在数据库应用开发中,我们经常需要取出最大值(或最小值)对应的记录而不是最大值本身,比如:每位员工涨薪最多的一次是哪次;高尔夫成绩最差的三次是哪三次;每个月,每种产品销量最高的五天是哪五天。由于SQL的max函数只能取出最大值,而不是最大值对应的记录,因此处理起来会比较复杂,只能用窗口函数或嵌套子查询以及keep/top/rownumber等高级技巧来间接处理。如果是多层分组、多级关联,计算过程会更加复杂。
集算器的top函数可以取出最大值对应的记录,解决此类问题会更加容易,下面用一个例子来说明。
数据库表golf存储着多位会员的高尔夫得分情况,请取出每位会员成绩最好的三次得分情况,部分数据如下:
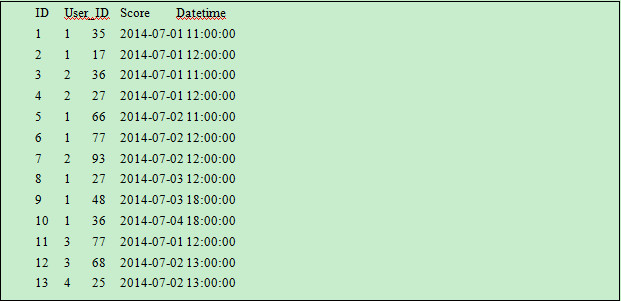
?
集算器代码:
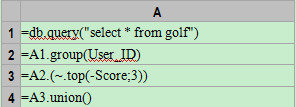
?
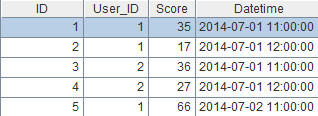
A1:从数据库取数。如果数据来自结构化的文本文件,可以使用这样的等价代码:=file("\\golf").[email protected]()。点击该单元格,可以看到取数结果:
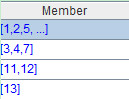
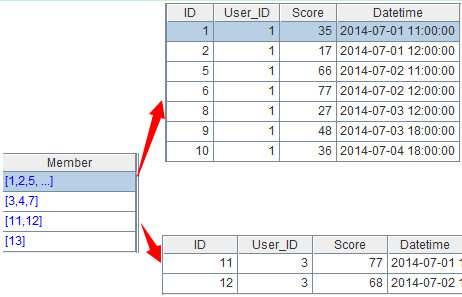
?A2:=A1.group(User_ID)。将A1的计算结果分组,结果如下:
?
如上图,数据按照User_ID分为了多个组,每行代表一组。点击蓝色超链接,可以看到组内成员,如下:
?
?
A3:=A2.(~.top(-Score;3))。计算出每组数据Score字段前三的记录。这里的“~”表示每组数据,~.top()表示依次对每组数据应用函数top。函数top可以取得数据集中最大或最小的N条记录,比如top(Score;3)表示按Score升序排列,取前3条(即最小值);top(-Scroe;3)表示按降序排列,取前3条(即最大值)。这一步的计算结果如下:
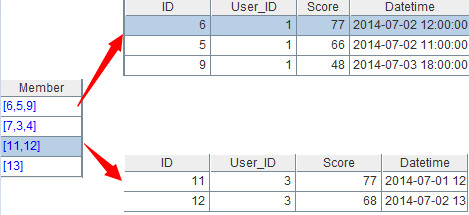
?
A4:=A3.union()。将各组数据合并,结果如下:
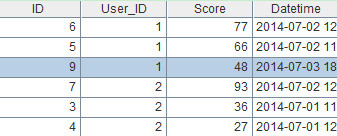
?
上述是分步骤的计算,便于维护和调试,也可以将四步合一:db.query("select * from golf").group(User_ID). (~.top(-Score;3)).union()。
集算器被java程序调用的方法也和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。
?