一、前言
好长时间没有更新文章了,主要还是工作上的事,连续加班一个月,没有时间研究了,只有周末有时间,来看一下,不过我还是延续之前的文章,继续我们的逆向之旅,今天我们要来看一下如何通过对so加密,在介绍本篇文章之前的话,一定要先阅读之前的文章:
so文件格式详解以及如何解析一个so文件
http://blog.csdn.net/jiangwei0910410003/article/details/49336613
这个是我们今天这篇文章的基础,如果不了解so文件的格式的话,下面的知识点可能会看的很费劲
下面就来介绍我们今天的话题:对so中的section进行加密
二、技术原理
加密:在之前的文章中我们介绍了so中的格式,那么对于找到一个section的base和size就可以对这段section进行加密了
解密:因为我们对section进行加密之后,肯定需要解密的,不然的话,运行肯定是报错的,那么这里的重点是什么时候去进行解密,对于一个so文件,我们load进程序之后,在运行程序之前我们可以从哪个时间点来突破?这里就需要一个知识点:
__attribute__((constructor));
关于这个,属性的用法这里就不做介绍了,网上有相关资料,他的作用很简单,就是优先于main方法之前执行,类似于Java中的构造函数,当然其实C++中的构造函数就是基于这个属性实现的,我们在之前介绍elf文件格式的时候,有两个section会引起我们的注意:
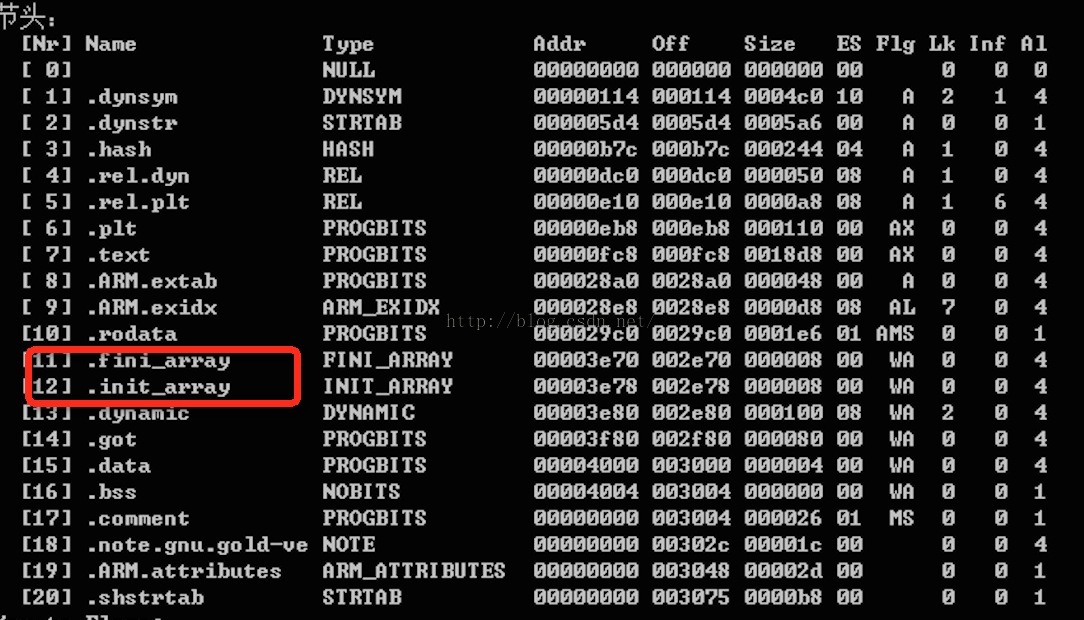
对于这两个section,其实就是用这个属性实现的函数存在这里,
在动态链接器构造了进程映像,并执行了重定位以后,每个共享的目标都获得执行 某些初始化代码的机会。这些初始化函数的被调用顺序是不一定的,不过所有共享目标 初始化都会在可执行文件得到控制之前发生。
类似地,共享目标也包含终止函数,这些函数在进程完成终止动作序列时,通过 atexit() 机制执行。动态链接器对终止函数的调用顺序是不确定的。
共享目标通过动态结构中的 DT_INIT 和 DT_FINI 条目指定初始化/终止函数。通常 这些代码放在.init 和.fini 节区中。
这个知识点很重要,我们后面在进行动态调试so的时候,还会用到这个知识点,所以一定要理解。
所以,在这里我们找到了解密的时机,就是自己定义一个解密函数,然后用上面的这个属性声明就可以了。
三、实现流程
第一、我们编写一个简单的native代码,这里我们需要做两件事:
1、将我们核心的native函数定义在自己的一个section中,这里会用到这个属性:__attribute__((section (".mytext")));
其中.mytext就是我们自己定义的section.
说到这里,还记得我们之前介绍的一篇文章中介绍了,动态的给so添加一个section:
http://blog.csdn.net/jiangwei0910410003/article/details/49361281
2、需要编写我们的解密函数,用属性: __attribute__((constructor));声明
这样一个native程序就包含这两个重要的函数,使用ndk编译成so文件
第二、编写加密程序,在加密程序中我们需要做的是:
1、通过解析so文件,找到.mytext段的起始地址和大小,这里的思路是:
找到所有的Section,然后获取他的name字段,在结合String Section,遍历找到.mytext字段
2、找到.mytext段之后,然后进行加密,最后在写入到文件中。
四、技术实现
前面介绍了原理和实现方案,下面就开始coding吧,
第一、我们先来看看native程序
#include <jni.h>#include <stdio.h>#include <android/log.h>#include <stdlib.h>#include <string.h>#include <unistd.h>#include <sys/types.h>#include <elf.h>#include <sys/mman.h>jstring getString(JNIEnv*) __attribute__((section (".mytext")));jstring getString(JNIEnv* env){ return (*env)->NewStringUTF(env, "Native method return!");};void init_getString() __attribute__((constructor));unsigned long getLibAddr();void init_getString(){ char name[15]; unsigned int nblock; unsigned int nsize; unsigned long base; unsigned long text_addr; unsigned int i; Elf32_Ehdr *ehdr; Elf32_Shdr *shdr; base = getLibAddr(); ehdr = (Elf32_Ehdr *)base; text_addr = ehdr->e_shoff + base; nblock = ehdr->e_entry >> 16; nsize = ehdr->e_entry & 0xffff; __android_log_print(ANDROID_LOG_INFO, "JNITag", "nblock = 0x%x,nsize:%d", nblock,nsize); __android_log_print(ANDROID_LOG_INFO, "JNITag", "base = 0x%x", text_addr); printf("nblock = %d\n", nblock); if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){ puts("mem privilege change failed"); __android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed"); } for(i=0;i< nblock; i++){ char *addr = (char*)(text_addr + i); *addr = ~(*addr); } if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC) != 0){ puts("mem privilege change failed"); } puts("Decrypt success");}unsigned long getLibAddr(){ unsigned long ret = 0; char name[] = "libdemo.so"; char buf[4096], *temp; int pid; FILE *fp; pid = getpid(); sprintf(buf, "/proc/%d/maps", pid); fp = fopen(buf, "r"); if(fp == NULL) { puts("open failed"); goto _error; } while(fgets(buf, sizeof(buf), fp)){ if(strstr(buf, name)){ temp = strtok(buf, "-"); ret = strtoul(temp, NULL, 16); break; } }_error: fclose(fp); return ret;}JNIEXPORT jstring JNICALLJava_com_example_shelldemo_MainActivity_getString( JNIEnv* env, jobject thiz ){#if defined(__arm__) #if defined(__ARM_ARCH_7A__) #if defined(__ARM_NEON__) #define ABI "armeabi-v7a/NEON" #else #define ABI "armeabi-v7a" #endif #else #define ABI "armeabi" #endif#elif defined(__i386__) #define ABI "x86"#elif defined(__mips__) #define ABI "mips"#else #define ABI "unknown"#endif return getString(env);}下面来分析一下代码:1、定义自己的段
jstring getString(JNIEnv*) __attribute__((section (".mytext")));jstring getString(JNIEnv* env){ return (*env)->NewStringUTF(env, "Native method return!");};这里的getString返回一个字符串,提供给Android上层,然后将getString定义在.mytext段中。2、获取so加载到内存中的起始地址
unsigned long getLibAddr(){ unsigned long ret = 0; char name[] = "libdemo.so"; char buf[4096], *temp; int pid; FILE *fp; pid = getpid(); sprintf(buf, "/proc/%d/maps", pid); fp = fopen(buf, "r"); if(fp == NULL) { puts("open failed"); goto _error; } while(fgets(buf, sizeof(buf), fp)){ if(strstr(buf, name)){ temp = strtok(buf, "-"); ret = strtoul(temp, NULL, 16); break; } }_error: fclose(fp); return ret;}这里的代码其实就是读取设备的proc/<uid>/maps中的内容,因为这个maps中是程序运行的内存映像:
我们只有获取到so的起始地址,才能找到指定的Section然后进行解密。
3、解密函数
void init_getString(){ char name[15]; unsigned int nblock; unsigned int nsize; unsigned long base; unsigned long text_addr; unsigned int i; Elf32_Ehdr *ehdr; Elf32_Shdr *shdr; //获取so的起始地址 base = getLibAddr(); //获取指定section的偏移值和size ehdr = (Elf32_Ehdr *)base; text_addr = ehdr->e_shoff + base; nblock = ehdr->e_entry >> 16; nsize = ehdr->e_entry & 0xffff; __android_log_print(ANDROID_LOG_INFO, "JNITag", "nblock = 0x%x,nsize:%d", nblock,nsize); __android_log_print(ANDROID_LOG_INFO, "JNITag", "base = 0x%x", text_addr); printf("nblock = %d\n", nblock); //修改内存的操作权限 if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){ puts("mem privilege change failed"); __android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed"); } //解密 for(i=0;i< nblock; i++){ char *addr = (char*)(text_addr + i); *addr = ~(*addr); } if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC) != 0){ puts("mem privilege change failed"); } puts("Decrypt success");}这里我们获取到so文件的头部,然后获取指定section的偏移地址和size//获取so的起始地址base = getLibAddr();//获取指定section的偏移值和sizeehdr = (Elf32_Ehdr *)base;text_addr = ehdr->e_shoff + base;nblock = ehdr->e_entry >> 16;nsize = ehdr->e_entry & 0xffff;这里可能会有困惑?为什么这里是这么获取offset和size的,其实这里我们做了一点工作,就是我们在加密的时候顺便改写了so的头部信息,将offset和size值写到了头部中,这样加大破解难度。后面在说到加密的时候在详解。
text_addr是起始地址+偏移值,就是我们的section在内存中的绝对地址
nsize是我们的section占用的页数
然后修改这个section的内存操作权限
//修改内存的操作权限if(mprotect((void *) (text_addr / PAGE_SIZE * PAGE_SIZE), 4096 * nsize, PROT_READ | PROT_EXEC | PROT_WRITE) != 0){ puts("mem privilege change failed"); __android_log_print(ANDROID_LOG_INFO, "JNITag", "mem privilege change failed");}这里调用了一个系统函数:mprotect第一个参数:需要修改内存的起始地址
必须需要页面对齐,也就是必须是页面PAGE_SIZE(0x1000=4096)的整数倍
第二个参数:需要修改的大小
占用的页数*PAGE_SIZE
第三个参数:权限值
最后读取内存中的section内容,然后进行解密,在将内存权限修改回去。
然后使用ndk编译成so即可,这里我们用到了系统的打印log信息,所以需要用到共享库,看一下编译脚本Android.mk
LOCAL_PATH := $(call my-dir)include $(CLEAR_VARS)LOCAL_MODULE := demoLOCAL_SRC_FILES := demo.cLOCAL_LDLIBS := -lloginclude $(BUILD_SHARED_LIBRARY)
关于如何使用ndk,这里就不做介绍了,参考这篇文章:
http://blog.csdn.net/jiangwei0910410003/article/details/17710243
第二、加密程序
1、加密程序(Java版)
我们获取到上面的so文件,下面我们就来看看如何进行加密的:
package com.jiangwei.encodesection;import com.jiangwei.encodesection.ElfType32.Elf32_Sym;import com.jiangwei.encodesection.ElfType32.elf32_phdr;import com.jiangwei.encodesection.ElfType32.elf32_shdr;public class EncodeSection { public static String encodeSectionName = ".mytext"; public static ElfType32 type_32 = new ElfType32(); public static void main(String[] args){ byte[] fileByteArys = Utils.readFile("so/libdemo.so"); if(fileByteArys == null){ System.out.println("read file byte failed..."); return; } /** * 先解析so文件 * 然后初始化AddSection中的一些信息 * 最后在AddSection */ parseSo(fileByteArys); encodeSection(fileByteArys); parseSo(fileByteArys); Utils.saveFile("so/libdemos.so", fileByteArys); } private static void encodeSection(byte[] fileByteArys){ //读取String Section段 System.out.println(); int string_section_index = Utils.byte2Short(type_32.hdr.e_shstrndx); elf32_shdr shdr = type_32.shdrList.get(string_section_index); int size = Utils.byte2Int(shdr.sh_size); int offset = Utils.byte2Int(shdr.sh_offset); int mySectionOffset=0,mySectionSize=0; for(elf32_shdr temp : type_32.shdrList){ int sectionNameOffset = offset+Utils.byte2Int(temp.sh_name); if(Utils.isEqualByteAry(fileByteArys, sectionNameOffset, encodeSectionName)){ //这里需要读取section段然后进行数据加密 mySectionOffset = Utils.byte2Int(temp.sh_offset); mySectionSize = Utils.byte2Int(temp.sh_size); byte[] sectionAry = Utils.copyBytes(fileByteArys, mySectionOffset, mySectionSize); for(int i=0;i<sectionAry.length;i++){ sectionAry[i] = (byte)(sectionAry[i] ^ 0xFF); } Utils.replaceByteAry(fileByteArys, mySectionOffset, sectionAry); } } //修改Elf Header中的entry和offset值 int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1); byte[] entry = new byte[4]; entry = Utils.int2Byte((mySectionSize<<16) + nSize); Utils.replaceByteAry(fileByteArys, 24, entry); byte[] offsetAry = new byte[4]; offsetAry = Utils.int2Byte(mySectionOffset); Utils.replaceByteAry(fileByteArys, 32, offsetAry); } private static void parseSo(byte[] fileByteArys){ //读取头部内容 System.out.println("+++++++++++++++++++Elf Header+++++++++++++++++"); parseHeader(fileByteArys, 0); System.out.println("header:\n"+type_32.hdr); //读取程序头信息 //System.out.println(); //System.out.println("+++++++++++++++++++Program Header+++++++++++++++++"); int p_header_offset = Utils.byte2Int(type_32.hdr.e_phoff); parseProgramHeaderList(fileByteArys, p_header_offset); //type_32.printPhdrList(); //读取段头信息 //System.out.println(); //System.out.println("+++++++++++++++++++Section Header++++++++++++++++++"); int s_header_offset = Utils.byte2Int(type_32.hdr.e_shoff); parseSectionHeaderList(fileByteArys, s_header_offset); //type_32.printShdrList(); //这种方式获取所有的Section的name /*byte[] names = Utils.copyBytes(fileByteArys, offset, size); String str = new String(names); byte NULL = 0;//字符串的结束符 StringTokenizer st = new StringTokenizer(str, new String(new byte[]{NULL})); System.out.println( "Token Total: " + st.countTokens() ); while(st.hasMoreElements()){ System.out.println(st.nextToken()); } System.out.println("");*/ /*//读取符号表信息(Symbol Table) System.out.println(); System.out.println("+++++++++++++++++++Symbol Table++++++++++++++++++"); //这里需要注意的是:在Elf表中没有找到SymbolTable的数目,但是我们仔细观察Section中的Type=DYNSYM段的信息可以得到,这个段的大小和偏移地址,而SymbolTable的结构大小是固定的16个字节 //那么这里的数目=大小/结构大小 //首先在SectionHeader中查找到dynsym段的信息 int offset_sym = 0; int total_sym = 0; for(elf32_shdr shdr : type_32.shdrList){ if(Utils.byte2Int(shdr.sh_type) == ElfType32.SHT_DYNSYM){ total_sym = Utils.byte2Int(shdr.sh_size); offset_sym = Utils.byte2Int(shdr.sh_offset); break; } } int num_sym = total_sym / 16; System.out.println("sym num="+num_sym); parseSymbolTableList(fileByteArys, num_sym, offset_sym); type_32.printSymList(); //读取字符串表信息(String Table) System.out.println(); System.out.println("+++++++++++++++++++Symbol Table++++++++++++++++++"); //这里需要注意的是:在Elf表中没有找到StringTable的数目,但是我们仔细观察Section中的Type=STRTAB段的信息,可以得到,这个段的大小和偏移地址,但是我们这时候我们不知道字符串的大小,所以就获取不到数目了 //这里我们可以查看Section结构中的name字段:表示偏移值,那么我们可以通过这个值来获取字符串的大小 //可以这么理解:当前段的name值 减去 上一段的name的值 = (上一段的name字符串的长度) //首先获取每个段的name的字符串大小 int prename_len = 0; int[] lens = new int[type_32.shdrList.size()]; int total = 0; for(int i=0;i<type_32.shdrList.size();i++){ if(Utils.byte2Int(type_32.shdrList.get(i).sh_type) == ElfType32.SHT_STRTAB){ int curname_offset = Utils.byte2Int(type_32.shdrList.get(i).sh_name); lens[i] = curname_offset - prename_len - 1; if(lens[i] < 0){ lens[i] = 0; } total += lens[i]; System.out.println("total:"+total); prename_len = curname_offset; //这里需要注意的是,最后一个字符串的长度,需要用总长度减去前面的长度总和来获取到 if(i == (lens.length - 1)){ System.out.println("size:"+Utils.byte2Int(type_32.shdrList.get(i).sh_size)); lens[i] = Utils.byte2Int(type_32.shdrList.get(i).sh_size) - total - 1; } } } for(int i=0;i<lens.length;i++){ System.out.println("len:"+lens[i]); } //上面的那个方法不好,我们发现StringTable中的每个字符串结束都会有一个00(传说中的字符串结束符),那么我们只要知道StringTable的开始位置,然后就可以读取到每个字符串的值了 */ } /** * 解析Elf的头部信息 * @param header */ private static void parseHeader(byte[] header, int offset){ if(header == null){ System.out.println("header is null"); return; } /** * public byte[] e_ident = new byte[16]; public short e_type; public short e_machine; public int e_version; public int e_entry; public int e_phoff; public int e_shoff; public int e_flags; public short e_ehsize; public short e_phentsize; public short e_phnum; public short e_shentsize; public short e_shnum; public short e_shstrndx; */ type_32.hdr.e_ident = Utils.copyBytes(header, 0, 16);//魔数 type_32.hdr.e_type = Utils.copyBytes(header, 16, 2); type_32.hdr.e_machine = Utils.copyBytes(header, 18, 2); type_32.hdr.e_version = Utils.copyBytes(header, 20, 4); type_32.hdr.e_entry = Utils.copyBytes(header, 24, 4); type_32.hdr.e_phoff = Utils.copyBytes(header, 28, 4); type_32.hdr.e_shoff = Utils.copyBytes(header, 32, 4); type_32.hdr.e_flags = Utils.copyBytes(header, 36, 4); type_32.hdr.e_ehsize = Utils.copyBytes(header, 40, 2); type_32.hdr.e_phentsize = Utils.copyBytes(header, 42, 2); type_32.hdr.e_phnum = Utils.copyBytes(header, 44,2); type_32.hdr.e_shentsize = Utils.copyBytes(header, 46,2); type_32.hdr.e_shnum = Utils.copyBytes(header, 48, 2); type_32.hdr.e_shstrndx = Utils.copyBytes(header, 50, 2); } /** * 解析程序头信息 * @param header */ public static void parseProgramHeaderList(byte[] header, int offset){ int header_size = 32;//32个字节 int header_count = Utils.byte2Short(type_32.hdr.e_phnum);//头部的个数 byte[] des = new byte[header_size]; for(int i=0;i<header_count;i++){ System.arraycopy(header, i*header_size + offset, des, 0, header_size); type_32.phdrList.add(parseProgramHeader(des)); } } private static elf32_phdr parseProgramHeader(byte[] header){ /** * public int p_type; public int p_offset; public int p_vaddr; public int p_paddr; public int p_filesz; public int p_memsz; public int p_flags; public int p_align; */ ElfType32.elf32_phdr phdr = new ElfType32.elf32_phdr(); phdr.p_type = Utils.copyBytes(header, 0, 4); phdr.p_offset = Utils.copyBytes(header, 4, 4); phdr.p_vaddr = Utils.copyBytes(header, 8, 4); phdr.p_paddr = Utils.copyBytes(header, 12, 4); phdr.p_filesz = Utils.copyBytes(header, 16, 4); phdr.p_memsz = Utils.copyBytes(header, 20, 4); phdr.p_flags = Utils.copyBytes(header, 24, 4); phdr.p_align = Utils.copyBytes(header, 28, 4); return phdr; } /** * 解析段头信息内容 */ public static void parseSectionHeaderList(byte[] header, int offset){ int header_size = 40;//40个字节 int header_count = Utils.byte2Short(type_32.hdr.e_shnum);//头部的个数 byte[] des = new byte[header_size]; for(int i=0;i<header_count;i++){ System.arraycopy(header, i*header_size + offset, des, 0, header_size); type_32.shdrList.add(parseSectionHeader(des)); } } private static elf32_shdr parseSectionHeader(byte[] header){ ElfType32.elf32_shdr shdr = new ElfType32.elf32_shdr(); /** * public byte[] sh_name = new byte[4]; public byte[] sh_type = new byte[4]; public byte[] sh_flags = new byte[4]; public byte[] sh_addr = new byte[4]; public byte[] sh_offset = new byte[4]; public byte[] sh_size = new byte[4]; public byte[] sh_link = new byte[4]; public byte[] sh_info = new byte[4]; public byte[] sh_addralign = new byte[4]; public byte[] sh_entsize = new byte[4]; */ shdr.sh_name = Utils.copyBytes(header, 0, 4); shdr.sh_type = Utils.copyBytes(header, 4, 4); shdr.sh_flags = Utils.copyBytes(header, 8, 4); shdr.sh_addr = Utils.copyBytes(header, 12, 4); shdr.sh_offset = Utils.copyBytes(header, 16, 4); shdr.sh_size = Utils.copyBytes(header, 20, 4); shdr.sh_link = Utils.copyBytes(header, 24, 4); shdr.sh_info = Utils.copyBytes(header, 28, 4); shdr.sh_addralign = Utils.copyBytes(header, 32, 4); shdr.sh_entsize = Utils.copyBytes(header, 36, 4); return shdr; } /** * 解析Symbol Table内容 */ public static void parseSymbolTableList(byte[] header, int header_count, int offset){ int header_size = 16;//16个字节 byte[] des = new byte[header_size]; for(int i=0;i<header_count;i++){ System.arraycopy(header, i*header_size + offset, des, 0, header_size); type_32.symList.add(parseSymbolTable(des)); } } private static ElfType32.Elf32_Sym parseSymbolTable(byte[] header){ /** * public byte[] st_name = new byte[4]; public byte[] st_value = new byte[4]; public byte[] st_size = new byte[4]; public byte st_info; public byte st_other; public byte[] st_shndx = new byte[2]; */ Elf32_Sym sym = new Elf32_Sym(); sym.st_name = Utils.copyBytes(header, 0, 4); sym.st_value = Utils.copyBytes(header, 4, 4); sym.st_size = Utils.copyBytes(header, 8, 4); sym.st_info = header[12]; //FIXME 这里有一个问题,就是这个字段读出来的值始终是0 sym.st_other = header[13]; sym.st_shndx = Utils.copyBytes(header, 14, 2); return sym; } }在这里,我需要解析so文件的头部信息,程序头信息,段头信息//读取头部内容System.out.println("+++++++++++++++++++Elf Header+++++++++++++++++");parseHeader(fileByteArys, 0);System.out.println("header:\n"+type_32.hdr);//读取程序头信息//System.out.println();//System.out.println("+++++++++++++++++++Program Header+++++++++++++++++");int p_header_offset = Utils.byte2Int(type_32.hdr.e_phoff);parseProgramHeaderList(fileByteArys, p_header_offset);//type_32.printPhdrList();//读取段头信息//System.out.println();//System.out.println("+++++++++++++++++++Section Header++++++++++++++++++");int s_header_offset = Utils.byte2Int(type_32.hdr.e_shoff);parseSectionHeaderList(fileByteArys, s_header_offset);//type_32.printShdrList();关于这个解析的工作说明这里就不解析了,看之前解析elf文件的那篇文章。
获取这些信息之后,下面就来开始寻找我们的段了,只需要遍历Section列表,找到名字是.mytext的section即可,然后获取offset和size,对内容进行加密,回写到文件中。下面来看看核心方法:
private static void encodeSection(byte[] fileByteArys){ //读取String Section段 System.out.println(); int string_section_index = Utils.byte2Short(type_32.hdr.e_shstrndx); elf32_shdr shdr = type_32.shdrList.get(string_section_index); int size = Utils.byte2Int(shdr.sh_size); int offset = Utils.byte2Int(shdr.sh_offset); int mySectionOffset=0,mySectionSize=0; for(elf32_shdr temp : type_32.shdrList){ int sectionNameOffset = offset+Utils.byte2Int(temp.sh_name); if(Utils.isEqualByteAry(fileByteArys, sectionNameOffset, encodeSectionName)){ //这里需要读取section段然后进行数据加密 mySectionOffset = Utils.byte2Int(temp.sh_offset); mySectionSize = Utils.byte2Int(temp.sh_size); byte[] sectionAry = Utils.copyBytes(fileByteArys, mySectionOffset, mySectionSize); for(int i=0;i<sectionAry.length;i++){ sectionAry[i] = (byte)(sectionAry[i] ^ 0xFF); } Utils.replaceByteAry(fileByteArys, mySectionOffset, sectionAry); } } //修改Elf Header中的entry和offset值 int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1); byte[] entry = new byte[4]; entry = Utils.int2Byte((mySectionSize<<16) + nSize); Utils.replaceByteAry(fileByteArys, 24, entry); byte[] offsetAry = new byte[4]; offsetAry = Utils.int2Byte(mySectionOffset); Utils.replaceByteAry(fileByteArys, 32, offsetAry);}我们知道Section中的sh_name字段的值是这个section段的name在StringSection中的索引值,这里offset就是StringSection在文件中的偏移值。当然我们需要知道的一个知识点就是:StringSection中的每个name都是以\0结尾的,所以我们只需要判断字符串到结束符就可以了,判断方法是Utils.isEqualByteAry:public static boolean isEqualByteAry(byte[] src, int start, String destStr){ if(destStr == null){ return false; } byte[] dest = destStr.getBytes(); if(src == null || dest == null){ return false; } if(dest.length == 0 || src.length == 0){ return false; } if(start >= src.length){ return false; } int len = 0; byte temp = src[start]; while(temp != 0){ len++; temp = src[start+len]; } byte[] sonAry = copyBytes(src, start, len); if(sonAry == null || sonAry.length == 0){ return false; } if(sonAry.length != dest.length){ return false; } String sonStr = new String(sonAry); if(destStr.equals(sonStr)){ return true; } return false;}这里我们加密的方法很简单,加密完成之后,我们需要做的是回写到so文件中,当然这里我们还需要做一件事,就是将我们加密的.mytext段的偏移值和pageSize保存到头部信息中://修改Elf Header中的entry和offset值int nSize = mySectionSize/4096 + (mySectionSize%4096 == 0 ? 0 : 1);byte[] entry = new byte[4];entry = Utils.int2Byte((mySectionSize<<16) + nSize);Utils.replaceByteAry(fileByteArys, 24, entry);这里又有一个知识点需要说明?大家可能会困惑,我们这样修改了so的头部信息的话,在加载运行so文件的时候不会报错吗?这个就要看看Android底层是如何解析so文件,然后将so文件映射到内存中的了,下面我们来看看系统是如何解析so文件的?
源代码的位置:Android linker源码:bionic\linker
在linker.h源码中有一个重要的结构体soinfo,下面列出一些字段:
struct soinfo{ const char name[SOINFO_NAME_LEN]; //so全名 Elf32_Phdr *phdr; //Program header的地址int phnum; //segment 数量unsigned *dynamic; //指向.dynamic,在section和segment中相同的//以下4个成员与.hash表有关unsigned nbucket;unsigned nchain;unsigned *bucket;unsigned *chain;//这两个成员只能会出现在可执行文件中unsigned *preinit_array;unsigned preinit_array_count;指向初始化代码,先于main函数之行,即在加载时被linker所调用,在linker.c可以看到:__linker_init -> link_image ->
call_constructors -> call_arrayunsigned *init_array;unsigned init_array_count;void (*init_func)(void);//与init_array类似,只是在main结束之后执行unsigned *fini_array;unsigned fini_array_count;void (*fini_func)(void);}
另外,linker.c中也有许多地方可以佐证。其本质还是linker是基于装载视图解析的so文件的。
基于上面的结论,再来分析下ELF头的字段。
1) e_ident[EI_NIDENT] 字段包含魔数、字节序、字长和版本,后面填充0。对于安卓的linker,通过verify_elf_object函数检验魔数,判定是否为.so文件。那么,我们可以向位置写入数据,至少可以向后面的0填充位置写入数据。遗憾的是,我在fedora 14下测试,是不能向0填充位置写数据,链接器报非0填充错误。
2) 对于安卓的linker,对e_type、e_machine、e_version和e_flags字段并不关心,是可以修改成其他数据的(仅分析,没有实测)
3) 对于动态链接库,e_entry 入口地址是无意义的,因为程序被加载时,设定的跳转地址是动态连接器的地址,这个字段是可以被作为数据填充的。
4) so装载时,与链接视图没有关系,即e_shoff、e_shentsize、e_shnum和e_shstrndx这些字段是可以任意修改的。被修改之后,使用readelf和ida等工具打开,会报各种错误,相信读者已经见识过了。
5) 既然so装载与装载视图紧密相关,自然e_phoff、e_phentsize和e_phnum这些字段是不能动的。
从上面我们可以知道,so中的有些信息在运行的时候是没有用途的,有些东西是不能改的。
2、加密程序(C版)
上面说的是Java版本的,下面再来一个C版本的:
#include <stdio.h>#include <fcntl.h>#include "elf.h"#include <stdlib.h>#include <string.h>int main(int argc, char** argv){ char *encodeSoName = "libdemo.so"; char target_section[] = ".mytext"; char *shstr = NULL; char *content = NULL; Elf32_Ehdr ehdr; Elf32_Shdr shdr; int i; unsigned int base, length; unsigned short nblock; unsigned short nsize; unsigned char block_size = 16; int fd; fd = open(encodeSoName, O_RDWR); if(fd < 0){ printf("open %s failed\n", argv[1]); goto _error; } if(read(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){ puts("Read ELF header error"); goto _error; } lseek(fd, ehdr.e_shoff + sizeof(Elf32_Shdr) * ehdr.e_shstrndx, SEEK_SET); if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){ puts("Read ELF section string table error"); goto _error; } if((shstr = (char *) malloc(shdr.sh_size)) == NULL){ puts("Malloc space for section string table failed"); goto _error; } lseek(fd, shdr.sh_offset, SEEK_SET); if(read(fd, shstr, shdr.sh_size) != shdr.sh_size){ puts("Read string table failed"); goto _error; } lseek(fd, ehdr.e_shoff, SEEK_SET); for(i = 0; i < ehdr.e_shnum; i++){ if(read(fd, &shdr, sizeof(Elf32_Shdr)) != sizeof(Elf32_Shdr)){ puts("Find section .text procedure failed"); goto _error; } if(strcmp(shstr + shdr.sh_name, target_section) == 0){ base = shdr.sh_offset; length = shdr.sh_size; printf("Find section %s\n", target_section); break; } } lseek(fd, base, SEEK_SET); content = (char*) malloc(length); if(content == NULL){ puts("Malloc space for content failed"); goto _error; } if(read(fd, content, length) != length){ puts("Read section .text failed"); goto _error; } nblock = length / block_size; nsize = length / 4096 + (length % 4096 == 0 ? 0 : 1); printf("base = %x, length = %x\n", base, length); printf("nblock = %d, nsize = %d\n", nblock, nsize); printf("entry:%x\n",((length << 16) + nsize)); ehdr.e_entry = (length << 16) + nsize; ehdr.e_shoff = base; for(i=0;i<length;i++){ content[i] = ~content[i]; } lseek(fd, 0, SEEK_SET); if(write(fd, &ehdr, sizeof(Elf32_Ehdr)) != sizeof(Elf32_Ehdr)){ puts("Write ELFhead to .so failed"); goto _error; } lseek(fd, base, SEEK_SET); if(write(fd, content, length) != length){ puts("Write modified content to .so failed"); goto _error; } puts("Completed");_error: free(content); free(shstr); close(fd); return 0;}这里就不做详细解释了
我们在上面加密完成之后,我们可以验证一下,使用readelf命令查看一下:

哈哈,加密成功,我们在用IDA查看一下:
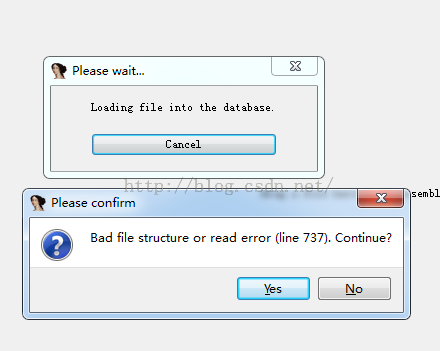
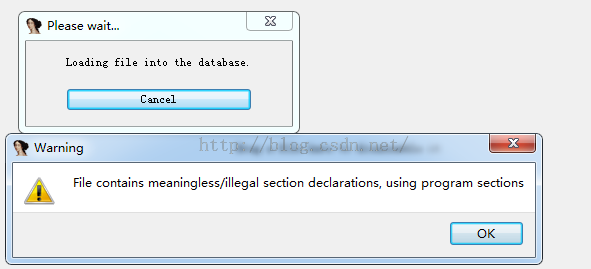
会有错误提示,但是我们点击OK,还是成功打开了so文件,但是我们ctrl+s查看段信息的时候:
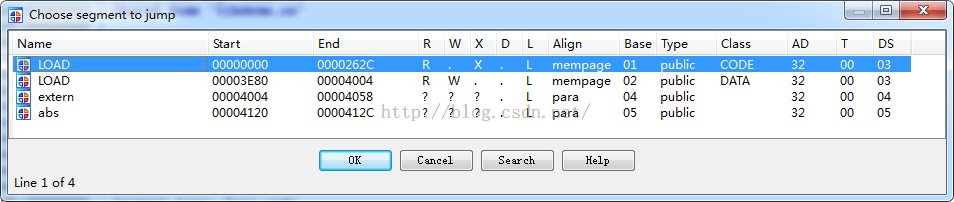
也是没有看到我们的段信息,我们可以看一下我们没有加密前的效果:
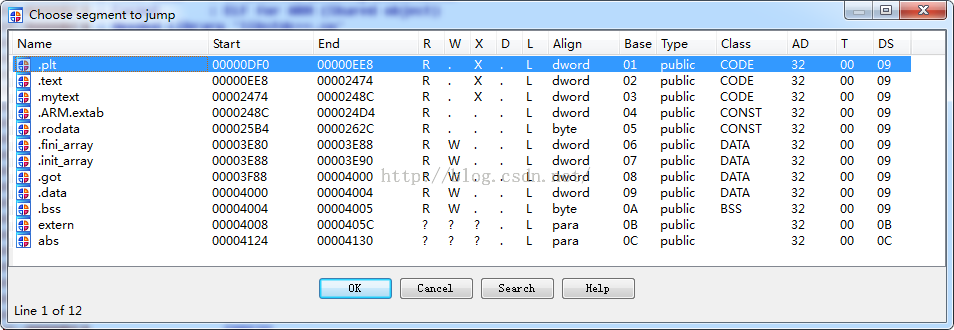
既然加密成功了,那么下面我们得验证一下能否运行成功
第三、Android测试demo
我们在获取加密之后的so文件之后,我们用Android工程测试一下:
package com.example.shelldemo;import android.app.Activity;import android.os.Bundle;import android.view.Menu;import android.view.MenuItem;import android.widget.TextView;public class MainActivity extends Activity { private TextView tv; private native String getString(); static{ System.loadLibrary("demo"); } @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); tv = (TextView) findViewById(R.id.tv); tv.setText(getString()); }}运行结果:
看到了,运行成功了。
案例下载地址:http://download.csdn.net/detail/jiangwei0910410003/9288051
五、技术总结
1、Elf文件格式的深入了解
2、两个属性的了解:__attribute__((constructor)); __attribute__((section (".mytext")));
3、程序的maps内存映像了解
4、修改内存属性方法
5、Android系统如何解析so文件linker源码
六、梳理流程步骤
加密流程:
1) 从so文件头读取section偏移shoff、shnum和shstrtab
2) 读取shstrtab中的字符串,存放在str空间中
3) 从shoff位置开始读取section header, 存放在shdr
4) 通过shdr -> sh_name 在str字符串中索引,与.mytext进行字符串比较,如果不匹配,继续读取
5) 通过shdr -> sh_offset 和 shdr -> sh_size字段,将.mytext内容读取并保存在content中。
6) 为了便于理解,不使用复杂的加密算法。这里,只将content的所有内容取反,即 *content = ~(*content);
7) 将content内容写回so文件中
8) 为了验证第二节中关于section 字段可以任意修改的结论,这里,将shdr -> addr 写入ELF头e_shoff,将shdr -> sh_size 和 addr 所在内存块写入e_entry中,即ehdr.e_entry = (length << 16) + nsize。当然,这样同时也简化了解密流程,还有一个好处是:如果将so文件头修正放回去,程序是不能运行的。
解密时,需要保证解密函数在so加载时被调用,那函数声明为:init_getString __attribute__((constructor))。(也可以使用c++构造器实现, 其本质也是用attribute实现)
解密流程:
1) 动态链接器通过call_array调用init_getString
2) Init_getString首先调用getLibAddr方法,得到so文件在内存中的起始地址
3) 读取前52字节,即ELF头。通过e_shoff获得.mytext内存加载地址,ehdr.e_entry获取.mytext大小和所在内存块
4) 修改.mytext所在内存块的读写权限
5) 将[e_shoff, e_shoff + size]内存区域数据解密,即取反操作:*content = ~(*content);
6) 修改回内存区域的读写权限
(这里是对代码段的数据进行解密,需要写权限。如果对数据段的数据解密,是不需要更改权限直接操作的)
六、总结
这篇文章主要介绍了如何对so中的section进行加密,然后将我们的native函数存到这个section中,从而达到对我们函数的实现的加密,这样对于后续的破解工作加大难度,但是还是那句话,没有绝对的安全,这种方式还是很容易破解的,动态调试so,在init出下断点,就可以跟到我们这里的init_getString函数的实现了。关于动态调试的知识点大家不要着急,后续我会详细讲解的,所以说攻与防是永不停息的战争。下一篇我会继续介绍如何对指定的函数进行加密,难度加大。。期待~~
PS: 关注微信,最新Android技术实时推送

