:34 INFO cluster.YarnClientSchedulerBackend: Application application_1453847555417_0001 has started running.16/01/27 07:22:34 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 33873.16/01/27 07:22:34 INFO netty.NettyBlockTransferService: Server created on 3387316/01/27 07:22:34 INFO storage.BlockManagerMaster: Trying to register BlockManager16/01/27 07:22:34 INFO storage.BlockManagerMasterEndpoint: Registering block manager 192.168.112.130:33873 with 517.4 MB RAM, BlockManagerId(driver, 192.168.112.130, 33873)16/01/27 07:22:34 INFO storage.BlockManagerMaster: Registered BlockManager16/01/27 07:22:37 INFO scheduler.EventLoggingListener: Logging events to hdfs://master1:9000/historyserverforSpark/application_1453847555417_000116/01/27 07:22:37 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000(ms)16/01/27 07:22:46 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 212.9 KB, free 212.9 KB)16/01/27 07:22:46 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 19.6 KB, free 232.4 KB)16/01/27 07:22:46 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on 192.168.112.130:33873 (size: 19.6 KB, free: 517.4 MB)16/01/27 07:22:46 INFO spark.SparkContext: Created broadcast 0 from textFile at WordCount_Cluster.scala:3616/01/27 07:22:49 INFO mapred.FileInputFormat: Total input paths to process : 116/01/27 07:22:50 INFO spark.SparkContext: Starting job: collect at WordCount_Cluster.scala:5516/01/27 07:22:51 INFO scheduler.DAGScheduler: Registering RDD 3 (map at WordCount_Cluster.scala:47)16/01/27 07:22:51 INFO scheduler.DAGScheduler: Got job 0 (collect at WordCount_Cluster.scala:55) with 2 output partitions16/01/27 07:22:51 INFO scheduler.DAGScheduler: Final stage: ResultStage 1 (collect at WordCount_Cluster.scala:55)16/01/27 07:22:51 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)16/01/27 07:22:51 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 0)16/01/27 07:22:51 INFO scheduler.DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount_Cluster.scala:47), which has no missing parents16/01/27 07:22:52 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.1 KB, free 236.5 KB)16/01/27 07:22:52 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.3 KB, free 238.8 KB)16/01/27 07:22:52 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on 192.168.112.130:33873 (size: 2.3 KB, free: 517.4 MB)16/01/27 07:22:52 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:100616/01/27 07:22:52 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[3] at map at WordCount_Cluster.scala:47)16/01/27 07:22:52 INFO cluster.YarnScheduler: Adding task set 0.0 with 2 tasks16/01/27 07:23:08 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources16/01/27 07:23:22 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (worker3:56136) with ID 216/01/27 07:23:23 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, worker3, partition 0,NODE_LOCAL, 2202 bytes)16/01/27 07:23:23 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources16/01/27 07:23:24 INFO storage.BlockManagerMasterEndpoint: Registering block manager worker3:41970 with 517.4 MB RAM, BlockManagerId(2, worker3, 41970)16/01/27 07:23:33 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on worker3:41970 (size: 2.3 KB, free: 517.4 MB)16/01/27 07:23:37 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on worker3:41970 (size: 19.6 KB, free: 517.4 MB)16/01/27 07:23:39 INFO cluster.YarnClientSchedulerBackend: Registered executor NettyRpcEndpointRef(null) (worker2:42174) with ID 116/01/27 07:23:39 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, worker2, partition 1,RACK_LOCAL, 2202 bytes)16/01/27 07:23:40 INFO storage.BlockManagerMasterEndpoint: Registering block manager worker2:44472 with 517.4 MB RAM, BlockManagerId(1, worker2, 44472)16/01/27 07:23:47 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on worker2:44472 (size: 2.3 KB, free: 517.4 MB)16/01/27 07:23:51 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on worker2:44472 (size: 19.6 KB, free: 517.4 MB)16/01/27 07:24:00 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 37460 ms on worker3 (1/2)16/01/27 07:24:09 INFO scheduler.DAGScheduler: ShuffleMapStage 0 (map at WordCount_Cluster.scala:47) finished in 75.810 s16/01/27 07:24:09 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 29446 ms on worker2 (2/2)16/01/27 07:24:09 INFO scheduler.DAGScheduler: looking for newly runnable stages16/01/27 07:24:09 INFO scheduler.DAGScheduler: running: Set()16/01/27 07:24:09 INFO scheduler.DAGScheduler: waiting: Set(ResultStage 1)16/01/27 07:24:09 INFO scheduler.DAGScheduler: failed: Set()16/01/27 07:24:09 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool 16/01/27 07:24:09 INFO scheduler.DAGScheduler: Submitting ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount_Cluster.scala:53), which has no missing parents16/01/27 07:24:09 INFO storage.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 2.6 KB, free 241.4 KB)16/01/27 07:24:09 INFO storage.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 1595.0 B, free 242.9 KB)16/01/27 07:24:09 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on 192.168.112.130:33873 (size: 1595.0 B, free: 517.4 MB)16/01/27 07:24:09 INFO spark.SparkContext: Created broadcast 2 from broadcast at DAGScheduler.scala:100616/01/27 07:24:09 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from ResultStage 1 (ShuffledRDD[4] at reduceByKey at WordCount_Cluster.scala:53)16/01/27 07:24:09 INFO cluster.YarnScheduler: Adding task set 1.0 with 2 tasks16/01/27 07:24:09 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 1.0 (TID 2, worker2, partition 0,NODE_LOCAL, 1951 bytes)16/01/27 07:24:09 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 1.0 (TID 3, worker3, partition 1,NODE_LOCAL, 1951 bytes)16/01/27 07:24:09 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on worker2:44472 (size: 1595.0 B, free: 517.4 MB)16/01/27 07:24:09 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on worker3:41970 (size: 1595.0 B, free: 517.4 MB)16/01/27 07:24:10 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to worker2:4217416/01/27 07:24:10 INFO spark.MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 158 bytes16/01/27 07:24:10 INFO spark.MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle 0 to worker3:5613616/01/27 07:24:13 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 1.0 (TID 3) in 3634 ms on worker3 (1/2)16/01/27 07:24:13 INFO scheduler.DAGScheduler: ResultStage 1 (collect at WordCount_Cluster.scala:55) finished in 3.691 s16/01/27 07:24:13 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 2) in 3696 ms on worker2 (2/2)16/01/27 07:24:13 INFO cluster.YarnScheduler: Removed TaskSet 1.0, whose tasks have all completed, from pool 16/01/27 07:24:13 INFO scheduler.DAGScheduler: Job 0 finished: collect at WordCount_Cluster.scala:55, took 82.513256 spackage:1this:1Version"](http://spark.apache.org/docs/latest/building-spark.html#specifying-the-hadoop-version):1Because:1Python:2cluster.:1[run:1its:1YARN,:1have:1general:2pre-built:1locally:2locally.:1changed:1sc.parallelize(1:1only:1Configuration:1This:2first:1basic:1documentation:3learning,:1graph:1Hive:2several:1["Specifying:1"yarn":1page](http://spark.apache.org/documentation.html):1[params]`.:1[project:2prefer:1SparkPi:2<http://spark.apache.org/>:1engine:1version:1file:1documentation,:1MASTER:1example:3are:1systems.:1params:1scala>:1DataFrames,:1provides:1refer:2configure:1Interactive:2R,:1can:6build:3when:1how:2easiest:1Apache:1package.:11000).count():1Note:1Data.:1>>>:1Scala:2Alternatively,:1variable:1submit:1Testing:1Streaming:1module,:1thread,:1rich:1them,:1detailed:2stream:1GraphX:1distribution:1Please:3is:6return:2Thriftserver:1same:1start:1Spark](#building-spark).:1one:2with:3built:1Spark"](http://spark.apache.org/docs/latest/building-spark.html).:1data:1wiki](https://cwiki.apache.org/confluence/display/SPARK).:1using:2talk:1class:2Shell:2README:1computing:1Python,:2example::1##:8building:2N:1set:2Hadoop-supported:1other:1Example:1analysis.:1from:1runs.:1Building:1higher-level:1need:1guidance:2Big:1guide,:1Java,:1fast:1uses:1SQL:2will:1<class>:1requires:1:67Documentation:1web:1cluster:2using::1MLlib:1shell::2Scala,:1supports:2built,:1./dev/run-tests:1build/mvn:1sample:1For:2Programs:1Spark:13particular:2The:1processing.:1APIs:1computation:1Try:1[Configuration:1./bin/pyspark:1A:1through:1#:1library:1following:2More:1which:2also:4storage:1should:2To:2for:11Once:1setup:1mesos://:1Maven](http://maven.apache.org/).:1latest:1processing,:1the:21your:1not:1different:1distributions.:1given.:1About:1if:4instructions.:1be:2do:2Tests:1no:1./bin/run-example:2programs,:1including:3`./bin/run-example:1Spark.:1Versions:1HDFS:1individual:1spark://:1It:2an:3programming:1machine:1run::1environment:1clean:11000::2And:1run:7./bin/spark-shell:1URL,:1"local":1MASTER=spark://host:7077:1on:5You:3threads.:1against:1[Apache:1help:1print:1tests:2examples:2at:2in:5-DskipTests:1optimized:1downloaded:1versions:1graphs:1Guide](http://spark.apache.org/docs/latest/configuration.html):1online:1usage:1abbreviated:1comes:1directory.:1overview:1[building:1`examples`:2Many:1Running:1way:1use:3Online:1site,:1tests](https://cwiki.apache.org/confluence/display/SPARK/Useful+Developer+Tools).:1running:1find:1sc.parallelize(range(1000)).count():1contains:1project:1you:4Pi:1that:2protocols:1a:8or:3high-level:1name:1Hadoop,:2to:14available:1(You:1core:1instance::1see:1of:5tools:1"local[N]":1programs:2package.):1["Building:1must:1and:10command,:2system:1Hadoop:316/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/api,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}16/01/27 07:24:13 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}16/01/27 07:24:13 INFO ui.SparkUI: Stopped Spark web UI at http://192.168.112.130:404016/01/27 07:24:14 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread16/01/27 07:24:14 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors16/01/27 07:24:14 INFO cluster.YarnClientSchedulerBackend: Asking each executor to shut down16/01/27 07:24:14 INFO cluster.YarnClientSchedulerBackend: Stopped16/01/27 07:24:14 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!16/01/27 07:24:14 INFO storage.MemoryStore: MemoryStore cleared16/01/27 07:24:14 INFO storage.BlockManager: BlockManager stopped16/01/27 07:24:14 INFO storage.BlockManagerMaster: BlockManagerMaster stopped16/01/27 07:24:14 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!16/01/27 07:24:15 INFO remote.RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.16/01/27 07:24:15 INFO remote.RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.16/01/27 07:24:15 INFO spark.SparkContext: Successfully stopped SparkContext16/01/27 07:24:15 INFO util.ShutdownHookManager: Shutdown hook called16/01/27 07:24:16 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1273b284-86a3-45a5-ab5f-7996b7f78a5f16/01/27 07:24:16 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1273b284-86a3-45a5-ab5f-7996b7f78a5f/httpd-c0ad1a3a-48fc-4aef-8ac1-ddc28159fe2croot@master1:/usr/local/spark/spark-1.6.0-bin-hadoop2.6/bin# 运行结果和本地的一样。
4.通过写一个wordcount.sh,实现自动化。
创建一个wordcount.sh文件,内容如下,保存并退出。然后chmod +x wordcount.sh给shell文件执行权限。运行下面的命令,执行即可,执行结果和上面的一样。
root@master1:/usr/local/sparkApps# ./wordcount.sh
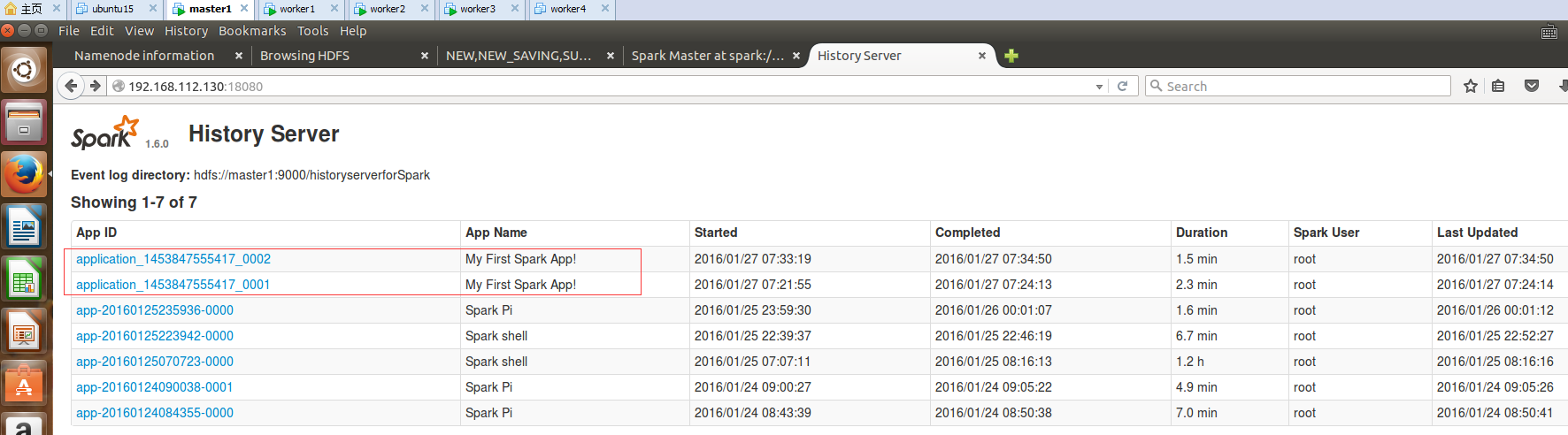
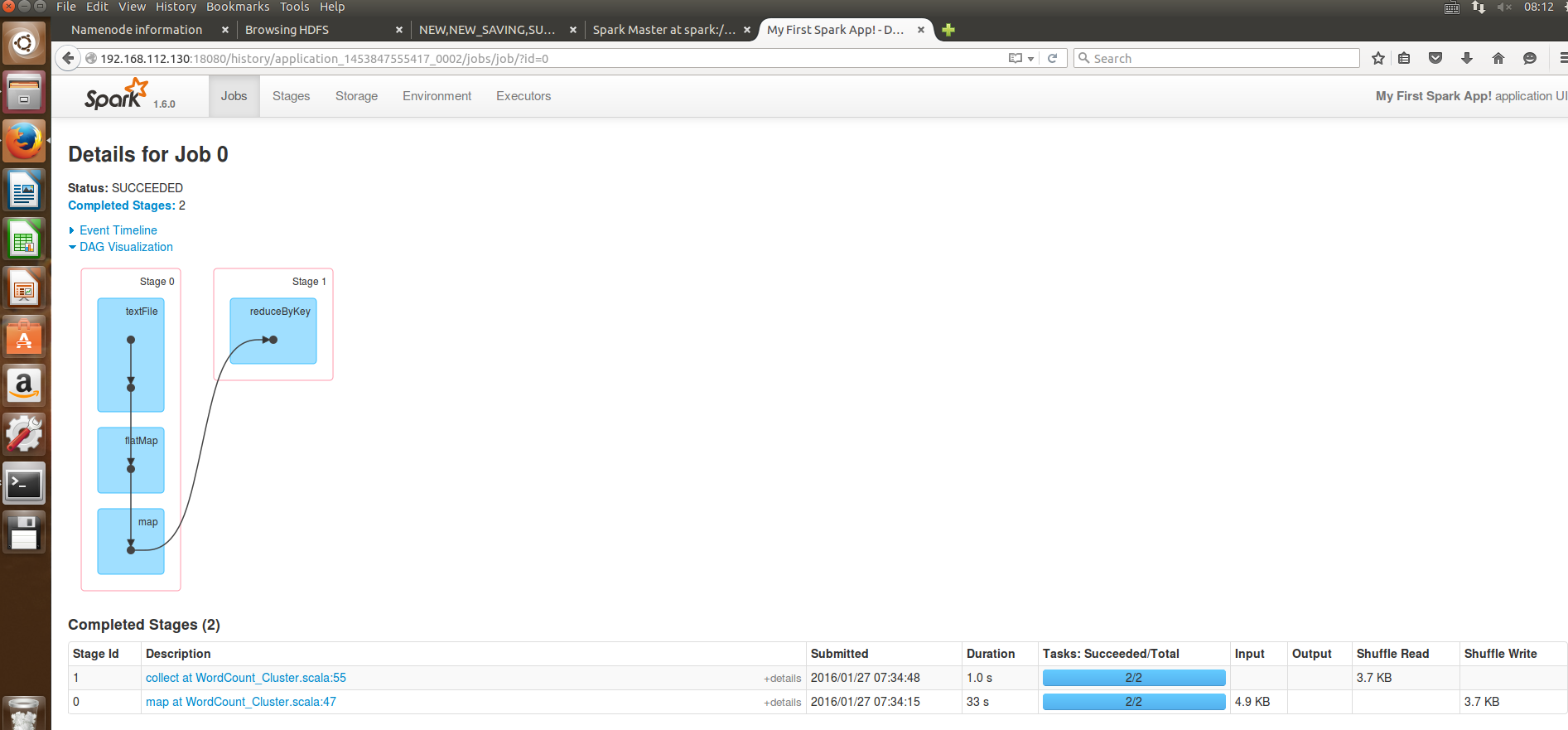
6.通过浏览器查看程序运行结果:
王家林:中国Spark第一人,Spark亚太研究院院长和首席专家
DT大数据梦工厂
新浪微博:http://weibo.com.ilovepains/
手机:18610086859
QQ:1740415547
联系邮箱18610086859@126.com