最近常看到"参数嗅探"这个词,看了几篇文章,于是就自己摸索做个测试来加深印象!去官网下载了数据库:AdventureWorks2012直接测试吧!找几个熟悉的表关联起来,用ProductID作为条件找到两个ID返回行数相差较大的值.ProductID=870(4688行) ProductID=897(2行)
【测试一】
--先清空计划缓存DBCC FREEPROCCACHE--执行前先打开计数器监控查看(分开执行以下查询)select sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID =870select sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID =897
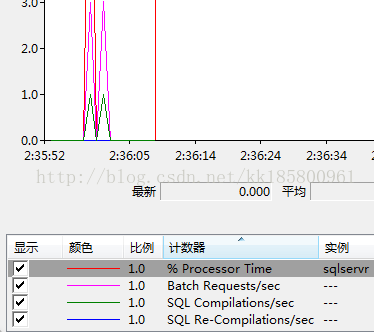
先看计数器,有两个绿色的峰值为1.就是上面分别执行时发生的编译次数.
-- 查看缓存对象执行类型:Adhoc(即时查询)SELECT cacheobjtype,objtype,refcounts,usecounts,[sql]FROM sys.syscacheobjectsWHERE [sql] LIKE '%SalesOrderID%' AND [sql] NOT LIKE '%sys%'-- 再用视图查看缓存查询计划和计划大小SELECT refcounts,usecounts,cacheobjtype,size_in_bytes,[text],query_planFROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)CROSS APPLY sys.dm_exec_query_plan(plan_handle)WHERE [text] LIKE '%SalesOrderID%' AND [text] NOT LIKE '%sys%'
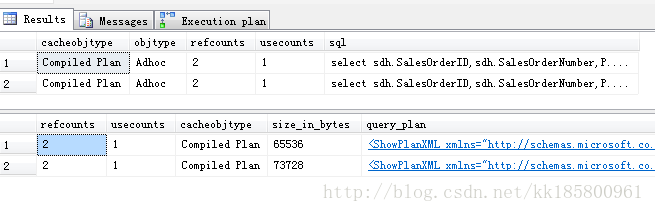
可以看到生成了两个不同的查询计划(query_plan),并且占用了缓存(size_in_bytes).
以上这种写法的优缺点是:
缺点: 如果查询条件值发生变化,每次都会作为新的查询语句编译第一次,不仅消耗CPU,而且生成新的查询计划也会占用缓存.
优点:每次执行计划都是最优的
【测试二】
现在换成带参数的形式.
--先清空计划缓存DBCC FREEPROCCACHE-- ProductID=870(4688行) ProductID=897(2行) DECLARE @ProductID INTSET @ProductID = 870select sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID [email protected]DECLARE @ProductID INTSET @ProductID = 897select sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID [email protected]
看计数器,同样有两个绿色的峰值为1.发生了2次编译
-- 再用视图查看缓存查询计划和计划大小SELECT refcounts,usecounts,cacheobjtype,size_in_bytes,[text],query_planFROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)CROSS APPLY sys.dm_exec_query_plan(plan_handle)WHERE [text] LIKE '%SalesOrderID%' AND [text] NOT LIKE '%sys%'

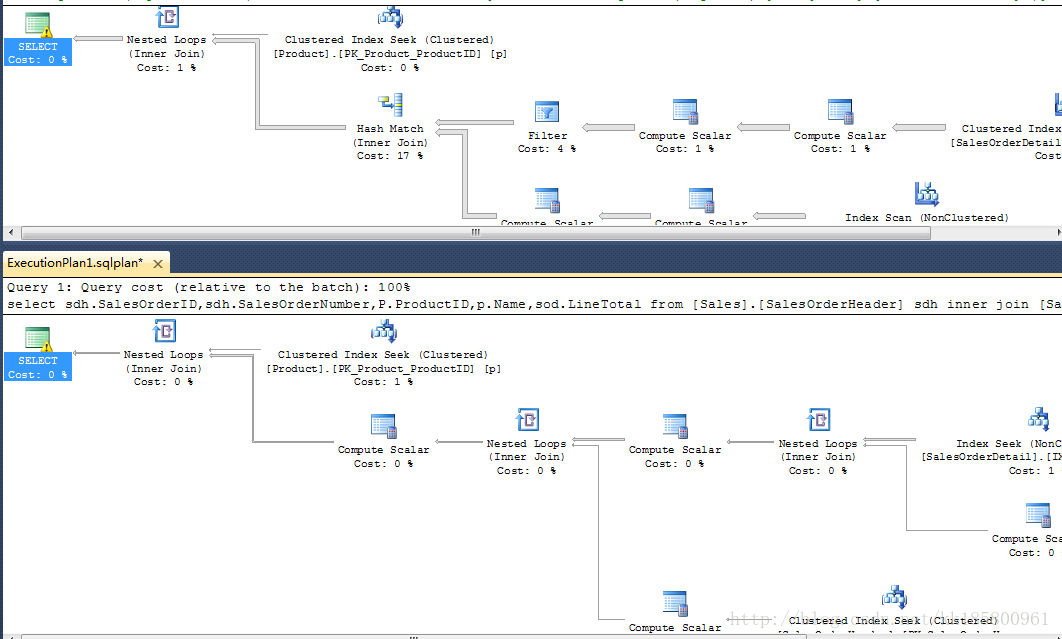
这会可以看到生成了两个相同的查询计划(query_plan),缓存大小(size_in_bytes)也就相同了.
还有另一点不同之处就是,执行计划分两部分执行,第一部分参数赋值,第二部分查询语句.
因此第二部分才用了相同的查询计划.
以上这种写法的优缺点是:
缺点: 如果查询条件值发生变化,每次都会作为新的查询语句编译第一次,不仅消耗CPU,而且生成新的查询计划也会占用缓存.
还有就是,由于查询计划相同.当返回行数相差较大.有的查询性能并不是较好的.
优点: 当返回数据量都差不多的时候是较好的,查询优化器根据参数估计一个较好的查询计划,有利于对查询计划进行控制.
(但是比较发现,这种写法比上一种还差!最后再测试)
【测试三】
-- 这时把执行语句放到存储过程CREATE PROCEDURE P_Test(@ProductID INT)ASBEGINselect sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID [email protected]END-- ProductID=870(4688行) ProductID=897(2行)-- 执行存储过程DBCC FREEPROCCACHEEXEC P_Test @ProductID = 870EXEC P_Test @ProductID = 897-- 查看缓存对象执行类型:Proc(存储过程)SELECT cacheobjtype,objtype,refcounts,usecounts,[sql]FROM sys.syscacheobjectsWHERE [sql] LIKE '%SalesOrderID%' AND [sql] NOT LIKE '%sys%'SELECT refcounts,usecounts,cacheobjtype,size_in_bytes,[text],query_planFROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)CROSS APPLY sys.dm_exec_query_plan(plan_handle)WHERE [text] LIKE '%SalesOrderID%' AND [text] NOT LIKE '%sys%'
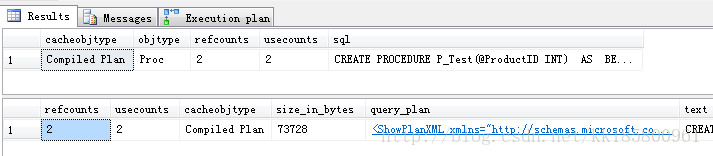
这时发现,只有1个缓存计划!无论参数怎么改变都是只缓存一个查询计划,这样就省去了内存的占用.
但是这个方法的优缺点就更明显了.
这种写法的优缺点是:
缺点: 如果查询条件值发生变化,每次都会编译1次,消耗CPU.
最重要的缺点是,查询计划的产生,是以第一次执行存储过程所传递的参数值来确定的!
也就是说,在存储过程创建后,传递参数首次执行存储过程,该参数返回的行数或多或少都会影响到执行计划的永久确定.
DBCC FREEPROCCACHE--情况计划缓存
EXEC P_Test @ProductID = 870--现在换870先执行
EXEC P_Test @ProductID = 897--刚才为897首次执行存储过程
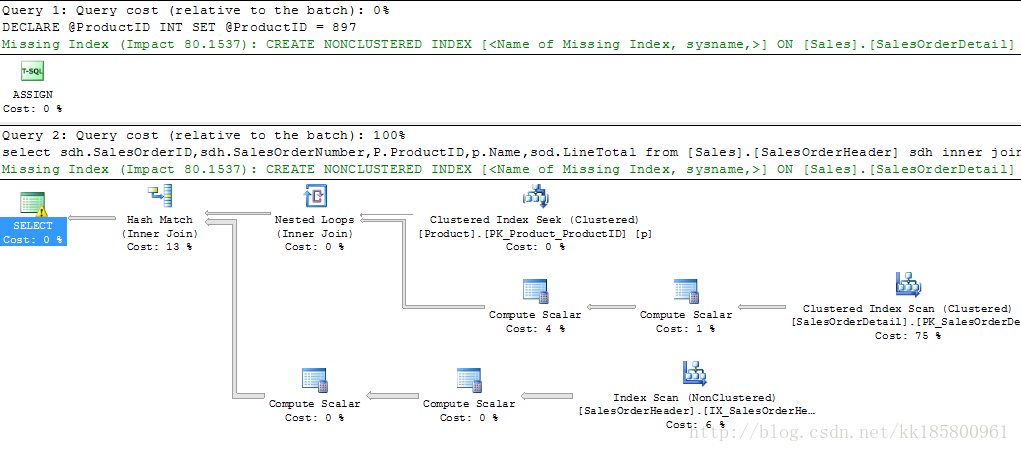
执行后再看查询计划,又是不一样了!
所以这点要注意,为什么同样的存储过程,表统计信息没问题,但是有的查询快,有的慢.
跟踪把具体语句查出来运行又正常,就如同上面【测试一】一样。
这种情况的解决方法可以这样:EXEC P_Test @ProductID = 897 WITH RECOMPILE
使用WITH RECOMPILE时,系统只对当前存储过程编译并用该计划,并没有生成新的查询计划。系统缓存的还是原来的计划。
优点: 省下了内存! 不用每次编译
【测试四】
-- 这时把执行语句放到存储过程CREATE PROCEDURE P_Test2(@ProductID INT)ASBEGINDECLARE @ID INTSET @ID = @ProductID --区别在这里select sdh.SalesOrderID,sdh.SalesOrderNumber,P.ProductID,p.Name,sod.LineTotalfrom [Sales].[SalesOrderHeader] sdhinner join [Sales].[SalesOrderDetail] sod on sdh.SalesOrderID = sod.SalesOrderIDinner join [Production].[Product] p on sod.ProductID = p.ProductIDwhere P.ProductID [email protected] END-- ProductID=870(4688行) ProductID=897(2行)DBCC FREEPROCCACHEEXEC P_Test2 @ProductID = 870EXEC P_Test2 @ProductID = 897SELECT refcounts,usecounts,cacheobjtype,size_in_bytes,[text],query_planFROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_sql_text(plan_handle)CROSS APPLY sys.dm_exec_query_plan(plan_handle)WHERE [text] LIKE '%SalesOrderID%' AND [text] NOT LIKE '%sys%'

这种方法优缺点与【测试三】其他一样,唯一不同的是,首次生成的执行计划不受参数影响。
如下两个存储过程,刚创建完存储过程后,不管谁先执行,查询计划都是一样的!
EXEC P_Test2 @ProductID = 870
EXEC P_Test2 @ProductID = 897
这里就真正用到了所谓的“参数嗅探”!因为优化引擎首次确定查询计划时,并不知道执行的参数值是什么。
因此只嗅探到传递的参数,系统就是根据参数确定了存储过程的查询计划。
这里也有不好的一点,就是参数返回多少也可能影响到性能。
对于这种存储过程,即使使用【WITH RECOMPILE】,计划还是一样。如下脚本,这种写法多余。
EXEC P_Test2 @ProductID = 870 WITH RECOMPILE
EXEC P_Test2 @ProductID = 897 WITH RECOMPILE
---------------------------------------------------------------------
---------------------------------------------------------------------
总结:
以上几种都有优缺点,最不好的就是【测试二】那种。
还有一个现象,就是上面的所有测试,个人在性能监视器中都没有发现“重编译”的情况,每次都只有“编译”。
虽然编译包括重编译,但是重编译都没出现过一次。除非显示让语句重编译(如 option(recompile))才出现。
测试一:最佳,每次都会生成新的计划缓存。但每次都编译并缓存
测试二:不好,同样缓存计划,返回结果集较大时性能不一样。每次都编译并缓存
测试三:省缓存,重用计划。随着表数据量增长,存储过程最好重新编译
测试四:省缓存,查询计划固定,更改不了。
最后总体测试对表以上这四种情况:
数据较多,不截图了,总结如下:
| ProductID | 查询类型 | 格式 | 总逻辑读 | CPU | 内存 | 时间 | 每次编译 | 缓存大小 | 查询开销 |
| 870(4688行) | 即时查询 | where P.ProductID =870 | 1305 | 20 | 952 | 20 | 是 | 56 KB | 26% |
| 870(4688行) | 即时参数查询 | where P.ProductID [email protected] | 1305 | 16 | 1016 | 16 | 是 | 56 KB | 24% |
| 870(4688行) | 存储过程 | proc :@ProductID = 870 | 1305 | 17 | 928 | 17 | 是 | 56 KB | 26% |
| 870(4688行) | 存储过程内声明 | proc :where P.ProductID [email protected] | 1305 | 18 | 984 | 18 | 是 | 56 KB | 24% |
| 897(2行) | 即时查询 | where P.ProductID =897 | 20 | 10 | 792 | 10 | 是 | 48 KB | 13% |
| 897(2行) | 即时参数查询 | where P.ProductID [email protected] | 1305 | 17 | 1016 | 17 | 是 | 56 KB | 37% |
| 897(2行) | 存储过程 | proc :P_Test @ProductID = 897 | 20 | 8 | 760 | 8 | 是 | 56 KB | 13% |
| 897(2行) | 存储过程内声明 | proc :where P.ProductID [email protected] | 1305 | 18 | 984 | 18 | 是 | 56 KB | 37% |