�������ͷ����㷨
����֪��������֪�����ܱ�ʾ���Ծ����档Ȼ�����ǿ��Խ��������似��֪����ģ�Ͱ��ղ�νṹ�����������������ܱ��ֳ������Ծ��ߵı߽��ˣ���Ҳ��������֪������Ҫ������ô��ѧϰ����֪��������������������棺
1�� Ҫѧϰ����ṹ��
2�� Ҫѧϰ����Ȩ值
����һ��������������һ���൱���㷨������Ȩ值������㷨���������㷨�������㷨��ѧϰ�Ķ�������ܹ���ʾ�����ķ��������档
����值����
����������ѧϰһ�㷴���㷨�Ļ����������Ҫ����sigmoid�����Լ�����值��Ԫ��
Ӧ��ʹ��ʲô���͵ĵ�Ԫ����Ϊ�����������Ļ�����������ǿ��Գ���ѡ��ǰ�����۵����Ե�Ԫ����Ϊ�����Ѿ�Ϊ���ֵ�Ԫ������һ���ݶ��½�ѧϰ����Ȼ����������Ե�Ԫ�������Ծɲ������Ժ����������Ǹ�ϣ��ѡ���ܹ����������Ժ��������硣
��֪����Ԫ����һ��ѡ�����IJ�������值ʹ�����������Բ��ʺ��ݶ��½��㷨����������Ҫ���������ĵ�Ԫ���������������ķ����Ժ������������������Ŀ�������һ�ִ���sigmoid��Ԫ��sigmoid unit��������һ�ַdz���似�ڸ�֪���ĵ�Ԫ����������һ��ƽ���Ŀ���值������
��ͼ��sigmoid��Ԫ�����֪����似��sigmoid��Ԫ�ȼ������������������ϣ�Ȼ��Ӧ��һ����值���˽����Ȼ��������sigmoid��Ԫ����值��������������������

����ȷ�ؽ���sigmoid��Ԫ�����������������
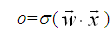
����
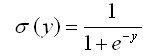
s��������Ϊsigmoid��������Ҳ���Գ�Ϊlogistic������logistic function����ע�����������ΧΪ0��1�������뵥���������μ�ͼ4-6�е���值�������ߣ�����Ϊ��������ѷdz��������值��ӳ�䵽һ��С��Χ�����������������Ϊsigmoid��Ԫ�ļ�ѹ������squashing function����sigmoid������һ�����õ����������ĵ��������������������ʾ��ȷ�еؽ����ǣ�

PS�������ټ�˵�����logistic���������⣬��֪һ���̶�������ṹ����Ҫ������ʱ����������Ȩ值����û�����ز������£�����ֱ���ø�֪����ѧϰ�������ҵ����ʵ�值���������ڼ��������ز㣬�����������ز�ĵ�Ԫ����ȷ��������δ֪�ģ���˸�֪�������������Dz����õġ�
��һ�ְ취�Ǹ���ÿ����Ԫ������Ԥ��Ĺ������������ز㵥Ԫ��Ȩ值������Ϳ���ͨ���ݶ��½��������������Ҫ���������ĸ�֪��ʹ�ý�������������ȫ�������ܺ�ת������0����1��Ԥ�⣬���ݺ������ɵ�����˱��뿼���Ƿ��ܽ����������滻�������ĺ�����


����ͼ���Կ���һ�ֽ��ݺ������Ա�s�ͺ��������棬���s�ͺ�������sigmoid��Ԫ������Ҳ����logistic������
�����㷨
������һϵ��ȷ���ĵ�Ԫ�����γɵĶ�����磬�����㷨������ѧϰ��������Ȩ值���������ݶ��½�������ͼ��С���������值��Ŀ��值֮������ƽ����
��Ϊ����Ҫ���Ƕ�������Ԫ�����磬����������ǰֻ���ǵ�����Ԫ���������������¶������E���Ա��������������������͡�

����outputs�����������Ԫ�ļ��ϣ�tkd��okd����ѵ������d�͵�k�������Ԫ��ص����值��
�����㷨���ٵ�ѧϰ����������һ����ļ���ռ䣬����ռ������������е�Ԫ�����п��ܵ�Ȩ值���塣�������������һ����������������ʾ������ͼ1��ʾ�����Ե�Ԫ�����������似�����ͼ�е������ǵ��µ�����E����������ҿռ��е�����ά���ڶ�Ӧ�����������е�Ԫ��ص�����Ȩ值����ѵ��������Ԫ�����һ�����ݶ��½��ɱ���������Ѱ��һ������ʹE��С����
��������һ����Ҫ��ͬ�����������������ж���ֲ���С值����ͼ1��ʾ�������������һ����С值�����ҵ��ǣ�����ζ���ݶ��½����ܱ�֤�������ֲ���С值����δ�صõ�ȫ����С��������������ϰ����Ѿ����ֶ���ʵ���кܶ�Ӧ�÷����㷨�������˳�ɫ�Ľ����

ͼ1
��������sigmoid��Ԫ��ǰ������ķ����㷨
Backpropagation(training_examples,h,nin,nout, nhidden)
trainning_exaples��ÿһ��ѵ����������ʽΪ<,>����ż����������������值��������Ŀ�����值��
h��ѧϰ���ʣ�����0.05����nin�����������������nhidden�����ز㵥Ԫ����nout�������Ԫ����
�ӵ�Ԫi����Ԫj�������ʾΪxji����Ԫi����Ԫj��Ȩ值��ʾΪwij��
��������nin�����룬nhidden�����ص�Ԫ��nout�������Ԫ������
��ʼ�����е�����Ȩ值ΪС�����值������-0.05��0.05֮�������
��������ֹ����ǰ����
����ѵ������training_examples�е�ÿ��<,>����
������������ǰ��
1�� ��ʵ���������磬������������ÿ����Ԫu�����ou��
ʹ��������練��
2�� ���������ÿ�������Ԫk���������������dk
dk <--k(1-ok)(tk-ok)
3�� ���������ÿ�����ص�Ԫh���������������dh
dh<--h(1-oh)wkhdk
4�� ����ÿ������Ȩ值wji
wji<--wji +Dwji
����
Dwji=hdjxji �� 1��
��������˷����㷨�������������㷨�����ڰ�������sigmoid��Ԫ�ķֲ�ǰ�����磬����ÿһ��ĵ�Ԫ��ǰһ������е�Ԫ���������Ƿ����㷨�������ݶ��½���������ݶ��½����汾������ʹ�õķ�����ǰһ��ʹ�õ�һ���������������µ���չ��
�� ������ÿ����㱻����һ����ţ�����һ��������������Ľ��Ҫô����������룬Ҫô��������ij����Ԫ�������
�� xji��ʾ���i����Ԫj�����룬����wji��ʾ��Ӧ��Ȩ值��
�� dn��ʾ�뵥Ԫn��������������Ľ�ɫ��ǰ�����۵�deltaѵ�������е�(t-o)��似���������ǿ��Կ���dn =
��������㷨�Ŀ�ʼ������һ��������������������Ԫ�������Ԫ�����磬����ʼ�����������Ȩ值ΪС�������������������̶�������ṹ���㷨����ѭ���Ͷ�ѵ���������з����ĵ���������ÿһ��ѵ����������Ӧ��Ŀǰ�����絽����������������������������������Ȼ��������������е�Ȩ值�����������ݶ��½�������е�����ֱ����������ܴﵽ�ɽ��ܵľ��ȣ���������ǧ�Σ����ʹ��ͬ����ѵ����������
��delta����ıȽ�
������ݶ��½�Ȩ���·�����deltaѵ��������似������delta�����������������ߵij˻�������ÿһ��Ȩ��ѧϰ����h����Ȩ值Ӧ�õ�����值xji���������Ԫ�������Ωһ�IJ�ͬ��delta�����е�����t-o�����滻��һ�������ӵ������dj����4.5.3�ڵĶ�Ȩ���·�����Ƶ�֮�����ǽ�����dj��ȷ��ʽ��Ϊ��ֱ�۵����������ȿ��������ÿһ�������Ԫk��dk����������ġ��ܼ�dk��delta�����еģ�tk-ok����似����������sigmoid��ѹ�����ĵ���ok(1-ok)��ÿ�����ص�Ԫh��dh��值������似����ʽ���㷨�Ĺ�ʽ[T4.4]����Ȼ������Ϊѵ�������������������ṩ��Ŀ��值tk������ȱ��ֱ�ӵ�Ŀ��值���������ص�Ԫ�����值����˲�ȡ���¼�Ӱ취�������ص�Ԫ�������������ص�ԪhӰ���ÿһ����Ԫ�����dk���м�Ȩ��ͣ�ÿ�����dkȨ值Ϊwkh��wkh���Ǵ����ص�Ԫh�������Ԫk��Ȩ值�����Ȩ值�̻������ص�Ԫh���������Ԫk�����Ӧ�����𡱵ij̶ȡ�
���ӳ�����Momentum����
�������ǻ�����һ�ַ��ִ����㷨�ı��֣����ӳ�����Momentum����
�������㷨�Ĺ�ʽ��1����Ϊ���µ���ʽ��
Dwji(n)=hdjxji+aDwji(n �C 1)
����Ҫ��Ϊ�˳��ƾֲ��ļ�С值�����Դ�һ��������С值������һ���ֲ���С值���п����ҵ�ȫ����С值��
����Dwji(n)���㷨��ѭ���еĵ�n�ε������е�Ȩ值���£�����0<a<1��һ����Ϊ������momentum���ij�����ע�������ʽ�Ҳ�ĵ�һ����Ƿ����㷨�Ĺ�ʽ��1���е�Ȩ值���¡��ұߵĵڶ������µģ�����Ϊ�����Ϊ�������������������ã������ݶ��½��������켣�ͺ���һ���������ģ������������档a�����������ӳ���ʹ������һ�ε�������һ�ε���ʱ��ͬ���ķ��������������ʱ��ʹ���������������ľֲ���С值����ʹ�������������ϵ�ƽ̹�������û�г���������п������������ֹͣ����Ҳ�������ݶȲ������������������������Ч�����Ӷ����Լӿ�������
ps:������ز��ʾ�����㷨��һ�����˵������ǣ����ܹ��������ڲ������ز㷢�����õ��м��ʾ����Ϊѵ��������������������������Ȩ值���ڵĹ��̿������ɵ�����Ȩ值������������С�����ƽ��E������Ч���κ����ص�Ԫ��ʾ�����ܹ����������㷨�����µ����ز���������Щ������������û����ȷ��ʾ��������ȴ�ܲ�����ʵ������ѧϰĿ�꺯������ص�������
���磬����ͼ4-7��ʾ�����硣���8������������3�����ص�Ԫ������3�����ص�Ԫ���������ӵ�8�������Ԫ�����������Ľṹ��3�����ص�Ԫ�������±�ʾ8������值����ij�ַ�ʽ�����������������Ա�������ز�ı�ʾ���Ա������Ԫ����������ȷ��Ŀ��值��

ͼ2
���8*8*8�����类ѵ����ѧϰ��Ⱥ�����ʹ��ͼ����ʾ��8��ѵ����������5000�֣�epochs��ѵ��֮��3�����ص�Ԫʹ��ͼ�Ҳ�ı��뷽ʽ������8�����ͬ�����롣ע������ѱ�����值��������Ϊ0��1����ô�����8����ͬ值�ı�����值���롣
����ѵ��ͼ2��ʾ�����磬��ѧϰ��Ŀ�꺯��f(x)=x�������Ǻ����߸�0��һ��1���������������ѧ����8�������Ԫ������8�����롣��������һ���ĺ�������������������ֻ��ʹ��3������Ԫ�����ԣ�ѧϰ����3�����ص�Ԫ���벶ס����8�����뵥Ԫ�����йؼ���Ϣ��
�������㷨����������������ʱ��ʹ��8������������Ϊѵ�����������ɹ���ѧ����Ŀ�꺯�����ݶ��½��ķ����㷨���������ز��ʾ��ʲô�أ�ͨ������ѧϰ�����������8�����������������������ص�Ԫ��值�����Կ���ѧ���ı������֪�Ķ�8��值ʹ��3λ�������Ʊ�����ͬ��Ҳ����000��001��010��������111����ͼ2��ʾ�˷����㷨��һ�������м��������3�����ص�Ԫ��ȷ��值��
������������ز��Զ��������ñ�ʾ��������ANNѧϰ��һ���ؼ����ԡ�����Щ������ʹ������������ṩ��Ԥ����������ѧϰ������ȣ����ṩ��һ���൱��Ҫ������ԡ�������ѧϰ������������û����ȷ�������������Ȼ��Щ�����������һ�������������sigmoid��Ԫ�������Լ�����ġ�ע��������ʹ�õĵ�Ԫ��Խ�࣬�Ϳ��Դ����Խ���ӵ�������