起因:
由于最近工作需要及过去一直的疑问,所以决定着手研究一下动态SQL。由于离开一线开发有点年头了,很多技巧性的东西没有过多研究,作为DBA和《SQL Server性能优化与管理的艺术》一书的独立作者,更多的是关注在满足功能要求前提下的性能问题。但是我认为本文不仅对DBA有用,对数据库开发人员甚至设计师、架构师等都有一定的参考价值。
前言:
读者是否遇到过类似功能:一个应用程序(不管是B/S还是C/S结构),有某个/些功能,允许用户选择不同的条件来进行查询(为了简便期间,这里仅针对查询功能)。极端情况下,用户可以通过界面选择结果集的不同的展示列、列展示顺序、排序形式甚至二次查询等。这些功能使用前端编程语言实现未尝不可,有时候甚至更佳,但是前端实现毕竟需要后台数据库的支持,所以这里更加集中在数据库层面。
上面的例子中,用户看到的可能就是这样,但是作为一个开发人员,你需要考虑的东西就不仅仅是这些了,假设我们使用存储过程来实现这个功能的数据支持,那么你需要考虑的是:不同的查询条件可能需要关联不同的表,比如需要同时筛选日期和货号,这两个条件是分布在A、B两表,那么你在查询时就要进行关联。但是当用户选择筛选货号和客户名时,这些数据可能分布在B、C两表,那么你需要在同一个存储过程中进行B、C表的关联。
由于关系数据库理论的限制,你很难做到灵活构建这种逻辑的同时保持代码的简洁及高效。除了用游标加大量判断这种几乎能实现任何功能但又往往极其低效的方式之外,动态SQL就出现在我们的考虑范围里面。我们需要借助某些工具来实现两个目的:得到正确数据和获得合理的性能。
本文出处: http://blog.csdn.net/dba_huangzj/article/details/49928527
简介:
在现代信息系统中,上面的例子广泛存在。但是随之引发的一个核心问题是:在SQL Server(估计在所有RDBMS中均是),没有一个单一的执行计划可以很好地支持所有的可能的查询条件。同时你也希望SQL Server针对用户的输入进行优化。
通常在数据库层面实现这种要求的方式有两种:
1. 编写带有查询提示(如OPTION(RECOMPILE))的静态SQL,强制SQL Server每次都对查询进行编译。
2. 使用动态SQL 创建一个可以覆盖用户定义的查询条件的字符串并执行语句。
这两种方式都有适用常见,各有优缺点,不能简单地说哪个好哪个不好,本系列文章将介绍两类的相关内容。
注意:本系列将使用SQL 2008 R2并用微软示例数据库AdventureWorks2008 R2作为演示。
基础知识:
为了让读者有一些知识准备,本问先介绍一些基础知识,这些基础知识有:
- 执行计划
- 执行计划缓存
- 统计信息
- 参数嗅探(简介)
注:为了控制文章的篇幅,本系列文章不打算深入探讨上面的知识,更详细的信息可查阅本人书籍《SQL Server性能优化与管理的艺术》中相关信息。
执行计划:
当一个SQL语句(SQL语句/批 或存储过程)提交给SQL Server之后,SQL Server会先分析语句的语法,若不符合要求马上停止后续操作并返回错误信息给客户端。
当SQL语句语法分析通过之后,SQLServer会根据语句的文本在内存的计划缓存中(Plan Cache,属于内存的Buffer Pool一部分)查找是否有可用的执行计划,若有,则直接执行,若无,则进行编译阶段。编译后生成执行计划提交给存储引擎进行执行并缓存。大概流程如下:
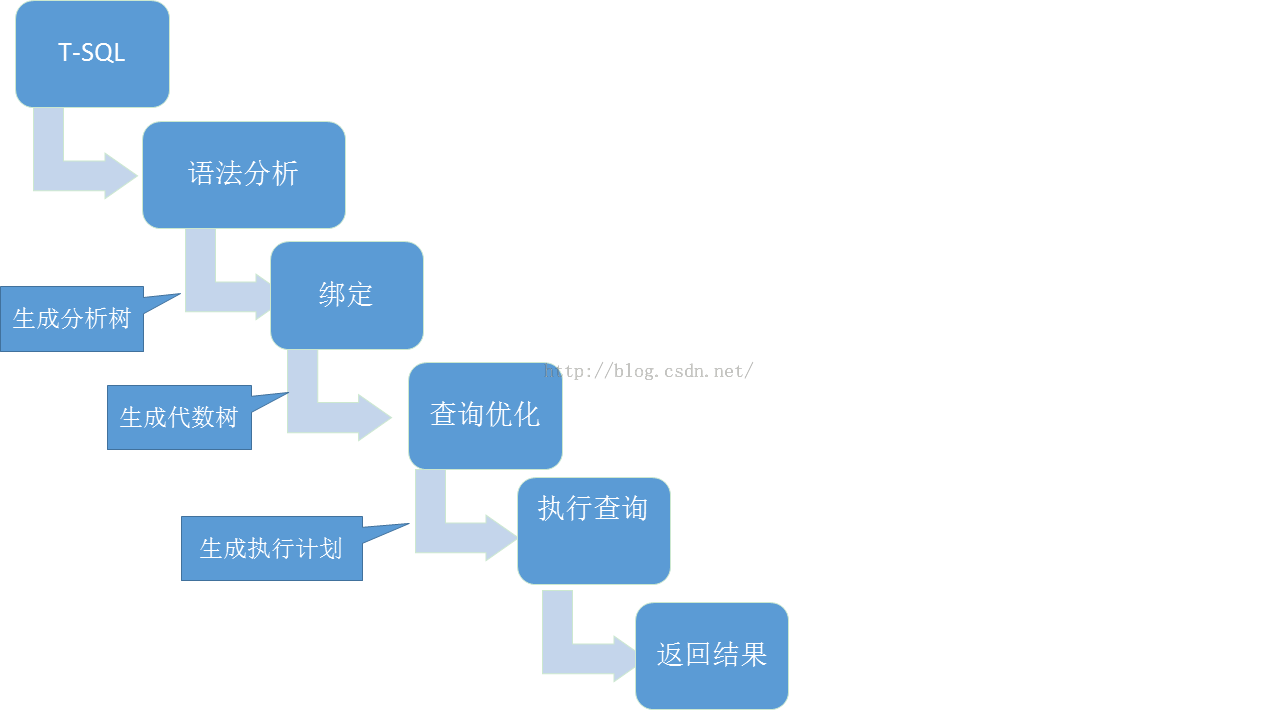
执行计划是性能的核心之一,存储引擎根据执行计划访问和返回数据给客户端,好的执行计划能高效、快速地完成数据请求,而不合理的执行计划会使一个本来很简单的请求的运行时间从几秒上升到数小时。而且执行计划也是分析性能问题的核心工具。在SQL Server Management Studio(SQL 2000叫查询分析器,SQL2005开始简称SSMS),查看执行计划可以通过快捷键:Ctrl+M(实际执行计划)和Ctrl+L(预估执行计划)来获取,也可以通过图形化界面中的下图来获取:

本文出处: http://blog.csdn.net/dba_huangzj/article/details/49928527
执行计划缓存:
在SQL Server优化器对语句进行编译和优化之后,提交给存储引擎执行,随即把执行计划缓存到内存的Plan Cache中以便后续重用。
计划缓存的最重要的目的是为了减少不必要的编译和重编译,这两个操作在负载很大的系统中会带来明显的CPU压力。如果在一个一秒钟某个存储过程会被调用超百次的系统中,避免一个只需要5ms的编译过程,可以使存储过程的执行计划从5分钟降到100ms。
另外计划缓存与语句的文本有密切关系,后续会介绍,对于下面两个语句,他们的执行计划是可以被重用的:
SELECT ID,A,B FROM TB WHERE ID=1SELECT ID,A,B FROM TB WHERE ID=10
但是下面两个语句会被认为两个不同的语句,导致第二个语句被认为新语句而进行编译,通常会导致性能问题和资源浪费:
SELECT ID,A,BFROM TB WHERE ID=1SELECT ID,A,B FROM TB WHERE ID=10 --注意空格
对于这类问题,通常的解决方案是合理的编码规范和使用参数化查询,后续将介绍。
另外,计划缓存有先进先存的特性,假设下面一个存储过程:
CREATEPROC TEST (@ID INT)AS SELECT ID,A,B FROM TB WHERE [email protected]GO本文出处: http://blog.csdn.net/dba_huangzj/article/details/49928527
同时假设表TB上ID列的数据分布极其不均匀,比如ID=1的数据在列上占了90%,而ID=10的数据在列上只有0.01%,数据行超百万,并且有合适的索引支持。在这种情况下,针对ID=1的查询,合理的应该是进行索引扫描,而对于ID=10的查询,合理的应该是索引查找。当第一次运行存储过程并[email protected]=1为参数时,执行计划按索引扫描的方式产生并缓存,[email protected]=10为参数时,可能因为某些原因执行计划被重用,依旧使用索引扫描方式,此时你可能会明显感觉到性能降低。这种情况反之亦然。关于这个情况在后续会整理一个关于参数嗅探的系列文章中详述。
最后,计划缓存是在内存中,也就是说,它是不稳定的,重启服务/服务器或某些命令和操作都可能导致计划被刷出内存。如有必要可以定期收集并存储在专门的监控数据库中或把执行计划另存为文件。
统计信息:
统计信息是一个描述表数据的“表”,简单来说就是描述数据的数据。我们常说的数据分布,对于SQL Server来说,就是存储在统计信息中。统计信息可以是自动创建或者手动创建的,并且通常在索引创建时就会附带创建对应的统计信息。关于统计信息的详述可见《SQL Server性能优化与管理的艺术》第六章。
统计信息也是性能优化的核心,SQLServer在分析语句语法之后,会根据统计信息的内容,选择执行计划中使用什么索引及表关联的算法,统计信息的过时和不准确会严重影响执行计划生成和服务器的整体性能。
同时,在优化过程中,如果统计信息足够准确,优化器可以通过判断数据是否有需要关联从而避免不必要的表关联。系列文章的后续部分也会做演示。
提醒:现行统计信息的算法最晚从SQL2000开始沿用至今,但是从SQL 2014开始做了大改动,算法更加合理,所以如有条件,建议使用SQL 2014或后续版本。
参数嗅探:
很多地方把这个功能视为性能杀手或者一个贬义词,但是存在即合理,我们应该具体情况具体分析。那么参数嗅探是什么呢?在执行计划缓存部分已经介绍了那个例子。在一些存储过程或者其他对象中,使用了传参数的方式,但是SQL Server并不知道你在实际执行时会传入什么参数,此时SQL Server就会使用一个预估值用于生成执行计划,但是在某些情况下,SQL Server也会“嗅探”实际传入的参数,并判断缓存中的执行计划针对当前语句及其参数是否不合理,是否有必要进行重编译。
所以这种功能其实是必要的,并且很多情况是有用的。但是如果因为某些原因,在本来不需要使用的时候使用了这个功能,会导致原来很合理的执行计划被抛弃,选择不合理的执行计划,其结果就是查询运行好好的,但是突然变得奇慢无比。
总的来说,需要了解参数嗅探的本质,才能下定论。后续会专门写一个关于参数嗅探的文章,一旦发布会在本文中加入链接。
本文出处: http://blog.csdn.net/dba_huangzj/article/details/49928527
环境准备:
软件环境:SQL Server 2008 R2,最好企业版。操作系统随意。
示例数据库:AdventureWorks 2008 R2,下载地址:http://msftdbprodsamples.codeplex.com/releases/view/59211
除了上面环境,还要在数据库中构建一个存储过程的模版,说是模版,其实就是后续演示过程中,在这个模版里面添加某些语句而已:
CREATE PROCEDURE sp_Get_orders @salesorderid int = NULL, @fromdate datetime = NULL, @todate datetime = NULL, @minprice money = NULL, @maxprice money = NULL, @custid nchar(5) = NULL, @custname nvarchar(40) = NULL, @prodid int = NULL, @prodname nvarchar(40) = NULL, @employeestrvarchar(MAX) = NULL, @employeetblintlist_tbltype READONLYAS SELECT o.SalesOrderID, o.OrderDate, od.UnitPrice, od.OrderQty, c.CustomerID, per.FirstName as CustomerName,p.ProductID, p.Name as ProductName, per.BusinessEntityID as EmpolyeeIDFROM Sales.SalesOrderHeader oINNER JOIN Sales.SalesOrderDetail od ON o.SalesOrderID = od.SalesOrderIDINNER JOIN Sales.Customer c ON o.CustomerID = c.CustomerIDINNER JOIN Person.Person per on c.PersonID=per.BusinessEntityIDINNER JOIN Production.Product p ON p.ProductID = od.ProductIDWHERE ???ORDER BY o.SalesOrderIDGO
注意上面WHERE ???的意思是后续例子中将会通过增减这个 WHERE条件并创建新命名的存储过程来演示。
简要说明一下存储过程的参数:
| @salesorderid | 订单ID |
| @fromdate | 起始日期 |
| @todate | 结束日期 |
| @minprice | 最低价 |
| @maxprice | 最高价 |
| @custid | 客户ID |
| @custname | 客户名 |
| @prodid | 产品ID |
| @prodname | 产品名 |
| @employeestr | 雇员ID的字符串组合,以逗号分割 |
| @employeetbl | 雇员ID的表值参数 |
如果用户不使用任何查询条件,那么查询条件将不起筛选作用,因此需要一个单纯的EXEC SP_GET_ORDERS的方式返回所有数据库订单的功能。
通过对存储过程的改写,可以应对业务中的下面需求:
本文出处: http://blog.csdn.net/dba_huangzj/article/details/49928527
- 用户可以选择如何对结果排序。
- 依赖于输入的参数,语句可以访问不同的表或列。
- 用户可以选择比较操作符,[email protected][email protected] !=’xxxx’。
- 用户可以从输出结果中添加或移除列,也可以在聚合查询中选择聚合什么。
- 其他你能想到甚至你不能想到但客户会想到的需求。
下一篇文章:T-SQL动态查询(2)——关键字查询
- 1楼zhouzxi昨天 19:05
- 本文的描述相当清楚,希望本系列文章能够让大家对动态SQL有一个全面的了解。