问题来源于这个帖子,
http://bbs.csdn.net/topics/390698376
主要涉及的问题就是“存储过程执行慢,单独执行sql快”的疑问
参数嗅探的原因以及执行计划的生成过程之前也多多少少了解过一点
只是有些问题没有深入进去,今天遇到这个帖子的问题,
又测试了一下参数嗅探问题,同时又联想到sqlserver执行计划的产生规则
所以想总结点东西出来,大家一起讨论讨论
本文不是讨论参数嗅探的优化问题的,
只是借此来讨论参数嗅探及其“存储过程执行慢,单独执行sql快”产生的原因
先说明一下我的测试过程吧
create table TestSniff
(
id int,
cloumn1 varchar(50),
cloumn2 varchar(50),
cloumn3 varchar(50),
cloumn4 varchar(50)
)
truncate table TestSniff
--生成不均匀的数据分布,id=10的占整个表的10%
declare @i int
set @i=1
while @i<10000
begin
if(@i%10=0)
begin
insert into TestSniff values(10,NEWID(),NEWID(),NEWID(),NEWID())
end
else
begin
insert into TestSniff values(@i,NEWID(),NEWID(),NEWID(),NEWID())
end;
set @i=@i+1
end
--id上建索引
create index index_id on testSniff(id)
set statistics profile on
set statistics io on
--因为10的分布占了整个表的10%,
--select * from TestSniff where id=10;走表扫描是正确的选择
--为了验证,看了一下强制走索引,其代价也明显大于表扫描
--select * from TestSniff with(index(index_id)) where id=10;
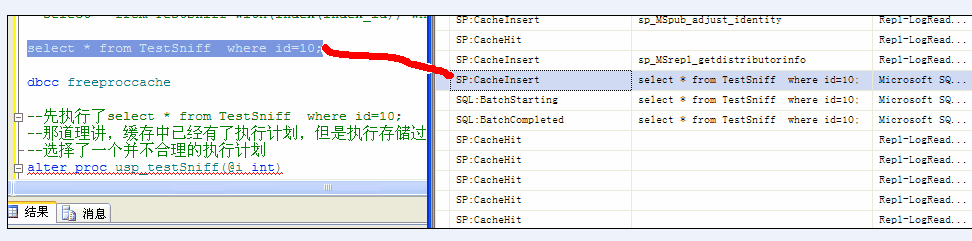
select * from TestSniff where id=10;
--这没问题,第一次执行,产生了一个缓存计划
create proc usp_testSniff(@i int)
as
declare @tmp int
set @tmp=@i
select * from TestSniff where id = @tmp --option(recompile)
--注意,执行select * from TestSniff where id=10;之后没有清楚计划缓存
--先执行了select * from TestSniff where id=10;
--那道理讲,缓存中已经有了执行计划,但是执行存储过程中,又重新编译了,
--选择了一个并不合理的执行计划
exec usp_testSniff 10

以前总是说,sqlserver生成计划的时候,是“完全一致”的sql才能重用计划
这里总算是又一次理解了这句话,
虽然缓存中有select * from TestSniff where id=10;执行而存储的计划缓存
但是select * from TestSniff where id=10;跟usp_testSniff中的sql是不完全一样的
所以执行存储过程前,还要重新编译
--再次执行
exec usp_testSniff 10
--这次才利用到计划缓存,可惜是上次生成的不合理的计划缓存

存储过程重编译也就算了,为什么没有生成一个合理的执行计划呢?
其实sqlserver生成执行计划的过程,当判断不了参数时,也是基于“猜测的”
比如说,他发现id上有索引,但是不知道具体的参数,那就根据猜测,走索引查找吧
尽管这种猜测可能不完全合理,
但是,对于大多数情况来说,比如执行其他9999个id不是10的查询,
走索引查找,是比较合理的
但是,正如这里,遇到数据分布不均匀的情况下,就悲剧了
那么这种猜测的根据是什么呢?
昨晚上也是用手机翻阅之前SQL_Beginner的一个精华帖
http://bbs.csdn.net/topics/390667246
54楼发现了这个,这里借用一下
SELECT* from @tb OPTION(RECOMPILE)
--为什么 Estimated Rowcount为1024?
--因为总共就插入了1024行,插入之后再次评估它的行数,就能得它比较准确的值。
SELECT* from @tb where [C1] like '1' OPTION(RECOMPILE)
--为什么 Estimated Rowcount为102.4?
--对于不模糊的like,Estimated Rowcount=total count *10%=1024*10%=102.4
Estimated RowcountSELECT* from @tb where [C1] Not like '1' OPTION(RECOMPILE)
--为什么 Estimated Rowcount为921.6?
--Not like 的 Estimated Rowcount=total count -like Estimated Rowcount=1024-102.4=921.6
SELECT* from @tb where [C1] between '1' and '2' OPTION(RECOMPILE)
--为什么 Estimated Rowcount为92.16?
--对于between 的Estimated Rowcount=total count *9%=1024*9%=92.16
SELECT * from @tb where [C1] not between '1' and '2' OPTION(RECOMPILE)
--为什么 Estimated Rowcount为522.24?
--not between 的Estimated Rowcount为total count *51%=522.24
SELECT* from @tb where [C5]=1 OPTION(RECOMPILE)
--为什么 Estimated Rowcount为512?
--[C5]的类型为 bit NOT NULL,所以有2种值,所以Estimated Rowcount=total count *1/2=512
SELECT* from @tb where [C4]=1 OPTION(RECOMPILE)
--为什么 Estimated Rowcount为337.92?
[C4]的类型为 bit NULL,所以有3种值的可能,所以
Estimated Rowcount=total count *1/3=337.92
SELECT* from @tb where [C2]< getdate() OPTION(RECOMPILE)
--为什么 Estimated Rowcount为307.2?
--一般对于>或者<Estimated Rowcount为 Estimated Rowcount*30%=307.2"
------解决方案--------------------
你把执行顺序反过来试试,先sp再ad hoc,另外也不是说完全一样的sql才行,空格是忽略的
------解决方案--------------------
楼主很强大,研究比较深入,遇到问题有时我们就缺乏刨根问底的精神
------解决方案--------------------
--这次才利用到计划缓存,可惜是上次生成的不合理的计划缓存
其实,我觉得,之所以还是会用上次生成的“不合理”的计划缓存,是因为,存储过程不像一般的语句,也每个命名,sql server不知道哪些语句是一样的,其实就是参数变了一下。
而存储过程的好处在于,他有名称,比如abc,那么sql server 根据exec的语法,以及这个名称,就能知道是存储过程,通过这个具体的名称abc,就能找到这个计划缓存。
而普通的sql语句,一般系统会对这段sql进行hash,然后再计划缓存中去查找,hash值是一样的,所对应的计划缓存,一般的空格,比如多了一个空格,少一个空格,都能自动忽略,产生一样的hash值,但如果你写的语句: