一、前言
在之前有一次面试中,被问到你了解Dictionary的内部实现机制吗?当时只是简单的了问答了:Dictionary的内部结构是哈希表,从而可以快速进行查找。但是对于更深一步了解就不清楚了。所以面试回来之后,就打算好好研究下Dictionary的源码。所以也就有了这篇文章。
二、Dictionary源码剖析
大家都知道,现在微软已经开源了.NET Framework的源码了,在线源码查看地址为:http://referencesource.microsoft.com/。通过查找可以找到.NET Framework类的源码。下面我们就一起来看下Dictionary源码。
2.1 添加元素
首先我们来查看下Dictionary.Add方法的实现。为了让大家更好地实现,下面抽取了Dictionary源码核心部分来进行分析,详细的分析代码如下所示:
// buckets是哈希表,用来存放Key的Hash值 // entries用来存放元素列表 // count是元素数量 private void Insert(TKey key, TValue value, bool add) { if (key == null) { throw new ArgumentNullException(key.ToString()); } // 首先分配buckets和entries的空间 if (buckets == null) Initialize(0); int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; // 计算key值对应的哈希值(HashCode) int targetBucket = hashCode % buckets.Length; // 对哈希值求余,获得需要对哈希表进行赋值的位置#if FEATURE_RANDOMIZED_STRING_HASHING int collisionCount = 0;#endif // 处理冲突的处理逻辑 for (int i = buckets[targetBucket]; i >= 0; i = entries[i].next) { if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) { if (add) { throw new ArgumentNullException(); } entries[i].value = value; version++; return; }#if FEATURE_RANDOMIZED_STRING_HASHING collisionCount++;#endif } int index; // index记录了元素在元素列表中的位置 if (freeCount > 0) { index = freeList; freeList = entries[index].next; freeCount--; } else { // 如果哈希表存放哈希值已满,则重新从primers数组中取出值来作为哈希表新的大小 if (count == entries.Length) { Resize(); targetBucket = hashCode % buckets.Length; } // 大小如果没满的逻辑 index = count; count++; } // 对元素列表进行赋值 entries[index].hashCode = hashCode; entries[index].next = buckets[targetBucket]; entries[index].key = key; entries[index].value = value; // 对哈希表进行赋值 buckets[targetBucket] = index; version++;#if FEATURE_RANDOMIZED_STRING_HASHING if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer)) { comparer = (IEqualityComparer<TKey>) HashHelpers.GetRandomizedEqualityComparer(comparer); Resize(entries.Length, true); }#endif }
下面以一个实际的添加例子来具体分析下上面的添加元素代码,从而更好地理解Add方法的实现原理。
Dictionary<int, string> myDictionary = new Dictionary<int, string>(); myDictionary.Add(1, "Item 1"); myDictionary.Add(2, "Item 2"); myDictionary.Add(3, "Item 3");
当添加第一个元素时,此时会分配哈希表buckets数组和entries数组的空间和初始大小为3,分配完成之后,会计算添加元素key值的哈希值,哈希值的计算由具体的哈希算法来实现的,假设1的哈希值为9的话,此时targetBucket = 9%buckets.Length(3)的值为0,index的值为0,则第一个元素存放在entries列表中的第一个位置,最后对哈希表进行赋值,此时赋值的位置为第0个位置,其值为index的值,所以为0,插入第一个元素后Dictionary的内部结构如下所示:

后面添加元素的过程依次类推。其原理就是,buckets记录了元素的在元素列表的存储位置,也就相当于一个映射列表。在查找的时候,就可以通过key值的哈希值来与buckets数组长度求余来获得元素在元素列表中的索引,这样就可以快速定位元素的位置,从而获得元素的key对应的Value值。如上面的例子中,如果想找到key值为1对应的Value值时,此时计算1的哈希值为9,然后对buckets数组长度求余,此时获得的值正是0,这样就可以直接从entries[0].Value的方式来获取对应的Value的值,这也就是Dictionary能完成快速查找的实现原理。后面会通过Dictionary内部的查找源码来证实上面分析的过程。
2.2 解决冲突
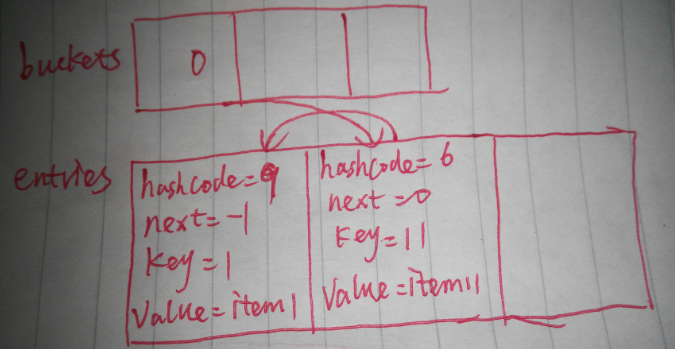
在添加元素过程中,有一个很重要的问题,如果产生冲突怎么办?即如果我后面需要插入的一个元素(假设这个值为11吧)的key值的哈希值也为6,此时targetBucket的值也是为0,但元素列表中0的位置已经存放了元素了,这样就出现了冲突,那Dictionary是怎样处理这个冲突的呢?处理冲突的方法有很多种,Dictionary处理的方式是链接法。Dictionary会把发生冲突的元素链接之前元素的后面,通过next属性来指定冲突关系。此时Dictionary内部结构如下图所示:
三、Dictionary如何实现快速查找呢?
针对于Dictionary实现快速查找的原因,在上面我们已经做了一个推断了,下面通过Dictionary内部的代码实现来验证下,具体的查找代码如下所示:
public TValue this[TKey key] { get { int i = FindEntry(key); // 通过元素所在存在的位置直接获取其对应的Value if (i >= 0) return entries[i].value; throw new KeyNotFoundException(); return default(TValue); } set { Insert(key, value, false); } } private int FindEntry(TKey key) { if (key == null) { throw new ArgumentNullException(); } if (buckets != null) { // 获得Key值对应的哈希值 int hashCode = comparer.GetHashCode(key) & 0x7FFFFFFF; // 查找元素在元素列表中的位置,如果没有冲突的情况下,此时查找速度为O(1),存在冲突的情况下为O(N),N为存在冲突的次数 for (int i = buckets[hashCode % buckets.Length]; i >= 0; i = entries[i].next) { if (entries[i].hashCode == hashCode && comparer.Equals(entries[i].key, key)) return i; } } return -1; }
通过代码可以看出,我们之前的分析是完成正确的。从中可以明白:Dictionary之所以能实现快速查找元素,其内部使用哈希表来存储元素对应的位置,然后我们可以通过哈希值快速地从哈希表中定位元素所在的位置索引,从而快速获取到key对应的Value值。
四、总结
可以说,Dictionary的实现原理也是一种空间换时间的思路,多使用一个buckets的存储空间来存储元素的位置,从而来提升查找速度。
接下来,我们新开一个领域驱动设计系列,还请大家多多拍砖。
本文所有源码下载:DictonaryInDepth.zip