? ? ? ? 区间合并是我们经常遇到的一种复杂SQL计算,如进行不重复时间段汇总,或将重叠的时间段合并等计算。由于SQL集合无序,实现时需要采用递归的方式实现,而对于递归函数不足的数据库实现起来则更加困难。除了递归,SQL实现时还要依赖多层子查询嵌套问题,SQL语句过为冗长使得实现和修改起来都很困难。
??? 集算器在实现这类计算时则比较简单,可以通过直观分步的脚本实现区间合并,下面通过一个例子说明。
?
?????? 用户操作记录表Udetail中存储各用户操作明细记录,部分源数据如下:
ID?? UID ?????? ST?? ?????? ????????????? ET
1???? 1001?????? 2014-9-1 10:00:00? 2014-9-2 11:30:00
2???? 1001?????? 2014-9-1 10:30:00? 2014-9-2 11:00:00
3???? 1001?????? 2014-9-3 11:00:00? 2014-9-4 12:00:00
4???? 1001?????? 2014-9-4 10:00:00? 2014-9-5 13:00:00
5???? 1001?????? 2014-9-4 15:00:00? 2014-9-5 18:00:00
6???? 1002?????? 2014-9-1 11:00:00? 2014-9-2 11:30:00
7???? 1002?????? 2014-9-1 10:30:00? 2014-9-2 11:00:00
???
?????? 其中,ST和ET分别为操作起止时间,每个用户中的时间段可能重叠,现需要根据指定用户起止时间计算:
? ? ???1、合并重叠的时间段,生成新的时段记录;
? ? ???2、?汇总不重叠的总时间。
?
? ? ???集算器实现代码如下:

?
? ? ???其中:
? ? ???A1=db1.query("select * from udetail where UID=?",arg1)
?
? ? ???根据指定用户从数据库查询数据,arg1是外部参数,比如arg1=1001。部分查询结果如下:
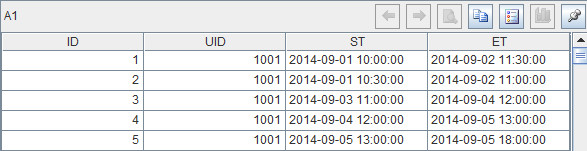
?
? ? ? ? ?A2= A1.sort(ST).select(ET>ET[-1]).run(max(ST,ET[-1]):ST)
?
???????? 该句代码首先按照起始时间排序(.sort(ST)),并选出结束时间大于上一结束时间的记录(.select(ET>ET[-1])),即删除完全重叠的时间段;最后取出起始时间和上一结束时间中最大值作为本条记录的起始时间,即可生成新的不重叠时段记录。结果如下:
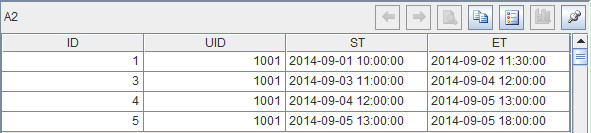
?
? ? ???这里可以看到集算器中集合是有序的,所以可以直接通过序号引用上一条记录,这与SQL有很大不同。
???????? 如果希望将连续的时间段合并为一个时段,可以将A2中的代码改为:A2=A1.sort(ST).select(ET>ET[-1]).run(if(ST<ET[-1],ST[-1],ST):ST).group(ST;~.m(-1).ET:ET)
?
? ? ???可以得到如下结果:

?
? ? ? ? ?A3=A2.sum([email protected](ST,ET))
?
???????? 汇总重叠总时间。计算结果如下:

?
? ? ? ? ?如果只汇总不重叠时间(不需要明细),可以将代码改为:
? ? ???A1.sort(ST).select(ET>ET[-1]).sum([email protected](max(ST,ET[-1]),ET))
? ? ???如果时间跨度不大,还可以这样写:A1.([email protected](ST,ET)).union().len()-2,通过计算时间点个数完成。
????????
?
另外,集算器可被报表工具或java程序调用,调用的方法也和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。