第一、前言
从今天开始我们正式开始Android的逆向之旅,关于逆向的相关知识,想必大家都不陌生了,逆向领域是一个充满挑战和神秘的领域。作为一名Android开发者,每个人都想去探索这个领域,因为一旦你破解了别人的内容,成就感肯定爆棚,不过相反的是,我们不仅要研究破解之道,也要研究加密之道,因为加密和破解是相生相克的。但是我们在破解的过程中可能最头疼的是native层,也就是so文件的破解。所以我们先来详细了解一下so文件的内容下面就来看看我们今天所要介绍的内容。今天我们先来介绍一下elf文件的格式,因为我们知道Android中的so文件就是elf文件,所以需要了解so文件,必须先来了解一下elf文件的格式,对于如何详细了解一个elf文件,就是手动的写一个工具类来解析一个elf文件。
第二、准备资料
我们需要了解elf文件的格式,关于elf文件格式详解,网上已经有很多介绍资料了。这里我也不做太多的解释了。不过有两个资料还是需要介绍一下的,因为网上的内容真的很多,很杂。这两个资料是最全的,也是最好的。我就是看这两个资料来操作的:
第一个资料是非虫大哥的经典之作:

看吧,是不是超级详细?后面我们用Java代码来解析elf文件的时候,就是按照这张图来的。但是这张图有些数据结构解释的还不是很清楚,所以第二个资料来了。
第二个资料:北京大学实验室出的标准版
http://download.csdn.net/detail/jiangwei0910410003/9204051
这里就不对这个文件做详细解释了,后面在做解析工作的时候,会截图说明。
关于上面的这两个资料,这里还是多数两句:一定要仔细认真的阅读。这个是经典之作。也是后面工作的基础。
第三、工具
当然这里还需要介绍一个工具,因为这个工具在我们下面解析elf文件的时候,也非常有用,而且是检查我们解析elf文件的模板。
就是很出名的:readelf命令
不过Window下这个命令不能用,因为这个命令是Linux的,所以我们还得做个工作就是安装Cygwin。关于这个工具的安装,大家可以看看这篇文章:
http://blog.csdn.net/jiangwei0910410003/article/details/17710243
不过在下载的过程中,我担心小朋友们会遇到挫折,所以很贴心的,放到的云盘里面:
http://pan.baidu.com/s/1C1Zci
下载下来之后,需要改一个东西才能用:

该一下这个文件:
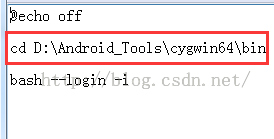
这个路径要改成你本地cygwin64中的bin目录的路径,不然运行错误的。改好之后,直接运行Cygwin.bat就可以了。
关于readelf工具我们这里不做太详细的介绍,只介绍我们要用到的命令:
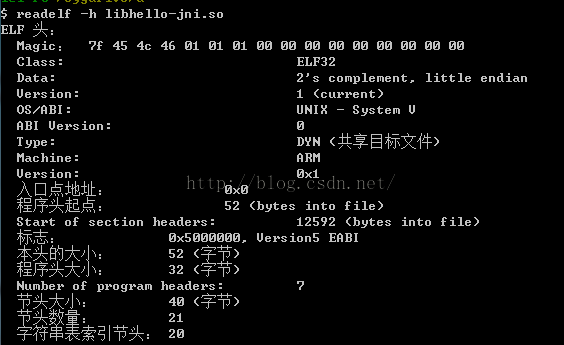
1、readelf -h xxx.so
查看so文件的头部信息
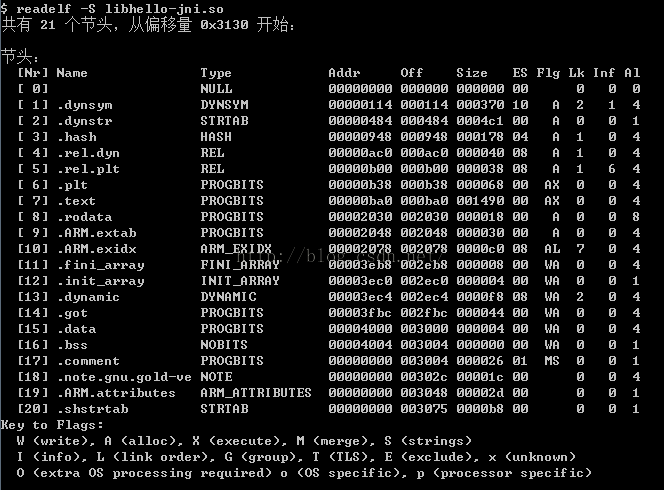
2、readelf -S xxx.so
查看so文件的段(Section)头的信息
3、readelf -l xxx.so
查看so文件的程序段头信息(Program)

4、readelf -a xxx.so
查看so文件的全部内容

还有很多命令用法,这里就不在细说了,网上有很多介绍的~~
第四、实际操作解析Elf文件(Java代码&C++代码)
上面我们介绍了elf文件格式资料,elf文件的工具,那么下面我们就来实际操作一下,来用Java代码手把手的解析一个libhello-jni.so文件。关于这个libhello-jni.so文件的下载地址:
http://download.csdn.net/detail/jiangwei0910410003/9204087
1、首先定义elf文件中各个结构体内容
这个我们需要参考elf.h这个头文件的格式了。这个文件网上也是有的,这里还是给个下载链接吧:
http://download.csdn.net/detail/jiangwei0910410003/9204081
我们看看Java中定义的elf文件的数据结构类:
package com.demo.parseso;import java.util.ArrayList;public class ElfType32 { public elf32_rel rel; public elf32_rela rela; public ArrayList<Elf32_Sym> symList = new ArrayList<Elf32_Sym>(); public elf32_hdr hdr;//elf头部信息 public ArrayList<elf32_phdr> phdrList = new ArrayList<elf32_phdr>();//可能会有多个程序头 public ArrayList<elf32_shdr> shdrList = new ArrayList<elf32_shdr>();//可能会有多个段头 public ArrayList<elf32_strtb> strtbList = new ArrayList<elf32_strtb>();//可能会有多个字符串值 public ElfType32() { rel = new elf32_rel(); rela = new elf32_rela(); hdr = new elf32_hdr(); } /** * typedef struct elf32_rel { Elf32_Addr r_offset; Elf32_Word r_info; } Elf32_Rel; * */ public class elf32_rel { public byte[] r_offset = new byte[4]; public byte[] r_info = new byte[4]; @Override public String toString(){ return "r_offset:"+Utils.bytes2HexString(r_offset)+";r_info:"+Utils.bytes2HexString(r_info); } } /** * typedef struct elf32_rela{ Elf32_Addr r_offset; Elf32_Word r_info; Elf32_Sword r_addend; } Elf32_Rela; */ public class elf32_rela{ public byte[] r_offset = new byte[4]; public byte[] r_info = new byte[4]; public byte[] r_addend = new byte[4]; @Override public String toString(){ return "r_offset:"+Utils.bytes2HexString(r_offset)+";r_info:"+Utils.bytes2HexString(r_info)+";r_addend:"+Utils.bytes2HexString(r_info); } } /** * typedef struct elf32_sym{ Elf32_Word st_name; Elf32_Addr st_value; Elf32_Word st_size; unsigned char st_info; unsigned char st_other; Elf32_Half st_shndx; } Elf32_Sym; */ public static class Elf32_Sym{ public byte[] st_name = new byte[4]; public byte[] st_value = new byte[4]; public byte[] st_size = new byte[4]; public byte st_info; public byte st_other; public byte[] st_shndx = new byte[2]; @Override public String toString(){ return "st_name:"+Utils.bytes2HexString(st_name) +"\nst_value:"+Utils.bytes2HexString(st_value) +"\nst_size:"+Utils.bytes2HexString(st_size) +"\nst_info:"+(st_info/16) +"\nst_other:"+(((short)st_other) & 0xF) +"\nst_shndx:"+Utils.bytes2HexString(st_shndx); } } public void printSymList(){ for(int i=0;i<symList.size();i++){ System.out.println(); System.out.println("The "+(i+1)+" Symbol Table:"); System.out.println(symList.get(i).toString()); } } //Bind字段==》st_info public static final int STB_LOCAL = 0; public static final int STB_GLOBAL = 1; public static final int STB_WEAK = 2; //Type字段==》st_other public static final int STT_NOTYPE = 0; public static final int STT_OBJECT = 1; public static final int STT_FUNC = 2; public static final int STT_SECTION = 3; public static final int STT_FILE = 4; /** * 这里需要注意的是还需要做一次转化 * #define ELF_ST_BIND(x) ((x) >> 4) #define ELF_ST_TYPE(x) (((unsigned int) x) & 0xf) */ /** * typedef struct elf32_hdr{ unsigned char e_ident[EI_NIDENT]; Elf32_Half e_type; Elf32_Half e_machine; Elf32_Word e_version; Elf32_Addr e_entry; // Entry point Elf32_Off e_phoff; Elf32_Off e_shoff; Elf32_Word e_flags; Elf32_Half e_ehsize; Elf32_Half e_phentsize; Elf32_Half e_phnum; Elf32_Half e_shentsize; Elf32_Half e_shnum; Elf32_Half e_shstrndx; } Elf32_Ehdr; */ public class elf32_hdr{ public byte[] e_ident = new byte[16]; public byte[] e_type = new byte[2]; public byte[] e_machine = new byte[2]; public byte[] e_version = new byte[4]; public byte[] e_entry = new byte[4]; public byte[] e_phoff = new byte[4]; public byte[] e_shoff = new byte[4]; public byte[] e_flags = new byte[4]; public byte[] e_ehsize = new byte[2]; public byte[] e_phentsize = new byte[2]; public byte[] e_phnum = new byte[2]; public byte[] e_shentsize = new byte[2]; public byte[] e_shnum = new byte[2]; public byte[] e_shstrndx = new byte[2]; @Override public String toString(){ return "magic:"+ Utils.bytes2HexString(e_ident) +"\ne_type:"+Utils.bytes2HexString(e_type) +"\ne_machine:"+Utils.bytes2HexString(e_machine) +"\ne_version:"+Utils.bytes2HexString(e_version) +"\ne_entry:"+Utils.bytes2HexString(e_entry) +"\ne_phoff:"+Utils.bytes2HexString(e_phoff) +"\ne_shoff:"+Utils.bytes2HexString(e_shoff) +"\ne_flags:"+Utils.bytes2HexString(e_flags) +"\ne_ehsize:"+Utils.bytes2HexString(e_ehsize) +"\ne_phentsize:"+Utils.bytes2HexString(e_phentsize) +"\ne_phnum:"+Utils.bytes2HexString(e_phnum) +"\ne_shentsize:"+Utils.bytes2HexString(e_shentsize) +"\ne_shnum:"+Utils.bytes2HexString(e_shnum) +"\ne_shstrndx:"+Utils.bytes2HexString(e_shstrndx); } } /** * typedef struct elf32_phdr{ Elf32_Word p_type; Elf32_Off p_offset; Elf32_Addr p_vaddr; Elf32_Addr p_paddr; Elf32_Word p_filesz; Elf32_Word p_memsz; Elf32_Word p_flags; Elf32_Word p_align; } Elf32_Phdr; */ public static class elf32_phdr{ public byte[] p_type = new byte[4]; public byte[] p_offset = new byte[4]; public byte[] p_vaddr = new byte[4]; public byte[] p_paddr = new byte[4]; public byte[] p_filesz = new byte[4]; public byte[] p_memsz = new byte[4]; public byte[] p_flags = new byte[4]; public byte[] p_align = new byte[4]; @Override public String toString(){ return "p_type:"+ Utils.bytes2HexString(p_type) +"\np_offset:"+Utils.bytes2HexString(p_offset) +"\np_vaddr:"+Utils.bytes2HexString(p_vaddr) +"\np_paddr:"+Utils.bytes2HexString(p_paddr) +"\np_filesz:"+Utils.bytes2HexString(p_filesz) +"\np_memsz:"+Utils.bytes2HexString(p_memsz) +"\np_flags:"+Utils.bytes2HexString(p_flags) +"\np_align:"+Utils.bytes2HexString(p_align); } } public void printPhdrList(){ for(int i=0;i<phdrList.size();i++){ System.out.println(); System.out.println("The "+(i+1)+" Program Header:"); System.out.println(phdrList.get(i).toString()); } } /** * typedef struct elf32_shdr { Elf32_Word sh_name; Elf32_Word sh_type; Elf32_Word sh_flags; Elf32_Addr sh_addr; Elf32_Off sh_offset; Elf32_Word sh_size; Elf32_Word sh_link; Elf32_Word sh_info; Elf32_Word sh_addralign; Elf32_Word sh_entsize; } Elf32_Shdr; */ public static class elf32_shdr{ public byte[] sh_name = new byte[4]; public byte[] sh_type = new byte[4]; public byte[] sh_flags = new byte[4]; public byte[] sh_addr = new byte[4]; public byte[] sh_offset = new byte[4]; public byte[] sh_size = new byte[4]; public byte[] sh_link = new byte[4]; public byte[] sh_info = new byte[4]; public byte[] sh_addralign = new byte[4]; public byte[] sh_entsize = new byte[4]; @Override public String toString(){ return "sh_name:"+Utils.bytes2HexString(sh_name)/*Utils.byte2Int(sh_name)*/ +"\nsh_type:"+Utils.bytes2HexString(sh_type) +"\nsh_flags:"+Utils.bytes2HexString(sh_flags) +"\nsh_add:"+Utils.bytes2HexString(sh_addr) +"\nsh_offset:"+Utils.bytes2HexString(sh_offset) +"\nsh_size:"+Utils.bytes2HexString(sh_size) +"\nsh_link:"+Utils.bytes2HexString(sh_link) +"\nsh_info:"+Utils.bytes2HexString(sh_info) +"\nsh_addralign:"+Utils.bytes2HexString(sh_addralign) +"\nsh_entsize:"+ Utils.bytes2HexString(sh_entsize); } } /****************sh_type********************/ public static final int SHT_NULL = 0; public static final int SHT_PROGBITS = 1; public static final int SHT_SYMTAB = 2; public static final int SHT_STRTAB = 3; public static final int SHT_RELA = 4; public static final int SHT_HASH = 5; public static final int SHT_DYNAMIC = 6; public static final int SHT_NOTE = 7; public static final int SHT_NOBITS = 8; public static final int SHT_REL = 9; public static final int SHT_SHLIB = 10; public static final int SHT_DYNSYM = 11; public static final int SHT_NUM = 12; public static final int SHT_LOPROC = 0x70000000; public static final int SHT_HIPROC = 0x7fffffff; public static final int SHT_LOUSER = 0x80000000; public static final int SHT_HIUSER = 0xffffffff; public static final int SHT_MIPS_LIST = 0x70000000; public static final int SHT_MIPS_CONFLICT = 0x70000002; public static final int SHT_MIPS_GPTAB = 0x70000003; public static final int SHT_MIPS_UCODE = 0x70000004; /*****************sh_flag***********************/ public static final int SHF_WRITE = 0x1; public static final int SHF_ALLOC = 0x2; public static final int SHF_EXECINSTR = 0x4; public static final int SHF_MASKPROC = 0xf0000000; public static final int SHF_MIPS_GPREL = 0x10000000; public void printShdrList(){ for(int i=0;i<shdrList.size();i++){ System.out.println(); System.out.println("The "+(i+1)+" Section Header:"); System.out.println(shdrList.get(i)); } } public static class elf32_strtb{ public byte[] str_name; public int len; @Override public String toString(){ return "str_name:"+str_name +"len:"+len; } }}这个没什么问题,也没难度,就是在看elf.h文件中定义的数据结构的时候,要记得每个字段的占用字节数就可以了。有了结构定义,下面就来看看如何解析吧。
在解析之前我们需要将so文件读取到byte[]中,定义一个数据结构类型
public static ElfType32 type_32 = new ElfType32();byte[] fileByteArys = Utils.readFile("so/libhello-jni.so");if(fileByteArys == null){ System.out.println("read file byte failed..."); return;}2、解析elf文件的头部信息

关于这些字段的解释,要看上面提到的那个pdf文件中的描述
这里我们介绍几个重要的字段,也是我们后面修改so文件的时候也会用到:
1)、e_phoff
这个字段是程序头(Program Header)内容在整个文件的偏移值,我们可以用这个偏移值来定位程序头的开始位置,用于解析程序头信息
2)、e_shoff
这个字段是段头(Section Header)内容在这个文件的偏移值,我们可以用这个偏移值来定位段头的开始位置,用于解析段头信息
3)、e_phnum
这个字段是程序头的个数,用于解析程序头信息
4)、e_shnum
这个字段是段头的个数,用于解析段头信息
5)、e_shstrndx
这个字段是String段在整个段列表中的索引值,这个用于后面定位String段的位置
按照上面的图我们就可以很容易的解析
/** * 解析Elf的头部信息 * @param header */private static void parseHeader(byte[] header, int offset){ if(header == null){ System.out.println("header is null"); return; } /** * public byte[] e_ident = new byte[16]; public short e_type; public short e_machine; public int e_version; public int e_entry; public int e_phoff; public int e_shoff; public int e_flags; public short e_ehsize; public short e_phentsize; public short e_phnum; public short e_shentsize; public short e_shnum; public short e_shstrndx; */ type_32.hdr.e_ident = Utils.copyBytes(header, 0, 16);//魔数 type_32.hdr.e_type = Utils.copyBytes(header, 16, 2); type_32.hdr.e_machine = Utils.copyBytes(header, 18, 2); type_32.hdr.e_version = Utils.copyBytes(header, 20, 4); type_32.hdr.e_entry = Utils.copyBytes(header, 24, 4); type_32.hdr.e_phoff = Utils.copyBytes(header, 28, 4); type_32.hdr.e_shoff = Utils.copyBytes(header, 32, 4); type_32.hdr.e_flags = Utils.copyBytes(header, 36, 4); type_32.hdr.e_ehsize = Utils.copyBytes(header, 40, 2); type_32.hdr.e_phentsize = Utils.copyBytes(header, 42, 2); type_32.hdr.e_phnum = Utils.copyBytes(header, 44,2); type_32.hdr.e_shentsize = Utils.copyBytes(header, 46,2); type_32.hdr.e_shnum = Utils.copyBytes(header, 48, 2); type_32.hdr.e_shstrndx = Utils.copyBytes(header, 50, 2);}按照对应的每个字段的字节个数,读取byte就可以了。3、解析段头(Section Header)信息
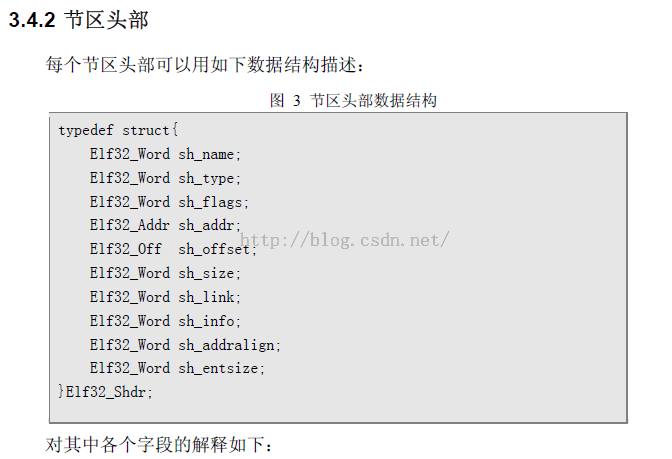
这个结构中字段见pdf中的描述吧,这里就不做解释了。后面我们会手动的构造这样的一个数据结构,到时候在详细说明每个字段含义。
按照这个结构。我们解析也简单了:
/** * 解析段头信息内容 */public static void parseSectionHeaderList(byte[] header, int offset){ int header_size = 40;//40个字节 int header_count = Utils.byte2Short(type_32.hdr.e_shnum);//头部的个数 byte[] des = new byte[header_size]; for(int i=0;i<header_count;i++){ System.arraycopy(header, i*header_size + offset, des, 0, header_size); type_32.shdrList.add(parseSectionHeader(des)); }}private static elf32_shdr parseSectionHeader(byte[] header){ ElfType32.elf32_shdr shdr = new ElfType32.elf32_shdr(); /** * public byte[] sh_name = new byte[4]; public byte[] sh_type = new byte[4]; public byte[] sh_flags = new byte[4]; public byte[] sh_addr = new byte[4]; public byte[] sh_offset = new byte[4]; public byte[] sh_size = new byte[4]; public byte[] sh_link = new byte[4]; public byte[] sh_info = new byte[4]; public byte[] sh_addralign = new byte[4]; public byte[] sh_entsize = new byte[4]; */ shdr.sh_name = Utils.copyBytes(header, 0, 4); shdr.sh_type = Utils.copyBytes(header, 4, 4); shdr.sh_flags = Utils.copyBytes(header, 8, 4); shdr.sh_addr = Utils.copyBytes(header, 12, 4); shdr.sh_offset = Utils.copyBytes(header, 16, 4); shdr.sh_size = Utils.copyBytes(header, 20, 4); shdr.sh_link = Utils.copyBytes(header, 24, 4); shdr.sh_info = Utils.copyBytes(header, 28, 4); shdr.sh_addralign = Utils.copyBytes(header, 32, 4); shdr.sh_entsize = Utils.copyBytes(header, 36, 4); return shdr;}这里需要注意的是,我们看到的Section Header一般都是多个的,这里用一个List来保存4、解析程序头(Program Header)信息

这里的字段,这里也不做解释了,看pdf文档。
我们按照这个结构来进行解析:
/** * 解析程序头信息 * @param header */public static void parseProgramHeaderList(byte[] header, int offset){ int header_size = 32;//32个字节 int header_count = Utils.byte2Short(type_32.hdr.e_phnum);//头部的个数 byte[] des = new byte[header_size]; for(int i=0;i<header_count;i++){ System.arraycopy(header, i*header_size + offset, des, 0, header_size); type_32.phdrList.add(parseProgramHeader(des)); }}private static elf32_phdr parseProgramHeader(byte[] header){ /** * public int p_type; public int p_offset; public int p_vaddr; public int p_paddr; public int p_filesz; public int p_memsz; public int p_flags; public int p_align; */ ElfType32.elf32_phdr phdr = new ElfType32.elf32_phdr(); phdr.p_type = Utils.copyBytes(header, 0, 4); phdr.p_offset = Utils.copyBytes(header, 4, 4); phdr.p_vaddr = Utils.copyBytes(header, 8, 4); phdr.p_paddr = Utils.copyBytes(header, 12, 4); phdr.p_filesz = Utils.copyBytes(header, 16, 4); phdr.p_memsz = Utils.copyBytes(header, 20, 4); phdr.p_flags = Utils.copyBytes(header, 24, 4); phdr.p_align = Utils.copyBytes(header, 28, 4); return phdr;}5、验证解析结果
那么上面我们的解析工作做完了,为了验证我们的解析工作是否正确,我们需要给每个结构定义个打印函数,也就是从写toString方法即可。

然后我们在使用readelf工具来查看so文件的各个结构内容,对比就可以知道解析的是否成功了。
解析代码下载地址:http://download.csdn.net/detail/jiangwei0910410003/9204119
上面我们用的是Java代码来进行解析的,为了照顾广大程序猿,所以给出一个C++版本的解析类:
#include<iostream.h>#include<string.h>#include<stdio.h>#include "elf.h"/** 非常重要的一个宏,功能很简单: P:需要对其的段地址 ALIGNBYTES:对其的字节数 功能:将P值补充到时ALIGNBYTES的整数倍 这个函数也叫:页面对其函数 eg: 0x3e45/0x1000 == >0x4000 */#define ALIGN(P, ALIGNBYTES) ( ((unsigned long)P + ALIGNBYTES -1)&~(ALIGNBYTES-1) )int addSectionFun(char*, char*, unsigned int);int main(){ addSectionFun("D:\libhello-jni.so", ".jiangwei", 0x1000); return 0;}int addSectionFun(char *lpPath, char *szSecname, unsigned int nNewSecSize){ char name[50]; FILE *fdr, *fdw; char *base = NULL; Elf32_Ehdr *ehdr; Elf32_Phdr *t_phdr, *load1, *load2, *dynamic; Elf32_Shdr *s_hdr; int flag = 0; int i = 0; unsigned mapSZ = 0; unsigned nLoop = 0; unsigned int nAddInitFun = 0; unsigned int nNewSecAddr = 0; unsigned int nModuleBase = 0; memset(name, 0, sizeof(name)); if(nNewSecSize == 0) { return 0; } fdr = fopen(lpPath, "rb"); strcpy(name, lpPath); if(strchr(name, '.')) { strcpy(strchr(name, '.'), "_new.so"); } else { strcat(name, "_new"); } fdw = fopen(name, "wb"); if(fdr == NULL || fdw == NULL) { printf("Open file failed"); return 1; } fseek(fdr, 0, SEEK_END); mapSZ = ftell(fdr);//源文件的长度大小 printf("mapSZ:0x%x\n", mapSZ); base = (char*)malloc(mapSZ * 2 + nNewSecSize);//2*源文件大小+新加的Section size printf("base 0x%x \n", base); memset(base, 0, mapSZ * 2 + nNewSecSize); fseek(fdr, 0, SEEK_SET); fread(base, 1, mapSZ, fdr);//拷贝源文件内容到base if(base == (void*) -1) { printf("fread fd failed"); return 2; } //判断Program Header ehdr = (Elf32_Ehdr*) base; t_phdr = (Elf32_Phdr*)(base + sizeof(Elf32_Ehdr)); for(i=0;i<ehdr->e_phnum;i++) { if(t_phdr->p_type == PT_LOAD) { //这里的flag只是一个标志位,去除第一个LOAD的Segment的值 if(flag == 0) { load1 = t_phdr; flag = 1; nModuleBase = load1->p_vaddr; printf("load1 = %p, offset = 0x%x \n", load1, load1->p_offset); } else { load2 = t_phdr; printf("load2 = %p, offset = 0x%x \n", load2, load2->p_offset); } } if(t_phdr->p_type == PT_DYNAMIC) { dynamic = t_phdr; printf("dynamic = %p, offset = 0x%x \n", dynamic, dynamic->p_offset); } t_phdr ++; } //section header s_hdr = (Elf32_Shdr*)(base + ehdr->e_shoff); //获取到新加section的位置,这个是重点,需要进行页面对其操作 printf("addr:0x%x\n",load2->p_paddr); nNewSecAddr = ALIGN(load2->p_paddr + load2->p_memsz - nModuleBase, load2->p_align); printf("new section add:%x \n", nNewSecAddr); if(load1->p_filesz < ALIGN(load2->p_paddr + load2->p_memsz, load2->p_align) ) { printf("offset:%x\n",(ehdr->e_shoff + sizeof(Elf32_Shdr) * ehdr->e_shnum)); //注意这里的代码的执行条件,这里其实就是判断section header是不是在文件的末尾 if( (ehdr->e_shoff + sizeof(Elf32_Shdr) * ehdr->e_shnum) != mapSZ) { if(mapSZ + sizeof(Elf32_Shdr) * (ehdr->e_shnum + 1) > nNewSecAddr) { printf("无法添加节\n"); return 3; } else { memcpy(base + mapSZ, base + ehdr->e_shoff, sizeof(Elf32_Shdr) * ehdr->e_shnum);//将Section Header拷贝到原来文件的末尾 ehdr->e_shoff = mapSZ; mapSZ += sizeof(Elf32_Shdr) * ehdr->e_shnum;//加上Section Header的长度 s_hdr = (Elf32_Shdr*)(base + ehdr->e_shoff); printf("ehdr_offset:%x",ehdr->e_shoff); } } } else { nNewSecAddr = load1->p_filesz; } printf("还可添加 %d 个节\n", (nNewSecAddr - ehdr->e_shoff) / sizeof(Elf32_Shdr) - ehdr->e_shnum - 1); int nWriteLen = nNewSecAddr + ALIGN(strlen(szSecname) + 1, 0x10) + nNewSecSize;//添加section之后的文件总长度:原来的长度 + section name + section size printf("write len %x\n",nWriteLen); char *lpWriteBuf = (char *)malloc(nWriteLen);//nWriteLen :最后文件的总大小 memset(lpWriteBuf, 0, nWriteLen); //ehdr->e_shstrndx是section name的string表在section表头中的偏移值,修改string段的大小 s_hdr[ehdr->e_shstrndx].sh_size = nNewSecAddr - s_hdr[ehdr->e_shstrndx].sh_offset + strlen(szSecname) + 1; strcpy(lpWriteBuf + nNewSecAddr, szSecname);//添加section name //以下代码是构建一个Section Header Elf32_Shdr newSecShdr = {0}; newSecShdr.sh_name = nNewSecAddr - s_hdr[ehdr->e_shstrndx].sh_offset; newSecShdr.sh_type = SHT_PROGBITS; newSecShdr.sh_flags = SHF_WRITE | SHF_ALLOC | SHF_EXECINSTR; nNewSecAddr += ALIGN(strlen(szSecname) + 1, 0x10); newSecShdr.sh_size = nNewSecSize; newSecShdr.sh_offset = nNewSecAddr; newSecShdr.sh_addr = nNewSecAddr + nModuleBase; newSecShdr.sh_addralign = 4; //修改Program Header信息 load1->p_filesz = nWriteLen; load1->p_memsz = nNewSecAddr + nNewSecSize; load1->p_flags = 7; //可读 可写 可执行 //修改Elf header中的section的count值 ehdr->e_shnum++; memcpy(lpWriteBuf, base, mapSZ);//从base中拷贝mapSZ长度的字节到lpWriteBuf memcpy(lpWriteBuf + mapSZ, &newSecShdr, sizeof(Elf32_Shdr));//将新加的Section Header追加到lpWriteBuf末尾 //写文件 fseek(fdw, 0, SEEK_SET); fwrite(lpWriteBuf, 1, nWriteLen, fdw); fclose(fdw); fclose(fdr); free(base); free(lpWriteBuf); return 0;}C++代码下载:http://download.csdn.net/detail/jiangwei0910410003/9204139
第五、总结
关于Elf文件的格式,就介绍到这里,通过自己写一个解析类的话,可以很深刻的了解elf文件的格式,所以我们在以后遇到一个文件格式的了解过程中,最好的方式就是手动的写一个工具类就好了。那么这篇文章是逆向之旅的第一篇,也是以后篇章的基础,下面一篇文章我们会介绍如何来手动的在elf中添加一个段数据结构,尽情期待~~
PS: 关注微信,最新Android技术实时推送

版权声明:本文为博主原创文章,未经博主允许不得转载。
- 1楼tyzhang1_08昨天 20:52
- 这路子太正统,不够野。n你像我,比如某天想知道某信用了什么技术底层,果断直接strings lib****.so | grep ****n是的,这种方式可以看见不少东西n比如strings ***.so | grep configure有时候可以看见编译配置之类的~n对于我当时只想了解下别人用了什么技术来说,足够,轻松,愉悦~~~
