? ????? ���ڶ�������д������������������£��±ʺ�ŷ�����ĺ���д���������������������������ڸ��ӣ�������Щ�������ţ�����ͨ��DMV��DMF��������������ܺ��ѿ���������Ӱ���������е���������ֹ�������Ǽ�Ȼ˵��Ҫд���ƺ���������ȥ�����ҵķ���ڽ������ļ�ƪ���£���ʵ��Ҳ��֪��Ҫ��ƪ�����Ҿ������������������дд����SQL2005�IJ���ģ����������������ĸ�����չ�������������ȸ����ʵ����ԭ�ʹ��һ����ѧϰ���в���֮��ϣ�����ָ���� ? ?????? һ����������������ģ�� ??? �����������<< SQL2005���ݿ�����ṹ>>һ�������ἰ�������ͨ���������ӽ��з��ʣ�SQL2005���ݿ�����ṹ����������һ�����˼����Ȼ���Ƕ������˼���������������Ⲣ�����Ƕ������ͬʱ�����������ݿⲢ�����Ƕ������ͬʱȡ�������ݿ������ݵ��������������ǿ�����ϵͳ����Ȼ�Ǽ���̬�IJ�������ܵIJ����û�����Խ�ಢ��������Խǿ�����������뿴�ö�����Ϲ���ϵͳ�����û�в�����������������ô������Ǽǵ��û���Ϣ����Ʒ�п����Ϣ���û��ʻ���Ϣ���ѱ�֤��ȷ�Ժ�һ���ԣ�����һ����Ʒ�������ֻ��100����������100��ͬʱ���߽���Ԥ���������п��ܸ�һ��100��1��Ч�������� ??? ����Ȼ����������������ϣ��һ���������Ŀ������ʱ������ֹ�������̶��������ݣ��������ڶ����û�����������������û����̽��ж����ĵIJ���������һ���Ʊ����ϵͳ�IJ��������½�������������������ְ취������֤������ȷ�Ժ�һ���ԡ�����ô�����������أ��취ֻ��ͨ����ͬ�IJ���ģʽ��������Щ�����¼����������������Ⲣ�����Ƶ�ģʽ�������¿��ܷ����ķ�һ��������Ϊ�������������ã�����ģʽ��������Ϊ����������ص�5������ȼ��ȸ�����������ⲻͬ����ȼ��²���ʵ�ֵĻ�������Ȼ�����Լ�Ҳ�Ϳ��Իش�������������ˡ� ��������ģʽ��һ�㲢������ģʽ�����֣������������ֳ��ֹ۲������������������ֳƱ��۲�����������������SQL2005���������ģʽ����2005��ǰ�İ汾��ʵֻ��Ψһ�IJ���ģʽ����������������ʲô�����������أ�������������SQLSERVERĬ����Ϊ�ǽ����Ի�ȡ���ķ�ʽ����ֹ�������̶�����ʹ�õ����ݽ����ĵ��������������ݿ���˵�������ĵIJ������̿϶��ܶ࣬��Щ���̿϶�����ȥӰ���������̶�ȡ���ݵ���������֮�������ݽ��ж�ʱ������Ҳһ����Ӱ���������������ݵ������������֮�����Ƕ�ȡ��������֮���dz�ͻ�ġ����������ġ��ֹ۲�����SQL2005����һ���а汾���������¼��������������ij�ͻ���а汾�������ڵ�ǰ���̶�ȡ����ʱ���ɾɰ汾�����ݣ�ʹ������������Ľ����ܿ�����ǰ����һ��ʼ��ȡʱ������״̬�����Ҳ��ܵ�ǰ���̻��������̶����ݽ����ĵ�Ӱ�졣�����֮������֮���Dz���ͻ�ģ�����������֮�仹�dz�ͻ�ġ� ??? ���������ֲ���ģʽ��������ͬʱ���������ı�Ȼ���ͻ�ģ���������IJ������һ�����ڳ�ͻ����ǰ���п��ƣ���һ���ڳ�ͻ�����˽���Э����������ñ�����һ�������ַ�ʽ�������ֲ�ͬ��������һ����������һ�ֻ������ϡ� ���������¿��ܷ����IJ��������ã���ʧ���¡�����������ظ�������Ӱ�� ??? Ϊ�˰���Щ���ܷ����IJ���������˵����������ȡ����á�һ������������һ��������ʯͷ��С�̵꣬ƽʱ��ǰ����ɽ��ף��ͻ�ƾ���ݵ�����ȡʯͷ��AMM��BMM��ӪҵԱ������ƽʱ���տ������ͨ���������һ��LED��ʾ�Ƶ�֮�������ڸ������һ�ʽ�����LED��ʾ���Ա�֤���ݵ�ʵʱ�ԡ�������������������۲���ܷ�������Ϊ�� 1��? ��ʧ���£� ��ʧ���¹������������ݿ��û������뷢���������ʲô�Ƕ�ʧ�����أ���ʧ�����ǵ�2�����������ϵ��û�����ͬʱ��ȡͬ�������ݺ�����ͼ��ԭ��������ʱ�ͻᷢ�����������������£�����LED��ʾ����ʾ��ǰ���1000����ʱͬʱ�������ͻ������ˣ�AMM��BMM���洺��Ӵ�������AMM����1����BMM��������10����AMM������ҵ���Ͻ���LED��ʾ����Ϊ1000������1������999��������ͬһʱ��BMM�������Լ���ҵ���ϰ���Եİ�LED��ʾ����Ϊ1000������10������990��������ʱ�ϰ�Ӻ���������LED�е㲻ˬ�����һ�������ڻ��ж��ٴ��ѽ����AMM˵������1����BMM˵����10�������������˶�ɵ���ˣ�LED��ʾ��ô��990�أ�ԭ��BMM�ڸ���ʱ��AMM���ĸ��ĸ㶪�ˣ�����Ƕ�ʧ���¡���Ȼ���ϰ��ӪҵԱ��˵���DZ���رܲ��ܷ������¡� 2��? ��� ����Ȼ�����������������ΪAMM��BMM������Ϊ��֪���Է��Ѿ����˹�̨��������Բ�����˴����Ŀ��ʾ��������������Ҫ��취������⣬Ӣ�����ϰ�˵�ˣ���������ĸ���̸һ������ʱ�Ȱѿͻ�������ʯͷ���۵���������ͻ���Ҫ���ٸĻ�ͷ������MM���ϰ��Ӣ��������ʾ����ͬ����������Ƿ����ˣ���ô�����أ����Ǽ����̨���1000��ʯͷ��AMM��һ����������̸�ţ��˿�����Ҫ600��ʯͷ��AMM�Ͻ���LED��ʾ��Ϊ400����ʱBMMҲ���˷���Ϊ���Ѿ�̸��һ��700��ʯͷ�����⣬������BMM̧ͷһ�����������400�����������BMM�������������ˣ�ֻ����ͻ�����Ǹ�⡣BMMֻ�����ϰ�����������ϰ�һ��LED��ʾ����1000����ô���700���������������أ�Ŷ����Ϊ���AMM��600������û���ɡ��ٺ٣�Ҳ����BMM����Ķ�ȡ��AMM�ĵ����ݣ������һ�Ρ���������������Ҳ����һ���û����̶�ȡ����һ���û������Ĺ���û����ʽ�ύ�����ݣ���ʱ���������ݲ�һ�������η����ˡ���ΪA�û���������ȷ����һ��B�û��������Լ��ύ����ǰ�Ƿ��Ĺ����ݣ��������ݿ�ϵͳĬ������±���رܵġ� 3��? �����ظ��� �����ظ����ֳƲ�һ�·�����������������Ϊ�ƺ���һ�·��������˺�����һ�㣬���Ǵֵط��Ʋ����ظ����������ظ�����ָһ���û��������ζ�ȡ���ݵõ���ͬ�������ݡ������Ǹ�Ӣ�����ϰ�ɣ���֪��Ҫ�̵㣬���տ��ı仯��æ�Ü�ͷ�����ڼƳ��������������˵1000�ɣ����ǵ����ܵ�����һ��LED��ʾ��ȴֻ����900����Ȼ��һ�εļ����Ĺ��������εõ��������һ����ԭ�����AMM���ϰ�Ӻ��ߵ�ǰ���Ĺ���������һ�����⣬����100�顣�ٺ٣��ϰ����ֲ��Dz����ֲ��ǣ���AMM��ɰ���������ͦ����ѽ����Ȼ��һ���û��������ζ�ȡ���ݼ������һ���û������������ݣ�����Dz����ظ����� 4��? ��Ӱ ��Ӱ���ٺ٣����Dz��Ǿ�������BS�Լ���������������������������BS��ɣ����BS����˾ͳ��˻�Ӱ���ٺٿ�����Ц��������������ڲ�ѯ��ν��ʱ������ڲ������ݱ仯��ʱ���������ν��������һ������������ͬһ��ѯ�Ľ������ͬ����Щ��ͬ���л��м����ǻ�Ӱ���ȷ�˵Ӣ�����ϰ嵽�������ߣ�˳�����ҳԷ�������������BMM����������һ·����ȥ��������10�ˣ��Ǻǣ�����һ������֪ͨ�����Ǻ��ϰ�ذ����������ң��ص�ǰ������AMM����һ��11�ˣ��Σ��ղ���ô����AMM����AMMҲ֪�����ϰ����û��������������������ʱAMM�ͳ��˻�Ӱ�� ?? ���������ֲ���������ֻ��һ��������������������ܷ������쳣�ķ�һ�µ�������Ϊ���Ǻò��������úͲ�һ�µ�������Ϊ��������Ժ�ᾭ���ἰ������ʵ�����кö����Ϊ�������������ģ���ô������������Ϊ��ʲô�أ����������������������ܡ����ǿ���ͨ�����뼶�����趨һ�����ʼ����Ծ�����������������Ϊ��Щ�������ġ���ʲô�ǽ�������ʲô���Ǹ���ȼ��أ� ? �������� ??? ���������ݿ�һ�ʽ��Ļ�����Ԫ���������ֲ���ģ���С��ַ�Ϊ��ʽ�������ʽ������ʽ��������ʽ�Ŀ�ʼһ��������ʽ�Ĺ��ػ��ύ��������ʽ����������ʽ���ˣ���ʽ���������ݿ��Լ����������ɵ����������絥����select��update��delete��select��䡣 ??? ��Ϊһ���������ܱ�֤���ݿ������һ���Լ��������ᵽ���ò��ἰ�����ACID���ԣ�ԭ���ԡ�һ���ԡ������Լ��־��ԡ���������ʽ������ʽ�ģ�������ά�����ĸ����ԡ� ??? ԭ���ԣ�һ��������һ�����壬Ҫ��ȫ���ύ��Ҫ��ȫ����ֹ����˼����Ҫ��ȫ���ɹ��ύ�����ݣ�Ҫ��ȫ���ع��ָ�����ʼǰ��״̬���ȷ�������һ�������������������������ⵥ���Ŀ����Ϊһ�����壬Ҫ�����ݱ����˹�ͬʱ���������Ӧ��ֵ��Ҫ�����ǵ���δ���ͬʱ��治�䡣 ??? һ���ԣ�һ����Ҫ������֤������������ȷ�������Ľ������һ����ȷ����״̬��ʲô�Dz�ȷ��״̬�أ�����˵�������һ�������ٵIJ��������û��һ������������ô������ĵ�ǰ�ľ���һ����ȷ��״̬����Ϊ����֪�����ٵĶ������Ķ�ȥ�ˡ� ??? �����ԣ��������������йأ��Ժ���˵���Ĺ����л��ᵽ��Щ�����ȼ�ס������С� �־��ԣ��־ú���Ȼ��Ҫ����ȷ�ύ���ı��뱣֤���ô��ڣ�������Ϊ�ػ���������ʽ������������е��������������������ȫ��������û�з���һ������������ύ��ȷ���Ѿ�������Ӧ�ó��������ϣ���ô��Щ��־������д�������������ָ����Զ������Ӧ�Ķ�����֤����ij־��ԡ��������ǰ�����������й�����Ŷ���� ? ? �ġ�����ȼ� ??? ������˵˵���룬������һ������������������������е���Դ�����ݸ������������Ȼ����ȼ���������ij̶��˰ɡ���˵���뼶�ò��ἰ���ĸ�������ڱ������ἰ�������Ժ����½�������˵�������ֻҪ�и�ӡ����С���������DZ������������£� ??? 1�����뼶��Ӱ����̻�������ĵ�������������������ᱣ�浽�������������ڶ�������˵�����뼶����ǶԶ�������һ���������𣬱�������������������Ӱ��ij��� ??? 2���ϵ͵ĸ��뼶�������ǿ�����û�ͬʱ�������ݵ���������Ҳ�������û����������IJ��������ã����������ʧ���£����������෴���ϸߵĸ��뼶��������û����������IJ��������ã�ȴ��Ҫ̫���ϵͳ��Դ��һ������������������Ŀ����ԡ� ??? Ӧƽ��Ӧ�ó����������Ҫ������Ӧ���뼶���ϵͳ�������ڴ˻�����ѡ����Ӧ�ĸ��뼶����߸��뼶�𣨿����л�����֤������ÿ���ظ���ȡ����ʱ����ȷ��������ͬ�����ݣ�����Ҫͨ��ִ��ij�ּ������������ɴ˲��������������ܻ�Ӱ�������û����̡�����뼶��δ�ύ�������Լ������������Ѿ��ĵ�δ�ύ�����ݡ���δ�ύ���У����в��������ö����ܷ���������Ϊû�ж���������������ȡ�����Կ������١� ??? ��ͬ�ĸ��뼶�������������Щ���ݸ����ÿ��Է�����������ģ�;�����ͬ����ȼ��������������Щ������Ϊ�����Э����������Ϊ���ã�����������עһ�²�ͬ����ȼ������������Щ��Ϊ�ķ����� ??? δ�ύ����uncommitted Read������������һ�£����˵�δ�ύ���ݿ��Զ�ȡ��ȷ�㣺һ���û����̿��Զ�ȡ��һ���û�������ȴδ�ύ�����ݡ�SQL SERVER������ȼ��µĶ���������Ҫ����κ����Ϳ��Զ�ȡ���ݣ���Ϊ����Ҫ�����Բ���������κν��̻�����������Ȼ��Ȼ�ܶ�ȡ�����������˵�ȴδ�ύ���ݡ���Ȼ�ⲻ�����������һ��ģʽ��������ȴ���˸߲����ԣ���Ϊ������û��������Ӱ���������̵Ķ���д�����������ּ����£����˶�ʧ���£���һ���е����ݿ��ܷ�������Ϊ���⣬������Ϊ���п��ܷ�����ð�����ݲ�һ�µķ����������ĵĽ���������ȡ�Ľ��̣������һ���Կ϶��ǵò������ϣ���Ȼ������������ģʽ�µĻر�����Ƶ����һ�ֽ��������δ�ύ���ǿ϶��Dz��ʺ��ڹ�Ʊ������ϵͳ�ģ�������һЩ���Ʒ�����ϵͳ�Ҫ���ֻ��һ������ȷ�Կ��Բ�����ô�ϸ�ʱ��������������ܳ�ǿ��Ϊ��ѡ�� ??? ���ύ��(Read Committed)������δ�ύ���෴�����ύ������֤һ�����̲����ܶ�����һ�������ĵ�δ�ύ�����ݡ��������������Ĭ�ϵļ���Ҳ��2005�ֹ۲���ģʽ��֧�ֵļ���Ҳ����˵���ύ�������ֹ۵�Ҳ�����DZ��۵ģ��Ǿ�����ǰ���������ĸ�����ģ���µ����ύ���أ���ȡ����һ��READ_COMMITED_SNAPSHOT���ݿ����������ȱʡ�DZ��۲������Ƶġ����������������ύ������������ʹ�����������а汾���ƣ�������Ȼ�а汾�������ֹ۲���ģʽ�������DZ��۲���ģʽ����������DZ������� ? --�������ύ������ʹ���а汾���� ALTER DATABASE testcsdn SET READ_COMMITTED_SNAPSHOT ON GO --�鿴��ǰ���ύ�����벢��ģ�� select name,database_id,is_read_committed_snapshot_on? from sys.databases /* ? name????????????????? database_id is_read_committed_snapshot_on --------------------?? ----------- ----------------------------- master?????????????????????? 1?????????? 0 tempdb?????????????????????? 2?????????? 0 model??????????????????????? 3?????????? 0 msdb???????????????????????? 4?????????? 0 ReportServer$SQL2005???????? 5?????????? 0 ReportServer$SQL2005TempDB?? 6?????????? 0 TestCsdn???????????????????? 7?????????? 1? --current ? (7 ����Ӱ��) */ --�������ύ������ʹ������ ALTER DATABASE testcsdn SET READ_COMMITTED_SNAPSHOT OFF GO --�鿴���ύ�����벢��ģ�� select name,database_id,is_read_committed_snapshot_on? from sys.databases ? ? /* ? name????????????????? database_id is_read_committed_snapshot_on --------------------?? ----------- ----------------------------- master?????????????????????? 1?????????? 0 tempdb?????????????????????? 2?????????? 0 model??????????????????????? 3?????????? 0 msdb???????????????????????? 4?????????? 0 ReportServer$SQL2005???????? 5?????????? 0 ReportServer$SQL2005TempDB?? 6?????????? 0 TestCsdn???????????????????? 7?????????? 0 --curret ? (7 ����Ӱ��) */ ??? ���ύ�������ϱ�֤�˲��������ʵ�ʴ��ڵ����ݡ����۲����µ����ύ����������Ҫ������ʱ�������������������������������̣������Ƕ�����д������ȵ��������ͷŲſ���ʹ����Щ���ݡ�������̽��Ƕ�ȡ����ʱ��ʹ�ù�����������������Ȼ���Զ�ȡ���ݵ������������ݣ�����ȵ��������ͷţ������������ݴ����꼴�ͷţ������й������ڵ�ǰ���������ݴ�������Զ��ͷţ����������������ڱ������������ֹ۲��������ύ����Ҳȷ���������δ�ύ�����ݣ�����ͨ�������ķ�ʽ��ʵ�֣�����ͨ���а汾�����������е���ǰ�������ݰ汾�����ĵ�������Ȼ��Ȼ�����������������̿��Կ��Զ�ȡ����ǰ�汾���ݡ� ??? ���ظ�����Repeatable Read������Ҳ��һ�����۲����ļ��𡣿��ظ��������ύ��Ҫ����ϸ������ύ���Ļ�����������һ�����ƣ���ȡ�Ĺ������������������������������£�������һ�������������ζ�ȡ������һ�£�Ҳ���Dz����ȡ�����������������ݡ�����������ᵽ�������ᱣ��������������ǵ�����һ���������ּ�����ģ�ͣ���������һ��Ҫ��������������ġ��ڿ��ظ�����������ͬ��Ҳ�ᱣ���������������ô���ֶ����ݰ�ȫ�ı�֤��ͨ�����ӹ��������Ŀ���Ϊ���۵ģ�Ҳ����ֻҪ��ʼһ�����������û������Dz����������ݵģ��Զ�����ϵͳ�IJ����Ժ����ܱ�Ȼ�½������ƺ������������е�һ�ּ�����Ȼ���������ʱ���رܻ�Ӱ������������ҲĬ�������������½�����ֻ�жԳ���Ա������Ŀ������ϸ��Ҫ������Ҫ�̲�������Ҫ��Ϊ���صĸ��ţ�����DZ�ڵ��������� ??? ����(SnapShot)���ֹ۲�����������2005�����ӵ�һ�����뼶�𡣿��ռ�����ʹ���ֹ۲��������ύ����࣬��������а������������ݰ汾�ж��磬������Ժ���ʱ��˵���������֤��һ�������ȡ������������ʼʱ�������ݿ�����ȷ�ϲ�����һ���Ե����ݡ�����������Ҫ�������������Ҫ��������Ѿ��������ͻ�ͨ���а汾��������ȡ����ķ���һ���Ե����ݡ� ??? �ɴ��л�����Ŀǰ���Ͻ����׳��һ���������ڱ��۲���������ֹ��Ӱ�ķ������ر�����ǰ����������Ϊ�ķ������ɴ��л���ζ��ϵͳ�����̽�����е�˳�����Ρ����л���ִ�еĽ��������ͬʱ���еõ�һ�µĽ��������׳�ļ�����Ȼ������Ҳ��������ʼ�������������ͨ���������ֲ����ڵ����ݣ�����������Χ���������رܻ�Ӱ�ķ����� ? ??????? ��ǰ�����ƪ���ҴӴ������ϰ�������ص�֪ʶ����һ�����������˿���һ��������ζ�˰ɣ�����һƪ���Ǽ���һ��T-SQL����ǰ����˵�ж�������������������Ϊ�������������ⲻͬ������������Ϊ�ڲ�ͬ����ȼ��µı��֣�˳��������һ�����������м�����ȼ����ô�ҶԽ���������һ��ֱ�۵���ʶ�� ???? �ڽ���ʵ��ǰ���ò��Ƚ���һ������֪ʶ��ע�����ֻ�Ǽ�˵һ�£������������ۡ����Ǹ����û�������Դ����Ϊ�ȹ��ɳ����������⼸�����������ʵ�������֣�����Ϊ�������������������������������������������������������(�������������������������)������Ȼ����������ģʽ����������һƪ��˵���������Ĵ����ǽ�������ķ�������֤��������������ǰȷ����ǰ�����Ƿ���ڲ������Ե������� ??? �ȶ������ᵽ������һ��������������ϸ��������˵�� ?? �������������ڲ�ѯ��¼ʱ��ֱ�۾�������select�������Dz�����ֻ��select���й���������һ����ѯ��¼����������û���빲�����������������ڻ�ȴ��������������������ù�����������ȡ����(���ⲻ����������ļ����ԣ������Ժ���˵��)�� ??? �������������ڶ��������ӡ�ɾ������ʱ������ʼ�Ժ�������벢������������(ǰ����û������������������)������ȷ��֪�������̶Ե�ǰ���ݲ����Բ�ѯ���ģ��ȴ�����������������̲ſ��Բ�ѯ���ġ� ??? ����������һ�����ڹ���������֮����м��������������Ǵ�where������update��䣬�ڲ�ѯҪ���µļ�¼ʱ�����ù�����������Ҫ��������ʱ��ʱ���������ɹ������������ɸ��������̶�����Ϊ�����������������������óɹ��ſ��Խ��������IJ�������ȻҲ��ҪҪ�����������Ĺ�����û�л��������Ĵ��ڡ����������������һ���м�բһ�����������������������̡����л������Խ������������ص�˵��һ�£����ݸ��½���Ҫ�����������������Ǹ�����������Ҫ��������˼ѵ��Ŷ�� ??? ���˵һ������������ģʽ�µĻ��⣬��������ֻ�������������⣬��������ֻ�빲�����������⡣ ??? �ڽ��о���ʵ��ǰ����һ��Ҫ��һ��������������ʵ�����̽��м�أ��ã�������д��һ�����̣�����Ҫʱֱ�ӵ��þ��У��������£� ? Create Proc sp_us_lockinfo --------------------------------- -- Author : HappyFlyStone -- Date?? : 2009-10-03 15:30:00 -- BLOG?? : http://blog.csdn.net/happyflystone -- ����??? ���뱣��������Ϣ��ת��ע������ --------------------------------- AS BEGIN ??? SELECT ??????? DB_NAME(t1.resource_database_id) AS [���ݿ���], ??????? t1.resource_type AS [��Դ����], ??? --??? t1.request_type AS [��������], ??????? t1.request_status AS [����״̬], ??? --??? t1.resource_description AS [��Դ˵��], ?????? CASE t1.request_owner_type WHEN 'TRANSACTION' THEN '��������' ??????????????????????????????? WHEN 'CURSOR' THEN '�α�����' ??????????????????????????????? WHEN 'SESSION' THEN '�û��Ự����' ??????????????????????????????? WHEN 'SHARED_TRANSACTION_WORKSPACE' THEN '���������Ĺ�������' ??????????????????????????????? WHEN 'EXCLUSIVE_TRANSACTION_WORKSPACE' THEN '���������Ķ�ռ����' ??????????????????????????????? ELSE '' ?????? END AS [ӵ�������ʵ������], ?????? CASE WHEN T1.resource_type = 'OBJECT' ?????????? THEN OBJECT_NAME(T1.resource_ASsociated_entity_id) ?????????? ELSE? T1.resource_type+':'+ISNULL(LTRIM(T1.resource_ASsociated_entity_id),'') ?????????? END AS [�����Ķ���], ??????? t4.[name] AS [����], ??????? t1.request_mode AS [��������], ??????? t1.request_session_id AS [��ǰspid],???? ??????? t2.blocking_session_id AS [����spid], ??? --??? t3.snapshot_isolation_state AS [���ո���״̬], ??????? t3.snapshot_isolation_state_desc AS [���ո���״̬����], ??????? t3.is_read_committed_snapshot_on AS [���ύ�����ո���] ????? ??? FROM ??????? sys.dm_tran_locks AS t1 ??? left join ??????? sys.dm_os_waiting_tasks AS t2 ??? ON ??????? t1.lock_owner_address = t2.resource_address ??? left join ??????? sys.databases AS t3 ??? ON t1.resource_database_id = t3.database_id ??? left join ?????? ( ??????? SELECT rsc_text,rsc_indid,rsc_objid,b.[name] ?????? FROM ?????????? sys.syslockinfo a ?????? JOIN ?????????? sys.indexes b ?????? ON a.rsc_indid = b.index_id and b.object_id = a.rsc_objid) t4 ??? ON t1.resource_description = t4.rsc_text END GO /* ����ʾ����exec sp_us_lockinfo */ exec sp_us_lockinfo /* */ drop proc sp_us_lockinfo ������һ������ȼ�������� SET TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED ???????????????????????????????? | READ COMMITTED ???????????????????????????????? | REPEATABLE READ ???????????????????????????????? | SNAPSHOT ???????????????????????????????? | SERIALIZABLE}[;] �ã����濪ʼʵ�������֡�֮���ˡ� ? �塢����ȼ�ʵ�� ������������ CREATE DATABASE testcsdn; GO CREATE TABLE TA(TCID INT PRIMARY KEY,TCNAME VARCHAR(20)) INSERT TA SELECT 1,'AA' INSERT TA SELECT 2,'AA' INSERT TA SELECT 3,'AA' INSERT TA SELECT 4,'BB' INSERT TA SELECT 5,'CC' INSERT TA SELECT 6,'DD' INSERT TA SELECT 7,'DD' GO Լ���������ἰ�IJ�ѯN�����Ǵ�һ��������ִ�в�ѯ 1�� δ�ύ����uncommitted Read�� ����عˣ�δ�ύ������͵ȼ��ĸ��룬�����������̶�ȡ������δ�ύ�������У�Ҳ���Ƕ�ȡ����ʱ�����ù�������ֱ�Ӷ�ȡ�������Ѿ����ڵĻ�������������Ȼδ�ύ�����ָ��뼶����ɶ�ʧ���£���������������Ϊ���ǿ��Է����ġ�����select ��������ʾNOLOCKЧ���൱�� ����ʵ���� ��ѯһ�� SELECT * FROM TA WHERE TCID = 1 BEGIN TRAN UPDATE TA SET TCNAME = 'TA' WHERE TCID = 1 --COMMIT TRAN --Don't commit SELECT * FROM TA WHERE TCID = 1 ? SELECT @@SPID /* tcid??????? Tcname ----------- -------------------- 1?????????? AA (1 ����Ӱ��) (1 ����Ӱ��) tcid??????? Tcname ----------- -------------------- 1?????????? TA (1 ����Ӱ��) SPID ------ 54 ? (1 ����Ӱ��) */ ��ѯ���� SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT * FROM TA WHERE TCID = 1 /* tcid??????? Tcname ----------- -------------------- 1?????????? TA ? (1 ����Ӱ��) */ --��Ȼδ�ύ��ģʽ���Ƕ���SPID=54δ�ύ�����ݡ� ��ѯ���� SELECT * FROM TA WHERE TCID = 1 --��ѯһֱ�����С��� ��� --��Ϊȱʡ�����ύ����������������������������������ȵ�SPID=54��������� ��ѯ�ģ� --�鿴��ǰ��������Ϣ exec sp_us_lockinfo ? /* */ ? ? ? ? ? 1�� ���ύ��(Read Committed) ����عˣ����ύ����SQL SERVER��ȱʡ���뼶�𣬱���ģ���������������ֹ�ģ����ʹ���а汾��������������ÿ���ͨ��SET READ_CIMMITTED_SNAPSHOT���ġ��ڱ���ģ���¶��ڶ�ȡ��˵���ù�����������ֹ�����������������ݶ�ȡ�����Զ��ͷţ��������̷��ɽ����IJ�����Ҳ����˵��������ֹ�����������ù�������������������ֹ�����������ڱ���ģ���¶�����������˵������������ֹ����������ʾ������ȵ����������ͷš��������ĸ������������������Ϊ�� ? ? A��?????? READ_COMMITTED_SNAPSHOTΪOFF�����(ȱʡ) I�������ݲ��� ? ��ѯһ�� BEGIN TRAN --��������ʾģ�����������ǿ�ƹ�������������������� SELECT * FROM TA with(holdlock) WHERE TCID = 1 --COMMIT TRAN --Don't commit SELECT @@SPID ? /* tcid??????? Tcname ----------- -------------------- 1?????????? CA (1 ����Ӱ��) ? ? ------ 54 (1 ����Ӱ��) */ ��ѯ��������ģ�������ύ������ SET TRANSACTION ISOLATION LEVEL READ COMMITTED UPDATE TA SET TCNAME = 'TA' WHERE TCID = 1 --��ѯһֱû�н������Ȼ������֤�˹���������ֹ������������ ��ѯ���� exec sp_us_lockinfo --�������Լ����п������ II�������ݲ��� ? ��ѯһ�� SELECT * FROM TA WHERE TCID = 1 BEGIN TRAN UPDATE TA SET TCNAME = 'READ COMMITTED LOCK' WHERE TCID = 1 --COMMIT TRAN --Don't commit SELECT @@SPID ? /* tcid??????? Tcname ----------- -------------------- 1?????????? TA ? (1 ����Ӱ��) ? ? ------ 54 ? (1 ����Ӱ��) */ ��ѯ���� SET TRANSACTION ISOLATION LEVEL READ COMMITTED SELECT * FROM TA WHERE TCID = 1 /* --��ѯһֱ�����С������������ --������������������������ȵ�SPID=54��������� */ ��ѯ���� exec sp_us_lockinfo /* ? */ ? ? A��?????? READ_COMMITTED_SNAPSHOTΪON����� ���ĵ�ǰ��ǰ���READ_COMMITTED_SNAPSHOTΪON ALTER DATABASE TESTCSDN SET READ_COMMITTED_SNAPSHOT ON GO ? ��ѯһ�� SELECT * FROM TA WHERE TCID = 1 BEGIN TRAN UPDATE TA SET TCNAME = 'READ COMMITTED SNAP' WHERE TCID = 1 --COMMIT TRAN --Don't commit ? SELECT @@SPID ? /* TCID??????? TCNAME ----------- -------------------- 1?????????? AA ? (1 ����Ӱ��) ? ? (1 ����Ӱ��) ? ------ 56 ? (1 ����Ӱ��) */ ��ѯ������Ϊ�����а汾���������������ݣ���֤�������̶�ȡ����Ȼ������������������ʼǰ�Ѿ��ύ�ı�֤һ���Ե����ݡ� SET TRANSACTION ISOLATION LEVEL READ COMMITTED SELECT * FROM TA WHERE TCID = 1 /* TCID??????? TCNAME ----------- -------------------- 1?????????? AA ? (1 ����Ӱ��) */ ��ѯ���� exec sp_us_lockinfo /* */ ? 3�����ظ�����Repeatable Read�� ??? ����عˣ����ظ����ȼ������ύ������һ��Լ�������еĹ���������������������������ڶ�ȡ�����ݾ��ͷš����ݱ������˹�����������������ֻ�ܽ��в�ѯ�����Ӳ��ܸ��ģ���Ȼ�������ĸ���Գ������˸��ߵ�Ҫ����Ϊ������ʱ��Ĺ�������Ӱ��ϵͳ�IJ������ܣ��������������Ļ��ʡ�����Ȼ�ǽ���˲����ظ�����������Ϊ�� ���ݲ��ԣ� ��ѯһ�� SET TRANSACTION ISOLATION LEVEL REPEATABLE READ ? BEGIN TRAN SELECT * FROM TA WHERE TCID = 1 --���ظ���ѯ�����Ҷ�����δ�ύ������ --COMMIT TRAN --Don't commit SELECT @@SPID /* tcid??????? Tcname ----------- -------------------- 1?????????? READ COMMITTED LOCK (1 ����Ӱ��) ? ------ 52 ? (1 ����Ӱ��) ? */ ��ѯ���� INSERT TA SELECT 9,'FF' /* (1 ����Ӱ��) */ SELECT * FROM TA-- WITH(UPDLOCK) WHERE TCID = 1 ? /* tcid??????? Tcname ----------- -------------------- 1?????????? READ COMMITTED LOCK ? (1 ����Ӱ��) ? */ ? UPDATE TA SET TCNAME = 'READ COMMITTED REP' WHERE TCID = 1 /* --��ѯһֱ�����С������������ --������������������������ȵ�SPID=52��������� ? */ ? ��ѯ���� ? ? ? ����Ȼ��ѯ���е�S��Is(������������)����һֱû��ʧ����Ϊ��ѯһ������û�н������ڲ�ѯ������Է��ֲ������ȡ(�����ڲ�ѯһ���ٴ�select)�Dz�Ӱ��ģ����Ҷ�ȡ����δ��ǰ�����ݡ� ? ? ? 4������(SnapShot) ??? ����عˣ�����SQL SERVER2005���¹��ܣ����ÿ��պ����еĶ�������������������Ӱ�죬��ȡ��������ͨ���а汾��������ȡ����ʼǰ��ȷ��������һ���Ե������а汾�� ���������������ύ�����а�������IJ������а汾����������ʷ�汾���ݶ�á� ? �������ݣ� ? ��ѯһ�� ALTER DATABASE TESTCSDN ??? SET ALLOW_SNAPSHOT_ISOLATION ON GO ? SELECT * FROM TA WHERE TCID = 1 --OLD���� BEGIN TRAN ? UPDATE TA SET TCNAME = 'SNAPSHOT' WHERE TCID = 1 --COMMIT TRAN --Don't commit SELECT @@SPID ? /* tcid??????? Tcname ----------- -------------------- 1?????????? READ COMMITTED REP ? (1 ����Ӱ��) ? ? (1 ����Ӱ��) ? ------ 52 ? (1 ����Ӱ��) ? */ ��ѯ���� SET TRANSACTION ISOLATION LEVEL SNAPSHOT SELECT * FROM TA WHERE TCID = 1 /* tcid??????? Tcname ----------- -------------------- 1?????????? READ COMMITTED REP ? (1 ����Ӱ��) ? */ ? ��ѯ���� ? exec sp_us_lockinfo ? ? ? ? ? 5���ɴ��л��� ??? ����عˣ����ǽ������׳���Ͻ������ĸ��롣ͨ����������Χ��ȫ�����������ĸ��ţ��˸����select��������ʾHOLDLOCKЧ��һ��������������������е�������Ϊ���Զ������Dz��������½���ϵͳ��Դ����������� �������ݣ� ? ��ѯһ�� DROP TABLE TB GO CREATE TABLE TB (ID INT Primary Key, COL VARCHAR(10)) GO INSERT INTO TB SELECT 1,'A' GO ? SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRAN SELECT * FROM TB WHERE ID BETWEEN 1 AND 5--OLD���� --COMMIT TRAN --Don't commit SELECT @@SPID ? /* ID????????? COL ----------- ---------- 1?????????? A (1 ����Ӱ��) ? ------ 52 (1 ����Ӱ��) */ ��ѯ���� ? SELECT * FROM TB WHERE ID = 1 ? /* ID????????? COL ----------- ---------- 1?????????? A (1 ����Ӱ��) */ INSERT TB SELECT 2,'EE' /* --��ѯһֱ�����С������������ --������������������������ȵ�SPID=52��������� ? */ UPDATE TB SET COL = 'SERIALIZABLE' WHERE ID = 1 /* --��ѯһֱ�����С������������ --������������������������ȵ�SPID=52��������� */ ��ѯ���� exec sp_us_lockinfo ? ? ? ? �������Եķ��ֳ��ִ�������������Χ(RangeS-S����)��ȷ���ڵ�ǰ����δ����֮ǰ������û�����������������Χ�ڲ������ݣ�������Ӱ������Ϊ�ķ������ɴ��л����������ܲ�ѯ�⣬�������ġ����ӡ�ɾ����������Χ�ڵ����������У�����ȵ������ϵ������ͷš� ? ? ? ??? ���ۣ�ͨ���Ե�һЩ���ԣ�����֪��ͨ������ȼ����ǿ��Կ��Ʋ���ʱ������Ϊ����ʵ�ʲ����Ĺ��������ǿ����ü��������������������ȡ�Ӱ�췶Χ���Դﵽ���Ʋ������������ݵ�����ȷ������һ���ԡ�������Ƿ���ͨ��������ʾ(LOCK HINTS)Ҳ���Ըı�����������͡��������ڣ��ﵽ�����ø���ȼ����ƵĹ��ܡ� ? ? ? ? �ã���ĿǰΪֹ���ǰ�������صĶ������ܵò���ˣ���������ǰ�����˲��ֵ�������������������������ص�������н��ܡ� ? ?????? �������������ж���û�ͬʱ���������Dz����Ա���ģ�ͨ����ͬ�ĸ���ȼ�����Դ�����ݽ��и������͵��������������ʵ�ʱ���ͷű�֤������ȷ���У�ʹ�ý�����������֤���ݵ�һ���ԡ����������������а汾����������������ҵ������������������������ݵ�һ�¡���������Ҫ����ʵ��������в����ڲ�������������Դ�����ɱ�֮���ҵ�ƽ��㣬���������ҵ����ƽ����أ������Ǿ͵ö�SQLSERVER��ι�����Դ������һ���˽⣬SQLSERVER����������������Ҫ��������ģʽ֮��ļ����Ի���������������������⡣ͨ��SQL SERVERǿ��ġ�ϸ�µ��������ƣ�ʹ�ò������ܵõ����̶ȵķ��ӣ�����ʹ�þ������ٵ�ϵͳ��ԴҲ��������ϣ���ġ� ?????? SQLSERVER����������������ϵ��һ���ǶԹ������ݵ����������������������Ǵ�ʱ�����۵�������һ���Ƕ��ڲ����ݽṹ����������������һ�ֳ�Ϊ�����������������ȵ�һ�������ٺ���Դ����sys.dm_tran_locks���ǿ���������������Ϣ�����������ݷ�ҳ�Ϸ���������¼��ѹ�����۷֡�ת�Ʒ�ҳ����ʱ���������ͻᷢ���ˡ�������ǰ��һֱ��˵���ݵ���һ���ԣ����������ϵ�һ���Ծ���ͨ�����������Ƶģ����������ᵽ�����DZ�֤������һ����(��������ϵͳ�ڲ�ʹ���������Dz��ص�������)�� ?????? ������������ʱ��SQL Server 2005ʹ�����л���ȷ������������ά�����ݵ�һ���ԣ� l???????? ���� l???????? �а汾���� �������а汾���ƿ��Է�ֹ�û���ȡδ�ύ�����ݣ������Է�ֹ����û�����ͬʱ����ͬһ���ݡ�����������������а汾���ƣ�������ִ�еIJ�ѯ���ܻ᷵�����ݿ�����δ�ύ�����ݣ��Ӷ���������Ľ���� ���˵һ�����������벢��������ì�ܵģ����ǶԹ��������ijɱ�ȴ�������ģ�����Խ�������½�������ԽС���������ɱ�Խ����ͼʾ��һ�£� 1�������ȺͿ�������Դ SQL Server2005 ���ж���������������һ������������ͬ���͵���Դ��Ϊ�˾������������Ŀ��������ݿ������Զ�����Դ�������ʺ�����ļ��������ڽ�С�����ȣ������У�������߲����ȣ��������ϸߣ���Ϊ��������������У�����Ҫ���и�������������ڽϴ�����ȣ���������ή���˲����ȣ���Ϊ������������������������Ա������ⲿ�ֵķ��ʣ����俪���ϵͣ���Ϊ��Ҫά���������١� SQL SERVER��������������ҳ���м�����������Χ�����������Ѵ��һ�£����ھۼ������ı�����Ϊ�����о���������Ҷ�������������Ǽ�����ɶ����������� ���ݿ�����ͨ�������ȡ�����ȼ����ϵ������������ر�����Դ����������ȼ����ϵ�����Ϊ����νṹ�����磬Ϊ�������ر����������Ķ�ȡ�����ݿ�����ʵ�����ܱ����ȡ���ϵĹ������Լ�ҳ�ͱ��ϵ����������� �±��г������ݿ����������������Դ�� ��ѯһ�� SELECT * FROM MASTER..SPT_VALUES WHERE TYPE = 'LR' /* name?????????????? number????? type? low???????? high????? status --------------- ----------- ---- ------- --------- ----------- LOCK RESOURCES????? 0?????????? LR?? NULL??????? NULL??????? 0 NUL?????????????????? 1?????????? LR?? NULL??????? NULL??????? 0 DB???????????????????? 2?????????? LR?? NULL??????? NULL??????? 0 FIL?????????????????? 3?????????? LR?? NULL??????? NULL??????? 0 TAB?????????????????? 5?????????? LR?? NULL??????? NULL??????? 0 PAG?????????????????? 6?????????? LR?? NULL??????? NULL??????? 0 KEY?????????????????? 7?????????? LR?? NULL??????? NULL??????? 0 EXT?????????????????? 8?????????? LR?? NULL??????? NULL??????? 0 RID?????????????????? 9?????????? LR?? NULL??????? NULL??????? 0 APP?????????????????? 10????????? LR?? NULL??????? NULL??????? 0 MD???????????????????? 11????????? LR?? NULL??????? NULL??????? 0 HBT??????????????????? 12????????? LR?? NULL??????? NULL??????? 0 AU???????????????????? 13????????? LR?? NULL??????? NULL??????? 0 (13 ����Ӱ��) */ ��ע�� ?????? RID??????? RID????????????????? ���������е��б�ʶ�� KEY???????? KEY???????????????? ���л������еļ���Χ���� PAG???????? PAGE??????????????? ���ݻ�����ҳ�棬8KΪ��λ EXT???????? EXTENT????????????? ���ݻ�����ҳ�棬������8*page HBT???????? HOBT??????????????? �ѻ�B��������������ѱ�ҳ�ѵ��� TAB???????? TABLE?????????????? ���������������ݼ����� FIL????????? FILE????????????????? ���ݿ��ļ� APP???????? APPLICATION???????? Ӧ�ó�����Դ MD????????? METADATA??????????? Ԫ���� AU????????? ALLOCATION_UNIT???? ���䵥Ԫ ?????? DB??????? DATABASE????????? ���ݿ� ? ע��SPT_VALUES�����Ҳ�İ���ɣ��ö�����������һ��������ID�ŵ�������ʱҲ���������������;�����ڷ������������˰ɡ��������ǻ���ʹ�õ��� ? ? 2������ģʽ ?????? ������ǰ����ǰ���Ĺ���������������������������������Ϊ�����ǰ���������ἰ�ģ���ôSQL SERVER2005һ���ж�������ģʽ�أ�����ͨ��һ���IJ�ѯ���б��� ? ��ѯ�� SELECT * FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L' /* NAME??????????????????????????????? NUMBER????? TYPE LOW???????? HIGH??????? STATUS ---------------- ----------- ---- ----------- ----------- ----------- LOCK TYPES????????????????????????? 0?????????? L??? NULL??????? NULL??????? 0 NULL??????????????????????????????? 1?????????? L??? NULL??????? NULL??????? 0 SCH-S?????????????????????????????? 2?????????? L??? NULL??????? NULL??????? 0 SCH-M?????????????????????????????? 3?????????? L??? NULL??????? NULL??????? 0 S?????????????????????????????????? 4?????????? L??? NULL??????? NULL??????? 0 U?????????????????????????????????? 5?????????? L??? NULL??????? NULL??????? 0 X?????????????????????????????????? 6?????????? L??? NULL??????? NULL??????? 0 IS????????????????????????????????? 7?????????? L??? NULL??????? NULL??????? 0 IU????????????????????????????????? 8?????????? L??? NULL??????? NULL??????? 0 IX????????????????????????????????? 9?????????? L??? NULL??????? NULL??????? 0 SIU???????????????????????????????? 10????????? L??? NULL??????? NULL??????? 0 SIX???????????????????????????????? 11????????? L??? NULL??????? NULL??????? 0 UIX???????????????????????????????? 12????????? L??? NULL??????? NULL??????? 0 BU????????????????????????????????? 13????????? L??? NULL??????? NULL??????? 0 RANGES-S??????????????????????????? 14????????? L??? NULL??????? NULL??????? 0 RANGES-U??????????????????????????? 15????????? L??? NULL??????? NULL??????? 0 RANGEIN-NULL??????????????????????? 16????????? L??? NULL??????? NULL??????? 0 RANGEIN-S?????????????????????????? 17????????? L??? NULL??????? NULL??????? 0 RANGEIN-U?????????????????????????? 18????????? L??? NULL??????? NULL??????? 0 RANGEIN-X?????????????????????????? 19????????? L??? NULL??????? NULL??????? 0 RANGEX-S??????????????????????????? 20????????? L??? NULL??????? NULL??????? 0 RANGEX-U??????????????????????????? 21????????? L??? NULL??????? NULL??????? 0 RANGEX-X??????????????????????????? 22????????? L??? NULL??????? NULL??????? 0 (23 ����Ӱ��) */ ? ?????? ���ǿ��Կ���һ����22������ģʽ ���ҼĶ�����[NAME]���м�ö�٣� l???????? S --- ��������(Shared) l???????? U --- ��������(Update) l???????? X --- ��������(Exclusive) l???????? I --- ��������(Intent) l???????? Sch --- �ܹ�����(Schema) l???????? BU --- ��������(Bulk Update) l???????? RANGE --- ����Χ(Key-Range) l???????? �����������������ı�����ϣ�����IS --- ���������� ? ��ʵ����Щ����ģʽûʲô���ܣ���ҿ��Բο��������������ʺ������ݿ����� -> �������а汾���� -> ���ݿ������е���������ʵ��Щ����ģʽ��ǰһƪ�������г��֣���ҿ����ڿ�����Ķ����ٻ�ͷ����ǰһƪ��������ݡ������Ҿͼ�˵˵�� ��������S ���� �����Dz�ѯ(select)����ʱSQL SERVER2005�᳢�������������빲������������ǰ�����ڵ�ǰ�������ϲ������빲�������������������Դ�ϴ��ڹ�����ʱ���κ����������������ݵ��ǿ��Զ�ȡ���ݡ���ȡ����һ��ɣ��������ͷ���Դ�ϵĹ����������ǽ�������뼶������Ϊ���ظ���������𣬻������������ʱ������������ʾ(HOLDLOCK)������������ ��������U ���� ��������һ�ֽ��ڹ�������������֮�����������һ���м���������һ���м�բ�ţ��Ѵӹ�������תΪ����������������Ŷӣ���Ч�ķ�ֹ�������������ڿ��ظ���������л������У�һ�������ȡ���� [��ȡ��Դ��ҳ���У��Ĺ�������S ����]��Ȼ�������� [�˲���Ҫ����ת��Ϊ��������X ����]�������������������Դ�ϵĹ���ģʽ����Ȼ����ͼͬʱ�������ݣ���һ�������Խ���ת��Ϊ��������X ����������ģʽ����������ת������ȴ�һ��ʱ�䣬��Ϊһ�����������������������Ĺ���ģʽ�������ݣ��������ȴ����ڶ���������ͼ��ȡ��������X �����Խ��и��¡�������������Ҫת��Ϊ��������X ����������ÿ�����ȴ���һ�������ͷŹ���ģʽ������˷��������������˸�������ɱ�������DZ�ڵ��������⣬�ڲ��ҵ�Ҫ���µ����ݺ�SQL SERVER���ȸ��������ø�����������Ϊ����������������������⣬�������������ù�������ʱ��Ȼ�������ø����������̶������������ģ��������Ҫ�����ݵ��������ȴ��������������Դ���������ת��Ϊ��������X ������ ��������X ���� ���������Է�ֹ�����������Դ���з��ʡ�ʹ����������X ����ʱ���κ����������������ݣ�����ʹ�� NOLOCK ��ʾ��δ�ύ�����뼶��ʱ�Ż���ж�ȡ������ ��������䣨�� INSERT��UPDATE �� DELETE���ϲ����ĺͶ�ȡ�����������ִ��������IJ���֮ǰ����ִ�ж�ȡ�����Ի�ȡ���ݡ���ˣ����������ͨ�����������������������磬UPDATE �����ܸ�����һ��������������һ�����е��С��ڴ�����£���������������ϵ�������֮�⣬UPDATE ��仹�����������ӱ��ж�ȡ�����ϵĹ������� ��������������������ͷš� ��������I���� ���ݿ�����ʹ����������������������S ��������������X ��������������νṹ�ĵײ���Դ�ϡ�������֮��������Ϊ������������Ϊ�ڽϵͼ�����ǰ�ɻ�ȡ���ǣ���˻�֪ͨ�����������ڽϵͼ����ϡ� ��������������;�� l???????? ��ֹ���������Ի�ʹ�ϵͼ��������Ч�ķ�ʽ�Ľϸ�����Դ�� l???????? ������ݿ����� �ڽϸߵ����ȼ���������ͻ��Ч�ʡ� ���磬�ڸñ���ҳ����������������S ����֮ǰ���ڱ������������������ڱ��������������ɷ�ֹ��һ����������ڰ�����һҳ�ı��ϻ�ȡ��������X ����������������������ܣ���Ϊ���ݿ�������ڱ��������������ȷ�������Ƿ����ȫ�ػ�ȡ�ñ��ϵ�����������Ҫ�����е�ÿ�л�ÿҳ�ϵ�����ȷ�������Ƿ���������������� ���������������� (IS)���������� (IX)�������������� (SIX)��������� (IU)������������� (SIU ��S�� IU �������)�������������� (UIX��U ���� IX �������)�� �������SIX��SIU��UIX���ǿ��������һ��ת����������������SQLSERVERֱ������ģ�����һ��ģʽ����һ��ģʽת��ʱ�м�״̬������˵SIX��ʾһ�������й��������Ľ���������ͼ������������������������������һ�����й�����������Դ���в��ַ�ҳ���б���һ�����̵��������������ˡ�����ͬ���������⡣ Ϊ�˸��õ�˵��һ�㣬 ����ȿ�һ��ͼ�� ? ? �ܹ������ܹ����� Sch-M �����ܹ��ȶ�����Sch-S ���� ִ�б������ݶ������� (DDL) ���������������л�ɾ������ʱʹ�üܹ��������ڼܹ����������õ��ڼ䣬���ֹ�Ա��IJ������ʡ�����ζ�����ͷżܹ�������Sch-M ����֮ǰ������֮������в�����������ֹ�� �������ѯʱ��ʹ�üܹ��ȶ��������ܹ��ȶ������������κ���������������������X ����������ڱ����ѯʱ���������� [�����ڱ�������������X ����������] ���ܼ������С��������ڱ���ִ�� DDL ������ ? ��������������BU ���� �������ݴ��������Ƶ�������ָ���� TABLOCK ��ʾ����ʹ�� sp_tableoption ������ table lock on bulk ��ѡ��ʱ����ʹ�ô���������������������������������߳̽����ݲ����ش��������ص�ͬһ����ͬʱ��ֹ���������д������������ݵĽ��̷��ʸñ��� ����������Χ����Key-range���� ��SQL SERVER2005���������ͼ���������������Χ���������������͵ļ���ȡ���ڸ��뼶�𡣶������ύ�������ظ��������ո���ʱSQLSERVER����ʵ�ʵ�������(����Ƕѱ�����ʵ�ʷǾۼ������ϵļ���ͬʱ��ʵ�����ϵ�����)������ǿɴ��л�����ʱ�Ϳ��Կ�������Χ���������ڵİ汾������ʵ����Կ���SQLSERVER��ͨ����ҳ�����������ʵ�ֵģ�Ҳ������Χ�������������ģ���������Ӧ�ÿ������ȷ�ҳ��������������ķ�ΧҪС�ö࣬�ڱ�֤�����ֻ�Ӱ��ǰ���¼���Χ������ǰ�汾���������ṩ�˸��ߵIJ������ܡ� ����Χ�������������ϣ�ָ����ʼ��ֵ�ͽ�����ֵ����������ֹ�κ�Ҫ���롢���»�ɾ���κδ��и÷�Χ�ڵļ�ֵ���еij��ԣ���Ϊ��Щ���������Ȼ�ȡ�����ϵ���������Χ����������Χ-�и�ʽָ���ķ�Χ��������������һ�������ģʽ(Range��Χ-���������ģʽ)�����磺RangeI-N ��RangeI ��ʾ���뷶Χ��N(NULL) ��ʾ����Դ������ʾ�������в����¼�֮ǰ���Է�Χ�� ��SELECT * FROM MASTER..SPT_VALUES WHERE [TYPE] = 'L'��ѯ��������9�������Ǽ���Χ�����������������ʱ��Ƚ϶�һ����sys.dm_tran_locks�к��Ѽ���������RangeI_N������������ڼ���Χ�ڲ����¼ʱ��õģ��ڼ���Χ���ҵ�λ����������ΪX������������̺̣ܶ�������sys.dm_tran_locks�к����ҵ�������Ӱ�����������ǿ���ģ������ģ�����������ģ��һ�£� ? ��ѯһ�� DROP TABLE TB GO CREATE TABLE TB (ID INT primary key, COL VARCHAR(16)) GO INSERT INTO TB SELECT 1,'A' GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE BEGIN TRAN SELECT * FROM TB WHERE id? BETWEEN 1 AND 5 --OLD���� --COMMIT TRAN --Don't commit SELECT @@SPID /* (1 ����Ӱ��) ID????????? COL ----------- ---------------- 1?????????? A (1 ����Ӱ��) ? ------ 52 (1 ����Ӱ��) */ ��ѯ���� ? INSERT TB SELECT 2,'E' ��ѯ���� exec sp_us_lockinfo ? ? ? ?????? �������������������ӵĿɴ��л����뼶���£�ѡ��������ֵ�ڡ�1-5��������ʱ��SQL SERVER ������1-5֮���ֵ���ü���Χ��������������������Χ�ڵļ�ֵ�IJ��뼰�����Χ�ڼ�ֵ��ɾ�������¡� ? ?????? ���ǿ��һ�¼���Χ�������������� 1��? ����뼶���������Ϊ SERIALIZABLE�� 2��ѯ����������ʹ��������ʵ�ַ�Χɸѡν�ʡ����磬SELEC�е� WHERE �Ӿ䡣 ? 3���������Ծ��� �������Կ��ƶ�������ܷ�ͬʱ��ȡͬһ��Դ�ϵ����������Դ�ѱ���һ�����������������������ģʽ����������ģʽ�����ʱ���Ż������µ������������������ģʽ����������ģʽ�����ݣ����������������ȴ��ͷ���������ȴ�����ʱ������ڡ� ? ? ? ? 4�������������Դ���������� ?????? ����Դ��Դ����Щ�أ�����ǰ���Ѿ��� SELECT * FROM MASTER..SPT_VALUES WHERE TYPE = 'LR' �������б���һ����12��֮�࣬��ʵ���Ǵӱ�ƪ�Ŀ�ʼ������һֱ�ڽӴ���������RID����������KEY������ҳ��PAG��������TAB��������(OBJECT)�������ǿ���������Դ���⼸�������Ѿ��Ӵ����ܶ��ˣ������ҾͲ�����ע�ļ�������һ��˵���� ?????? EXT �������ݻ�����ҳ����չ����һ������Ժ���ʱ�������������ݴ洢��������ҳ�Ľṹʱ����ϸϸ˵˵��չ���������ǿ��Լ�����Ϊ����չ��һ��64K�ķ��䵥Ԫ������������8��8K��ҳ��ɡ�SQLSERVER�ڱ�������������չʱ�����8��������8K�ռ䣬ÿһ����չ����ҳ����8�ı�����������չ�䱾����һ������Ŷ�����������������Ƭ�ˡ�����չ��Ҳ���Լ���������ʵ��Ҳ�����⣬�ڲ�ͬ�ı���������Ҫ�µ���չʱ��ϵͳΪ����ͬһ��չ��������ʹ��(����������ͬʱ�õ�һ����չ���DZȽϿֲ�Ŷ)�����й���������������������ϵͳ�Է����еģ�����һ�㿴���������������ϵ�һ����������ǰ���ᵽ��һ���������ٺ���ӡ������Ҳ�����������һ����ʵ�ϵ������� ?????? DB���ݿ�(DATABAES)����ʵֻҪ�Ҵ�һ�����ӣ������ʹ��sp_us_lockinfoһ���õ�һ����Ӧ��ǰ���ӵ�DB���͵������������ͼ61 select @@spid go exec sp_us_lockinfo ? ? ? ? ? ��ô��DATABASE�����������м������أ�Ϊ���Ӧ��Щ�����أ��ܲ���ģ������أ��ã�����������ģ��һЩ�ɣ�����ɾ��������� 1��? �ȴ�һ��managerment studio,�����ȴ���һ�����ݿ⣬����Ϊdblock�����ú�����һ������ǰ���Ǹ�����sp_us_lockinfo 2��? ����һ��managerment studio���һ�dblock����ɾ���������ڵ����Ĵ��ڵ�ȷ�� 3��? �ڵڶ���������Ѹ���л�����һ��managerment staido���������´��� �����õ�ͼ63 ? select @@spid ?exec sp_us_lockinfo ? ? ?????? ����ͼ���������ǿ������ǵ�һ�������Ӷ�Dblock��һ��DB��Դ���͵Ĺ��������ų��˵ڶ���ɾ�����������������ٱ�����������Dblock���ó�ֻ������������棬���˼�������Ŷ!�ȴ�������ѯ(һ��Ҫͬʱ������Ŷ!!) ? ��ѯһ�� alter database dblock SET READ_ONLY ? /* ��ѯһֱ�����С��� */ ? ��ѯ����(���ͼ63) select @@spid exec sp_us_lockinfo ? ? ? ?????? ����������ҿ����Լ�ģ�� �� ? ?????? APPӦ�ó�����Դ����һ��Ӧ�ó�������ģʽ��֮��Ӧ��Ӧ�ó������͵���Դ����������ǰ�����۵���������ģʽ����һ����ǰ�����е�����ȫ��SQLSERVER�Լ������ģ�Ӧ�ó�������������SQLSERVER�ļ�������������Ļ����������Լ���Ҫ�������κζ���������������Ҫ�ﵽ��һ��Ч����һ���������ͬʱֻ��һ�������ܹ����С�Ϊ����ģ���������͵��������ȿ�������� ? sp_getapplock [ @Resource = ] 'resource_name',????? [ @LockMode = ] 'lock_mode'????? [ , [ @LockOwner = ] 'lock_owner' ]????? [ , [ @LockTimeout = ] 'value' ]???? [ , [ @DbPrincipal = ] 'database_principal' ][ ; ] ? ����������ģ��һ�£� ? ��ѯһ�� exec sp_getapplock 'testapplock','exclusive','session'; go ? select * from ta ? --sp_releaseapplock 'testapplock','session'; ? ��ѯ���� exec sp_getapplock 'testapplock','exclusive','session'; go ? select * from ta /* ��ѯһֱ�����С����������� */ ? ��ѯ�������ͼ64 --create database dblock select @@spid exec sp_us_lockinfo ? ?? METADATA Ԫ���ݡ��������͵Ŀ�������Դ������ʵǰ���Ѿ��п������������ĵ�ǰ��Ϊֻ��ʱ������ͼ65 ? ? ? ? 5�����ı��ʡ��������ڼ�����������ʵ������ ?????? �����Ҹ��ߴ��SQLSERVER����֪��(����)���������Ķ�����ʱ��ʹ�����ܹ���������ȴ����ȷ��������������Ľṹ������������һ���е����˰ɣ���ô��Ҫ������������������֪���������Ķ����Ǻη���ʥ���Ǻǣ���������˵һ���ڲ��Ľṹ�� ?????? ����SQLSERVER��һ���ڴ�ṹ��������һ�����������ݽṹ����������Ԫ��������������¼�ġ��رջ���ֹһ��������Ӧ�IJ���������Ϣ�ͻ���ʧ������ṹ���϶������飨Lock block����������������������ݡ�������������ص���Ϣ��������Ȼ��Щ������Ҫ����ͬ������ӵ�еģ�SQL����һ���������߿���������Щ�������߿�������֮��ͨ�������ߵ�ָ�������� ����������һ��ר�Ŷ�������Դ�������ṹ����Դ�飬��Դ�鸺��ά����Դ���ơ������ָ�롢�Ѿ���Ȩ��������ָ���б���ת���е�������ָ���б����ȴ����������б�������Դ����һ������������ռ��һ���ֽڣ����������������ǰ���Ѿ�ͨ��SQL�������б����� ? ��ѯһ�� ? SELECT * FROM MASTER..SPT_VALUES WHERE TYPE = 'LR' ? ? ?????? �Ծ������Դ������12���ֽڵ��ڴ�ṹ����¼��������2000��ʹ�ù�һ����syslockinfo����Щ��Ϣ��rsc_bin�������֣�����ֶζ���Դ�����������������͵IJ�ͬ����12���ֽ����Ų�ͬ�ķֹ���ϡ��������һ�Ҫ����2000�µ��û���rsc_bin��2005�����岻�ٵ�ͬ��2000�����ǽ���С�IJ��Ϊ��˵����������۵㣬���Զ�syslockinfo����һ�����룬֤��SQLSERVER�Ա��Ķ����Dz����ĵġ���������ʵ�ʿ�������������ݣ��������ͼ66 ? ? Query 1: ? CREATE TABLE TB (ID INT primary key, COL VARCHAR(16)) GO INSERT INTO TB SELECT 1,'A' GO SET TRANSACTION ISOLATION LEVEL repeatable read BEGIN TRAN SELECT * FROM TB WHERE id? BETWEEN 1 AND 5 ? ? ? ? ? ? ��������������ʵ�����ͣ������ǰ��ļ���ÿһ��ͼ���ﶼ���Կ�����һ�С�ͼ68 ? �����ͼ������ֻ�������࣬�����������࣬һ�����ࣺ�������ͣ��α����͡��������ռ����͡��Ự���͡� �����������ͣ�����Ͳ��ö�˵�˰ɣ�����������ʽ�Ŀ�ʼһ������ʱ�������Ӷ�����һ���������͵�ʵ�塣 �����������ռ����ͣ�����SQLSERVER2005����ġ�SQLSERVER2000�����г��������α����͵�ʵ��ȫ��Ϊ�Ự�͡�ͨ�����ǿ��������ݿ⼶�������ǿռ����͵ģ�Ҳ���ǻ���һ���Ự�Ͷ�Ӧһ�������ռ䣬�����Ự�����е����ݿ⼶�����ᱣ������ͬ�Ĺ����ռ������ڰỰ����ʮ����Ҫ�����塣 �Ͱ���˵MS��ȷ�����Ժ�İ汾��֧���ˡ���Ϊ��������ǰ�汾�ù������������˵˵�� ��˵˵���ֵı����ɣ�������ȷһ�������������Ƿ����ڲ�ͬ��SQL���̼䣬Ҳ���ǽ����Լ��Dz�����Լ��������ġ���������ȷһ���Ϊ��ͬ���̣�ÿһ��������SQL���ӣ��������Dz�Ҫ�������Ϊͬһ���û�ͬһ�������һ��һ�����ӡ�һ�����̡���ʵ��ͬһ���û�ͬһ��Ӧ�ó���ӵ�ж�����Ӽ����̵Ŀ��ܳ��Ƿdz���ġ���ô������Ȼ�Ϳ�������ͬһ���û�ͬһ�������Լ����������Լ�����Ϊ��ӵ�ж�������ǰɣ���SQLSERVER����֪��ͬһӦ�ó���ӵ���ļ������ӣ�Ҳ��֪����Щ���Ӽ���ô�����ġ���ô���������ô����ء���SQL6.5�Ժ�SQL2005��ǰ�����ð��֣���Ȼ2005Ҳ֧�֣�����MS��ȷ���Ժ�İ汾���ܲ�֧���ˡ� ��Ϊ���ذ��ּ��ֲ�ʽ������ɲ�ͬ������ͬһ����ռ��ڵĽ�����ͬ�������Ϲ�����Ԫ�Ľ�����һ������Ե�һ�����ӽ������Ӳ����롰�����ơ���������ƾ���һ������ռ�ı����ַ�������������ַ����ɹ����������ӽ��м��������������������Ӧ������ռ�ͻᱻ������ �������һ�����ɣ� ? ��ѯһ�� ? begin tran declare @token varchar(100) exec sp_getbindtoken @token output select @token ? select * from tb update tb set col = 'b' where id = 1 /* ------------------------- .Y4bBahH9aCGCj[a[0b-:-5---03E=-- (1 ����Ӱ��) ID????????? COL ----------- ---------------- 1?????????? A (1 ����Ӱ��) (1 ����Ӱ��) */ commit tran���C-��һ��������ѯ��ִ�����ִ�У�һ��Ҫע�� /* �˻Ự�еĻ������������һ���Ự�ύ����ֹ�� ��Ϣ3902������16��״̬1����1 �� COMMIT TRANSACTION ����û�ж�Ӧ��BEGIN TRANSACTION�� ? */ ��ѯ���� select * from tb where id = 1 ? /* ��ѯһֱ�����С��� */ ��ѯ���� ? exec sp_bindsession '.Y4bBahH9aCGCj[a[0b-:-5---03E=--' update tb set col = 'c' where id = 1 commit tran select * from tb ? /* (1 ����Ӱ��) ID????????? COL ----------- ---------------- 1?????????? c (1 ����Ӱ��) */ ? ??? �ڲ�ѯһ��������������һ�������ơ���Ȼ��ʼ��ID��1�ļ�¼��ע�⡡�����Ǹ���ΪB��Ȼ�����Ǵ���һ���Ӳ�ִ�ж�ID��1�IJ�ѯ�����ֲ�ѯһֱ�����У���������һ����ִ��sp_us_lockinfo��ᷢ���ڹ����������ڲ�ѯ���������ȹ����ղŵ����ӣ�Ȼ��������ݵ��ģ�ע��������ID��1��COLֵΪc���ύ������ʱ���Dz�ѯ����������ݷ��ּ�¼�ǵ�������ѯ��ִ���ĵĽ������Ȼ���������̼�û�����������ʱ�����ֻص���һ����ѯ��ִ��commit tran�㷢�������ύ����ʧ�ܣ���Ϊ��ǰ�����Ѿ��ڵ�������ѯ���ύ�ˣ����Գ���Ӧ�Ĵ��� �������˵��һ�°�����û�и��������ƣ���ʵ����������Ͻ�Ҳ�鷳����2005��һ���������������ѡ�����ʵ��������ƻ������ܣ�Ĭ�����ǹرգ���ҿ������в��ԡ� ? ? �����α��ͣ�������Ǿ������õ���ֻ��û��ע�⡣����ʵ�������ʹ���α�ʱ��ʽ���룬ÿ��ȡһ��ʱ�õ�һ���α�����ֱ����ȡ��һ����ر��α꣬����ʹ���ύ��rollback��������α�����Ҳ�����ͷţ�����ô�������أ���������ʵ���� ? ? BEGIN TRAN DECLARE @f1 varchar(10) DECLARE cur CURSOR SCROLL_LOCKS ??? FOR SELECT f1 FROM ta FOR UPDATE OPEN cur FETCH NEXT FROM cur INTO @f1 EXEC sp_us_lockinfo �C����һ��ͼ69 WHILE @@FETCH_STATUS = 0 BEGIN ??? UPDATE TA SET s1 = 0 WHERE CURRENT OF cur ??? EXEC sp_us_lockinfo �C�ڶ���ͼ6a ??? BREAK;--ֻȡ��һ���ˣ�������¼��ͬ�����Բ���ģ�� ??? FETCH NEXT FROM cur INTO @f1 END EXEC sp_us_lockinfo��������ͼ6b CLOSE cur DEALLOCATE cur EXEC sp_us_lockinfo�����Ĵ�ͼ6c COMMIT EXEC sp_us_lockinfo�������ͼ6d ��ͼ69�� ? ? ��ͼ6a�����ע����һ��ͼ����Ϊ����һ���ɸ����α꣬����ȡ����һ�м�¼ʱ��ͼȥ���µ��е���Ϣ����Ϊ��ʱ�����ͺ��α���ʵ��ͬʱ�����ˡ� ? ? ��ͼ6b�� ͼ6b��ͼ6��ͬ������ֻ��ģ��һ��ȡ�������к����ݿ��ϵ�������Ϊ�� ��ͼ6c�����ǹرղ�ɾ���α����ú������ݿ������µ�������Ҳ�����ڹر��α���α���ʵ�����������ˣ�ֻ���������͵�ʵ�壬��Ϊ�������ǿɸ����α꣬��������ʵ�����и��¶���������������������������ڡ� ? ? ��ͼ6d��ֻ�е�ǰ�Ự���������ռ���ʵ���� ? ? ? ? ���������һ���κ���ҵ�� ? 1��? �Ա��ṹ����A�ij�B����õ�ʲô���Ľ����ע��Ŷ����ʱ�����һ��NULL������Ŷ���������������Ϊ�������ģ�����ʵ��������A�ṹ�²��Եģ��� A�� create table ta(f1 int,s1? char(10)) insert into ta select 1,'a' ������������һ������������ζ��ʲô�� B�� create table ta(f1 int primary key ,s1? char(10)) insert into ta select 1,'a' ? 2��? ����һ�ʵ�B�ṹ�£�ִ������SQL��������ʲô���Ľ������ϸ�Ƚ� BEGIN TRAN DECLARE @f1 varchar(10) DECLARE cur CURSOR SCROLL_LOCKS ??? FOR SELECT f1 FROM ta --FOR UPDATE OPEN cur FETCH NEXT FROM cur INTO @f1 EXEC sp_us_lockinfo WHILE @@FETCH_STATUS = 0 BEGIN ??? UPDATE TA SET s1 = 0 WHERE f1 = 0 ??? EXEC sp_us_lockinfo ??? BREAK;-- ??? FETCH NEXT FROM cur INTO @f1 END EXEC sp_us_lockinfo CLOSE cur DEALLOCATE cur EXEC sp_us_lockinfo COMMIT EXEC sp_us_lockinfo ? ? ? �Ự�ͣ��Ự������������ʽ�����룬�������ҽ���APP������Դʱ������ȷ�ĻỰ������ʵ�����ͣ���ҿ��Կ���ƪ��APP������Դ�������һ��ͼ������ ? ? ? ? ���������������ڣ����˵˵���ij���ʱ�䣬�������dz����������������һ��������Ҳ��һ������ʱ�䡣����ʱ����ʵ��ȡ��������ģʽ������ȼ����������ǻ�����ʹ��������ʾ���ı����ij���ʱ�䡣��Ϊ�������ʱ������dz����������������һ��������ϰ�߳�Ϊ�������ڡ� ?????? ����������ʾ�ı������������������Ժ���˵���ҰѼ����ȼ��³���ģʽ��������һ���б��� ? ? ? (�Կ���ģʽ������ģʽ�е�����ش˸��£����Ǹ��) ? ?6�������� ��ֹ������ ?????? ����������һ����ѯ���������������С���ݣ����Ȳ�ͬ���ݿ�����ܺͲ��������Ǵ����˳��ģ���ô�������أ�����������ԽС�������û���Խ�࣬�����Զ��ģ������ʱ����һ�����������ҵ�����Ҫ���������ļ�¼�������и��£��ڱ��ֲ����û���ǰ���£����������ļ�¼������������ͺܶ࣬����֪������������ѵ���ͣ���Ҫ�������۵ģ�������������Խ��ϵͳ��Դ������Խ���ǵ�������ǰ����ܹ�����ɣ�������һ��64/128(128��64λ����ϵͳ)�ֽڵ��ڴ�飬�����ÿһ�����������������Ľ��̻�Ҫ��һ��32/64(64��64λ����ϵͳ)�ֽڵ��ڴ����������Щ���̣����������ȷ��һ��ǰ������������ȵĴ�С��ÿһ��������ռ�ü���ͬ����ϵͳ�������ã���������Ҫ����10W�����ݸ��£�Ϊ�˲������Ƕ�������������������������Ķ�����ô���Ǿ͵���Ҫ64B * 100000+N*32B= 6400000B +32NB(���۸�������ȡN=1�����6400000���Ժ���)> 6.4M��RAM��������Щ���������貢������(��Ȼ�Dz�ͬ��Դ�ϵ�)������X����ô��ǰ���ݿ�͵�ҪX*6.4M��RAM���ڹ�����������Ȼ���ֶ�RAM�����������ϵͳ�����ܣ������������Ƶ������������������ôSQLSERVER����һ�ְ취����ֹϵͳʹ��̫����ڴ����������������������Ч�ʡ��������������������������ƽ����Դ��ʹ��(��Ȼ��������ض������Ŀ�ʼ������������������������)����ʱ�������Ͳ�ȡ����������һ�������������������ҳ������Ϊ�����������Ƚ�6.4M��96B����Ȼ��ȡһ�����������ȳ��������л�����������塣 ?????? ���������������Զ�����ʹ�����������½�������ϵͳ��Դ�ľ����ڽṹ�����������ἰ����������ϵͳ����������������ڴ������ģ�����������֤������ռ���ڴ�ά��һ���������ȡ� ?????? ������������ʱ���� 1��? ��һ��������һ����ѯ����³�����������������ֵ��SQL2005ȱʡ��5000����(�ǵ�SQL6.0ֻ��200������������Ҫ��סSQL6.0ֻ��ҳ������Ŷ)�� 2��? ����Դռ�õ��ڴ泬��AWE���ڴ��40%��40%��һ��Լ���� ʱ��һ����SQLSERVER�ͻ᳢������������Ȼ������һ����ɹ�����ʧ�ܺ���ͬһ�������ϵ�����Դ�ٴ�������һ���̶�ʱ�������ٴη�������������ɹ�SQLSERVER���ͷŶ�������ǰ��õ��С�������ҳ����������ʧ�ܷ���������һ�����̶Ա����л�ҳ����������ʱ�� ������DZ�ڵ�Σ�գ� 1��? �������Ľ��һ����һ����ȫ����������Ҳ���Dz����ܳ�����������Ϊҳ���ģ���ϸ���м���������ֱ�ӽ��һ���DZ������� 2��? ����������������������(���Ӧ���Ǻܺ������) 3��? �������ɹ��������� ��ֹ���� ����֪������������DZ�ڵ�Σ�գ��������������Ľ���Dz������ֽ���������������������������Ƕ����е�Ӧ�ö���һ�����£�MS�ṩ�����������1211��1224�����ǿ���ͨ�����ø��ٱ�ʶ����ֹ������ 7��������ҳ�� ?????? 7.0֮ǰ�İ汾��������С���Ⱦ���ҳ�������Ѵ��һ����ʱ��ҳ����С��λ��2K�����ϸ�IJ���һ���̶����ǿ������㹻��ą������Ϳ��Խ��ܵ���Ӧʱ�䡣Ȼ��7.0��ѷ�ҳ��2KB����Ϊ8KBʱ(ΪʲôҪ�����أ��ٺ٣���һ�����ʸ����)������ҳ�������Բ���������һ����ս��Ҳ���������ķ�Χ��7.0֮ǰ��4������ʱ��������Ӧʱ�䶼��һ�����⡣SQL2005��ȫʵ���м���������Ȼ��Բ�����Ӧ�ǿ�ϲ�ģ����������������������������һ���ʣ����������õ�������Դǰ���£������м������Ĵ��ۻ������������ܵģ��ر��ڼ���״̬�¡� ?????? ����֪������������һ���ܼ��Ͳ�����һ����������Ҫ�����ڴ����ģ���Ҫ����SQLSERVER������Щ�������䱾����Ҳ��һ�ָ��ɡ���ȻSQL�ڲ�ʹ���Ż����������������ָ��ɣ������Ǻ��������������һ����ҳ�����ȹ���N���м�����(����ҳ������N�м�¼)�����ɡ�����Ч�ʡ� ?????? �Ƚ�������ҳ�������������˲�����ͻ������Դ�����Ҳ����Ȼ�ģ�ҳ�����ٱ����������������������Щ��������Դ��ĵ����Բ������½�Ϊ���۵ġ������ĸ������ʣ����²���һ��������˵��ģ���Ϊ��Բ�ͬӦ�á���ͬ��ҵ����ͬ����ģ�͡���ͬ�����������и������ơ� ?????? ��SQLSERVER2005������sp_indexoption������������������λ����������������ǿ��Կ�����������������һ��Ҫע����ֻ����������ԶԶѱ������Ʒ�ҳ������ 8����̬�������� ?????? SQL�����������͡������ǻ�������������ɨ���ҳ��������ҳ�ϵ����������뼶�𡢽��еĺ��ֲ�������ʹ�õ�ϵͳ��Դ�����ص�Ӱ�� ��������ЩӰ������SQLSERVERѡ��һ�ֺ��ʵ�����ģʽ������̳ƶ�̬��������(�ҷ��ֲ�����MS������)�����ݿ�����(����ӡ����������ṹ�н��ܵĴ洢�����)��̬�Ĺ������Ⱥ�����ģʽ������������ϵͳ��Դ����ѳɱ�Ч�ʡ�һ����Χ�ڵ�������Ҫʹ�õ�ϵͳ��Դ�϶�С������ϵͳ�IJ�����Ҳ�ͽ��ͣ����ѡ��С��Χ�ڵ��������ǹ���������ʹ�õ�ϵͳ��Դ������Ȼ����������ȴ�õ������췢�ӡ� ?????? һ��������ǿ�ʹ��ϵͳȱʡ����(�м�������ϵͳȱʡ��)����ϵͳ�����Ƿ�Ҫ��������������������һ�������ǶԿ������Ĺ�����ϵͳ����ʵ�����ƽ�⸺�ء� 9������ ���ȣ����ǵ����������ȴ��������¡��ȴ��ǵ�ǰ��������Ҫ����Դ����һ�����������ˣ�ֻҪ����һ�������ͷţ���ʱ���̾Ϳ��Լ���ִ��(��Ȼ���������������Ѿ������ǻ���������ڵȴ��������������һ�㲻�ᷢ������ΪSQLSERVER���Ԥ�����ġ��������ǻ���һ��������ʱ���� ���ⷽ���ҿ��Կ���������)���������Ƿ������������̼䣬��û����Ϊ��Ԥ���������Ľ����Ƕ�������������һ������������һ�������ĵط���������һ��������SQLSERVER�ͻ��Ԥ�������������ܸ�֪������յ�1205�Ŵ���׳��Ӧ��ϵͳ���˹���Ԥ1205����ǡ���������ύ����������1205������û����ֹ�Ľ��̻����Ӧ����Դ�������Լ�������ֱ���ͷ���Դ����ʵ������Ϊ�ĸ�ԤDZ�ڵ���Ϊ�����ṩһ�����ڻ�������Ȼ����ǰ��д��һ������Ҳ���Բ�ѯ����Ӧ��������Ϣ�� ���ţ�����������ȫ����ġ���һ�������Ķ��û�ϵͳ���������̡߳��ڴ桢���в�ѯ��MARS�������ķ����������ġ�����Ԥ���ģ�Ҳ�DZ�Ȼ�ġ�������������Χ��ֻ�ܾ����ܵ���Ӧ�ö˻��������ǡ���Ĵ���������ʹ����������ȫ������¼���ϵͳ������Ӱ�콵����͡�Ҳ��������Ӧ�����ף�����������ȫ���⣬�����ҿ��Խ��ͷ����Ĵ����� ������������һ��ĩ�գ�û����Ϊ��Ԥʱ��Զ�˲�������״̬��һ�������Ķ��û�ϵͳ���־�����Դ�Ŀ������Ǻܴ�ģ�һ�о����ͻ��С�ì�ܡ�������˫���ȴ��Է��ͷ��Լ�����Ҫ����Դ����Ȼ���������ڵȴ������ֵȴ�����������˵������������ͨ������Ľ���֪����ʱSQLSERVER�����������Ԥ������̣��������û��SQLSERVER���������ĸ�Ԥ��ô��������һ���h�Ľ�����������ڵȴ�������Ӧ��ϵͳ��˵����һ��ĩ�ա�SQLSERVER2005�����ṩ�˷ḻ�����й�Ԫ���ݣ����Ժܷ��������������Ϣ��SQLSERVER����������Ԥ�Ľ�����Ǹ�������Ʒ�����ȵȼ����ع����ۣ������ȼ��ͺʹ�����С�Ľ��̵�������Ʒ��ɱ��������̲��׳�1205���� ���ģ����������Ϊ���ࣺcycle������conversion������Ӧ�ü����������������� Cycle�������ǽ���˫�����е���������Դ������һ����Ҫ����Դ������˵����Aӵ��TA�ı�����������ʱ����������TB����������ͬʱ����B��ӵ��TB����������Ҳ������TA�ı����������������ǽ���A��ҪTB�������������Ѿ��ý���B����������B��Ҫ��TA����Ҳ�Ѿ��ý���B��������ʱ��������������������ģ��һ�£� ? create table ta(id int,col varchar(10)) create table tb(id int,col varchar(10)) go ? ��ѯһ�� ? BEGIN TRAN UPDATE TB SET COL = 'A' WAITFOR DELAY '00:00:05' ??? UPDATE TA SET COL = 'B'? --COMMIT TRAN ? ? ��ѯ���� BEGIN TRAN UPDATE TA SET COL = 'A' WAITFOR DELAY '00:00:05' EXEC SP_US_LOCKINFO���C-������ǰ��ȡ������Ϣ UPDATE TB SET COL = 'B' --COMMIT TRAN ? ִ��˳���������в�ѯһ�����л���ѯ��ִ�У�������ǰ��������Ϣ�������г�����������Ϣ�� ? ? ??? ����ͼ���ǿ��Կ��ó���һ��ʼ��ѯһ�Ͳ�ѯ���ֱ�����TB��TA�ϵ��������к�Ϊ20��25�ļ�¼���ǿ��Կ����ֱ����������������ҽ�˵��RID,�ڱ���ҳ��Ҳ����Ӧ������������Ϊ��ѯһ��ִ�У���ô5S���������TA����ʱ�������������ǴӼ�¼26���Կ���SPID��53�Ľ�����Ҫ��ȡ��TA���еĸ���������SPID��52�Ľ���������������ȴ�״��ע����ʱ��������Ŷ���ǵȴ�Ŷ�����Ӳ�ѯ��5S���˿�ʼִ�и���TB�ϵļ�¼�У���Ȼ���ʱ��TB������53��������������������������Ϊ����52�ȴ�53�ͷ�TB�ϵ�����������53�ڵȴ�52�ͷ���Դ�������˱���״̬�������cycle��������ʱ���ǻ�SQLSERVER�����˸�Ԥ����ѯ���׳����ع����� ? ��Ϣ1205������13��״̬45����8 �� ����(����ID 52)����һ�����̱�����������Դ�ϣ������ѱ�ѡ����������Ʒ�����������и����� Ϊʲô˵���ع��أ�������������ʱSQLSERVER�Զ������ģ�����������ύ��ѯ����commit��䣬��ᷢ�ֱ����´���3902���� ? ��Ϣ3902������16��״̬1����1 �� COMMIT TRANSACTION ����û�ж�Ӧ��BEGIN TRANSACTION�� ? conversion������ת�����������ڲ�ͬ�����ڲ�ѯ��ͬ�����ݺ������Ը��¸ղŲ�ѯ������ʱ����ʱ��Ҷ�����ͬ���ݵĹ�����������������Ϊ�����������Ƕ���Ϊ�Է����ͷŹ�������������ȡ���������������������������dz����Ϊת������������������ģ��һ��conversion������ (Լ�������в�ѯһ����3S�����в�ѯ��) ��ѯһ�� ? select @@spid �C-53 set transaction isolation level repeatable read begin tran select * from ta waitfor delay '00:00:03' ??? update ta ??? set col = 'B' where id = 1 exec sp_us_lockinfo -�C�����ͼconversion1 commit tran ? ��ѯ���� ? select @@spid �C-52 set transaction isolation level repeatable read begin tran ??? select * from ta ??? ??? waitfor delay '00:00:05' ??? exec sp_us_lockinfo? --�����ͼconversion2 ??? update ta ?????? set col = 'B' ??? where id = 1 �C-ϵͳ���������׳�1205���� commit tran ? ͼconversion1�� ? ��ѯ������1205��Ϣ �� ��Ϣ1205������13��״̬45����7 �� ����(����ID 52)����һ�����̱�����������Դ�ϣ������ѱ�ѡ����������Ʒ�����������и����� ? ??? Ӧ�ü��������������������������е����⣬���˰������ǿ���ͨ����̬������ͼ����������������Ϣ����Ȼ������������Ҳ����Ԥ�����������ܿ���������һ������ռ�õ���Դ����������������DZ����ɸ�����������������˵ͬһ��Ӧ�ó���Ķ��̼߳䡢Ӧ�ó�������ⲿ�������������������ݿⷢ����ϵ������Ȼ�������ݿ��������̼�����������������ݿ���ϵ����ô�������������������״̬����ֻ���������ڵĵȴ���������Ϊ��ԤSQLSERVER�Ǹ�Ԥ���˵ġ� ??? ���ǰ�SQLSERVER�������������������Ʋ��������������������Խ���SSIS��ģ�⣬��������Ҫ���һ��������ǰ�δ����������ͨ��SSIS�����ļ��������Ѿ��������������ϱ�ʶ��������һ������ģ��������ݣ����������ύǰ����SSIS��������ݵ������ı�ʶ����ʱ���������Ҫ��һ��������������й������Dz����ܵģ����������һֱ���У�������������������Ҳ����⡣ ? ���壬������������SQLSERVER��һ�ж����߳������Եļ��ϵͳ������������������ʱ�������ļ��������С�����뼶��ֱ��������Ƶ�ʽ����ٴλָ���Ĭ�ϵ����ڡ��������������������Ȩ��ع��Ĵ��ۣ��������Ƿ��Ѿ���ʶΪ�ع�������״̬������Ʒ�����ȼ���ѡ������Ʒ��ɱ�����̲�����1205������Ҳ����˼����Ʒ��ռ����Դȫ���ͷţ�����������صĽ��̿��Լ������С� �����һ��������ǰ�ᵽ���ż�����������������Ԥ�����������ǽ��������������������������֮������Ԥ����������ΪMS�Ͻ��Ŀ��ƴﵽ����Ҫ���������� ? ��������������������ȫ����ģ�����SQLSERVER���������������DZȽ����״����ģ�ǡ�������ó�����Ĵ���ʹ�ö�������ص��û����̵�Ӱ�콵����͡���ν���䵱���ǽ��ܵ�1205����ʱӦ�ó���Ӧ�ܹ��ٴ��ύ����������1205������û�������Ӧ���������ǻ���������һ���¾��Ǿ����ر������� �ر��������Դ����漸������� ? l???????? �����ܵĶ̣�����ʱ��ͻ�̣� l???????? Ӧ�ó��������������������� l???????? ��ʶ��������Ҫ�ԣ� l???????? ��֤ҵ�����ִ��˳��ĺ����ԡ���ʵ���ԣ� l???????? ����ҵ�����ѡ����ʸ���ȼ��� l???????? ������ʼ����(dbcc opentran & set xaxt_abort on); l???????? ������Ϊ���������ִ��(��Ҫ���������˻���������)�� l???????? ����������ʾ(Lock Hint)���ı����������ȣ� l???????? ��ȷ��ʶʹ�ð� ? ? ����������һ���ܸ��ӵĹ��̣�����֤�˲�������Դ����ȷ������ʹ�ã����˽������Ļ��ƺ�Ը��ٽ�����������൱�İ�������������������һ��2005���а汾���ơ� ? 10���а汾�������� ??? �а汾������SQLSERVER2005��֤����������һ�µ��»��ơ�����ǰ���ᵽ����ģ�������֣��������ֹ۲��������а汾�������ֹ۲����µ�һ�ֱ�������������һ�µ��¼������а汾���ƺ�ǰ���ἰ���������Ʋ���һ������������д�Ľ�������Ľ��̼䲻�������������ڱ�֤������δ�ύ�������������������ݿ�IJ���������Ȼ������Ҫע������ֹ۲�����д�Ľ��̻��ǻ��ȡ���������������ἰ��һЩ����ģʽ������ʱ�估���������ķ�ʽ������������ ??? SQLSERVER2005ʹ���а汾���Ƶĸ�����������RCSI���͡�SI��RCSI����������������ύ��ģʽ����ν���������������ڴ�ͳ�����ύ��ģʽ��������ģʽ��д���̲������������̣������̲������ù�������������ʹ���а汾���ƶ�ȡ��伶��һ���Ե����ݣ���˵�����κζ������Եõ���俪ʼ��һʱ��������Ѿ��ύ���ݡ����ո���(SI)����ʹ�κζ����̶�ȡ��������һ�������ݣ���˵�����κζ����̶����Զ�ȡ������ʼʱ���ύ���ݡ� ??? SQLSERVER2005�������д�����������أ�һ������RCSI��SI�����ݿʼ��tempdb�д洢�����Ѿ��Ĺ��ļ�¼����(��¼�汾���Ժ�����ֱ�ӳ��а汾)��ͬʱ��֤��ֻҪ�н�����Ҫ��Щ���ݾͻ�һֱά����Щ�а汾������tempdb�ֱ����dz�Ϊ�汾�洢��������Ȼ���������а汾���ƺ�tempdb����Ҫ����Ŀռ��������а汾���������������ݿ�ʹ�����а汾������һ��Ҫ������tempdb���а汾��δ洢�ڰ汾�洢����������˵�� ??? �ã���������˵����Ӧ��������һ������Ѿ��ύ�����ݴ洢�ڵ�ǰ���ݿ⣬����������ǰ�����ݱ����Ƶ�tempdb�У���ô����֮�������ϵ�أ��������������һ�����XSN��ע��Ŷ��������LSNŶ��XSN��Ϊ�������кţ�����ͨ�����XSN��tempdb����а汾֮�䱣����ϵ���Dz����е�ָ��ζ��ѽ��������ͬʱ����Ҫע���ˣ�����XSNָ���а汾����ijһ���У�ͬʱ��һ���п��ܰ���ָ���оɵ�������XSN��SQLSERVEͨ������������Է��ʵ���ȷ�İ汾�� ??? ˵����ô�࣬�о�����а汾������ô����ѽ��������ǿ�˲��������ɣ������ڸ��ĵ�ǰ���ݿ�ʹ���а汾����ǰ����Ҫ��˼���У����ȣ�������tempdb�ĸ��������ָ����������ǿռ��ϵġ����ţ�ά���ɰ�������б�Ȼ�ή���²�����������������û�ж����̴��ڣ�ֻҪ�и��´������ݿ�͵�Ϊ�˸������ۡ����������ӵIJ�������ʹ��ÿһ�������̶��ø�������Ŀ��������ʸղ������ᵽ��XSN�����ҵ������а汾���������˵�����Dz�����ȫ����ģ������������ֹ�ģʽ��дд���������ġ��ں�������ģ����SI�µĸ��³�ͻ�� ?????? ����Ҫ����RCSI��SI֮����ʲô����أ���ʵRCSI��SI��Ϊ�ϻ������Ƶģ����ǿ����ڵ�ǰ����������ǰ���¶�ȡ����ǰ�����Ѿ��ύ�����ڰ汾�����ǵ���Ҫ����ж���һ���а汾��¼���а汾�������ʱЧ���˻���ô�����أ�����ǰ��˵��RCSI����伶�Ķ�SI�����ģ������ֱ�ӵ��������а��ж�õĹؼ�������RCSI���Ѿ��ύ�����������ı��֣���SI�Ǵ��������ġ��������ǻ�˵��˵����������Ϊ�� 11���а汾�� ?????? SQLSERVER2005ֻҪ�������գ����и��º�ɾ���ͻ������Ѿ��ύ���а汾������Щ�а汾�DZ������а汾������tempdb���ݿ�����ݷ�ҳ�ϣ���ʱ���Ͽ��յIJ�ѯ��Ҫ�����仰˵ֻҪ�в�ѯ��Ҫ���а汾�����ݾʹ��ڡ�SQLSERVER2005��һ�������̣߳����������һ���Ӿͽ���һ�λ��գ�����SI�����µIJ�ѯ�а汾�����������������RCSI�����µIJ�ѯ�а汾һֱ���浽��ǰ��ѯ�������� ?????? ����ᵽtempdb�������������tempdb��tempdbҲ�Ǽ�¼��־�ģ������Ǻö�����Ϊ�IJ���¼��������־��Ϊ����ʱ�����ϵ�����ع�����סֻ�ܻع������ָܻ�����������Ȼ�������⻰��һ�������� ?????? Tempdb�����������͵Ķ����û������ڲ����汾�⡣����汾���������Դ������һ���ؽ��������п��ռ�������ݿ���ִ����DML(����һ��˵���������ռ���)�����������������б���2000Ŷ��2005��α��(deleted ��inserted)�����а汾�����ģ������������� ?????? 12���Ѿ��ύ�����ո����¶�д��Ϊ ?????? RCSI����һ��Ҫ��ס����һ����伶�Ŀ��ո��뼶���κβ�ѯ�����Բ�ѯ����俪ʼʱ������Ѿ��ύ�����ݡ� ?????? ��ο�����������������ǰ���Ѿ�д���ˣ��ԣ���alter database dbname set read_comm.itted_snapshot on ���У���������һ����Ҫע��ʱ�����û����������ݿ⣬���������ʹ�����ݿ��������ͻ�������������������������with nowait ��rollback��������������ֹ�κ����ݿ����ӣ���ҿ��Բ���������顣 ?????? ����ǰ��д���뼶�������ʱ�ᵽ������뼶��������������ύ������һ������Ϊ������������һ��ʵ���������� ? ���ĵ�ǰ��ǰ���READ_COMMITTED_SNAPSHOTΪON ALTER DATABASE TESTCSDN SET READ_COMMITTED_SNAPSHOT ON GO Exec sp_us_lockinfo Go ? --test data and table ? create table ta(id int,col varchar(10)) insert ta select 1 ,'a' union all select 2,'b' union all select 3,'c' go ? ��ѯһ�� ? begin tran ? update ta set col = 'd' where id = 1 ? waitfor delay '00:00:05' �C�������ʱ������������Ƿ�Ӱ���ѯ�� exec sP_us_lockinfo �C�鿴��ǰ�����������ͼ����֪���ڱ������������� commit ? ? ? ��ѯ���� ? begin tran ? waitfor delay '00:00:01'��ȷ�������Ѿ����������� select * from ta where id = 1 -�C�а汾��������ύ������ /* id????????? col ----------- ---------- 1?????????? a (1 ����Ӱ��) */ waitfor delay '00:00:05'��-��֤��ѯһ�Ѿ��ύ���� select * from ta where id = 1 �C ��ѯ�������а汾���� /* id????????? col ----------- ---------- 1?????????? d (1 ����Ӱ��) */ commit ? �ع�һ�����Ϲ��̣����Ƿ���������ύ���պ����ύ������ʽһ������Ϊ��������������ģʽ�и�ǿ�IJ������� ����Ϊ��д���̼䲻����������������ע�û�У�����Ҫ��ÿһ���Ự��ʹ��SET������ѡ��Ϳ���ʹ��RCSI��Ҳ�������������Ӧ�ó������κ��ľͿ��Դ�ȱʡ��������ʽ�����ύ���л������շ�ʽ�����ύ�����Ӷ��������������IJ�����ͻ�� ? ? 12�����ո����µĶ�д��Ϊ ?????? SI��SQLSERVER2005�����һ���µĸ��룬Ҫ���ñ����������ط�ͬʱ���ã�1������Allow_SNAPSHOW_ISOLATION��2���ڻỰ��ʹ��SET TRANSACTION ISOLATION LEVEL����Ϊÿһ���Ự���ø��롣������ǰ��˵������һ���ֹ�ģʽ�ĸ��룬���������ύ�����ո��룬��������Щ��� ?????? ������� ALTER DATABASE DB_NAME SET ALLOW_SNAPSHOT_ISOLATION ON�� ?????? ������ʹ���������ʱ������л����ʱ��������RCSI��������������л����ʱ���ǻᱻ����������������к����ݵ�״̬����������ON״̬ �����Ǿ���һ��IN_TRANSITION_TO_ON��״̬����ʱ���ݿ�ڵȴ����ݿ������������������ʼΪ���º�ɾ�������汾���ݣ�һ����alter���ʼʱ�Ѿ����е�����һ���������ݿ�ͻ����ON״̬��ͬ������ΪOFFʱ���ݵĿ�״̬Ҳ�ᾭ��һ���м�״̬IN_TRANSITION_TO_OFF,�ȴ�������������һ�����еĻ����������ݿ�ͻ��ΪOFF״̬��������������ģ���������̣��رյĹ��̴���Լ�ģ��ɡ� ? ����ģ��Ĺ��̣� ��ѯһ����ʼһ������ס��Ҫ�ύ�ɻع� BEGIN TRAN ? UPDATE TA ??? SET COL = 'B' WHERE ID = 1 ? ? ��ѯ������������ ? ALTER DATABASE DBlock SET ALLOW_SNAPSHOT_ISOLATION on; ? /* ��ѯһֱ�����С��� */?? ? ��ѯ���� exec sp_us_lockinfo --��ҿ��Կ�����ǰ���ݴ����м�̬��IN_TRANSITION_TO_ON ? ��ѯ�ģ� --����ģ����ʱ����SI�������ݷ��ʣ���������ʲô��� SET TRANSACTION ISOLATION LEVEL SNAPSHOT ? BEGIN TRAN SELECT * FROM TA WHERE ID = 1 ?/* id????????? col ----------- ---------- ��Ϣ3956������16��״̬1����4 �� ���ո�������δ�������ݿ�'dblock' ����������Ϊ�������ô����ݿ�Ŀ��ո���� ?ALTER DATABASE ������δ��ɡ����ݿ�����ת��������ON ״̬��������ȴ��� ֱ��ALTER DATABASE ����ɹ���ɡ� ? */ ? ���ţ������ڲ�ѯһ�� ����һ�䣺COMMIT;Ȼ�����������в�ѯ���� ? ?????? �Ǻã�����ͨ������������Ѿ�ѧ��ʹ��������뼶��SI��֤��������һ���ԣ��κζ����������Եõ�����ʼʱ����Ѿ��ύ�����ݰ汾������������ģ��һ�²�ѯ�������ݣ� ? ��ѯһ�� ? SELECT * FROM TA /* id????????? col ----------- ---------- 1?????????? B ? (1 ����Ӱ��) */ BEGIN TRAN ? UPDATE TA ??? SET COL = 'C' WHERE ID = 1 ? WAITFOR DELAY '00:00:05' exec sp_us_lockinfo /* ? ? ?*/ COMMIT ? ��ѯ���� SET TRANSACTION ISOLATION LEVEL SNAPSHOT ? BEGIN TRAN SELECT * FROM TA WHERE ID = 1 /* id????????? col ----------- ---------- 1?????????? B ? (1 ����Ӱ��) */ waitfor delay '00:00:05' ? SELECT * FROM TA WHERE ID = 1 /* id????????? col ----------- ---------- 1?????????? B ? (1 ����Ӱ��) */ commit tran ? ? SELECT * FROM TA WHERE ID = 1 ? ? /* ?id????????? col ----------- ---------- 1?????????? C ? (1 ����Ӱ��) */ ? ?????? ���ǵ�����ǰ��˵��SI���г�ͻ����(����3960)��Ŷ�� ��������ģ��һ�£���Ҳ�������Ѵ��ʹ��SIģʽʱһ��ҪDZ�ڵ��������ÿ������ʵ���� ? ��ѯһ�� SET TRANSACTION ISOLATION LEVEL SNAPSHOT ? ? BEGIN TRAN SELECT * FROM TA where id = 1 ? WAITFOR DELAY '00:00:05' ? UPDATE TA ??? SET COL = 'c' WHERE ID = 1 ? ? ? /* ? ��Ϣ3960������16��״̬2����9 �� ���ո����������ڸ��³�ͻ����ֹ�����������ݿ�'dblock'��ʹ�ÿ��ո�����ֱ�� ���ӷ��ʱ�'dbo.TA'���Ա���¡�ɾ��������������������Ļ�ɾ�����С����� �Ը���������update/delete ���ĸ��뼶�� ? */ ? ��ѯ���� ? WAITFOR DELAY '00:00:02' ? BEGIN TRAN UPDATE TA ??? SET COL = 'd' WHERE ID = 1 commit tran ? ? SELECT * FROM TA WHERE ID = 1 ? ? /* ?id????????? col ----------- ---------- 1?????????? d ? (1 ����Ӱ��) */ ? ? 13��������ʾ(LOCK HINTS) ?????? ���뼶���ǻỰ����ģ��ڻỰ���ڶԳ����������� �������������ڲ���Ӱ�졣Ȼ������Ҫʱ����ʹ�ñ���������ʾ���ı�����Ĭ��������Ϊ����������һ��Ҫע�����ֲ���������Ӱ�첢�����ܡ� ?????? ����һ��Ҫ��סʹ��������ʾ�DZ�����ʾ����Ϊ����һ������From�Ӿ���ʹ��wthָ��������SQLSERVER2005�Ƽ�ʹ��With(Locktype),����with�������Ҫʹ�á� ? ����ö��һ��������ʾ�Ĺؼ���(����̫���ˣ���ֱ�Ӹ�������ǰ�ղص�)�� ? SELECT au_lname FROM authors WITH (NOLOCK) ? ������ʾ???????????????????????????????? ����? HOLDLOCK?????? ��������������������ɣ�����������Ӧ�ı����л�����ҳ������Ҫ ʱ�������ͷ���������ͬ��SERIALIZABLE��ֻ�����������ڱ����� NOLOCK???????? �����������������Ҳ�Ҫ�ṩ������������ѡ����Чʱ�����ܻ��ȡδ�ύ�������һ���ڶ�ȡ�м�ع���ҳ�档�п��ܷ����������Ӧ���� SELECT��䣬��Ȼ�൱��δ�ύ������??????? PAGLOCK??????? ��ͨ��ʹ�õ��������ĵط�����ҳ����??????? READCOMMITTED �����������ύ�����뼶���������ͬ��������ִ��ɨ�衣Ĭ����� �£�SQL Server 2000 �ڴ˸��뼶���ϲ�����??????? READPAST??????? ���������С���ѡ����������������������������У���Щ��ƽ�� ����ʾ�ڽ�����ڣ�������������������ʹ��ȴ����������ͷ����� Щ���ϵ�����READPAST����ʾ���������������ύ�����뼶����� ����ֻ���м���֮���ȡ����������SELECT��䡣??????? READUNCOMMITTED??????? ��ͬ��NOLOCK��??????? REPEATABLEREAD? ���������ڿ��ظ������뼶���������ͬ��������ִ��ɨ�衣??????? ROWLOCK????????? ʹ���м���������ʹ�����ȸ��ֵ�ҳ�����ͱ�������??????? SERIALIZABLE????? ���������ڿɴ��ж����뼶���������ͬ��������ִ��ɨ�衣 ��ͬ��HOLDLOCK��??????? TABLOCK?????? ʹ�ñ����������ȸ�ϸ���м�����ҳ��������������ǰ��SQL Server һֱ���и��������ǣ����ͬʱָ�� HOLDLOCK����ô���������֮ǰ��������һֱ���С�??????? TABLOCKX???? ʹ�ñ������������������Է�ֹ���������ȡ����±������������������ǰһֱ���С�����TABLOCKG��XLOCK���õ�Ч��һ���� UPDLOCK????? ��ȡ��ʱʹ�ø�����������ʹ�ù�������������һֱ��������������Ľ�����UPDLOCK���ŵ�����������ȡ���ݣ������������������Ժ�������ݣ�ͬʱȷ���Դ��ϴζ�ȡ���ݺ�����û�б����ġ�����ת�����͵�������Ҫ������ XLOCK???????? ��ʾSQLSERVER�����ʹ�õ�ȫ��������ʹ������������һֱ���ֵ� �������ʱ������ʹ�� PAGLOCK��TABLOCKָ����������������� �������������ʵ���������� ? ? 14��������ʱ ?????? SET LOCK_TIMEOUT n�� �Σ������������������ˣ�������д�ˡ� 15�������а汾�洢�� ? ??? ǰ��˵�˺ö���а�֪ʶ�����������ָ���ȼ��£�������ʲô�����أ���һ����������ϸ��˵˵�� ??? Ϊ�˸��õķ����а�ļ�¼�У���˵����ص�֪ʶ�㡣��������ص�֪ʶ������ѧϰ�а�����ɵ㡣 A�� ��β鿴����ҳ�棨DBCC PAGE��DBCC TRACEON �� ���ǿ���ͨ��DBCC���鿴����ҳ�����ݣ����������Կ������ݿ��е�ҳ�汨ͷ�������м���ƫ�Ʊ�����Ȼ�������ֻ��ϵͳ����Ա�ſ���ִ�У�����һ�������ԱҲ����ȥ��ҳ�����ݡ� ? DBCC PAGE�������ʽ���£� DBCC PAGE({dbid|dbname},filenum,pagenum[,printopt]) Dbid|dbname? ���ݿ�ID����� Filenum?????? ҳ����ļ��� Pagenum?????? ָ���ļ��ڵ�ҳ��� Printopt????? ���ѡ�0��Ĭ��ֵ�����屨ͷ��ҳ�汨ͷ ��������������������������1����ÿ��¼�зֱ�������弰ҳ�汨ͷ����ƫ��� ��������������������������2������Ļ��塢ҳ�汨ͷ����ƫ��� ��������������������������3�������ı�ͷ����ƫ������ɿ������еĸ���ֵ ? DBCC TRACEON��ʽ�� DBCC TRACEON(3604) �����ȴ���3604����DBCC PAGE�Ľ��������ͻ��ˡ� ? ����������һ��DBCC PAGE�Ľ��(��TAֻ������¼)�� ? PAGE: (1:89) BUFFER: BUF @0x02BFFDF0 bpage = 0x04938000?????????????????? bhash = 0x00000000?????????????????? bpageno = (1:89) bdbid = 8??????????????????????????? breferences = 0????????????????????? bUse1 = 23490 bstat = 0xc00009???????????????????? blog = 0x21432159??????????????????? bnext = 0x00000000 PAGE HEADER: Page @0x04938000 m_pageId = (1:89)??????????????????? m_headerVersion = 1????????????????? m_type = 1 m_typeFlagBits = 0x4???????????????? m_level = 0????????????????????????? m_flagBits = 0xa200 m_objId (AllocUnitId.idObj) = 86???? m_indexId (AllocUnitId.idInd) = 256? Metadata: AllocUnitId = 72057594043564032???????????????????????????????? Metadata: PartitionId = 72057594038583296??????????????????????? Metadata: IndexId = 0 Metadata: ObjectId = 21575115??????? m_prevPage = (0:0)?????????????????? m_nextPage = (0:0) pminlen = 18???????????????????????? m_slotCnt = 2??????????????????????? m_freeCnt = 8022 m_freeData = 166???????????????????? m_reservedCnt = 0??????????????????? m_lsn = (45:288:2) m_xactReserved = 0?????????????????? m_xdesId = (0:0)???????????????????? m_ghostRecCnt = 0 m_tornBits = -1441945315???????????? Allocation Status GAM (1:2) = ALLOCATED??????????????? SGAM (1:3) = ALLOCATED?????????????? PFS (1:1) = 0x61 MIXED_EXT ALLOCATED? 50_PCT_FULL???????????????????????? DIFF (1:6) = CHANGED ML (1:7) = NOT MIN_LOGGED??????????? DATA: Slot 0, Offset 0x60, Length 35, DumpStyle BYTE Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP VERSIONING_INFO Memory Dump @0x3432C060 00000000:?? 50001200 01000000 61616161 61616161 ?P.......aaaaaaaa???????? 00000010:?? 61610200 fc000000 00000000 000c0000 ?aa..............???????? 00000020:?? 000000???????????????????????????????...? --ɾ����һ����¼��Ϣ??????????????????? OFFSET TABLE: Row - Offset???????????????????????? 1 (0x1) - 131 (0x83)???????????????? 0 (0x0) - 96 (0x60)??? Buffer:��ǰҳ������ڴ�ʱ��ҪΪ�˱��ڹ����ڴ������ҳ�����ɵ�һ�ֽṹ�� Page Head:��ͷ��(���ֽ�������) m_pageId��ǰҳ����ļ��ż�ҳ��š� m_level��ǰҳ���������еļ����� AllocUnitId ���䵥ԪID�� PartitionId ����ID�� ObjectId���������ID�� IndexIdҳ�������ID�� m_prevPageǰһҳ��ָ�룬 m_nextPage��һҳ��ָ�롣 Pminlen �ж��������ֽ����� m_freeDataҳ���һ�������ֽ�ƫ������ m_slotCnt�ܼ�¼���� m_freeCnt ҳ������ֽ����� DATA����¼ÿһ���е���Ϣ�� ???????????????????? Slot 0 �к� Offset 0x60 ����ҳ���ƫ���� Length 35 ��¼����, Record Type ��¼���� Record Attributes �������� VERSIONING_INFO�а� ????????????? OFFSET TABLE����ƫ�ƾ������� ???????????????????? 1 (0x1) �C 131 (0x83)? 0 (0x0) �C 96 (0x60) B�� ����ҳ�� ����ҳ����ȻҲ��һ�ֽṹ�������а����˱����û����ݣ����̶�Ϊ8K��С(8192byte)��һ�����������͵�ҳ��(��������IN_ROW_DATA�����������ROW_OVERFLOW_DATA��������LOBҳ��LOB_DATA)����ÿһ��ҳ�����������ּ���(��ͷ�������У���ƫ�ƾ���)���������������ڸղ�����ı�������������֡� ҳ�汨ͷ����ռ��ҳ���ǰ96���ֽڣ���������ҳ��ֻ��8096���ֽ����������м���ƫ�ƴ洢������Ժ�������Сʱһ��Ҫע�⡣ 96���ֽں�������������������ݲ��֣���������������˵һ���е����Ϊ8060���ֽڡ������й̶��ı���˵��ÿһ��ҳ���ϴ洢�ļ�¼������һ���ģ�����䳤ʱҪ������������ݶ������Ӽ���IO��������������˵������Ҫ����ʹ��ҳ�����ɾ�����ļ�¼�� ��ƫ�ƾ�����2���ֽڵĿ飬�������ֽ�Ϊ��λ��ÿһ���о��������ֽڵĿ飬���������˼�¼��ҳ���ϵ���˳���������ע��һ�£��оۼ������ı���SQLSERVER��������ֵ���洢��������˼��ҳ���ϵ������洢Ҳһ���Ǽ�ֵ��˳��Ŷ��ʵ�������˳�����ɾ������˳������֤�ģ���������һ������ ����ҿ����� ? ? ? create table ta( id int primary key , col3 char(1)) insert into ta select? 1,'a' insert into ta select? 2,'a' insert into ta select? 3,'a' insert into ta select? 4,'a' insert into ta select? 5,'a' insert into ta select? 6,'a' insert into ta select? 11,'a' insert into ta select? 21,'a' insert into ta select? 31,'a' insert into ta select? 41,'a' insert into ta select? 51,'a' insert into ta select? 61,'a' insert into ta select 10 ,'b' ? go dbcc ind(testcsdn,'ta',-1) �C227 go dbcc traceon(3604) go dbcc page('testcsdn',1,227,1) go /* DATA: ? Slot 0, Offset 0x60, Length 12, DumpStyle BYTE Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP???? Memory Dump @0x443CC060 00000000:?? 10000900 01000000 610200fc ??????????........a...??????????? ������������--ʡ�����м���м�¼ ? 00000000:?? 10000900 06000000 610200fc ??????????........a...???????????? ? Slot 6, Offset 0xf0, Length 12, DumpStyle BYTE Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP???? Memory Dump @0x443CC0F0 00000000:?? 10000900 0a000000 620200fc ??????????........b...???????????? ? Slot 7, Offset 0xa8, Length 12, DumpStyle BYTE Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP???? Memory Dump @0x443CC0A8 00000000:?? 10000900 0b000000 610200fc ??????????........a...???????????? ������������--ʡ�� OFFSET TABLE: Row - Offset???????????????????????? 12 (0xc) - 228 (0xe4)??????????????? 11 (0xb) - 216 (0xd8)??????????????? 10 (0xa) - 204 (0xcc)??????????????? 9 (0x9) - 192 (0xc0)???????????????? 8 (0x8) - 180 (0xb4)???????????????? 7 (0x7) - 168 (0xa8)???????????????? 6 (0x6) - 240 (0xf0)???????????????? 5 (0x5) - 156 (0x9c)???????????????? 4 (0x4) - 144 (0x90)???????????????? 3 (0x3) - 132 (0x84)???????????????? 2 (0x2) - 120 (0x78)???????????????? 1 (0x1) - 108 (0x6c)???????????????? 0 (0x0) - 96 (0x60)? */???? ע�ⱨ���Ľ���ĺ�ɫ���֡� C�� �����нṹ �����ҳ��ṹ�������Ѿ����������еĽṹ��ֻ������û�ж��е����������ܣ��������һ���е����ݣ���������ϸ˵˵�еĽṹ�� insert into ta select 10 ,'b' ? Slot 6, Offset 0xf0, Length 12, DumpStyle BYTE Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP???? Memory Dump @0x443CC0F0 00000000:?? 10000900 0a000000 620200fc ??????????........b...? ���������ֻ���۹̶������е��нṹ���䳤�е��нṹ�����ۡ� ������˵�еij��ȣ����Ǽ���̶������ͻ������Ⱥ�ΪN���̶��е�����ΪM����ô���ȵĻ�����ʽΪ��N+ceiling(M/8)+6������ı��汨ͷ�ҿ��Կ��ó�������12�����������ʽ�����ԣ�5+ceiling( 2/8) + 6 = 12 . �ã��еĽṹ������ʲô���أ��������ǹ̶��г��� B״̬1 + B״̬2 + W��ƫ�� +��L���� + W���� + NULL״̬λ B������������������1�����ֽ� W������������������2�����ֽ� L�������������������䳤 NULL״̬λ��������Ceiling(W����/8) �Ǻã����Ǹ���������нṹ������һ��slot 6��¼����һ���ֽ�0x10 ,���ĸ�bitλ��1����ʾ����NULL״̬λ����5��Bitλ�DZ�ʾ���ޱ䳤�У�0��ʾ���ޱ䳤�У�����bitλ�������ˣ����ڶ����ֽ���״̬2,��δʹ�á����������ֽڶԵ�Ϊ0x0009��ʾ��λ�������Ƕ�������м�¼��ƫ������ô��9���أ����ã����ǿ������������Ǵӵ�5���ֽڿ�ʼ�ģ�һ�����Σ�4���ֽڣ���һ������Ϊ1���ַ���1���ֽڣ���5���ֽڣ�5��4������9���������Եõ��е�ǰ��ƫ��Ϊ9����10��11���ֽڶԵ�����0x0002��ʾ�������У���12���ֽڱ�ʾ��NULL״̬λ��������ú͵�һ���ֽڵĵ��ĸ�bitλ��Ӧ�ϣ�һ��Bit��ʾһ���е�NULL���ԣ�Ceiling(2��/8) = 1����ǰֵ��0xfc,��11111100��B����BITλ��ʾ�Ƿ�ΪNULL�Ӹߵ��͵�˳����ʾ��������ֻ���������ȫ��0����ʾ����Ϊ�գ�1������ǰ��Ӧ����ΪNULL���� ���������˵����ҿ����Լ����ԡ��� D�� ��εõ�ҳ���(pagenum) ����˵����ô��������һ���ؼ��Ķ���û˵��ʲô�أ��Ǿ�����εõ���ǰ����ҳ����أ��ã���������������Խ������ְ취�� 1�� DBCC IND() ? DBCC IND ['dbname'|dbid], -- ���ݿ�����ID Printopt��noclustered index_id [, --���ѡ�� Partition_num] �C-ָ�������ţ���Ҫ����2000 ) Printopt : --���ѡ����õģ� -- noclustered index_id? ������IAM�����ݼ�ָ�������ķ�ҳ��Ϣ?? -- -2?? ����IAMҳ�� -- -1?? ���е����ݡ�������IAM���������LOBҳ�� --? 0?? �������ݡ��������ݵ�IAMҳ�� --? 1?? �ۼ��������������ݡ�IAM��LOBҳ�� Partition_num�� --��Ҫ�Ǽ���2000��ȱʡ0Ϊ���з�������2005�����ǿ���ָ���ض��ķ����� ? ? 2��? ��system_internals_allocation_unitsȡ��first_page ? --------------------------------- --??????????? ��ѯ�����ļ��ż�ҳ��� -- Author : HappyFlyStone -- Date?? : 2009-11-19 13:23:02 -- Version: Microsoft SQL Server 2005 - 9.00.2047.00 (Intel X86) --????? Apr 14 2006 01:12:25 --????? Copyright (c) 1988-2005 Microsoft Corporation --????? Enterprise Edition on Windows NT 5.2 (Build 3790: Service Pack 2) --?? blog : http://blog.csdn.net/happyflystone?????????? --���������� ת��ע�������������Ϣ --------------------------------- ? ;WITH T1 AS ( ??? SELECT OBJECT_NAME(OBJECT_ID) AS NAME,TYPE_DESC,FIRST_PAGE ??? FROM SYS.SYSTEM_INTERNALS_ALLOCATION_UNITS U ??? JOIN SYS.PARTITIONS P ??? ON U.CONTAINER_ID = P.PARTITION_ID ??? WHERE [OBJECT_ID] = OBJECT_ID('TA') ) SELECT *,CAST( ?????????? CONVERT(INT,SUBSTRING(FIRST_PAGE,6,1)) * POWER(2,8) ???????? + CONVERT(INT,SUBSTRING(FIRST_PAGE,5,1)) ?????????? AS VARCHAR)+':'+CAST( ????????? (CONVERT(INT,SUBSTRING(FIRST_PAGE,4,1)) * POWER(2,24)) ???????? + (CONVERT(INT,SUBSTRING(FIRST_PAGE,3,1)) * POWER(2,16)) ???????? + (CONVERT(INT,SUBSTRING(FIRST_PAGE,2,1)) * POWER(2,8 )) ???????? + (CONVERT(INT,SUBSTRING(FIRST_PAGE,1,1))) AS VARCHAR) AS 'FILE:PAGE_NUM' ????????? FROM T1 ? /* name??? type_desc????? first_page???? File:page_num ----- --------------- -------------- ---------------- ta???? IN_ROW_DATA??? 0x590000000100???? 1:89 ? (1 ����Ӱ��) ? */ ? ?????? ��������CTE��ҿ��Է�װ�ɺ���������Ҫʱ���á� ? 3�� DBCC��IND���������������� ? ? PageFID �� ҳ����ļ��� 2.???????? LOB_DATA�� 3.?????? ROW_OVERFLOW_DATA �� PageType �C ҳ������ 2 - index page 3 and 4 - text pages 8 - GAM page 9 - SGAM page 10 - IAM page 11 - PFS page IndexLevel �C �����Ӧҳ�汨ͷ���ֵ�m_level��l��ǰҳ���������еļ��� 16�������а汾�洢���� ? ??? �ã�������������а����ݵĽṹ���������ȹ�ע�⼸����̬������ͼ(DWV)�� ? select * from sys.dm_tran_version_store select * from sys.dm_tran_current_transaction select * from sys.dm_tran_transactions_snapshot go ? sys.dm_tran_version_store ����һ������ʾ�汾�洢�������а汾��¼��������������м����ֶ�Ҫ�˽�һ�£� ���� dm_tran_current_transaction��ʾ��ǰ�Ự�е�����״̬��Ϣ�� ??? ������������һ�µ�ǰ�����״̬�� select name,snapshot_isolation_state_desc,is_read_committed_snapshot_on from sys.databases where name = 'dblock' /* name?????????????? snapshot_isolation_state_desc?????????? is_read_committed_snapshot_on ------------- -------------------------------?? ----------------------------- dblock????????????? OFF????????????????????????????????????????????????????????? 1 (1 ����Ӱ��) */ ? ? ??? �ðɣ����������������ݲ���ǰ�浫Ҫ�鿴ҳ����Ϣ�������ȿ���ҳ�����ݣ� ? drop table ta ? create table ta(id int,col char(10)) insert into ta select 1,'aaaaaaaaaa' insert into ta select 1,'bbbbbbbbbb' dbcc ind(dblock,'ta',-1) --73 dbcc traceon(3604) dbcc page('dblock',1,89,1) 00000000:?? 50001200 01000000 63636363 63636363 ?P.......cccccccc???????? 00000010:?? 63200200 fcc80000 00010000 00120000 ?c ..............???????? 00000020:?? 000000???????????????????????????????...????????????????????? ? Slot 1, Offset 0x83, Length 35, DumpStyle BYTE ? Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP VERSIONING_INFO ? Memory Dump @0x433BC083 ? 00000000:?? 50001200 01000000 63636363 63636363 ?P.......cccccccc???????? 00000010:?? 63200200 fcc80000 00010001 00120000 ?c ..............???????? 00000020:?? 000000???????????????????????????????...????????? --------------------------- Slot 0, Offset 0x60, Length 35, DumpStyle BYTE ? Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP VERSIONING_INFO ? Memory Dump @0x444CC060 ? 00000000:?? 50001200 01000000 64646464 64646464 ?P.......dddddddd???????? 00000010:?? 64640200 fcd00000 00010000 00130000 ?dd..............???????? 00000020:?? 000000???????????????????????????????...????????????????????? ? Slot 1, Offset 0x83, Length 35, DumpStyle BYTE ? Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP VERSIONING_INFO ? Memory Dump @0x444CC083 ? 00000000:?? 50001200 01000000 64646464 64646464 ?P.......dddddddd???????? 00000010:?? 64640200 fcd00000 00010001 00130000 ?dd..............???????? 00000020:?? 000000???????????????????????????????...????????????????????? ??????????? ? ����������ʾ������Ϣ�����ҽ����˰ɣ�ֱ������������ܵģ���Ϊ��ǰû�в����汾��Ϣ������������select����֤�� select * from sys.dm_tran_version_store select * from sys.dm_tran_current_transaction ����SQLû�з����κ���Ϣ��������¼�¼���ɰ汾��Ϣ�� ? update ta set col = 'ddddddddd' where id = 1 select * from sys.dm_tran_version_store select * from sys.dm_tran_current_transaction ? transaction_sequence_num version_sequence_num database_id rowset_id??????????? status min_length_in_bytes record_length_first_part_in_bytes record_image_first_part??????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????????? record_length_second_part_in_bytes record_image_second_part --------------------------------- 29???? 1? 8????? 72057594038714368??? 0????? 18???? 35 0x5000120001000000616161616161616161610200FC0000000000000000100000000000??????? 0??????? NULL ? (1 ����Ӱ��) ? transaction_id?????? transaction_sequence_num transaction_is_snapshot first_snapshot_sequence_num last_transaction_sequence_num first_useful_sequence_num -------------------- --------- -------- -----? -------------------?? 4872???? 18?????????? 0???????????? NULL??????????? 29??????????????? 21 ? (1 ����Ӱ��) �����ʱ�����ٲ鿴ԭ����TA���slot0��Ϣ�� ? Slot 0, Offset 0x60, Length 35, DumpStyle BYTE ? Record Type = PRIMARY_RECORD???????? Record Attributes =? NULL_BITMAP VERSIONING_INFO ? Memory Dump @0x445EC060 ? 00000000:?? 50001200 01000000 64646464 64646464 ?P.......dddddddd???????? 00000010:?? 64200200 fcc00000 00010001 001d0000 ?d ..............???????? 00000020:?? 000000???????????????????????????????...??? ??? ǰ��26���ֽڲ��ý����˰ɣ�����(c00000 00010001 001d0000 000000)14���ֽ���ʲô��˼�أ�����Ǽǵ�ǰ����ܹ�XSN���������14���ֽ�ָ����Ϣ�����ڸ����а汾��Ϣ�ġ�sys.dm_tran_current_transaction �����ص�first_useful_sequence_num�о����Ǵ�XSN�а汾��XSN�����£� ��һ���� 8bytes FILE_NUM:PAGE_ID:SLOT_ID ---------------------------- 1?????? : 192?? : 1 ÿһ���������һ���������������ӵ�XSNֵ ??? ��֤һ����tempdb�е����� (ע���ɫ����)�� ? dbcc page('tempdb',1,192,1) ? Slot 1, Offset 0xc8, Length 104, DumpStyle BYTE Record Type = INDEX_RECORD?????????? Record Attributes =? VARIABLE_COLUMNS Memory Dump @0x441FC0C8 ? 00000000:?? 26010068 0000851f 44f77f1b 01140000 ?&..h....D.......???? 00000010:?? 00000000 00010000 00000000 0008001f ?................???? 00000020:?? 44000005 a000000c 00000000 0112001f ?D...............???? 00000030:?? 441c5b1b 0180861f 441c0800 00000000 ?D.[.....D.......???? 00000040:?? 00000000 00500012 00010000 00616161 ?.....P.......aaa???? 00000050:?? 61616161 61616102 00fc0000 00000000 ?aaaaaaa.........???? 00000060:?? 00001000 00000000 ???????????????????........ ? 17���汾����С�Ĺ��� ?????? ���Ȱ汾���Ĵ�С��SQLSERVER���й����ģ�����һ�������߳��ڻ��ȷ���汾������ʱЧ������SIģʽ��˵�汾�������������������RCSIģʽ��˵��Select�����߳̾ͻ��Ƴ��汾���ݡ� ?????? �����̻߳�����Է��Ӽƣ�������һ�����⣬�Ǿ����������δ����tempdbû�п��ÿռ�ʱ�������߳̾ͻ���ǰ���á��ڼ��˵��������������Ѿ������汾�������ɣ���ѯ��ʧ�ܣ�����ʹ�ð汾���Ƶ�һ��ע����� ?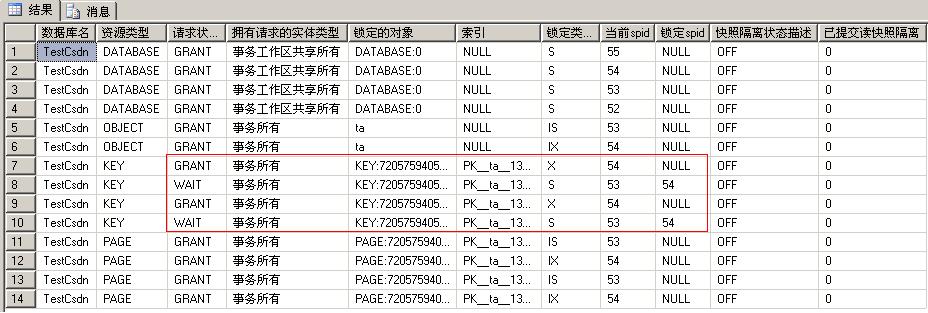
���ʱ��������ǻ�ͷ����ѯһ��ִ��commit tran ����ᷢ�ֲ�ѯ����õ�����������Dz�ѯһ�ĺ�Ľ������������rollback ,��ô�������ԭ����ֵ���䣬��������Լ��ٲ��ԡ�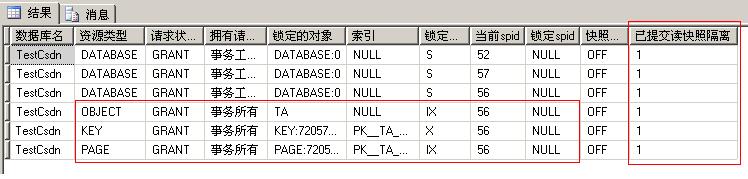

?

??? ÿ�����������������Դ�����С�ҳ���������ͬ���͵�������������ֹ����������ij�ֿ��ܻᵼ�����������������ķ�ʽ����Դ����������������������Դʱ�������ͷ�����
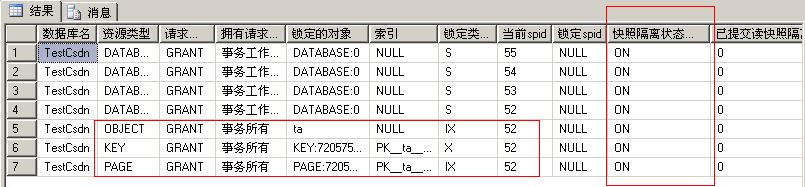
??? �������˻����а汾���Ƶĸ��뼶��ʱ�����ݿ����� ��ά���ĵ�ÿһ�еİ汾��Ӧ�ó������ָ������ʹ���а汾�鿴������ѯ��ʼʱ���ڵ����ݣ�������ʹ�����������ж�ȡ��ͨ��ʹ���а汾���ƣ���ȡ������ֹ��������Ŀ����Խ���͡�
��������
?
��������TA���ϼ�Where������һ�����¶�����Ȼ��ͨ������ǰд��һ�����ߣ�sp_us_lockinfo�鿴������Ϣ����ʵ�ҵ�updateֻ��Ӱ��һ���м�¼���������Ƿ��������������ڣ�ֻҪ��ǰ�������������������������벻����ҳ����������DZ���������һ���������ڵı���ҳ��������ͻ��������������������������ǰ��ĸ���ȼ���ʵ����Ҳ�����ӣ���ᷢ����������״̬��WAIT ������GRANT��
��ʹ�ÿ����л�������뼶��ʱ������ Transact-SQL ����ȡ�ļ�¼��������Χ������������ȡ������ֹһ�г����ڰ���������ֵ���뷶Χ����ɾ�ĵ������У�������ʽ�����ü�¼���а������з�Χ������Χ���ɷ�ֹ�ö���ͨ��������֮����ķ�Χ��������ֹ��������ʵļ�¼�����л�������ɾ����

 ?
?


?
?????? �ã���ĿǰΪֹ�Կ���������Դ��˵���ˡ��ٺ٣����⼸������ѻ�B����������(HBT)�����Ժ���������ʱ�پ��������ˡ�
?????? ͨ�����ͼ����Ӧ�ÿ���rsc_bin���������ֽں�2000�²�һ���ˣ��������ֽڽ����������Դ������ͣ���һ����Ҫע��Ŷ��
��������ͼ���Ǻ�������������Ϊobjec��page��rsc_bin���塣�ص�˵һ��KEY���͵Ĺ�����������һ����¼��syslockinfo��rsc_bin�У�ǰ6���ֽ��Ƿ���ID�����ǿ���ͨ��sys.partitions���ҵ���Ӧ�ķ����������ŵ�6���ֽڣ���ͼ�ú���߱�ʶ�IJ��֣���ͷ��С���Ǹ��ݵ�ǰ�������������������ɵ��н������ϣֵ��������������ϣ��ֵ�������Ƶġ��������ı���ҳ�����ǿ��Բ��ҵ���Ӧ�Ľṹ�Ļ����Ǹ��������ֵ������ľ��Dz��Dz���֪���ṹ��������IJ�֪��ʲô�ṹ�˹������������֤��������Ľ��۰ɡ���ʵ���Dz��õ��ģ���Ϊ��Ȼ���ܷ��ƣ��������������������ǻ��ǿ��Բ���ƥ���ѽ��Ҳ���������ͬʱ���ɵĹ�ϣһ��������SQLSERVER��֪��������ͬ����Դ�������������Ѿ��������ٺ٣���ʵֻҪ���ı���������Դ�ı�ʶ�������Թ���������������





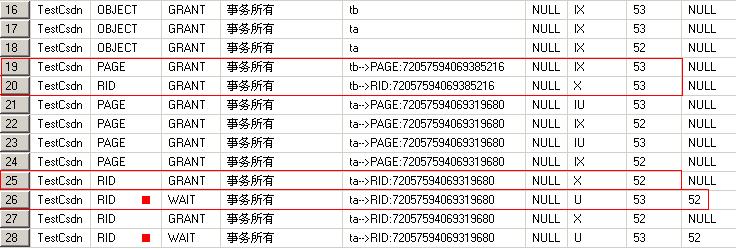

ͼconversion2��




?
(��
����tbname, -- ����
PagePID �� ҳ���
IAMFID? �� IAM�����ļ��ţ������IAMҳ�����Ϊ��
IAMPID? �� ��Ӧ��IAMҳ��ţ�����IAMΪNULL
ObjectID ����ҳ����������ID
IndexID �C ������ID��
PartitionNumber �C ������
PartitionID �C ����ID
iam_chain_type �C 2005�����¼������ͣ�
1.???????? IN_ROW_DATA ��
1 - data page
?
?˵��
?
transaction_sequence_num
?���ɸü�¼�汾����������к�
?
version_sequence_num
?�汾��¼���кš���ֵ����������İ汾����Ψһ�ġ�
?
status
?ָʾ�а汾���Ƶļ�¼�Ƿ��Ѳ��Ϊ������¼�������ֵΪ 0�����¼�洢��һҳ�С������ֵΪ 1�����¼���Ϊ������¼���Ҵ洢��������ͬҳ�ϡ�
?
min_length_in_bytes
?��¼����С���ȣ��ֽڣ���
?
record_image_first_part
?�汾��¼�ĵ�һ���ֵĶ�����ͼ��
?
record_image_second_part
?�汾��¼�ĵڶ����ֵĶ�����ͼ��
?
?�ڶ����� 6bytes
?
c00000 00010001 00
?1d0000 000000
?
��tempdb�е��ļ��š�ҳ��š�slot��
?��¼�汾����������к�
?
exec sp_us_FPSinfo 0xc000000001000100
?1d �� 29
?
��ϸ�������
SQL2005�����������
�ȶȣ�115 ����ʱ�䣺2016-05-05 14:54:53.0
������http://blog.csdn.net/happyflystone
��ؽ������
- С���ҵ�<����֪ʶ����ϵͳ>����������,���ṩԴ������(C#ASP.NET 2.0,SQL2005)
- log4net sql2005,������
- ������װ��VS2005+SQL2005�������밲װVS2008����װʱ��ʾ�ˣ�ϵͳ�Ѱ�װMicrosoft Windows Installer 3.1�������Ӱ����
- ����CommandNotification + Sql2005 ����֪ͨ�Ļ���ʧЧ���й�����
- ��λʦ�� С������ С�����õ���SQL2000ȴ���� SQL2005 40 �쳣 ���������ν����������
- SQL2005 ȥ�����"dbo."
- SQL2005 Reporting Service����ʱ����ʾ"Reporting Service"��¼���Ի����������е��û�С���Һ����붼����[��]
- ����ֽ��һ���������ݿ�汾���й����� SQL2005 To SQL2000
- sql2005 ����ѡ����û���뵼������
- sql2005 ����ά���ƻ�����ʧ��,����ô���
- sql2005+iis+asp���˼·
- ����sql2005 ������䣡����ô���
- jsp+sql2005 �������ݿ�ʱ�������룬ʹ���˹���������utf-8����
- eclipse��sql2005��tomcat��д��½ҳ�棬ִ�к�һ���쳣
- spring+hibernate+struts +SQL2005 ���ݿ�Ƶ���������ܽ������100�ֽ������
- sql2005 java ���������
- SQL2005 ͬʱ���¶���SUM,��ʾ�ؼ��� 'FROM' ��������쳣
- sql2005 װ��
- sql2005 ���ݿⲻ���� log�ļ�һֱ��2M
- sql2005 �����û�ͬһʱ���ͬһ�ű���չ���������ѽ
- SQL2005 ��ѯ���,11�����й���,��ѯʱ��4��,С�������������֪�������ĸ���ռ�����ʱ��
- Sql2005 ��������е�˯��״̬�������й�����
- sql2005 ��ȡcsv�ļ���ʧ���ݵ��й�����
- sql2005 ���� չʾ��Ŀ¼����Ч��
- sql2005 ���Ƽ����� δ��ʼ���Ķ��Ľ������
- sql2005 win7 64λ װ��һֱ���ɹ�
- sql2005 ������ʱ���������ֶν������
- SQL2005 �����ӵ��������������
- ��1sql��� ��sql2005��
- sql2005 ����sql2008�������