��дSQL�dz���Ա�Ļ�����������д�����������SQL���������Ա�ıر����ܡ�
����Щ���ܺõ�SQL�������ôд�����ģ��ѵ������˽����ݿ�ײ�Ķ�����
��ʵ�˽����ݿ�ԭ����һ���棬����ݵ��ǽ�����ִ�мƻ�����Explain Plan��������SQL���ִ�еIJ��輰���̡���ͬ�����ݿ⣬ʹ��ִ�мƻ��ķ�ʽ��Щ��ͬ����ƪ��MySql���ݿ�Ϊ����
Explain�
EXPLAIN SELECT �������壺1. EXPLAIN EXTENDED SELECT ������ִ�мƻ��������롱��SELECT��䣬����SHOW WARNINGS �ɵõ���MySQL�Ż����Ż���IJ�ѯ��� 2. EXPLAIN PARTITIONS SELECT �������ڷ�������EXPLAIN
ִ�мƻ���������Ϣ

id
����һ�����֣���ʾ��ѯ��ִ��select�Ӿ���������˳��

id��ͬ��ִ��˳����������

������Ӳ�ѯ��id����Ż������id值Խ�����ȼ�Խ�ߣ�Խ�ȱ�ִ��
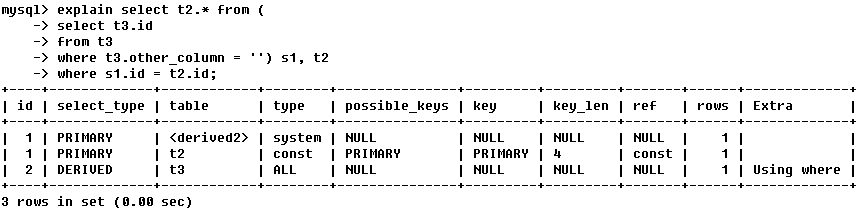
id�����ͬ��������Ϊ��һ�飬��������˳��ִ�У����������У�id值Խ�����ȼ�Խ�ߣ�Խ��ִ��
select_type
��ʾ��ѯ��ÿ��select�Ӿ�����ͣ��� OR���ӣ�
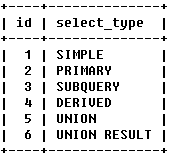
a.SIMPLE����ѯ�в������Ӳ�ѯ����UNION
b.��ѯ���������κθ��ӵ��Ӳ��֣�������ѯ���Ϊ��PRIMARY
c.��SELECT��WHERE�б��а������Ӳ�ѯ�����Ӳ�ѯ�����Ϊ��SUBQUERY
d.��FROM�б��а������Ӳ�ѯ�����Ϊ��DERIVED��������
e.���ڶ���SELECT������UNION֮�����ΪUNION����UNION������ FROM�Ӿ���Ӳ�ѯ�У����SELECT�������Ϊ��DERIVED
f.��UNION����ȡ�����SELECT�����Ϊ��UNION RESULT
type
��ʾMySQL�ڱ����ҵ������еķ�ʽ���ֳơ��������͡��������������£�
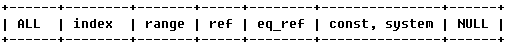
�������ң��������
a.ALL��Full Table Scan�� MySQL������ȫ�����ҵ�ƥ�����

b.index��Full Index Scan��index��ALL����Ϊindex����ֻ����������

c.range��������Χɨ�裬��������ɨ�迪ʼ��ijһ�㣬����ƥ��值����У�������between��<��>�ȵIJ�ѯ


range�������͵IJ�ͬ��ʽ�������������ܲ���

d.ref����Ψһ������ɨ�裬����ƥ��ij������值�������С�������ʹ�÷�Ψһ������Ψһ�����ķ�Ψһǰ���еIJ���


e.eq_ref��Ψһ������ɨ�裬����ÿ��������������ֻ��һ����¼��֮ƥ�䡣������������Ψһ����ɨ��

f.const��system����MySQL�Բ�ѯij���ֽ����Ż�����ת��Ϊһ������ʱ��ʹ����Щ���ͷ��ʡ��罫��������where�б��У�MySQL���ܽ��ò�ѯת��Ϊһ������

system��const���͵�����������ѯ�ı�ֻ��һ�е�����£� ʹ��system
g.NULL��MySQL���Ż������зֽ���䣬ִ��ʱ�������÷��ʱ�������

possible_keys
ָ��MySQL��ʹ���ĸ������ڱ����ҵ��У���ѯ�漰�����ֶ���������������������������г�������һ������ѯʹ��
key
��ʾMySQL�ڲ�ѯ��ʵ��ʹ�õ���������û��ʹ����������ʾΪNULL
TIPS����ѯ����ʹ���˸������������������������key�б���

key_len
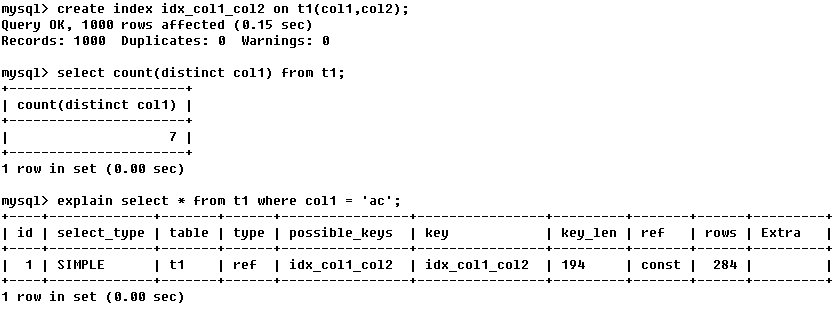
��ʾ������ʹ�õ��ֽ�������ͨ�����м����ѯ��ʹ�õ������ij���


key_len��ʾ��值Ϊ�����ֶε������ܳ��ȣ�����ʵ��ʹ�ó��ȣ���key_len�Ǹ��ݱ����������ã�����ͨ�����ڼ�������
ref
��ʾ������������ƥ������������Щ�л��������ڲ����������ϵ�值

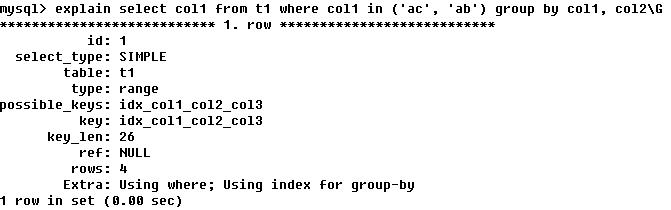
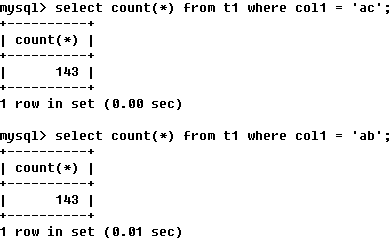
�����У���key_len��֪t1����idx_col1_col2�����ʹ�ã�col1ƥ��t2����col1��col2ƥ����һ���������� ��ac��
rows
��ʾMySQL���ݱ�ͳ����Ϣ������ѡ�������������ҵ�����ļ�¼����Ҫ��ȡ������

Extra
�������ʺ�������������ʾ��ʮ����Ҫ�Ķ�����Ϣ
a.Using index
��值��ʾ��Ӧ��select������ʹ���˸���������Covering Index��

TIPS������������Covering Index��
MySQL����������������select�б��е��ֶΣ������ظ��������ٴζ�ȡ�����ļ�
�������������ѯ��Ҫ�����ݵ�������Ϊ ����������Covering Index��
ע�⣺
���Ҫʹ�ø���������һ��Ҫע��select�б���ֻȡ����Ҫ���У�����select *����Ϊ����������ֶ�һ���������ᵼ�������ļ�����ѯ�����½�
b.Using where
��ʾMySQL�������ڴ洢�����ܵ���¼����С�����ˡ���Post-filter��,
�����ѯδ��ʹ��������Using where������ֻ����������MySQL����where�Ӿ������˽����

c.Using temporary
��ʾMySQL��Ҫʹ����ʱ�����洢�����������������ͷ����ѯ

d.Using filesort
MySQL��������������ɵ����������Ϊ���ļ�����



MySQLִ�мƻ��ľ���
?EXPLAIN�����������ڴ��������洢���̵���Ϣ���û��Զ��庯���Բ�ѯ��Ӱ�����
?EXPLAIN�����Ǹ���Cache
?EXPLAIN������ʾMySQL��ִ�в�ѯʱ�������Ż�����
?����ͳ����Ϣ�ǹ���ģ����Ǿ�ȷ值
?EXPALINֻ�ܽ���SELECT��������������Ҫ��дΪSELECT��鿴ִ�мƻ�