����������ѧsqlserver��ʱ���̿����ǰ���Ƕ�˵״̬�ٵ��ֶβ�Ҫ���������ɴ˴����Ŀ��������粻��������������仰�ж��������֪����
����˵�ж�������ĶԴ��бȽ���̵����⣬�����������˵���;˵�����������ǵÿ죬���ǵ�Ҳ������������ƪ��������һ����仰�����м�����˼��
һ������
�� �������ǻ����ò����������������⣬���Ƚ���һ��Person����5���ֶΣ�����sql���£�
DROP TABLE dbo.PersonCREATE TABLE Person(ID INT PRIMARY KEY IDENTITY,NAME VARCHAR(900),Age INT,Email VARCHAR(20),isMan INT )-- ��isMan�ֶδ����Ǿۼ�������0��Ů 1���У�CREATE INDEX idx_isMan ON dbo.Person(isMan)DECLARE @ch AS INT=0WHILE @ch<=100000BEGIN INSERT INTO dbo.Person(NAME,Age,Email,isMan) VALUES ( REPLICATE(CHAR(@ch),50), @ch, CAST(CAST(RAND()*1000000000 AS INT) AS VARCHAR(10))+'qq.com', @ch%2 ) SET @ch=@ch+1END
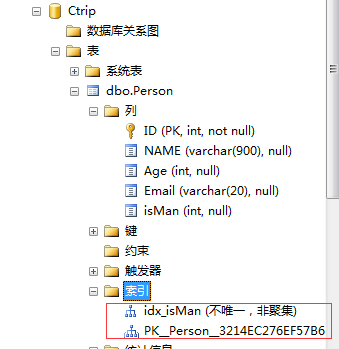
ͨ�������sql���Է��ֱ�����5���ֶΣ�IDΪ�ۼ�������isManΪ�Ǿۼ�������isManҲ��������״̬��0,1�������Ҳ���10w����¼����ͼ���£�
sql�������ˣ�������Ҫ����������Dz�ѯ�£� isMan=1�ļ�¼������ͼ��
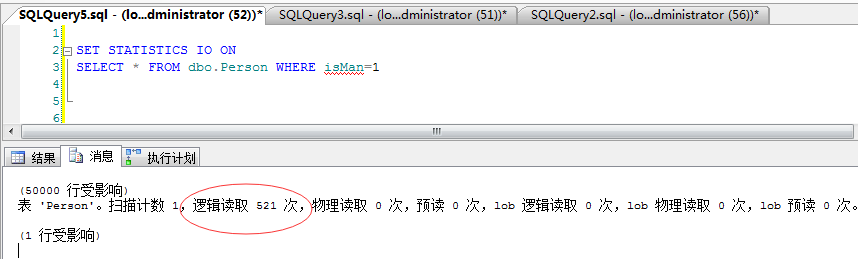
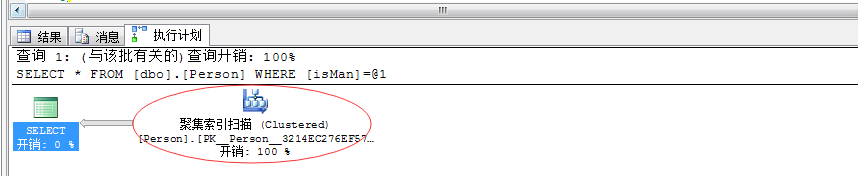
�鵰�������������������isMan�������ݼ����ģ���ô�ͱ�� “�ۼ�����ɨ��”�ˣ���������ô��ʲô��˼���Ȼ�����ҵ�“idx_isMan”������
ȴ����ô��“�ۼ�����(PK__Person__3214EC276EF57B66)”��������ͬʱҲ���������”����ȡ”Ϊ521������˵�����ڴ�������521������ҳ��
�����Ҳ���ѽ��������һ��Ҫ��ִ�мƻ����ҵ������������취����ǿ��ָ������������ͼ��
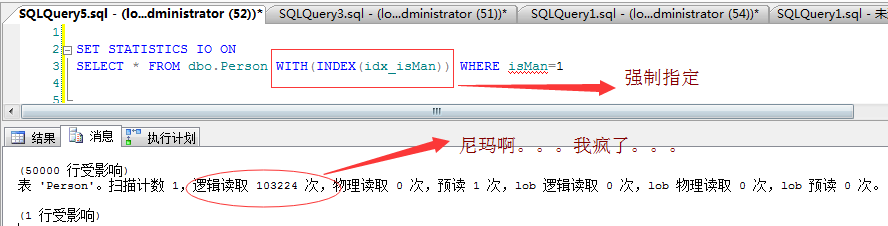
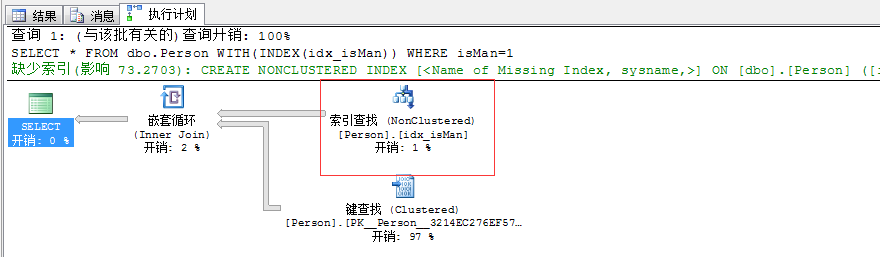
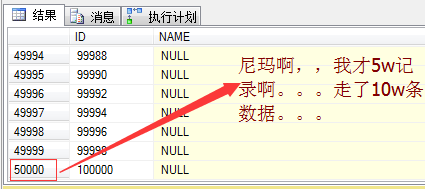
���������ͼ�����Dz����Ѿ����ˡ��������Ӳ���5w�����ݣ����������10w�������ҳ��������ô˵1����¼Ҫ����������ҳ��������ɨ��ۼ�
��������521������ҳ�����200���������ѹ�ִ�мƻ�����Ҳ����“idx_isMan”��������������Ҫ�����������˼һ����õ�ͱ��sqlserverô������
��������ԭ��
�������ں������������˶������ˣ�Ϊʲô������������Ϊ���ҳ����⣬���ǻ��ÿ�����ҳ��
1 DBCC TRACEON(3604,2588)2 DBCC IND(Ctrip,Person,-1)

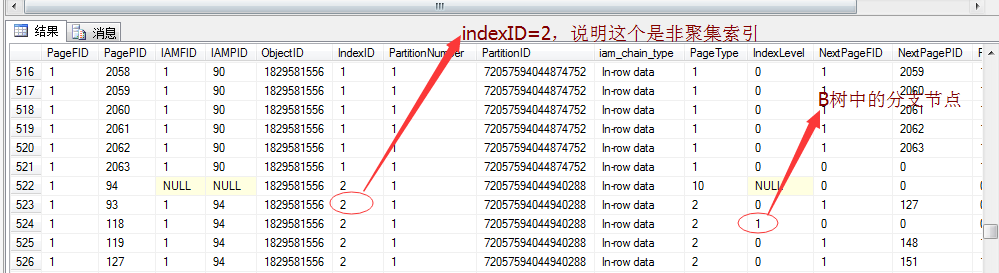
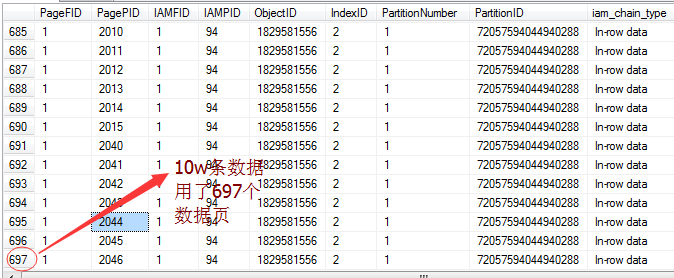
ͨ�����������ͼ����ſ��Կ�����10w����������697����ҳ�����оۼ�������521�����Ǿۼ�����Ϊ176������Ҳ˵���������”�ۼ�����ɨ��“��
�������Լ����е�����ҳ�����̳����ݣ�ͬʱ��������������������һ����ͬ�������ǣ�ֻ��һ�����ڵ�(indexLevel=1������������indexLevel=0��
Ҷ�ӽڵ㣬Ȼ���������������һ��ͼ�����ˡ�����
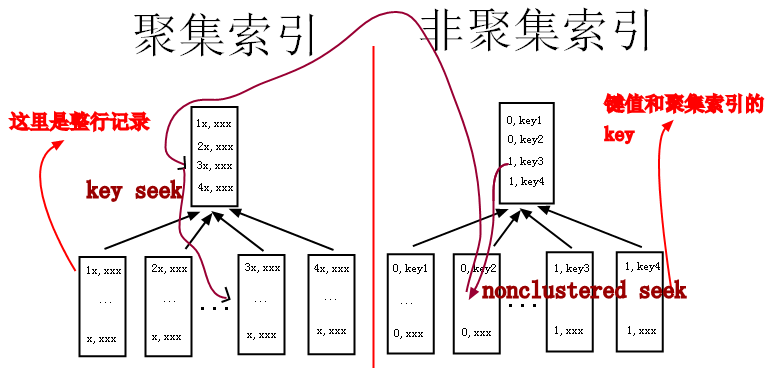
��������ҹ�˼������ͼ�����רҵһ������ֽ�����ǩ���ҡ���������ͨ������”idx_isMan“�����ͻṹ���Ұ�ͼ��B���ṹ������������¼
��������ֵ��һ��������ֵisMan��һ���ۼ�����ֵID������㲻���ŵĻ�������ͨ��DBCC Pageȥ̽��"idx_isMan"������ҳ����Ҳ����ͨ��
DBCC SHOW_STATISTICS ȥ�鿴����ͼ��
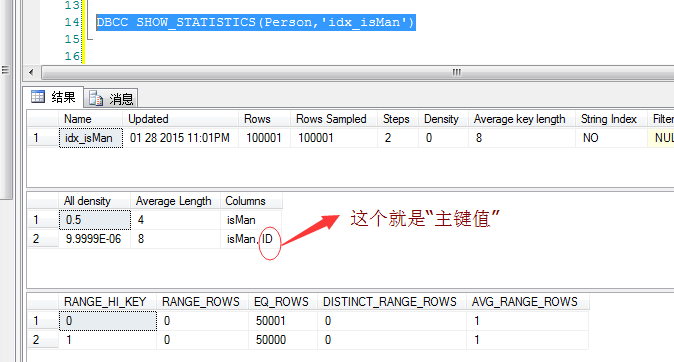
Ȼ������ͨ��“idx_isMan“ɨ����õ���keyֵ�����Ƿdz���ϧ������select * �ģ����Ա��뻹Ҫ�����¼�е�Name��Emai��l�ֶΣ�����
”index_isMan"�в�û�б����⼸���ֶΣ����Ա���ͨ��keyȥ”�ۼ�����“��B����ȥ�ҡ��������ͨ��”�ۼ�����“��B���ҵ���Ŀ���¼����Ҳ
������ν��ִ�мƻ��е�”������“��Ȼ�����”Name��Email“���ֶΡ�����������������������Ϊ���������صı��Q���Q������������ҳ�
������һ����¼����Ҫ���Q2-3������ҳ�����������Ѱ�Ҽ�¼���ɲο�ͼ�е�”��ɫ����“�����Ҳ�������10w��α��Q������
������ʾ
��������Ӹ�����ʲô��ʾ�أ�������ϸ�������֪��������ʹ�÷Ǿۼ�������ǧ��Ҫ��ȡ��������ݡ�������Ϊ��������ݻ�����ڶ��
B�������صı��Q��������Ҫ������ȡ���ݽ��٣��ͱ����ڸ�Ψһ�Ե��ֶ��Ͻ��������������Ļ��ڷǾۼ�����B���з��ϵ�������Խ��٣�Ҳ��
�������ұ��Q��”��������“��B�����������������Ļ����ر��Q�Ĵ���ԶԶ��”�ۼ�����“ɨ������ʵ�ݣ��Բ��ԡ�����
���Խ��۳����ˣ�������Ψһ�Խϸߵ��ֶ��Ͻ����Ǿۼ�������
- 4¥�᳤
- �����ٶ�̫���ˣ���Ҫ��������·ŵ��¿��У��㲻����ɣ��㷢�ı��������Ķ���
- 3¥�������·�˹��
- ����֮����scan����Ϊ��������̫������Ҳ�д���ȷ��Ψһ�Խϸߵ��ֶν���cluster index��������isman֮����ֶ��ǿ��Խ���non cluster index�ģ�������Ҫ��Ϊ������ǰ��
- Re: ���Ѳ���
- @�������·�˹�������þ���֮����scan����Ϊ��������̫������Ҳ�д���ȷ��Ψһ�Խϸߵ��ֶν���cluster index��������isman֮����ֶ��ǿ��Խ���no cluster index�ģ�������Ҫ��Ϊ������ǰ�أ�¥��˵���DZ�����Ψһ�Խϸߵ��ֶ��Ͻ����Ǿۼ������������������ʸ����⣬���Ǿۼ�������¼��������ֵ��һ��������ֵisMan��һ���ۼ�����ֵID������ۼ�����ֵID��ʲô���Ǿۼ���������ֵ���DZ����������������û�оۼ������Լ�������������أ�ֻ�зǾۼ��������������и�������ܲ��Ǻ����������ҳ������������ҳ��ʵ�ʼ�¼������ҳ�ɣ���������ҳֻ�����������ı��д��ڣ�������ҳ�ж�������ô��������ģ�����ҳ��С���Լ������еij��ȣ��������һ�����⣬¥���Ǹ�����Ⱥ�Ƕ��٣�����û�У�
- 2¥dotNetDR_
- ��ô��������ˣ�����ֻ����0��1�������Ƶ��ֶΡ���ô����������ܲŻ�������ȥ�������ɷ������м�һ�����ݣ�
- Re: john_masen
- @dotNetDR_����ʵ���Ľ���һ���ܳ������������⣺���Ǿۼ�����û�а���select�����������Ҫ������ֶ�ʱ�����ݿ����治�ò���ȡ�ۼ��������ճ����е�����ֶΡ� ����Ȼ�����Ǿۼ�������ʱ�����include������ֶ��������������������ͬ����Ҫ�������������Լ�����Ч���½��������������½������ݿ��Ż����Dz�ǽ����ǽ���ؼ�����ΰ���ƽ�⡣
- 1¥fishstone
- ���һ����ٽ����ֶ�������Ӱ��Ӧ�ò�̫���