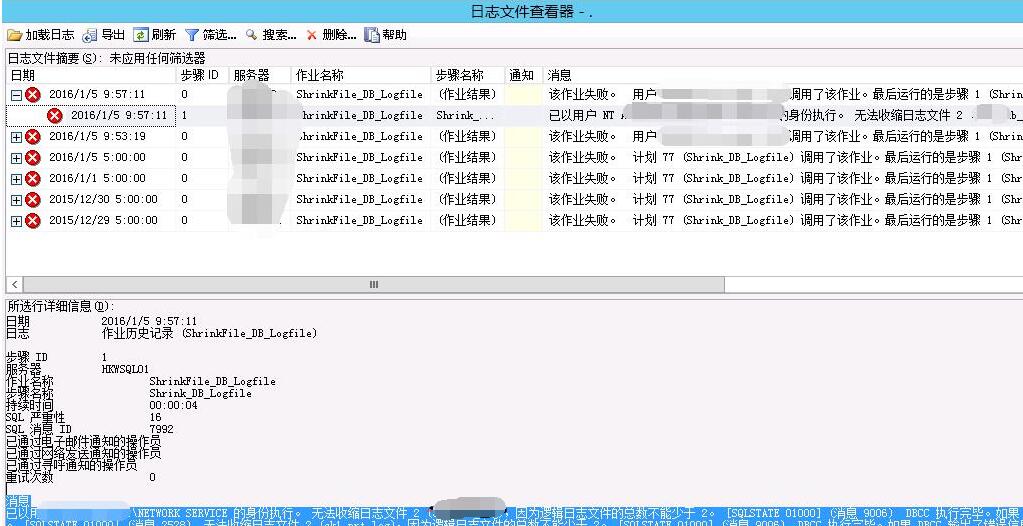
SQL Server无法收缩日志文件 2 因为逻辑日志文件的总数不能少于 2问题
最近服务器执行收缩日志文件大小的job老是报错
我所用的一个批量收缩日志脚本
USE [master]GO/****** Object: StoredProcedure [dbo].[ShrinkUser_DATABASESLogFile] Script Date: 01/05/2016 09:52:39 ******/SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGOALTER PROC [dbo].[ShrinkUser_DATABASESLogFile]ASBEGIN DECLARE @DBNAME NVARCHAR(MAX)DECLARE @SQL NVARCHAR(MAX)--临时表保存数据CREATE TABLE #DataBaseServerData( ID INT IDENTITY(1, 1) , DBNAME NVARCHAR(MAX) , Log_Total_MB DECIMAL(18, 1) NOT NULL , Log_FREE_SPACE_MB DECIMAL(18, 1) NOT NULL )--游标DECLARE @itemCur CURSORSET @itemCur = CURSOR FOR SELECT name from SYS.[databases] WHERE [name] NOT IN ('MASTER','MODEL','TEMPDB','MSDB','ReportServer','ReportServerTempDB','distribution')and state=0OPEN @itemCurFETCH NEXT FROM @itemCur INTO @DBNAMEWHILE @@FETCH_STATUS = 0 BEGIN SET @SQL=N'USE ['+@DBNAME+'];'+CHAR(10) +' DECLARE @TotalLogSpace DECIMAL(18, 1) DECLARE @FreeLogSpace DECIMAL(18, 1) DECLARE @filename NVARCHAR(MAX) DECLARE @CanshrinkSize BIGINT DECLARE @SQL1 nvarchar(MAX)SELECT @TotalLogSpace=(SUM(CONVERT(dec(17, 2), sysfiles.size)) / 128) FROM dbo.sysfiles AS sysfiles WHERE [groupid]=0SELECT @FreeLogSpace = ( SUM(( size - FILEPROPERTY(name, ''SpaceUsed'') )) )/ 128.0 FROM sys.database_files WHERE [type] = 1SELECT @filename=name FROM sys.database_files WHERE [type]=1SET @CanshrinkSize=CAST((@[email protected]) AS BIGINT) SET @SQL1 = ''USE ['+@DBNAME+']''SET @SQL1 = @SQL1+ ''DBCC SHRINKFILE (['' + @filename + ''],'' + CAST(@CanshrinkSize+1 AS NVARCHAR(MAX)) + '')'' EXEC (@SQL1)' EXEC (@SQL) FETCH NEXT FROM @itemCur INTO @DBNAME END CLOSE @itemCurDEALLOCATE @itemCurSELECT * FROM [#DataBaseServerData]DROP TABLE [#DataBaseServerData]END
幸亏报错信息还是很全面,根据报错信息找到相关的数据库,执行一下DBCC LOGINFO
dbcc loginfo(N'cdb')
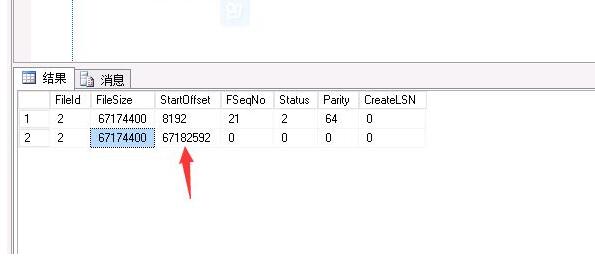
发现确实只有两个VLF文件,不能再收缩了,因为是批量脚本,当其中有一个库失败之后,后续的库就不会再进行收缩操作
这里只要加上数据库的VLF数量的判断就可以了
附上TIPS
VLF的5种状态
0、从未使用过
1、active。表示VLF中存在活动的事务(即未完成的事务)。
2、recoverable。表示VLF中的事务全部已经完成,但是某些操作(例如数据库镜像、复制等)还需要用到这些数据,因此不可以被覆盖。
3、reusable。表示VLF中的数据已经不需要了,可以被覆盖。
4、unused。表示VLF从未被使用。
创建数据库的时候,指定LDF文件可以大一点,比如指定大于1G,LDF文件自动增长指定一次增长200MB
这样就有足够的VLF给你收缩了

如有不对的地方,欢迎大家拍砖o(∩_∩)o