逆分组也是我们经常遇到的一种计算,即将每条记录拆成多条,实现分组汇总的逆运算。SQL可以实现这种算法,但必须转换思路绕个大弯才能实现,代码很复杂,也不易理解。
集算器实现这种逆分组较为容易,代码简单易懂,下面用一个例子来说明。
? 表packGather记录着多种产品的包裹汇总数据,字段productID是产品编号,字段packing是包裹件数,每个包裹里的产品数量相同,字段quantitiySum是产品总量。部分数据如下:
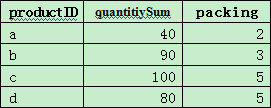
?
现在需要将表packGather拆分成包裹列表,即将多件包裹均分成单件包裹,并给每个包裹设定相对序号。以产品b为例,拆分后是3条记录:

?
集算器代码:

?
A1:从数据库取数。计算结果如下:
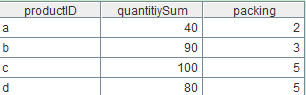
?
A2= A1.conj(packing.new(~:seq, productID:product, quantitiySum/packing:quan))
这句代码表示将A1中的每条记录拆成多条,形成二维表,每个二维表的记录数不同但结构相同,都有三个字段:seq、product、quantity,最后将这些二维表纵向拼成一张大二维表。
函数conj的作用是拼合,比如单独拆分A1的第一条记录,代码和结果分别是:
?
A1(1).(packing.new( ~:seq,productID:product,quantitiySum/packing:quan))

?
?
A1.conj(…)等价于[A1(1),A1(2),A1(3)…].conj(…),最终结果如下:
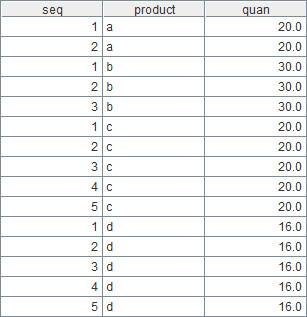
?
注意表达式packing.new(…),这表示根据A1中每条记录的packing字段建立新序表。函数new可以根据已有的序列/序表创建新序表,比如["a","b","c"].new()或[1,2,3…N].new(),后者可以简化成N.new()。比如第一条记录packing=2,则本表达式会被解析为[1,2].new(…)。用函数new建立新序表时,可以用符号“~”来表示原序列中的成员,因此表达式中的~:seq就表示将原序列作为新序表的第一个字段,字段名是seq。
A2就是本案例的最终计算结果。
?
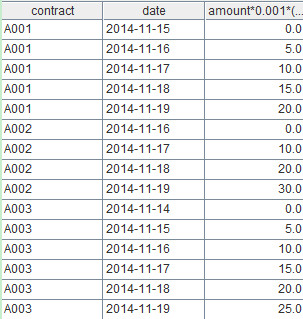
下面再看一个数据仓库中计算每日违约金额的例子,contract表有若干字段,其中合同编号、到期日、合同金额分别是:ID、enddate、amount,请计算到目前为止,违约的那些合同每天所需要交纳的违约金。假设每天所需交纳的违约金是合同金额的千分之一。
?
表contract的部分数据如下:
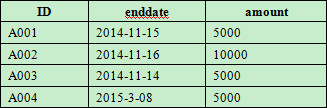
?
集算器代码:

?
这段代码使用了函数periods来生成从合同到期日到当天的日期序列,#代表时间序列的当前序号。最终计算结果如下:
?
另外,集算器可被报表工具或java程序调用,调用的方法也和普通数据库相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的计算结果,具体方法可参考相关文档。
?