【注】该系列文章以及使用到安装包/测试数据 可以在《倾情大奉送–Spark入门实战系列》获取
1 运行环境说明
1.1 硬软件环境
- 主机操作系统:Windows 64位,双核4线程,主频2.2G,10G内存
- 虚拟软件:VMware? Workstation 9.0.0 build-812388
- 虚拟机操作系统:CentOS 64位,单核
- 虚拟机运行环境:
- JDK:1.7.0_55 64位
- Hadoop:2.2.0(需要编译为64位)
- Scala:2.10.4
- Spark:1.1.0(需要编译)
- Hive:0.13.1
1.2 机器网络环境
集群包含三个节点,节点之间可以免密码SSH访问,节点IP地址和主机名分布如下: 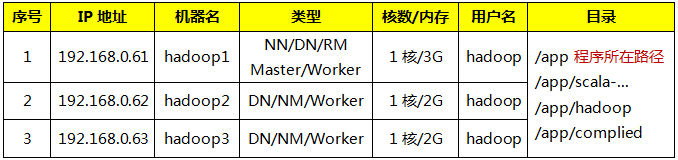
2 Spark基础应用
SparkSQL引入了一种新的RDD——SchemaRDD,SchemaRDD由行对象(Row)以及描述行对象中每列数据类型的Schema组成;SchemaRDD很象传统数据库中的表。SchemaRDD可以通过RDD、Parquet文件、JSON文件、或者通过使用hiveql查询hive数据来建立。SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
值得注意的是:
- Spark1.1使用registerTempTable代替1.0版本的registerAsTable
- Spark1.1在hiveContext中,hql()将被弃用,sql()将代替hql()来提交查询语句,统一了接口。
- 使用registerTempTable注册表是一个临时表,生命周期只在所定义的sqlContext或hiveContext实例之中。换而言之,在一个sqlontext(或hiveContext)中registerTempTable的表不能在另一个sqlContext(或hiveContext)中使用。
另外,Spark1.1提供了语法解析器选项spark.sql.dialect,就目前而言,Spark1.1提供了两种语法解析器:sql语法解析器和hiveql语法解析器。
- sqlContext现在只支持sql语法解析器(SQL-92语法)
- hiveContext现在支持sql语法解析器和hivesql语法解析器,默认为hivesql语法解析器,用户可以通过配置切换成sql语法解析器,来运行hiveql不支持的语法,如select 1。
- 切换可以通过下列方式完成:
- 在sqlContexet中使用setconf配置spark.sql.dialect
- 在hiveContexet中使用setconf配置spark.sql.dialect
- 在sql命令中使用 set spark.sql.dialect=value
SparkSQL1.1对数据的查询分成了2个分支:sqlContext 和 hiveContext。至于两者之间的关系,hiveSQL继承了sqlContext,所以拥有sqlontext的特性之外,还拥有自身的特性(最大的特性就是支持hive)。
2.1 启动Spark shell
2.1.1 环境设置
使用如下命令打开/etc/profile文件:
sudo vi /etc/profile
设置如下参数:
export SPARK_HOME=/app/hadoop/spark-1.1.0export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbinexport HIVE_HOME=/app/hadoop/hive-0.13.1export PATH=$PATH:$HIVE_HOME/binexport CLASSPATH=$CLASSPATH:$HIVE_HOME/bin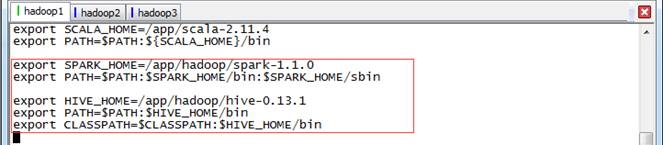
2.1.2 启动HDFS
$cd /app/hadoop/hadoop-2.2.0/sbin$./start-dfs.sh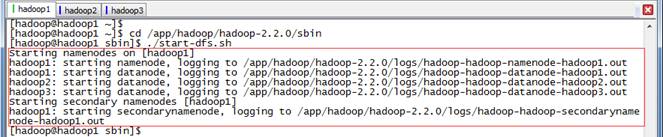
2.1.3 启动Spark集群
$cd /app/hadoop/spark-1.1.0/sbin $./start-all.sh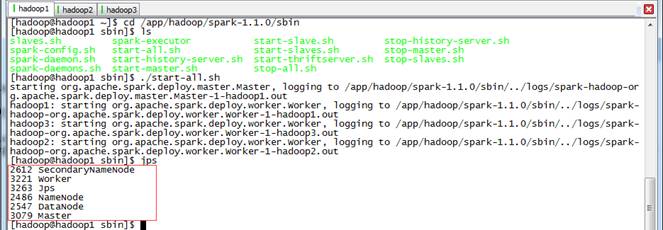
2.1.4 启动Spark-Shell
在spark客户端(在hadoop1节点),使用spark-shell连接集群
$cd /app/hadoop/spark-1.1.0/bin$./spark-shell --master spark://hadoop1:7077 --executor-memory 1g 
启动后查看启动情况,如下图所示: 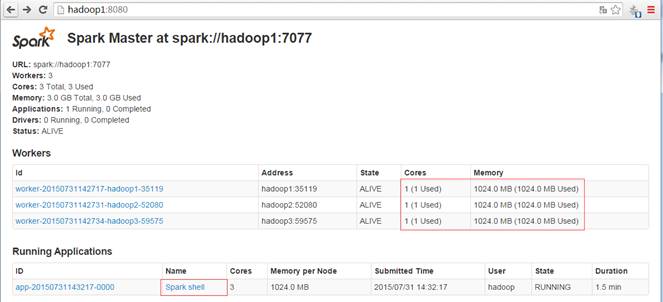
2.2 sqlContext演示
Spark1.1.0开始提供了两种方式将RDD转换成SchemaRDD:
- 通过定义Case Class,使用反射推断Schema(case class方式)
- 通过可编程接口,定义Schema,并应用到RDD上(applySchema 方式)
前者使用简单、代码简洁,适用于已知Schema的源数据上;后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
2.2.1 使用Case Class定义RDD演示
对于Case Class方式,首先要定义Case Class,在RDD的Transform过程中使用Case Class可以隐式转化成SchemaRDD,然后再使用registerTempTable注册成表。注册成表后就可以在sqlContext对表进行操作,如select 、insert、join等。注意,case class可以是嵌套的,也可以使用类似Sequences 或 Arrays之类复杂的数据类型。
下面的例子是定义一个符合数据文件/sparksql/people.txt类型的case clase(Person),然后将数据文件读入后隐式转换成SchemaRDD:people,并将people在sqlContext中注册成表rddTable,最后对表进行查询,找出年纪在13-19岁之间的人名。
第一步 上传测试数据
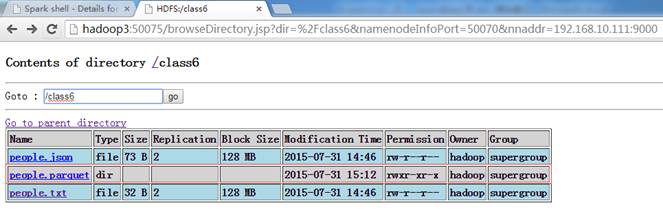
在HDFS中创建/class6目录,把配套资源/data/class5/ people.txt上传到该目录上
$hadoop fs -mkdir /class6$hadoop fs -copyFromLocal /home/hadoop/upload/class6/people.* /class6$hadoop fs -ls /
第二步 定义sqlContext并引入包
//sqlContext演示scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)scala>import sqlContext.createSchemaRDD
第三步 定义Person类,读入数据并注册为临时表
//RDD1演示scala>case class Person(name:String,age:Int)scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))scala>rddpeople.registerTempTable("rddTable")
第四步 在查询年纪在13-19岁之间的人员
scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)上面步骤均为trnsform未触发action动作,在该步骤中查询数据并打印触发了action动作,如下图所示: 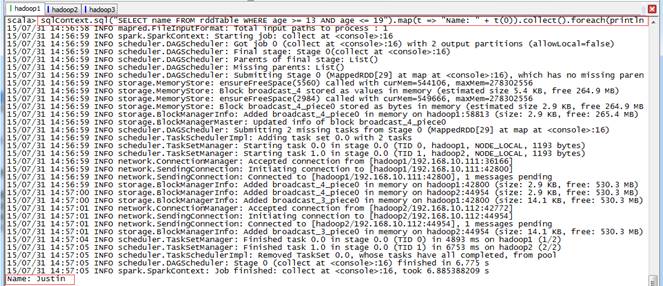
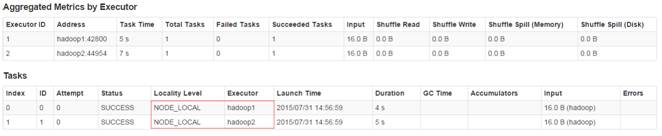
通过监控页面,查看任务运行情况: 
2.2.2 使用applySchema定义RDD演示
applySchema 方式比较复杂,通常有3步过程:
- 从源RDD创建rowRDD
- 创建与rowRDD匹配的Schema
- 将Schema通过applySchema应用到rowRDD
第一步 导入包创建Schema
//导入SparkSQL的数据类型和Rowscala>import org.apache.spark.sql._//创建于数据结构匹配的schemascala>val schemaString = "name age"scala>val schema = StructType( schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))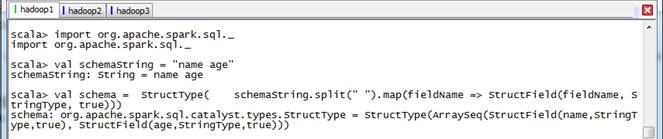
第二步 创建rowRDD并读入数据
//创建rowRDDscala>val rowRDD = sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p => Row(p(0), p(1).trim))//用applySchema将schema应用到rowRDDscala>val rddpeople2 = sqlContext.applySchema(rowRDD, schema)scala>rddpeople2.registerTempTable("rddTable2")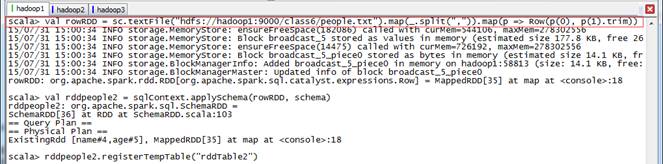
第三步 查询获取数据
scala>sqlContext.sql("SELECT name FROM rddTable2 WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
通过监控页面,查看任务运行情况:


2.2.3 parquet演示
同样得,sqlContext可以读取parquet文件,由于parquet文件中保留了schema的信息,所以不需要使用case class来隐式转换。sqlContext读入parquet文件后直接转换成SchemaRDD,也可以将SchemaRDD保存成parquet文件格式。
第一步 保存成parquest格式文件
// 把上面步骤中的rddpeople保存为parquet格式文件到hdfs中 scala>rddpeople.saveAsParquetFile("hdfs://hadoop1:9000/class6/people.parquet")
第二步 读入parquest格式文件,注册表parquetTable
//parquet演示scala>val parquetpeople = sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")scala>parquetpeople.registerTempTable("parquetTable")
第三步 查询年龄大于等于25岁的人名
scala>sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)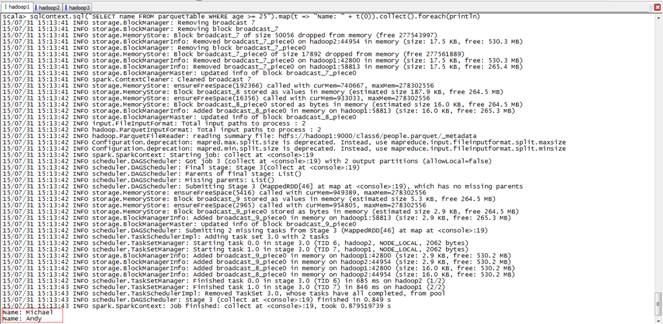
2.2.4 json演示
sparkSQL1.1.0开始提供对json文件格式的支持,这意味着开发者可以使用更多的数据源,如鼎鼎大名的NOSQL数据库MongDB等。sqlContext可以从jsonFile或jsonRDD获取schema信息,来构建SchemaRDD,注册成表后就可以使用。
- jsonFile - 加载JSON文件目录中的数据,文件的每一行是一个JSON对象
- jsonRdd - 从现有的RDD加载数据,其中RDD的每个元素包含一个JSON对象的字符串
第一步 上传测试数据 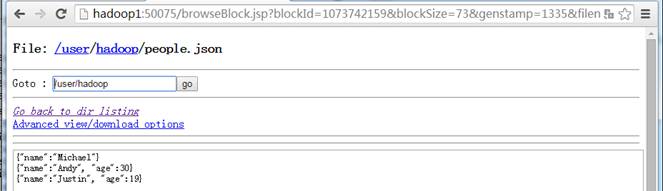
第二步 读取数据并注册jsonTable表
//json演示scala>val jsonpeople = sqlContext.jsonFile("hdfs://hadoop1:9000/class6/people.json")jsonpeople.registerTempTable("jsonTable")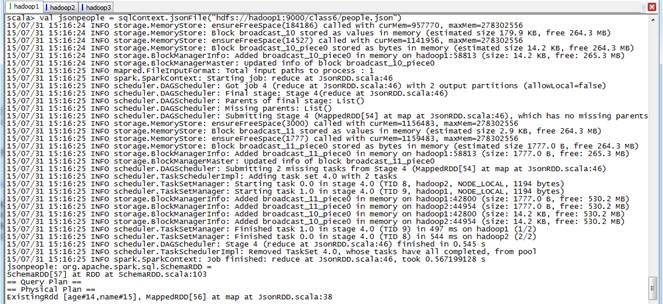
第三步 查询年龄大于等于25的人名
scala>sqlContext.sql("SELECT name FROM jsonTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)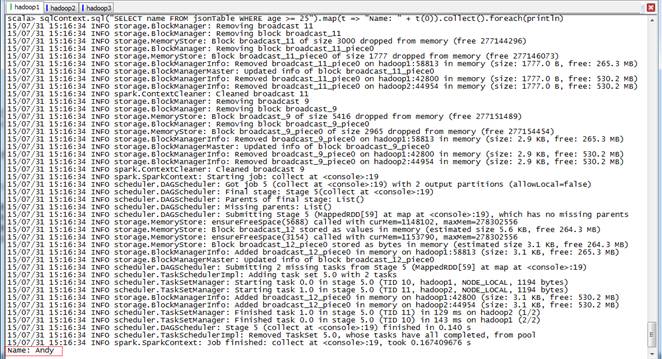
2.2.5 sqlContext中混合使用演示
在sqlContext或hiveContext中来源于不同数据源的表在各自生命周期中可以混用,即sqlContext与hiveContext之间表不能混合使用
//sqlContext中来自rdd的表rddTable和来自parquet文件的表parquetTable混合使用scala>sqlContext.sql("select a.name,a.age,b.age from rddTable a join parquetTable b on a.name=b.name").collect().foreach(println)

2.3 hiveContext演示
使用hiveContext之前首先要确认以下两点:
- 使用的Spark是支持hive
- Hive的配置文件hive-site.xml已经存在conf目录中
前者可以查看lib目录下是否存在以datanucleus开头的3个JAR来确定,后者注意是否在hive-site.xml里配置了uris来访问Hive Metastore。
2.3.1 启动hive
在hadoop1节点中使用如下命令启动Hive
$nohup hive --service metastore > metastore.log 2>&1 &
2.3.2 在SPARK_HOME/conf目录下创建hive-site.xml
在SPARK_HOME/conf目录下创建hive-site.xml文件,修改配置后需要重新启动Spark-Shell
【注】如果在第6课《SparkSQL(二)–SparkSQL简介》配置,
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://hadoop1:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property></configuration>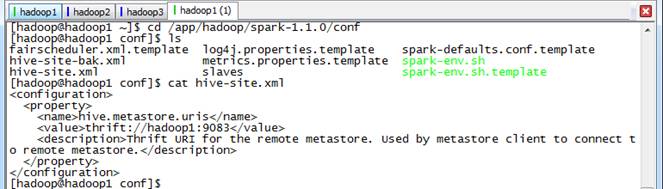
2.3.3 查看数据库表
要使用hiveContext,需要先构建hiveContext:
scala>val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
然后就可以对Hive数据进行操作了,下面我们将使用Hive中的销售数据,首先切换数据库到hive并查看有几个表:
//销售数据演示scala>hiveContext.sql("use hive")
scala>hiveContext.sql("show tables").collect().foreach(println)

2.3.4 计算所有订单中每年的销售单数、销售总额
//所有订单中每年的销售单数、销售总额//三个表连接后以count(distinct a.ordernumber)计销售单数,sum(b.amount)计销售总额scala>hiveContext.sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear").collect().foreach(println)
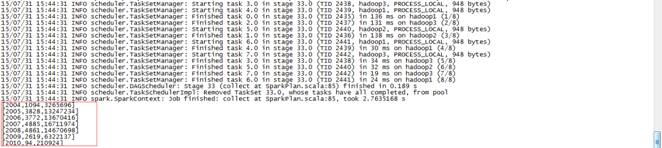
结果如下:
[2004,1094,3265696][2005,3828,13247234][2006,3772,13670416][2007,4885,16711974][2008,4861,14670698][2009,2619,6322137][2010,94,210924]通过监控页面,查看任务运行情况: 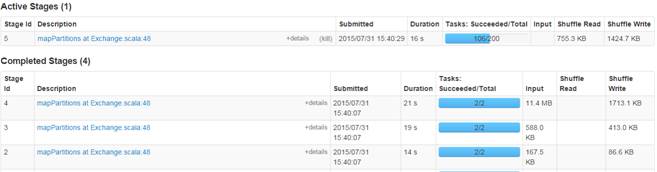
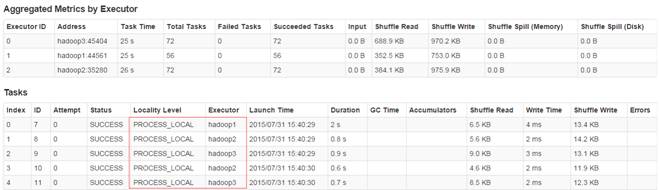
2.3.5 计算所有订单每年最大金额订单的销售额
第一步 实现分析
所有订单每年最大金额订单的销售额:
1、先求出每份订单的销售额以其发生时间
select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber 2、以第一步的查询作为子表,和表tbDate 连接,求出每年最大金额订单的销售额
select c.theyear,max(d.sumofamount) from tbDate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear第二步 实现SQL语句
scala>hiveContext.sql("select c.theyear,max(d.sumofamount) from tbDate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear").collect().foreach(println)

结果如下:
[2010,13063][2004,23612][2005,38180][2006,36124][2007,159126][2008,55828][2009,25810]第三步 监控任务运行情况 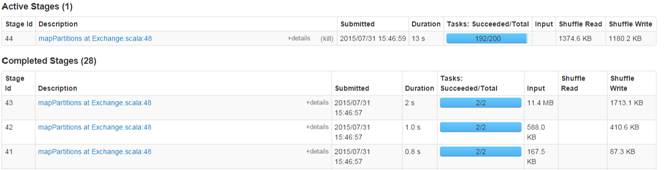
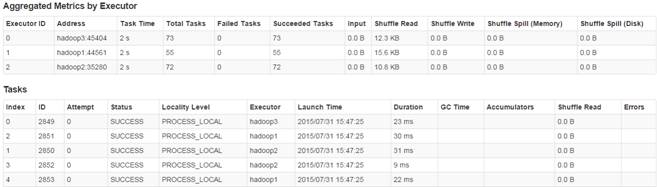
2.3.6 计算所有订单中每年最畅销货品
第一步 实现分析
所有订单中每年最畅销货品:
1、求出每年每个货品的销售金额
scala>select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid2、求出每年单品销售的最大金额
scala>select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear3、求出每年与销售额最大相符的货品就是最畅销货品
scala>select distinct e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear第二步 实现SQL语句
scala>hiveContext.sql("select distinct e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear").collect().foreach(println)
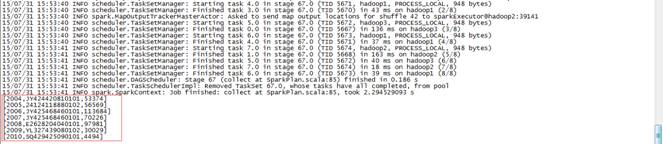
结果如下:
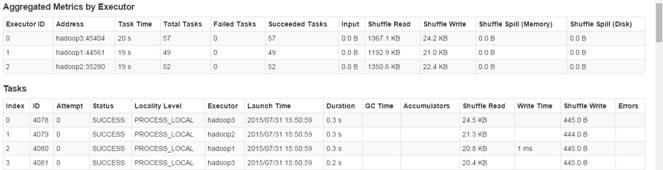
[2004,JY424420810101,53374][2005,24124118880102,56569][2006,JY425468460101,113684][2007,JY425468460101,70226][2008,E2628204040101,97981][2009,YL327439080102,30029][2010,SQ429425090101,4494]第三步 监控任务运行情况 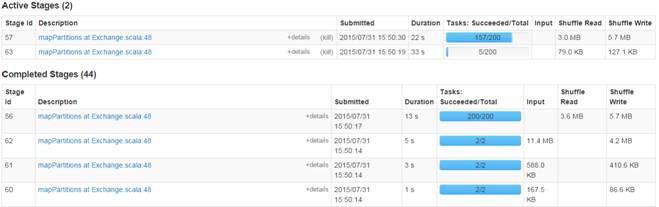
2.3.7 hiveContext中混合使用演示
第一步 创建hiveTable从本地文件系统加载数据
//创建一个hiveTable并将数据加载,注意people.txt第二列有空格,所以age取string类型scala>hiveContext.sql("CREATE TABLE hiveTable(name string,age string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ")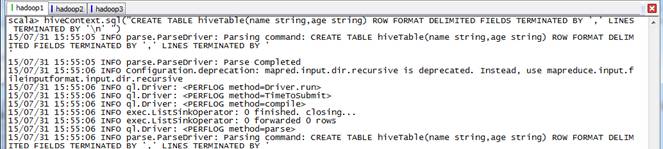
scala>hiveContext.sql("LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/people.txt' INTO TABLE hiveTable")
第二步 创建parquet表,从HDFS加载数据
//创建一个源自parquet文件的表parquetTable2,然后和hiveTable混合使用scala>hiveContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet").registerTempTable("parquetTable2")
第三步 两个表混合使用
scala>hiveContext.sql("select a.name,a.age,b.age from hiveTable a join parquetTable2 b on a.name=b.name").collect().foreach(println)

2.4 Cache使用
sparkSQL的cache可以使用两种方法来实现:
- CacheTable()方法
- CACHE TABLE命令
千万不要先使用cache SchemaRDD,然后registerAsTable;使用RDD的cache()将使用原生态的cache,而不是针对SQL优化后的内存列存储。
第一步 对rddTable表进行缓存
//cache使用scala>val sqlContext=new org.apache.spark.sql.SQLContext(sc)scala>import sqlContext.createSchemaRDDscala>case class Person(name:String,age:Int)scala>val rddpeople=sc.textFile("hdfs://hadoop1:9000/class6/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))scala>rddpeople.registerTempTable("rddTable")scala>sqlContext.cacheTable("rddTable")scala>sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
在监控界面上看到该表数据已经缓存

第二步 对parquetTable表进行缓存
scala>val parquetpeople = sqlContext.parquetFile("hdfs://hadoop1:9000/class6/people.parquet")scala>parquetpeople.registerTempTable("parquetTable")scala>sqlContext.sql("CACHE TABLE parquetTable")scala>sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)


在监控界面上看到该表数据已经缓存

第三步 解除缓存
//uncache使用scala>sqlContext.uncacheTable("rddTable")scala>sqlContext.sql("UNCACHE TABLE parquetTable")

2.5 DSL演示
SparkSQL除了支持HiveQL和SQL-92语法外,还支持DSL(Domain Specific Language)。在DSL中,使用Scala符号’+标示符表示基础表中的列,Spark的execution engine会将这些标示符隐式转换成表达式。另外可以在API中找到很多DSL相关的方法,如where()、select()、limit()等等,详细资料可以查看Catalyst模块中的DSL子模块,下面为其中定义几种常用方法:
//DSL演示scala>import sqlContext._scala>val teenagers_dsl = rddpeople.where('age >= 10).where('age <= 19).select('name)scala>teenagers_dsl.map(t => "Name: " + t(0)).collect().foreach(println)

3 Spark综合应用
Spark之所以万人瞩目,除了内存计算还有其ALL-IN-ONE的特性,实现了One stack rule them all。下面简单模拟了几个综合应用场景,不仅使用了sparkSQL,还使用了其他Spark组件:
- SQL On Spark:使用sqlContext查询年纪大于等于10岁的人名
- Hive On Spark:使用了hiveContext计算每年销售额
- 店铺分类,根据销售额对店铺分类,使用sparkSQL和MLLib聚类算法
- PageRank,计算最有价值的网页,使用sparkSQL和GraphX的PageRank算法
以下实验采用IntelliJ IDEA调试代码,最后生成LearnSpark.jar,然后使用spark-submit提交给集群运行。
3.1 SQL On Spark
3.1.1 实现代码
在src->main->scala下创建class6包,在该包中添加SQLOnSpark对象文件,具体代码如下:
import org.apache.spark.rdd.RDDimport org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.SQLContextcase class Person(name: String, age: Int)object SQLOnSpark { def main(args: Array[String]) { val conf = new SparkConf().setAppName("SQLOnSpark") val sc = new SparkContext(conf) val sqlContext = new SQLContext(sc) import sqlContext._ val people: RDD[Person] = sc.textFile("hdfs://hadoop1:9000/class6/people.txt") .map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)) people.registerTempTable("people") val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 10 and age <= 19") teenagers.map(t => "Name: " + t(0)).collect().foreach(println) sc.stop() }}
3.1.2 IDEA本地运行
先对该代码进行编译,然后运行该程序,需要注意的是在IDEA中需要在SparkConf添加setMaster(“local”)设置为本地运行。运行时可以通过运行窗口进行观察:

打印运行结果

3.1.3 生成打包文件
【注】可以参见第3课《Spark编程模型(下)–IDEA搭建及实战》进行打包
第一步 配置打包信息
在项目结构界面中选择”Artifacts”,在右边操作界面选择绿色”+”号,选择添加JAR包的”From modules with dependencies”方式,出现如下界面,在该界面中选择主函数入口为SQLOnSpark:

第二步 填写该JAR包名称和调整输出内容
打包路径为/home/hadoop/IdeaProjects/out/artifacts/LearnSpark_jar
【注意】的是默认情况下”Output Layout”会附带Scala相关的类包,由于运行环境已经有Scala相关类包,所以在这里去除这些包只保留项目的输出内容

第三步 输出打包文件
点击菜单Build->Build Artifacts,弹出选择动作,选择Build或者Rebuild动作

第四步 复制打包文件到Spark根目录下
cd /home/hadoop/IdeaProjects/out/artifacts/LearnSpark_jarcp LearnSpark.jar /app/hadoop/spark-1.1.0/ll /app/hadoop/spark-1.1.0/
3.1.4 运行查看结果
通过如下命令调用打包中的SQLOnSpark方法,运行结果如下:
cd /app/hadoop/spark-1.1.0bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLOnSpark --executor-memory 1g LearnSpark.jar

3.2 Hive On Spark
3.2.1 实现代码
在class6包中添加HiveOnSpark对象文件,具体代码如下:
import org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.hive.HiveContextobject HiveOnSpark { case class Record(key: Int, value: String) def main(args: Array[String]) { val sparkConf = new SparkConf().setAppName("HiveOnSpark") val sc = new SparkContext(sparkConf) val hiveContext = new HiveContext(sc) import hiveContext._ sql("use hive")sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber join tbDate c on a.dateid=c.dateid group by c.theyear order by c.theyear") .collect().foreach(println) sc.stop() }}
3.2.2 生成打包文件
按照3.1.3SQL On Spark方法进行打包
3.2.3 运行查看结果
【注】需要启动Hive服务,参见2.3.1
通过如下命令调用打包中的SQLOnSpark方法,运行结果如下:
cd /app/hadoop/spark-1.1.0bin/spark-submit --master spark://hadoop1:7077 --class class6.HiveOnSpark --executor-memory 1g LearnSpark.jar

通过监控页面看到名为HiveOnSpark的作业运行情况:


3.3 店铺分类
分类在实际应用中非常普遍,比如对客户进行分类、对店铺进行分类等等,对不同类别采取不同的策略,可以有效的降低企业的营运成本、增加收入。机器学习中的聚类就是一种根据不同的特征数据,结合用户指定的类别数量,将数据分成几个类的方法。下面举个简单的例子,按照销售数量和销售金额这两个特征数据,进行聚类,分出3个等级的店铺。
3.3.1 实现代码
import org.apache.log4j.{Level, Logger}import org.apache.spark.sql.catalyst.expressions.Rowimport org.apache.spark.{SparkConf, SparkContext}import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.mllib.clustering.KMeansimport org.apache.spark.mllib.linalg.Vectorsobject SQLMLlib { def main(args: Array[String]) { //屏蔽不必要的日志显示在终端上 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) //设置运行环境 val sparkConf = new SparkConf().setAppName("SQLMLlib") val sc = new SparkContext(sparkConf) val hiveContext = new HiveContext(sc) //使用sparksql查出每个店的销售数量和金额 hiveContext.sql("use hive") hiveContext.sql("SET spark.sql.shuffle.partitions=20") val sqldata = hiveContext.sql("select a.locationid, sum(b.qty) totalqty,sum(b.amount) totalamount from tbStock a join tbStockDetail b on a.ordernumber=b.ordernumber group by a.locationid") //将查询数据转换成向量 val parsedData = sqldata.map { case Row(_, totalqty, totalamount) => val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble) Vectors.dense(features) } //对数据集聚类,3个类,20次迭代,形成数据模型 //注意这里会使用设置的partition数20 val numClusters = 3 val numIterations = 20 val model = KMeans.train(parsedData, numClusters, numIterations) //用模型对读入的数据进行分类,并输出 //由于partition没设置,输出为200个小文件,可以使用bin/hdfs dfs -getmerge 合并下载到本地 val result2 = sqldata.map { case Row(locationid, totalqty, totalamount) => val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble) val linevectore = Vectors.dense(features) val prediction = model.predict(linevectore) locationid + " " + totalqty + " " + totalamount + " " + prediction }.saveAsTextFile(args(0)) sc.stop() }}
3.3.2 生成打包文件
按照3.1.3SQL On Spark方法进行打包
3.3.3 运行查看结果
通过如下命令调用打包中的SQLOnSpark方法:
cd /app/hadoop/spark-1.1.0bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLMLlib --executor-memory 1g LearnSpark.jar /class6/output1
运行过程,可以发现聚类过程都是使用20个partition:

查看运行结果,分为20个文件存放在HDFS中

使用getmerge将结果转到本地文件,并查看结果:
cd /home/hadoop/uploadhdfs dfs -getmerge /class6/output1 result.txt
最后使用R做示意图,用3种不同的颜色表示不同的类别。

3.4 PageRank
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名,是Google创始人拉里?佩奇和谢尔盖?布林于1997年构建早期的搜索系统原型时提出的链接分析算法。目前很多重要的链接分析算法都是在PageRank算法基础上衍生出来的。PageRank是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。在揉合了诸如Title标识和Keywords标识等所有其它因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中令网站排名获得提升,从而提高搜索结果的相关性和质量。
Spark GraphX引入了google公司的图处理引擎pregel,可以方便的实现PageRank的计算。
3.4.1 创建表
下面实例采用的数据是wiki数据中含有Berkeley标题的网页之间连接关系,数据为两个文件:graphx-wiki-vertices.txt和graphx-wiki-edges.txt ,可以分别用于图计算的顶点和边。把这两个文件上传到本地文件系统/home/hadoop/upload/class6目录中(注:这两个文件可以从该系列附属资源/data/class6中获取)
第一步 上传数据

第二步 启动SparkSQL
参见第6课《SparkSQL(一)–SparkSQL简介》3.2.3启动SparkSQL
$cd /app/hadoop/spark-1.1.0$bin/spark-sql --master spark://hadoop1:7077 --executor-memory 1g
第三步 定义表并加载数据
创建vertices和edges两个表并加载数据:
spark-sql>show databases;spark-sql>use hive;spark-sql>CREATE TABLE vertices(ID BigInt,Title String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/graphx-wiki-vertices.txt' INTO TABLE vertices; 
spark-sql>CREATE TABLE edges(SRCID BigInt,DISTID BigInt) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; LOAD DATA LOCAL INPATH '/home/hadoop/upload/class6/graphx-wiki-edges.txt' INTO TABLE edges;
查看创建结果
spark-sql>show tables;
3.4.2 实现代码
import org.apache.log4j.{Level, Logger}import org.apache.spark.sql.hive.HiveContextimport org.apache.spark.{SparkContext, SparkConf}import org.apache.spark.graphx._import org.apache.spark.sql.catalyst.expressions.Rowobject SQLGraphX { def main(args: Array[String]) { //屏蔽日志 Logger.getLogger("org.apache.spark").setLevel(Level.WARN) Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF) //设置运行环境 val sparkConf = new SparkConf().setAppName("PageRank") val sc = new SparkContext(sparkConf) val hiveContext = new HiveContext(sc) //使用sparksql查出每个店的销售数量和金额 hiveContext.sql("use hive") val verticesdata = hiveContext.sql("select id, title from vertices") val edgesdata = hiveContext.sql("select srcid,distid from edges") //装载顶点和边 val vertices = verticesdata.map { case Row(id, title) => (id.toString.toLong, title.toString)} val edges = edgesdata.map { case Row(srcid, distid) => Edge(srcid.toString.toLong, distid.toString.toLong, 0)} //构建图 val graph = Graph(vertices, edges, "").persist() //pageRank算法里面的时候使用了cache(),故前面persist的时候只能使用MEMORY_ONLY println("**********************************************************") println("PageRank计算,获取最有价值的数据") println("**********************************************************") val prGraph = graph.pageRank(0.001).cache() val titleAndPrGraph = graph.outerJoinVertices(prGraph.vertices) { (v, title, rank) => (rank.getOrElse(0.0), title) } titleAndPrGraph.vertices.top(10) { Ordering.by((entry: (VertexId, (Double, String))) => entry._2._1) }.foreach(t => println(t._2._2 + ": " + t._2._1)) sc.stop() }}
3.4.3 生成打包文件
按照3.1.3SQL On Spark方法进行打包
3.4.4 运行查看结果
通过如下命令调用打包中的SQLOnSpark方法:
cd /app/hadoop/spark-1.1.0bin/spark-submit --master spark://hadoop1:7077 --class class6.SQLGraphX --executor-memory 1g LearnSpark.jar
运行结果:

3.5 小结
在现实数据处理过程中,这种涉及多个系统处理的场景很多。通常各个系统之间的数据通过磁盘落地再交给下一个处理系统进行处理。对于Spark来说,通过多个组件的配合,可以以流水线的方式来处理数据。从上面的代码可以看出,程序除了最后有磁盘落地外,都是在内存中计算的。避免了多个系统中交互数据的落地过程,提高了效率。这才是spark生态系统真正强大之处:One stack rule them all。另外sparkSQL+sparkStreaming可以架构当前非常热门的Lambda架构体系,为CEP提供解决方案。也正是如此强大,才吸引了广大开源爱好者的目光,促进了Spark生态的高速发展。
版权声明:本文为博主原创文章,未经博主允许不得转载。