转自:http://www.cnblogs.com/tmyh/archive/2010/09/29/sqlindex_01.html
?
我们来简单地看看SQL SERVER索引是如何工作的,关于索引的一些概念就不说了。
?
?
聚簇索引:
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
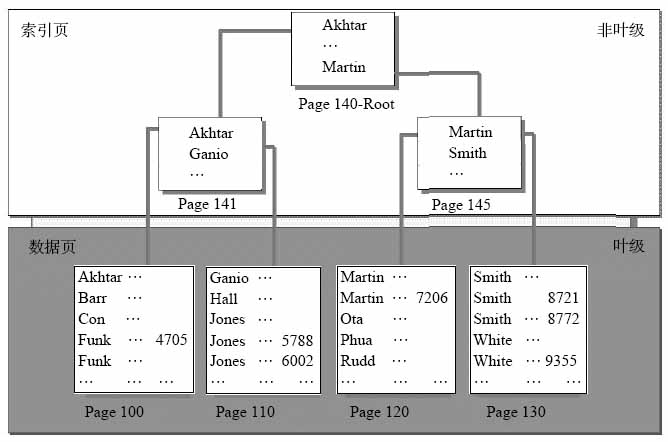
(图A)
?
我们来看图A,聚簇索引的结构图。
数据页就是数据库里实际存储数据的地方,可以看到是按页1页1页存的。
假设那个列是”LastName”。
因为是聚集索引,所以它是按照顺序排下来的。可以看到,索引是一棵树,首先先看一下这棵树是怎么形成的。
先看Page100和Page110的最上面,由它们形成了Page141,Page141的第一条数据是Page100的第一条数据,Page141的最后一条数据是Page110的第一条数据。同理由Page120和Page130形成Page145,Page141和Page145形成根Page140.
好了,然后来看看它是如何查找数据的。
我们来找”Rudd”这个姓。
首先它会从根即Page140开始找,因为”Rudd”的值比”Martin”大(只要比较一下他们首字母就知道了,按26个字母顺序R排在M的后面),所以会往”Martin”的后面找,即找到Page145,然后在比较一下”Rudd”和”Smith”,”Rudd”比”Smith”小,所以会往左边找即Page120,然后在Page120逐行扫描下来直到找到”Rudd”。
如果不建索引的话,SQL SERVER会从第一页开始按顺序每页逐行扫描过去,直到找到”Rudd”。显然如果对于一个百万行的表来说,效率是极其低下的,如果建了索引,非常快就能找到。
?
非聚簇索引:
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
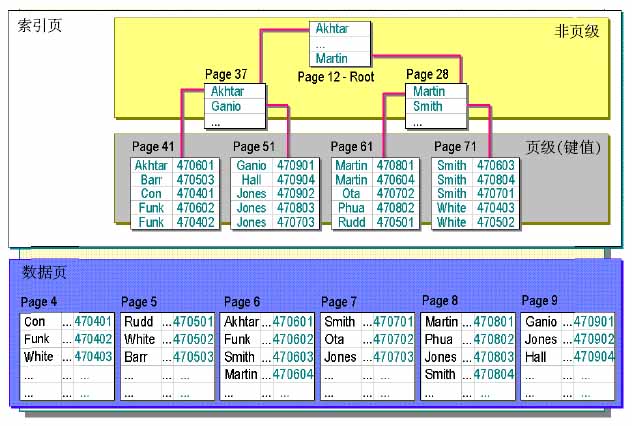
(图B)?
看图B,非聚簇索引的结构图。
聚簇索引和非聚簇索引的区别就是:聚簇索引的数据物理存储顺序和索引顺序一致的,也就是它的数据就是按顺序排下来的。非聚簇索引的数据存储是无序的,不按索引顺序排列。
从图B可以看到数据页里是无序的。那么它的索引是如何建立的呢?
再看图B,它是把这个索引列的数据复制了一份然后按顺序排下来,再建立索引。每行数据都有一个指针。
我们再来找”Rudd”.首先从索引页的根开始找,查找原理跟聚集索引是一样的。在索引页的Page61找到”Rudd”,它的指针是470501,然后在数据页的Page5找到470501,这个位置就是”Rudd”在数据库中的实际位置,这样就找到了”Rudd”。
好了,索引的基本工作原理就是这样,可能实际上要复杂些。
?