�Լ�ʵ��һ��SQL��������
���ܣ����û������SQL�������ת��Ϊһ����ִ�еIJ������У������ز�ѯ�Ľ������
SQL�Ľ������������ѯ�������ѯ�Ż��Ͳ�ѯ�����У���Ҫ����3�����裺
- ��ѯ������
- �ƶ�����ѯ�ƻ����Ż���أ�
- �ƶ�������ѯ�ƻ����Ż���أ�
- ��ѯ������ ��SQL����ʾ��ij�����õ����.
- �ƶ�����ѯ�ƻ��� �����ת����һ����ϵ��������ʽ������似�Ľṹ������ṹͨ���������ƻ���
- �ƶ�������ѯ�ƻ��������ƻ�ת����������ѯ�ƻ���Ҫ��ָ������ִ�е�˳��ÿһ��ʹ�õ��㷨������֮��Ĵ��ݷ�ʽ�ȡ�
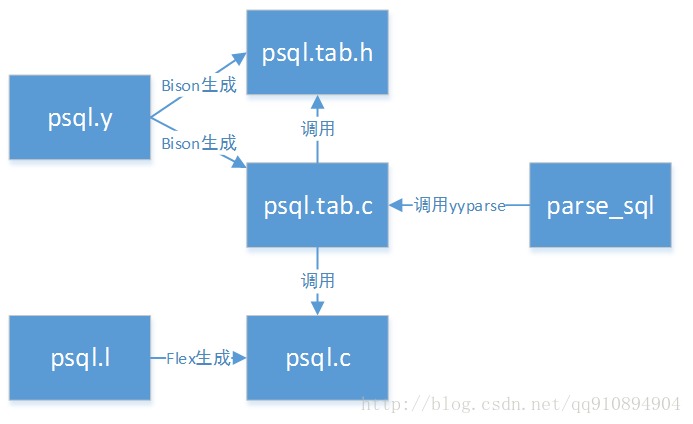
��ѯ������ģ����Ҫ������ĵ��ù�ϵ:
ͼ1.SQL�����ģ��ĵ��ù�ϵ
FLEX���
flex��һ���ʷ��������ߣ�������Ϊ��Ϊ.l���ļ�,���Ϊ.c���ļ�. ʾ����һ����似Unix�ĵ���ͳ�Ƴ���wc��
%option noyywrap%{ int chars = 0; int words = 0; int lines = 0;%}%%[_a-zA-Z][_a-zA-Z0-9]+ { words++; chars += strlen(yytext); }\n { chars++ ; lines++; }. { chars++; }%%int main(){ yylex(); printf("%8d %8d %8d\n",lines,words,chars); return 0;}.l�ļ�ͨ����Ϊ3���֣�
%{ definition%}%% rules%% codedefinition����Ϊ���岿�֣���������ͷ�ļ�����������������������ע�͵ȣ��ⲿ�ֻᱻԭ�������������.c�ļ��С�rules���ֶ���ʷ�����ʹ���������ʽ����ʷ������������������ɨ�赽��Ӧ�ʷ�ʱ�Ķ������롣code����ΪC���ԵĴ��롣yylexΪflex�ĺ�����ʹ��yylex��ʼɨ�衣%option ָ��flexɨ��ʱ��һЩ���ԡ�yywrapͨ���ڶ��ļ�ɨ��ʱ����ʹ�á����õ�һЩѡ����noyywrap ��ʹ��yywrap����yylineno ʹ���к�case-insensitive �������ʽ�����Сд��
flex�ļ��ı���
flex �Co wc.c wc.l cc wc.c �Co wcBison���
Bison��Ϊһ���������������Ϊһ��.y���ļ�,���Ϊһ��.h�ļ���һ��.c�ļ���ͨ��Bison��Ҫʹ��Flex��ΪЭͬ�Ĵʷ�����������ȡ�Ǻ�����Flexʶ���������ʽ����ȡ�Ǻţ�Bison�������Щ�ǺŻ�����������������
��������ʾ����calc.y
%{#include <stdio.h>%}%token NUMBER%token ADD SUB MUL DIV ABS%token OP CP%token EOL%%calclist: | calclist exp EOL {printf("=%d \n> ",$2);} | calclist EOL {printf("> ");} ;exp: factor | exp ADD factor {$$ = $1 + $3;} | exp SUB factor {$$ = $1 - $3;} ;factor:term | factor MUL term {$$ = $1 * $3;} | factor DIV term {$$ = $1 / $3;} ;term:NUMBER | ABS term ABS { $$ = ($2 >= 0 ? $2 : -$2);} | OP exp CP { $$ = $2;} ;%%int main(int argc,char *argv[]){ printf("> "); yyparse(); return 0;}void yyerror(char *s){ fprintf(stderr,"error:%s:\n",s);}Flex��Bison�����Ǻţ�值ͨ��yylval��Flex��Bison�䴫�ݡ���Ӧ��.l�ļ�Ϊ%option noyywrap%{#include "fb1-5.tab.h"#include <string.h>%}%%"+" { return ADD;}"-" { return SUB;}"*" { return MUL;}"/" { return DIV;}"|" { return ABS;}"(" { return OP;}")" { return CP;}[0-9]+ { yylval = atoi(yytext); return NUMBER; }\n { return EOL; }"//".*[ \t] {}"q" {exit(0);}. { yyerror("invalid char: %c\n;",*yytext); }%%Bision�ļ�����
bison -d cacl.y flex cacl.l cc -o cacl cacl.tab.c lex.yy.cͨ����BisonĬ���Dz�������ģ����ϣ����yyparse����������������������Բ������ַ�ʽ��һ��������һ��ȫ�ֱ�������һ����������һ���������������ParseResult�������û��Լ�����Ľṹ�塣%parse-param {ParseResult *result}
�ڹ�������п������øò�����
stmt_list: stmt ';' { $$ = $1; result->result_tree = $$; }| stmt_list stmt ';' { $$ = (($2 != NULL)? $2 : $1); result->result_tree = $$;}����yyparseʱ��Ϊ�� ParseResult p;yyparse(&p);
SQL���������е����ݽṹ
����ṹ
��ʵ�ֵ�ʱ�������������ƻ������������ṹ���б��ṹ���������ƻ�����������ʽ�ṹ�����ṹҪע������Ҷ�ӽڵ㣨Ҳ����ֹ���ڵ㣩�ͷ�Ҷ�ӽڵ㣨����ֹ���ڵ㣩��ͬʱҶ�ӽڵ�ͷ�Ҷ�ӽڵ㶼�����ж������͡�
����Ľڵ㣺�����������֣��ڵ�����͵�ö��值kind����ʾ�ڵ�值��������u���������а����˸����ڵ�������ֶΡ�
typedef struct node{ NODEKIND kind; union{ //... /* query node */ struct{ int distinct_opt; struct node *limit; struct node *select_list; struct node *tbl_list; struct node *where_clause; struct node *group_clause; struct node *having_clause; struct node *order_clause; } SELECT; /* delete node */ struct{ struct node *limit; struct node *table; struct node *where_clause; struct node *group_clause; } DELETE;/* relation node */ struct{ char * db_name; char * tbl_name; char * alias_name; } TABLE; //�����ṹ�� }u;}NODE ;NODEKINDö�������п��ܳ��ֵĽڵ�����.�䶨��Ϊ
typedef enum NODEKIND{ N_MIN, /* const node*/ N_INT, //int or long N_FLOAT, //float N_STRING, //string N_BOOL, //true or false or unknown N_NULL, //null /* var node*/ N_COLUMN, // colunm name //�������� /*stmt node*/ N_SELECT, N_INSERT, N_REPLACE, N_DELETE, N_UPDATE, //�������� N_MAX} NODEKIND;������У���������Ҷ�ӽڵ�Ϊ���֣��ַ��������Եȣ�����Ϊ�ڲ��ڵ㡣�����Щ���ݿ��ʵ���н�����Ľڵ㶨��Ϊ���µ�ParseNode�ṹ��
typedef struct _ParseNode{ ObItemType type_;//�ڵ�����ͣ���T_STRING,T_SELECT�� /* ��ֹ���ڵ㣬����ʵ�ʵ�值 */ int64_t value_; const char* str_value_; /* ����ֹ���ڵ㣬ӵ�ж������ */ int32_t num_child_;//�ӽڵ�ĸ��� struct _ParseNode** children_;//�ӽڵ�ָ����} ParseNode;���ƻ��ṹ
���ƻ����ڲ��ڵ������ӣ�Ҷ�ӽڵ��ǹ�ϵ.
typedef struct plannode{ PLANNODEKIND kind; union{ /*stmt node*/ struct { struct plannode *plan; }SELECT; /*op node*/ struct { struct plannode *rel; struct plannode *filters; //list of filter }SCAN; struct { struct plannode *rel; NODE *expr_filter; //list of compare expr }FILTER; struct { struct plannode *rel; NODE *select_list; }PROJECTION; struct { struct plannode *left; struct plannode *right; }JOIN; /*leaf node*/ struct { NODE *table; }FILESCAN; //�������ͽڵ� }u;}PLANNODE;���ƻ��ڵ������PLANNODEKIND��ö��值���£�
typedef enum PLANNODEKIND{ /*stmt node tags*/ PLAN_SELECT, PLAN_INSERT, PLAN_DELETE, PLAN_UPDATE, PLAN_REPLACE, /*op node tags*/ PLAN_FILESCAN, /* Relation ��ϵ��Ҷ�ӽڵ� */ PLAN_SCAN, PLAN_FILTER, /* Selection ѡ�� */ PLAN_PROJ, /* Projection ͶӰ*/ PLAN_JOIN, /* Join ���� ��ָ��值����*/ PLAN_DIST, /* Duplicate elimination( Distinct) �����ظ�*/ PLAN_GROUP, /* Grouping ����(�����˾ۼ�)*/ PLAN_SORT, /* Sorting ����*/ PLAN_LIMIT, /*support node tags*/ PLAN_LIST }PLANNODEKIND;�����ƻ��ṹ
�������ƻ��й�ϵɨ�������ΪҶ�ӽڵ㣬���������Ϊ�ڲ��ڵ㡣ӵ��3������������open,close,get_next_row���䶨�����£�
typedef int (*IntFun)(PhyOperator *);typedef int (*RowFun)(Row &row,PhyOperator *);struct phyoperator{ PHYOPNODEKIND kind; IntFun open; IntFun close; RowFun get_next_row;//�������� union{ struct { struct phyoperator *inner; struct phyoperator *outter; Row one_row; }NESTLOOPJOIN; struct { struct phyoperator *inner; struct phyoperator *outter; }HASHJOIN; struct { struct phyoperator *inner; }TABLESCAN; struct { struct phyoperator *inner; NODE * expr_filters; }INDEXSCAN; //�������͵Ľڵ� }u;}PhyOperator;������ѯ�ƻ��Ľڵ�����PHYOPNODEKINDö�����£�
typedef enum PHYOPNODEKIND{ /*stmt node tags*/ PHY_SELECT, PHY_INSERT, PHY_DELETE, PHY_UPDATE, PHY_REPLACE, /*phyoperator node tags*/ PHY_TABLESCAN, PHY_INDEXSCAN, PHY_FILESCAN, PHY_NESTLOOPJOIN, PHY_HASHJOIN, PHY_FILTER, PHY_SORT, PHY_DIST, PHY_GROUP, PHY_PROJECTION, PHY_LIMIT}PHYOPNODEKIND;�ڵ��ڴ��
���Կ��������������ƻ�����������ѯ��������ָ��Ϊ���Ľṹ�壬���ÿ�ζ���̬������Ļ�����ȽϺ�ʱ����Ҫʹ���ڴ�صķ�ʽ��һ�����������ڵ��ڴ棬���Ժ���á�������һ�ּķ�ʽ��ÿ�δ����ڵ�ʱ��ʹ��newnode�������ɡ��������ʱ���ͷ��ڴ�ؼ��ɡ�
static NODE *nodepool = NULL;static int MAXNODE = 256;static int nodeptr = 0;NODE *newnode(NODEKIND kind){ //�״�ʹ��ʱ����MAXNODE���ڵ� if(nodepool == NULL){ nodepool = (NODE *)malloc(sizeof(NODE)*MAXNODE); assert(nodepool); } assert(nodeptr <= MAXNODE); //���ڵ��������MAXNODEʱrealloc��չΪԭ���������ڵ� if (nodeptr == MAXNODE){ MAXNODE *= 2; NODE *newpool = (NODE *)realloc(nodepool,sizeof(NODE)*MAXNODE) ; assert(newpool); nodepool = newpool; } NODE *n = nodepool + nodeptr; n->kind = kind ; ++nodeptr; return n;}��ѯ����
��ѯ������Ҫ�Բ�ѯ�����дʷ������������������������ʷ�������ָʶ��SQL����е������������Ԫ����ؼ��֣�SELECT��INSERT�ȣ������֣��������ȡ���������Ǹ��������ʶ������Ĵ���ϳ����������䡣 �ʷ���������LEX�����������ΪYacc����GNU�Ŀ�Դ�����ж�Ӧ����Flex��Bison��ͨ�����Ǵ���ʹ�á�
�ʷ��������
SQL����Ĵʷ����������������Flex��Bison���ɣ�parse_sqlΪ�����������ڣ�����bison��yyparse��ɡ�Դ�ļ�����������ʾ
| �ļ� | ���� |
|---|---|
| parse_node.h parse_node.cpp | ��������ڵ�ṹ�ͷ�������ں���Ϊparse_sql |
| print_node.cpp | ��ӡ�ڵ���Ϣ |
| psql.y | ������ṹ,��Bison���д |
| psql.l | ����ʷ��ṹ,��Flex���д |
SQL��ѯ��������
��ϤBison��Flex���÷�֮�����ǾͿ�������Flex��ȡ�Ǻ�,Bison���SQL��ѯ�����һ��SQL��ѯ����������ɶ�������ɣ��ԷֺŸ������������������DML��DDL���������֮�֡�
stmt_list : stmt ��;�� | stmt_list stmt ��;�� ; stmt: ddl | dml | unility | nothing ; dml: select_stmt | insert_stmt | delete_stmt | update_stmt | replace_stmt ;��DELETE �������
DELETE [IGNORE] [FIRST|LAST row_count] FROM tbl_name [WHERE where_definition] [ORDER BY ...]��Bison���Ա�ʾΪ:
delete_stmt:DELETE opt_ignore opt_first FROM table_ident opt_where opt_groupby { $$ = delete_node(N_DELETE,$3,$5,$6,$7);} ;opt_ignore:/*empty*/ | IGNORE;opt_first: /* empty */{ $$ = NULL;}| FIRST INTNUM { $$ = limit_node(N_LIMIT,0,$2);}| LAST INTNUM { $$ = limit_node(N_LIMIT,1,$2);};Ȼ���ڰ�opt_where,opt_groupby��table_ident��һֱ�ݹ���ȥ��ֱ��������ϸ��Ϊֹ��
SQL����ΪDDL����DML����utility��䣬����ֻ��DML�����Ҫ�ƶ�ִ�мƻ������������ת�빦��ģ��ִ�С�
�ƶ����ƻ�
ִ��˳��
���תΪ���ƻ�ʱ�����Ӵ����Ⱥ�˳����select���Ϊ����ִ�е�˳��Ϊ�� FROM > WHERE > GROUP BY> HAVING > SELECT > DISTINCT > UNION > ORDER BY > LIMIT��
û���Ż������ƻ�Ӧ��������˳�������ɻ����������ɡ�תΪ���ƻ��������ӦΪ�� JOIN �C> FILTER -> GROUP -> FILTER(HAVING) -> PROJECTION -> DIST -> UNION -> SORT -> LIMIT��
���ƻ����Ż�
���ƻ����Ż���Ҫ��ϸһ�������ȣ���FILTER��Ӧ�ı���ʽ��ֳɶ��ԭ�ӱ���ʽ����WHERE t1.a = t2.a AND t2.b = '1990'���Բ�ֳ���������ʽ��
1��t1.a = t2.a
2��t2.b = '1990'
������ν��LIKE��IN������£�ԭ�ӱ���ʽʵ���Ͼ���һ���ȽϹ�ϵ����ʽ����ڵ�Ϊ���������֣��ַ��������Խ�ԭ�ӱ���ʽ����Ϊ
struct CompExpr{ NODE * attr_or_value; NODE * attr_or_value; CompOpType kind;};CompOpTypeΪ��>��, ��<�� ,��=���ȸ��ֱȽϲ�������ö��值��
�������ʽ���� attr comp value ���� value comp attr������Խ���ԭ�ӱ���ʽ���Ƶ���Ӧ��Ҷ�ӽڵ�֮�ϣ�����һ��Filter��
�����attr = value���ͣ���attr�ǹ�ϵ�������Ļ�������Բ�������ɨ��IndexScan��
����������������ϵ�IJ���ʱ���ȶ���С�Ĺ�ϵ������ϡ�
�����������Ż��������Խ�һ�������ڴ����ݿ���洢�ڴ����ϵ����ݿ�Ĵ��۹��Ʋ�һ�������ݴ�����ѯʱCPU���ڴ�ռ�õĴ��ۣ���Ҫ��������һЩ���أ�
- ��ѯ��ȡ�ļ�¼����
- ����Ƿ�����(����ܻᵼ��ʹ����ʱ��)��
- �Ƿ���Ҫ����������ԭ����
�ƶ������ƻ�
������ѯ�ƻ���Ҫ�����һЩ�㷨ѡ��Ĺ��������ϵɨ������������� TableScan(R):������˳��������Դ����R�е�Ԫ�顣SortScan(R,L):��˳�����R��Ԫ�飬������L�����Խ�������IndexScan(R,C): ��������C����R��Ԫ�顣
���ݲ�ͬ�������ѡ��ͬ��ɨ�跽ʽ���������������ͶӰ����Projection��ѡ������Filter,�����������Ƕ����������NestLoopJoin��ɢ������HashJoin����������Sort�ȡ�
�㷨��һ���������������ģ�����ɢ�еģ������������ġ�
��ˮ���������ﻯ
���ڲ�ѯ�Ľ�������ܻ�ܴ�����������ͬʱΪ���ܹ���߲�ѯ���ٶȣ������������֧����ˮ����������ˮ������Ҫ������������֧�ֵ�������������֮��ͨ��GetNext�������ڵ�ִ�е�ʵ��˳��������������open,getnext,close3��������
��NestLoopJoin���������������ΪR��S��NestLoopJoin�ĵ������������£�
void NestLoopJoin::Open(){ R.Open(); S.Open(); r =R.GetNext();}void NestLoopJoin::GetNext(tuple &t){ Row r,s; S.GetNext(s); if(s.empty()){ S.Close(); R.GetNext(r); if(r.empty()) return; S.Open(); S.GetNext(s); } t = join(r,s)}void NestLoopJoin::Close(){ R.Close(); S.Close();}���TableScan��IndexScan��NestLoopJoin 3���������֧�ֵ�������������ͼ5�е�����NestLoopJoin(t1,t2��)�ɱ�ʾΪ��phy = Projection(Filter(NestLoopJoin(TableScan(t1),IndexScan(t2��))));
ִ�������ƻ�ʱ��
phy.Open(); while(!tuple.empty()){ phy.GetNext(tuple); } phy.Close();���ַ�ʽ�£������ƻ�һ�η���һ�У�ִ�е�˳����������ĺ�������������ȷ��������ֻ��Ҫ1���������Ϳ������û����ؽ������
Ҳ��Щ�����Ҫ�ȴ����н�����زŽ�����һ������ģ�����Sort , Dist���㣬��Ҫ������������ź������ܷ��أ�������������ﻯ���ﻯ����ͨ������open��������ɵġ�
һ������������
��������һ������Ϊ����ʾ�����ֵĽṹ��SQL��� SELECT t1.a,t2.b FROM t1,t2 WHERE t1.a = t2.a AND t2.b = '1990';
���Ӧ�ķ�����Ϊ�� 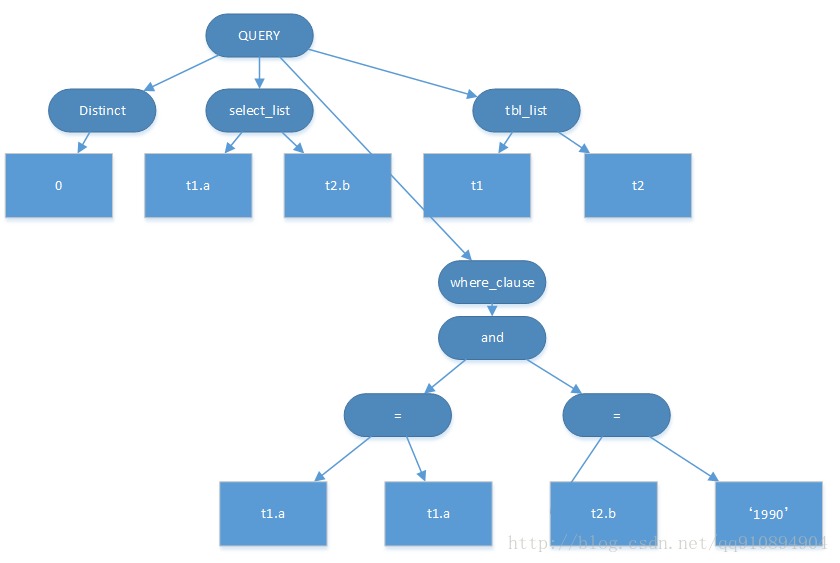
ͼ2. SQL�����Ӧ�ķ�����
��������Ҷ�ӽڵ�Ϊ���֣��ַ��������Եȣ�����Ϊ�ڲ��ڵ㡣
��ͼ2�ķ�����ת��Ϊ���ƻ�������ͼ3��ʾ�� 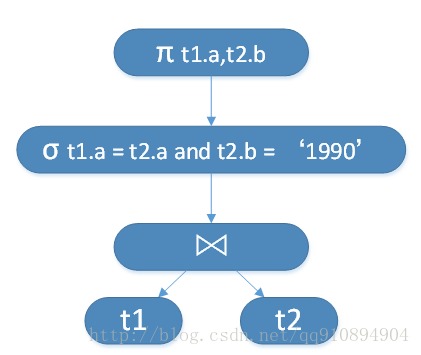
ͼ3. ͼ2��������Ӧ�����ƻ�
���ƻ��ǹ�ϵ������һ�����֣���ϵ����ӵ���ֻ����������ͶӰ (��)��ѡ�� (��)����Ȼ���� (?)���ۼ�����(G)�����ӡ�������ƻ�Ҳӵ����Щ���͵Ľڵ㡣
���ƻ����ڲ��ڵ������ӣ�Ҷ�ӽڵ��ǹ�ϵ���������ӱ���ʽ�������������ʱ��Ϊ�������㣬���SQL��ѯ�Ż��ĺܴ�һ���ֹ����Ǽ�С���ӵĴ�С����ͼ3��Ӧ�����ƻ����Ż�Ϊͼ4��ʾ�����ƻ���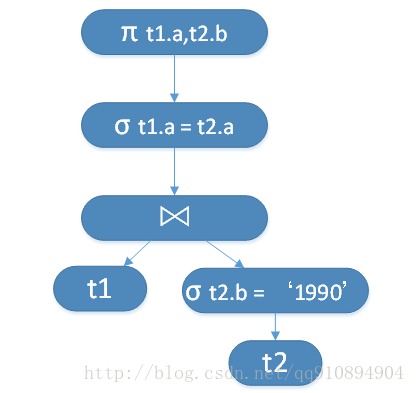
ͼ4. ͼ3�Ż�������ƻ�
������ƻ����Ż����ڽ����ƻ�ת��Ϊ������ѯ�ƻ���ͼ4�����ƻ���Ӧ��������ѯ�ƻ����£� 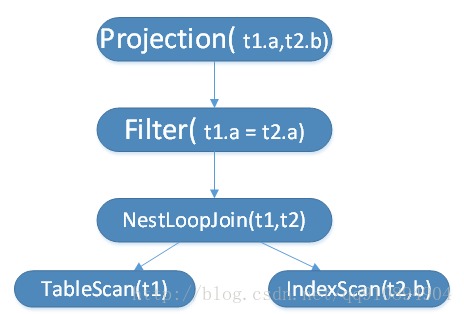
ͼ5. ͼ4��Ӧ��������ѯ�ƻ�
������ѯ�ƻ�������ƻ��е�ÿһ������ӵ�ж�Ӧ��1�����������������������ѯ�ƻ��ǻ��ڲ�ͬ�IJ���ѡ����ʵ�������������㡣���У���ϵɨ�������ΪҶ�ӽڵ㣬���������Ϊ�ڲ��ڵ㡣
���
��Դ�����ݿ�����п�������OceanBase����RedBase��OceanBase ���Ա��Ŀ�Դ���ݿ⣬RedBase��˹̹����ѧ���ݿ�ϵͳʵ�ֿγ̵�һ����Դ��Ŀ��������������Ŀ���ǽϽ���ʼ����Ŀ�����������٣��ṹ����������Լ�������github�϶����ҵ�������OceanBaseĿǰSQL��������Ҳû��ȫ����ɣ�ֻ��DML������ɣ�RedBase��Ƹ�������û��������ƻ���
�����о��Dzο���RedBase�ķ�ʽ���н�����
�ο����ף�
�����ݿ�ϵͳʵ�֡�
��flex��bison��
��ӭ�����ҵ���վ----������Ȼ�IJ���----�˼�������ר����
����Ķ����Ĺ��������κ����⣬����ϵ���ߣ�ת����ע��������