? ? ? ? ?етМИЬьЃЌдкаДвЛИіЙигкPGSQLадФмЕФВтЪдБЈИцЁЃ
? ? ? ? НёЬьевСЫЬЈЖЅХфЕФR710зіВтЪдЁЃR710ХфжУШчЯТЃКE5-2650 v2СНПХЃЌ128GФкДцЃЌДХХЬЮЊСНПщSATAХЬзіRAID0 ЦДГіРДЕФвЛИіTЕФДХХЬЁЃ
? ? ? ? жЎЧАЭЌЪТдкЩЯУцВтЪдmysqlЕФQPSДѓИХЪЧ20WЖрЃЌОпЬхВЛЯъЁЃ
? ? ? ? БОзХМђЕЅЪдЪдЕФЯыЗЈЃЌдДТыБрвыАВзАСЫpgsqlЃЌpgsqlЕФХфжУШчЯТЃК
? ? ? ? ?
max_connections = 512shared_buffers = 30720MBmaintenance_work_mem = 512MBvacuum_cost_delay = 10vacuum_cost_limit = 10000 # 1-10000 creditsbgwriter_delay = 10ms # 10-10000ms between roundsbgwriter_lru_maxpages = 1000 # 0-1000 max buffers written/roundwal_level = hot_standby wal_writer_delay = 10ms # 1-10000 millisecondscheckpoint_segments = 256 # in logfile segments, min 1, 16MB eachcheckpoint_timeout = 10min # range 30s-1
? ?ЛљБОЩЯЖМЪЧОбщжЕЁЃshared_bufferЩшжУжївЊЪЧИљОнНЈвщЩшжУЮЊФкДцЕФ20%ЩЯЯТ
?
? ?ШЛКѓЪЙгУpgbencЩњГЩСЫДѓИХ60ИіGЕФЪ§ОнЃК
pgbench -i -s 4000
? ?НсЙћАДееШчЯТЗНЪНжБНгдЫааpgbench,
?
?
pgbench -S -M prepared -c N -j N -T 60 postgres
ЦфжаЃК-SбЁЯюжИЖЈжЛжДааselectЃЌвВОЭЪЧжЛжДаа
SELECT abalance FROM pgbench_accounts WHERE aid = $1
?етбљЕФSQLЃЌpebench_acountsЪЧвЛеХДњБэЃЌЖдгІвЛИіаЧаЮФЃаЭжаЕФФЧИіДѓБэЃЌРяУцБЛВхШыСЫ4KWЬѕЪ§ОнЃЌБэЕФжїМќЪЧaidетИізжЖЮЃЌВщбЏЕФВЮЪ§ЪЧЫцЛњЩњГЩЕФЃЛ-M preparedЪЧЪЙгУдЄБрвыЕФЗНЪНжДааSQL,БмУтжиИДНтЮіSQLЃЛNЪЧСЌНгЪ§КЭФЃФтЕФПЭЛЇЖЫЃЌдкетРяЪЧУПИіПЭЛЇЖЫЪЙгУвЛИіСЌНгЃЛ?-T 60жИЖЈСЌајжДаа60УыЁЃ
дкЦєЖЏЪ§ОнПтжЎКѓЃЌЯШгУЩЯУцЕФУќСюдЫааСЫ300УыЃЌРДдЄШШЪ§ОнЁЃШЛКѓдйНјааЪЕМЪЕФВтЪд
зюКѓЗЂЯжNдк128жЎКѓЃЌдіДѓNЮоЗЈУїЯдЛёЕУИќДѓЕФQPSЃЌШчЪЧНЋNЩшжУЮЊ128ЁЃЕЋЪЧХмГіРДЕФНсЙћШУШЫИаОѕЛЙааЃЌПь20WСЫЃК
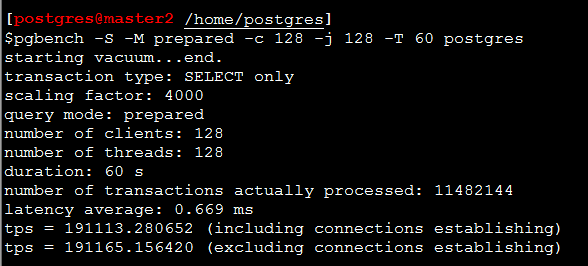
?
ВщПДСЫДХХЬЕФIOЃЌЗЂЯжВЛЖЯЕФгаЖСЕФЧыЧѓЃЌгкЪЧжБНгВщПДЪ§ОнЪ§ОнПтЕФblockУќжаТЪЃЌЗЂЯжУќжаТЪВЛИпЃЌВЛЕН90%ЃК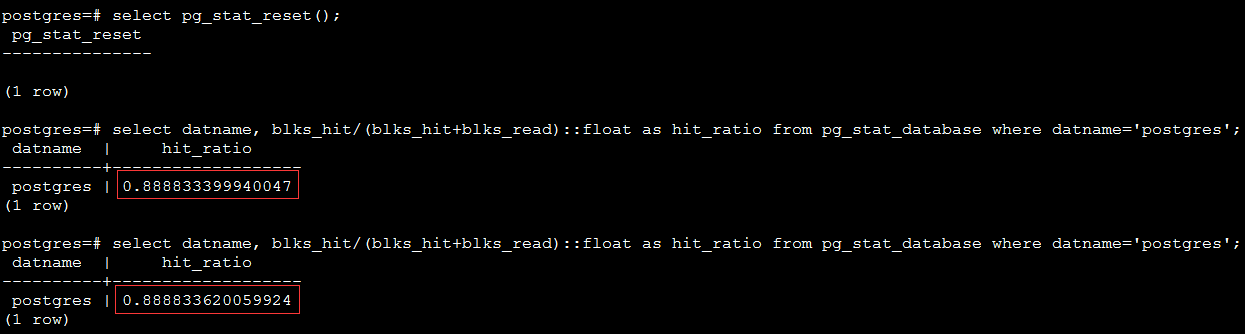
?ИаОѕжївЊЪЧУЛгаЛКДцзЁЫљгаШШЪ§ОнЃЌгаЧБСІПЩЭкЃЌгкЪЧЪдзХНЋshared_bufferЕїећЕНСЫ50GМЬајВтЪдЃЌQPSЕНСЫ26WЃЌЖјУќжаТЪвВЕНСЫ96%ЁЃЕЋЪЧЃЌЗЂЯжIOЛЙЪЧХМЖћЛсДяЕН10M/sЁЃ
? гкЪЧЃЌНЋshared_bufferЕїећЕНСЫ60GЃЌетЛљБОЩЯгІИУФмЛКДцзЁЫљгаЕФЪ§ОнСЫЁЃНсЙћTPSЕНСЫ34WЖрЃЌУќжаТЪвВЕНСЫПь100%ЃК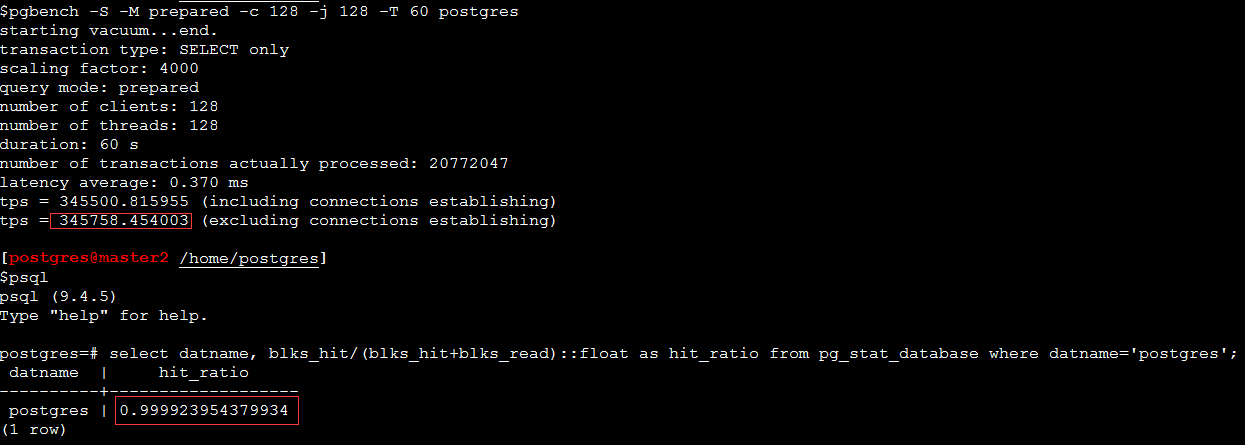
?УїЯдЃЌетИівбОЪЧзюРэЯыЕФЧщПіСЫЁЃЪ§ОнЖМдкshared bufferРяУцСЫЁЃШчЙћЛЙвЊНјвЛВНЕФЬсИпQPSЃЌдђашвЊИќЖрИќЧПЕФCPUСЫЁЃЕБШЛЃЌМЬајЕїИпshared bufferвВУЛгаБивЊСЫЃЌвђЮЊЪЕМЪЕФЪ§ОнОЭжЛга60GСЫЁЃ
? ?СэЭтЃЌФУзХupdateКЭinsertВйзїВтЪдЙ§ЃЌЪ§ОнВЛЪЧКмРэЯыЃЌжївЊЪЧвђЮЊЦПОБдкIOФмСІЩЯЃЌБЯОЙSATAХЬОрРыЪЕМЪЪЙгУЕФSSDЛЙЪЧгаВЛаЁОрРыЕФЃЌетРяОЭВЛЬљСЫЁЃ
?
?
?
?