在网上和教材上也看了有很多数据挖掘方面的很多知识,自己也学习很多,就准备把自己学习和别人分享的结合去总结下,以备以后自己回头看,看别人总还是比不上自己写点,及时有些不懂或者是没有必要。
定义:分类树(决策树)是一种十分常用的分类方法。他是一种监管学习,所谓监管学习说白了很简单,就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。分类本质上就是一个map的过程。C4.5分类树就是决策树算法中最流行的一种。
算法简介:
Function C4.5(R:包含连续属性的无类别属性集合,C:类别属性,S:训练集) /*返回一棵决策树*/ Begin If S为空,返回一个值为Failure的单个节点; If S是由相同类别属性值的记录组成, 返回一个带有该值的单个节点; If R为空,则返回一个单节点,其值为在S的记录中找出的频率最高的类别属性值; [注意未出现错误则意味着是不适合分类的记录]; For 所有的属性R(Ri) Do If 属性Ri为连续属性,则 Begin 将Ri的最小值赋给A1: 将Rm的最大值赋给Am;/*m值手工设置*/ For j From 2 To m-1 Do Aj=A1+j*(A1Am)/m; 将Ri点的基于{< =Aj,>Aj}的最大信息增益属性(Ri,S)赋给A; End; 将R中属性之间具有最大信息增益的属性(D,S)赋给D; 将属性D的值赋给{dj/j=1,2...m}; 将分别由对应于D的值为dj的记录组成的S的子集赋给{sj/j=1,2...m}; 返回一棵树,其根标记为D;树枝标记为d1,d2...dm; 再分别构造以下树: C4.5(R-{D},C,S1),C4.5(R-{D},C,S2)...C4.5(R-{D},C,Sm); End C4.5
该算法的框架表述还是比较清晰的,从根节点开始不断得分治,递归,生长,直至得到最后的结果。根节点代表整个训练样本集,通过在每个节点对某个属性的测试验证,算法递归得将数据集分成更小的数据集.某一节点对应的子树对应着原数据集中满足某一属性测试的部分数据集.这个递归过程一直进行下去,直到某一节点对应的子树对应的数据集都属于同一个类为止,例如数据集对应得到的决策树如下:
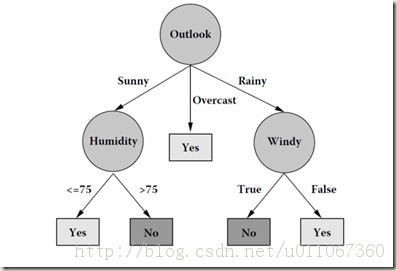
分类树中的测试是怎样的?
分类树中的测试是针对某一个样本属性进行的测试。样本的属性有两种,一种是离散变量,一种是连续变量。对于离散变量,这很简单,离散变量对应着多个值,每个值就对应着测试的一个分支,测试就是验证样本对应的属性值对应哪个分支。这样数据集就会被分成几个小组。对于连续变量,所有连续变量的测试分支都是2条,其测试分支分别对应着{<=A?,>a?}(a就是对应的阀值)。
如何选择测试?
分类树中每个节点对应着测试,但是这些测试是如何来选择呢?C4.5根据信息论标准来选择测试,比如增益(在信息论中,熵对应着某一分布的信息量,其值同时也对应着要完全无损表示该分布所需要的最小的比特数,本质上熵对应着不确定性,可能的变化的丰富程度。所谓增益,就是指在应用了某一测试之后,其对应的可能性丰富程度下降,不确定性减小,这个减小的幅度就是增益,其实质上对应着分类带来的好处)或者增益比(这个指标实际上就等于增益/熵,之所以采用这个指标是为了克服采用增益作为衡量标准的缺点,采用增益作为衡量标准会导致分类树倾向于优先选择那些具有比较多的分支的测试,这种倾向需要被抑制)。算法在进行Tree-Growth时,总是“贪婪得”选择那些信息论标准最高的那些测试。
如何选择连续变量的阈值?
在《分类树中的测试是怎样的?》中提到连续变量的分支的阈值点为a,这阈值如何确定呢?很简单,把需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序,假设该属性对应的不同的属性值一共有N个,那么总共有N-1个可能的候选分割阈值点,每个候选的分割阈值点的值为上述排序后的属性值链表中两两前后连续元素的中点,那么我们的任务就是从这个N-1个候选分割阈值点中选出一个,使得前面提到的信息论标准最大。举个例子,对play数据集,我们来处理温度属性,来选择合适的阈值。首先按照温度大小对对应样本进行排序如下:

那么可以看到有13个可能的候选阈值点,比如middle[64,65], middle[65,68]….,middle[83,85]。那么最优的阈值该选多少呢?应该是middle[71,72],如上图中红线所示。为什么呢?如下计算:

通过上述计算方式,0.939是最大的,因此测试的增益是最小的。(测试的增益和测试后的熵是成反比的,这个从后面的公式可以很清楚的看到)。根据上面的描述,我们需要对每个候选分割阈值进行增益或熵的计算才能得到最优的阈值,我们需要算N-1次增益或熵(对应温度这个变量而言就是13次计算)。能否有所改进呢?少算几次,加快速度。答案是可以该进,如下图:
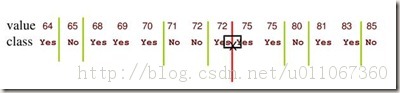
该图中的绿线代表可能的最优分割阈值点,根据信息论知识,像middle[72,75](红线所示)这个分割点,72,75属于同一个类,这样的分割点是不可能有信息增益的。(把同一个类分成了不同的类,这样的阈值点显然不会有信息增益,因为这样的分类没能帮上忙,减少可能性)
哪个属性是最佳的分类属性?
信息论标准有两种,一种是增益,一种是增益比。
首先来看看增益Gain的计算
为了精确地定义信息增益,我们先定义信息论中广泛使用的一个度量标准,称为熵(entropy),它刻画了任意样例集的纯度(purity)。给定包含关于某个目标概念的正反样例的样例集S,那么S相对这个布尔型分类的熵为:
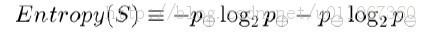
上述公式中,p+代表正样例,比如在本文开头第二个例子中p+则意味着去打羽毛球,而p-则代表反样例,不去打球。
举例来说,假设S是一个关于布尔概念的有14个样例的集合,它包括9个正例和5个反例(我们采用记号[9+,5-]来概括这样的数据样例),那么S相对于这个布尔样例的熵为:
Entropy([9+,5-])=-(9/14)log2(9/14)-(5/14)log2(5/14)=0.940。
上述公式的值为0.940。它的信息论含义就是我要想把Play?这个信息传递给别人话,平均来讲我至少需要0.940个bit来传递这个信息。C4.5的目标就是经过分类来减小这个熵。那么我们来依次考虑各个属性测试,通过某一属性测试我们将样本分成了几个子集,这使得样本逐渐变得有序,那么熵肯定变小了。这个熵的减小量就是我们选择属性测试的依据。
信息增益Gain(S,A)定义
已经有了熵作为衡量训练样例集合纯度的标准,现在可以定义属性分类训练数据的效力的度量标准。这个标准被称为“信息增益(information gain)”。简单的说,一个属性的信息增益就是由于使用这个属性分割样例而导致的期望熵降低(或者说,样本按照某属性划分时造成熵减少的期望)。更精确地讲,一个属性A相对样例集合S的信息增益Gain(S,A)被定义为:
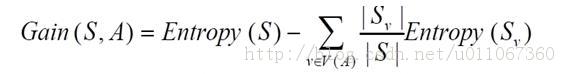
其中 Values(A)是属性A所有可能值的集合,是S中属性A的值为v的子集。换句话来讲,Gain(S,A)是由于给定属性A的值而得到的关于目标函数值的信息。当对S的一个任意成员的目标值编码时,Gain(S,A)的值是在知道属性A的值后可以节省的二进制位数。
它的实质是把数据集D根据某一属性测试分成v个子集,这使得数据集S变得有序,使得数据集S的熵变小了。分组后的熵其实就是各个子集的熵的权重和。通过计算我们得到Gain(Outlook)=0.940-0.694=0.246,Gain(Windy)=0.940-0.892=0.048….
可以得到第一个测试属性是Outlook。需要注意的是,属性测试是从数据集中包含的所有属性组成的候选属性中选择出来的。对于所在节点到根节点的路径上所包含的属性(我们称之为继承属性),其实根据公式很容易得到他们的熵增益是0,因此这些继承属性完全不必考虑,可以从候选属性中剔除这些属性。
到这里似乎一切都很完美,增益这个指标非常好,但是其实增益这个指标有一个缺点。我们来考虑play数据集中的Day这个属性(我们假设它是一个真属性,实际上很可能大家不会把他当做属性),Day有14个不同的值,那么Day的属性测试节点就会有14个分支,很显然每个分支其实都覆盖了一个“纯”数据集(所谓“纯”,指的就是所覆盖的数据集都属于同一个类),那么其熵增益显然就是最大的,那么Day就默认得作为第一个属性。之所以出现这样的情况,是因为增益这个指标天然得偏向于选择那些分支比较多的属性,也就是那些具有的值比较多的那些属性。这种偏向性使我们希望克服的,我们希望公正地评价所有的属性。因此又一个指标被提出来了Gain Ratio-增益比。
C4.5算法之信息增益率
增益比率度量是用前面的增益度量Gain(S,A)和分裂信息度量SplitInformation(S,A)来共同定义的,如下所示:
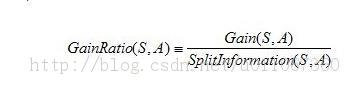
其中,分裂信息度量被定义为(分裂信息用来衡量属性分裂数据的广度和均匀):

其中S1到Sc是c个值的属性A分割S而形成的c个样例子集。分裂信息实际上就是S关于属性A的各值的熵。这与我们前面对熵的使用不同,在那里我们只考虑S关于学习到的树要预测的目标属性的值的熵。
通过计算我们很容易得到GainRatio(Outlook)=0.246/1.577=0.156。增益比实际上就是对增益进行了归一化,这样就避免了指标偏向分支多的属性的倾向。
决策树能够帮助我们对新出现的样本进行分类,但还有一些问题它不能很好得解决。比如我们想知道对于最终的分类,哪个属性的贡献更大?能否用一种比较简洁的规则来区分样本属于哪个类?等等。
C4.5算法的改进:
用信息增益率来选择属性。
在树构造过程中进行剪枝,在构造决策树的时候,那些挂着几个元素的节点,不考虑最好,不然容易导致overfitting。
对非离散数据也能处理。
能够对不完整数据进行处理。
决策树的剪枝
决策树为什么要剪枝?原因就是避免决策树“过拟合”样本。前面的算法生成的决策树非常的详细而庞大,每个属性都被详细地加以考虑,决策树的树叶节点所覆盖的训练样本都是“纯”的。因此用这个决策树来对训练样本进行分类的话,你会发现对于训练样本而言,这个树表现堪称完美,它可以100%完美正确得对训练样本集中的样本进行分类(因为决策树本身就是100%完美拟合训练样本的产物)。但是,这会带来一个问题,如果训练样本中包含了一些错误,按照前面的算法,这些错误也会100%一点不留得被决策树学习了,这就是“过拟合”。C4.5的缔造者昆兰教授很早就发现了这个问题,他作过一个试验,在某一个数据集中,过拟合的决策树的错误率比一个经过简化了的决策树的错误率要高。那么现在的问题就来了,如何在原生的过拟合决策树的基础上,通过剪枝生成一个简化了的决策树?
1、第一种方法,也是最简单的方法,称之为基于误判的剪枝。这个思路很直接,完全的决策树不是过度拟合么,我再搞一个测试数据集来纠正它。对于完全决策树中的每一个非叶子节点的子树,我们尝试着把它替换成一个叶子节点,该叶子节点的类别我们用子树所覆盖训练样本中存在最多的那个类来代替,这样就产生了一个简化决策树,然后比较这两个决策树在测试数据集中的表现,如果简化决策树在测试数据集中的错误比较少,并且该子树里面没有包含另外一个具有类似特性的子树(所谓类似的特性,指的就是把子树替换成叶子节点后,其测试数据集误判率降低的特性),那么该子树就可以替换成叶子节点。该算法以bottom-up的方式遍历所有的子树,直至没有任何子树可以替换使得测试数据集的表现得以改进时,算法就可以终止。
2、第一种方法很直接,但是需要一个额外的测试数据集,能不能不要这个额外的数据集呢?为了解决这个问题,于是就提出了悲观剪枝。该方法剪枝的依据是训练样本集中的样本误判率。我们知道一颗分类树的每个节点都覆盖了一个样本集,根据算法这些被覆盖的样本集往往都有一定的误判率,因为如果节点覆盖的样本集的个数小于一定的阈值,那么这个节点就会变成叶子节点,所以叶子节点会有一定的误判率。而每个节点都会包含至少一个的叶子节点,所以每个节点也都会有一定的误判率。悲观剪枝就是递归得估算每个内部节点所覆盖样本节点的误判率。剪枝后该内部节点会变成一个叶子节点,该叶子节点的类别为原内部节点的最优叶子节点所决定。然后比较剪枝前后该节点的错误率来决定是否进行剪枝。该方法和前面提到的第一种方法思路是一致的,不同之处在于如何估计剪枝前分类树内部节点的错误率。
连续值属性的改进
相对于那些离散值属性,分类树算法倾向于选择那些连续值属性,因为连续值属性会有更多的分支,熵增益也最大。算法需要克服这种倾向,我们利用增益率来克服这种倾向。增益率也可以用来克服连续值属性倾向。增益率作为选择属性的依据克服连续值属性倾向,这是没有问题的。但是如果利用增益率来选择连续值属性的分界点,会导致一些副作用。分界点将样本分成两个部分,这两个部分的样本个数之比也会影响增益率。根据增益率公式,我们可以发现,当分界点能够把样本分成数量相等的两个子集时(我们称此时的分界点为等分分界点),增益率的抑制会被最大化,因此等分分界点被过分抑制了。子集样本个数能够影响分界点,显然不合理。因此在决定分界点是还是采用增益这个指标,而选择属性的时候才使用增益率这个指标。这个改进能够很好得抑制连续值属性的倾向。当然还有其它方法也可以抑制这种倾向,比如MDL。
处理缺失属性
如果有些训练样本或者待分类样本缺失了一些属性值,那么该如何处理?要解决这个问题,需要考虑3个问题:
i)当开始决定选择哪个属性用来进行分支时,如果有些训练样本缺失了某些属性值时该怎么办?
ii)一个属性已被选择,那么在决定分支的时候如果有些样本缺失了该属性该如何处理?
iii)当决策树已经生成,但待分类的样本缺失了某些属性,这些属性该如何处理?针对这三个问题,昆兰提出了一系列解决的思路和方法。
对于问题i),计算属性a的增益或者增益率时,如果有些样本没有属性a,那么可以有这么几种处理方式:
(1)忽略这些缺失属性a的样本。
(2)给缺失属性a的样本赋予属性a一个均值或者最常用的的值。
(3)计算增益或者增益率时根据缺失属性样本个数所占的比率对增益/增益率进行相应的“打折”。
(4)根据其他未知的属性想办法把这些样本缺失的属性补全。
对于问题ii),当属性a已经被选择,该对样本进行分支的时候,如果有些样本缺失了属性a,那么:
(1)忽略这些样本。
(2)把这些样本的属性a赋予一个均值或者最常出现的值,然后再对他们进行处理。
(3)把这些属性缺失样本,按照具有属性a的样本被划分成的子集样本个数的相对比率,分配到各个子集中去。至于哪些缺失的样本被划分到子集1,哪些被划分到子集2,这个没有一定的准则,可以随机而动。(A)把属性缺失样本分配给所有的子集,也就是说每个子集都有这些属性缺失样本。
(3)单独为属性缺失的样本划分一个分支子集。
(4)对于缺失属性a的样本,尝试着根据其他属性给他分配一个属性a的值,然后继续处理将其划分到相应的子集。
对于问题iii),对于一个缺失属性a的待分类样本,有这么几种选择:
(1)如果有单独的确实分支,依据此分支。
(2)把待分类的样本的属性a值分配一个最常出现的a的属性值,然后进行分支预测。
(3)根据其他属性为该待分类样本填充一个属性a值,然后进行分支处理。
(4)在决策树中属性a节点的分支上,遍历属性a节点的所有分支,探索可能所有的分类结果,然后把这些分类结果结合起来一起考虑,按照概率决定一个分类。
(5)待分类样本在到达属性a节点时就终止分类,然后根据此时a节点所覆盖的叶子节点类别状况为其分配一个发生概率最高的类。
推理规则
C4.5决策树能够根据决策树生成一系列规则集,我们可以把一颗决策树看成一系列规则的组合。一个规则对应着从根节点到叶子节点的路径,该规则的条件是路径上的条件,结果是叶子节点的类别。C4.5首先根据决策树的每个叶子节点生成一个规则集,对于规则集中的每条规则,算法利用“爬山”搜索来尝试是否有条件可以移除,由于移除一个条件和剪枝一个内部节点本质上是一样的,因此前面提到的悲观剪枝算法也被用在这里进行规则简化。MDL准则在这里也可以用来衡量对规则进行编码的信息量和对潜在的规则进行排序。简化后的规则数目要远远小于决策树的叶子节点数。根据简化后的规则集是无法重构原来的决策树的。规则集相比决策树而言更具有可操作性,因此在很多情况下我们需要从决策树中推理出规则集。C4.5有个缺点就是如果数据集增大了一点,那么学习时间会有一个迅速地增长。