д��ǰ��һ��
�����ܽ����HBase��SQL��ѯϵͳ����Salesforce phoenix

д��ǰ�����
����˵����

һ��ʲô��Phoenix
ժ�Թ�����

Phoenix��һ���ṩhbase��sql�����Ŀ�ܣ�Phoenix�ǹ�����HBase֮�ϵ�һ��SQL�м�㡣Phoenix��ȫʹ��Java��д������λ��GitHub�ϣ������ṩ��һ���ͻ��˿�Ƕ���JDBC���������ڼĵ��ӳٲ�ѯ������������Ϊ���룻���ڰ����������˵������������Ϊ�롣Phoenix��������HBase����
����map-reduce job�ģ�����ͨ������������������HBase���ݵġ�
Phoenix��值�ù�ע�����ԣ�
1��Ƕ��ʽ��JDBC������ʵ���˴ֵ�java.sql�ӿڣ�����Ԫ����API
2������ͨ���ಿ�м����Ǽ�/值��Ԫ���н��н�ģ
3�����ƵIJ�ѯ֧�֣�����ʹ�ö��ν���Լ��Ż���ɨ���
4��DDL֧�֣�ͨ��CREATE TABLE��DROP TABLE��ALTER TABLE������/ɾ����
5���汾����ģʽ�ֿ⣺��д������ʱ�����ղ�ѯ��ʹ��ǡ����ģʽ
6��DML֧�֣��������в����UPSERT VALUES��������ͬ��ͬ��֮��������ݴ����UPSERT SELECT������ɾ���е�DELETE
7��ͨ���ͻ��˵�������ʵ�ֵ���������֧��
8������������û�����ӣ�ͬʱ��������Ҳ�ڿ�������
9������ANSI SQL��
����Phoenixԭ��
Phoenix����ԭ���ǽ�һ������HBase client��˵�Ƚϸ��ӵIJ�ѯת����һϵ��Region Scan�����coprocessor��custom filter�ڶ�̨Region Server�Ͻ��в��в�ѯ�����ܸ���Scan��������ּ��������PhoenixӦ�ò��Ǹ��Ż���OLAPϵͳ��������һ�����ڼ�����ѯ�����ˣ���������OLTPϵͳ�� Phoenix ����Ϊ����Ŀǰ������ƽ̨�ṩ�Ƚϱ�ݵ����ݲ���������ֱ����jdbc��ʽ�������ܱȽϲ�����ע�ⲻҪʹ�ö����ѯ���� ��
����Phoenix��װ����
1������
phoenix-3.0.0-incubating.tar.gz
http://phoenix.incubator.apache.org/download.html#Installation
2������phoenix-3.0.0-incubating/common/phoenix-core-3.0.0-incubating.jar��$HBASE_HOME/lib/��
3������HBase��Ⱥ
��ͨ���ͻ��˷���phoenix����������²�����
��phoenix-3.0.0-incubating/hadoop-1/phoenix-3.0.0-incubating-client.jar���ӵ�Phoenix�ͻ��˵���·����
�ġ�����Phoenix
4.1��ͨ��������
����phoenix
cd /home/yujianxin/hbase/phoenix/phoenix-3.0.0-incubating/bin
./sqlline.py slave3:2181
����������Ӧ��˵����װ�ɹ�

4.2��ͨ��Java
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver"); // connection string: jdbc:phoenix [ :<zookeeper quorum> [ :<port number> ] [ :<root node> ] ]Connection connection = DriverManager.getConnection("jdbc:phoenix:slave3:2181");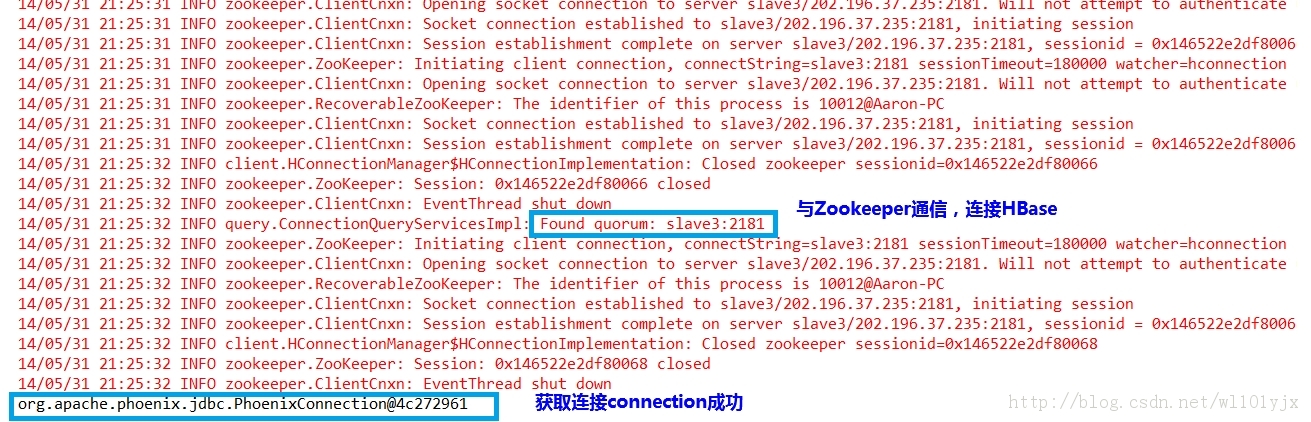
4.3��ͨ��SQL�ͻ���SQuirrel����
���ص�ַ��http://squirrel-sql.sourceforge.net/
�ٽ��а�װ���ü��ɡ�
�塢ʹ��Phoenix
ʹ��phoenix-3.0.0-incubating.tar.gz�Դ������ݽ��в���

���У�WEB_STAT.sql���������£�

ִ����������鿴phoenix�еı���
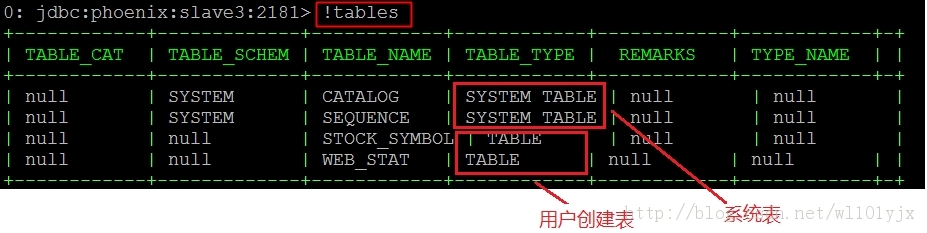
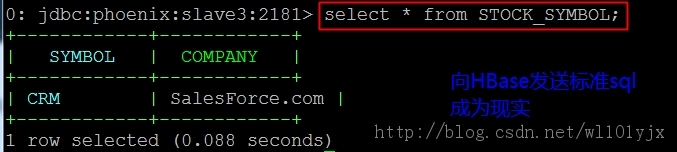
�鿴HBase�еı������£�

����ͨ��Phoenix���������HBase֮�ϵ�SQL�м�㣬��HBase���ͱ�sql��䣬��HBase���в�����