译序
很多朋友问时下如火如荼的 Hadoop 是否适合引进我们自己的项目,什么时候用 SQL,什么时候用 Hadoop,它们之间如何取舍?Aaron Cordova 用一张图来回答你这个问题,对于不同的数据场景,如何选取正确的数据存储处理工具进行了详细描述。Aaron Cordova 是美国大数据分析及架构专家,Koverse CTO 及联合创始人。原文正文
Twitter 上的 @merv 转发了一篇博客《三角形的统计》。这是一篇关于如何统计一张图形里的三角形的博客,并将使用 Vertica 和 Hadoop 的 MapReduce 的结果进行了对比。在 1.3 GB 的数据之上,Vertica 比 Hadoop 快了 22-40x 倍。而且它只用了三行 SQL。统计表明,在 1.3 GB 数据之上,Vertica 更简单更快速。但这个结果不是太那么有意思。
对于写入任务的结果将会截然不同 - 是,SQL 在这个案例里确实非常简单,大家都知道。SQL 是比 MapReduce 简单得多,但在分布式计算的场合 MapReduce 却又比 SQL 简单的多。而且 MapReduce 还能做 SQL 做不到的事情,比如图像处理。
以 1.3 GB 的数据作为 Vertica 或者 Hadoop 的衡量基准,就像说"我们将要在波音 737 和 DC10 之间进行一场 50 米赛跑比赛"一样。这样的一场比赛甚至都无须起飞。上面博客的对比也是一样的道理。这些技术显然都不是设计用来处理这种级别的数据集。
如果有一个可伸缩的系统即使在小规模数据仍然很快的话当然更好,但这不是本文所讨论的。在大规模数据时的性能结果是否还是这么明显,这个问题就不是那么显而易见的了,确实值得证明。
为了帮大家如何基于自己的实际情况选取哪种技术,我画了这个流程图:
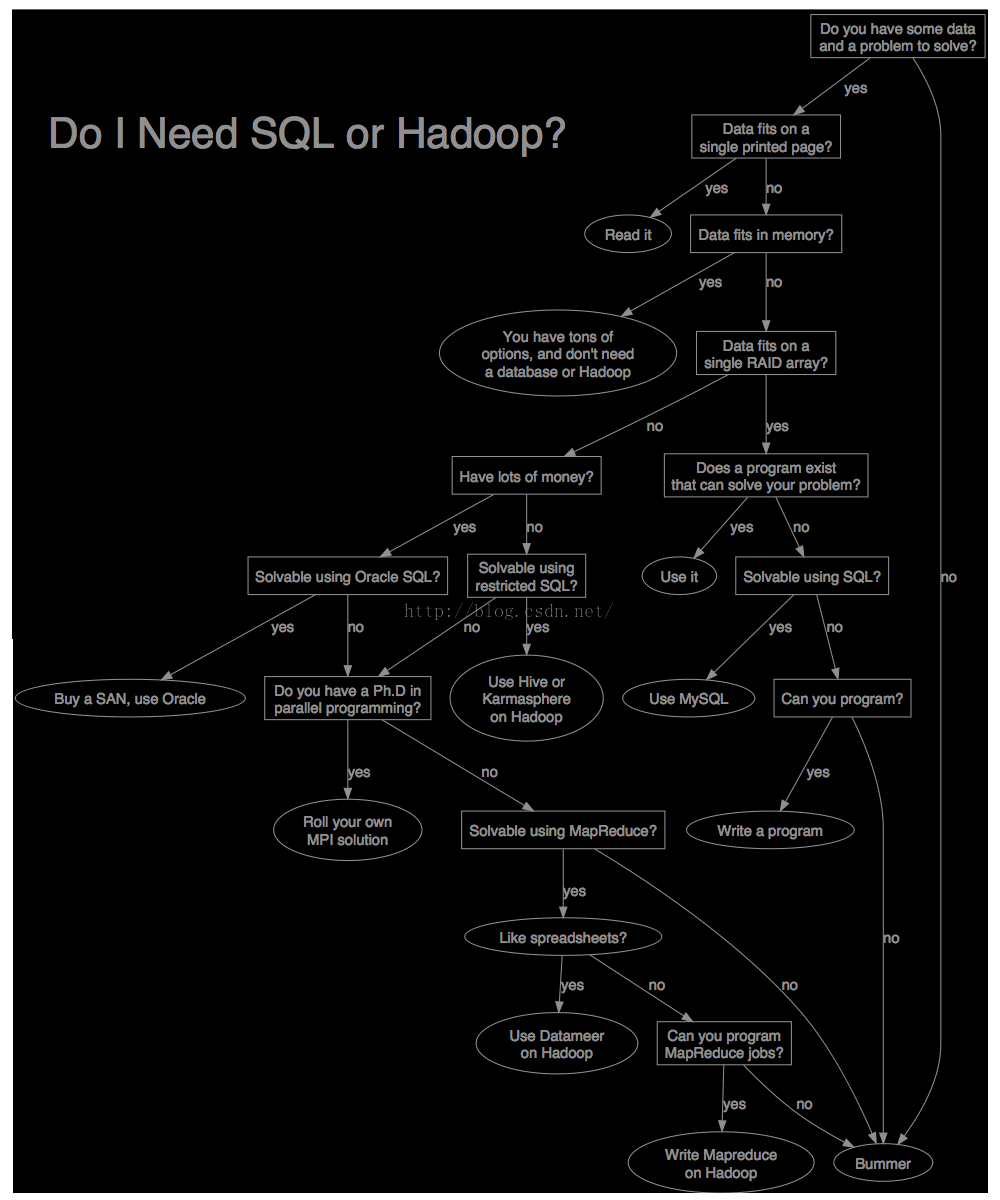
原文链接:http://aaroncordova.com/blog2/roncordova.com/2012/01/do-i-need-sql-or-hadoop-flowchart.html。
- 1楼dear_Alice_moon昨天 18:02
- 为何这则博文自己收藏不了呢?