дкЩЯДЮ<INDEX--ДгЪ§ОнДцЗХЕФНЧЖШПДЫїв§>жаЃЌЮвУЧЫЕЕН"ЮЈвЛЗЧОлМЏЫїв§"КЭ“ЗЧЮЈвЛЗЧОл̏ۿ⧔дкДцДЂЩЯгавЛИіУїЯдЕФВюБ№ЃКЮЈвЛЗЧОлМЏЫїв§ЕФЗЧвЖзгНкЕуЩЯВЛЛсАќКЌRIDЕФЪ§ОнЃЌШУЮвУЧМЬајРДЩюЭквЛЯТЁЃ
зМБИВтЪдЪ§ОнЃК
CREATE TABLE TB1( C1 INT, C2 INT, C3 INT)GOCREATE UNIQUE CLUSTERED INDEX IDX_C1 ON TB1(C1)GOCREATE UNIQUE INDEX IDX_C2 ON TB1(C2)GOCREATE INDEX IDX_C3 ON TB1(C3)GOINSERT INTO TB1(C1,C2,C3)VALUES(1,1,1)GOINSERT INTO TB1(C1,C2,C3)VALUES(2,2,2)GOINSERT INTO TB1(C1,C2,C3)VALUES(3,3,3)
Ыїв§БрКХШчЯТЃК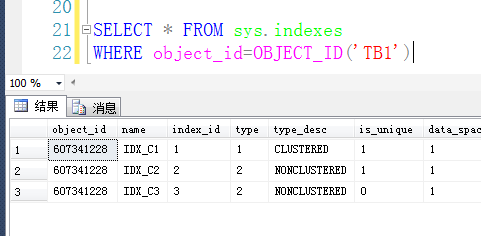
дйЭЈЙ§DBCC INDКЭDBCC PAGEРДВщПДвГЧщПі
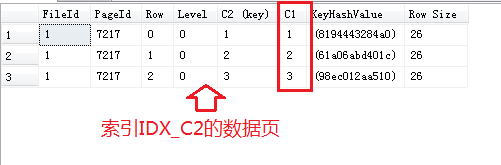
ЮЈвЛЗЧОлМЏЫїв§IDX_C2ЕФЪ§ОнвГЃК
ЗЧЮЈвЛЗЧОлМЏЫїв§IDX_C3ЕФЪ§ОнвГЃК

вдЩЯСНеХЭМгаИіУїЯдЕФЧјБ№ЪЧC1КЭC1(key)ЃЌФбЕРдк“ЗЧЮЈвЛЗЧОл̏ۿ⧔жаЃЌ“ОлМЏЫїв§Мќ”вВБЛЗХЕН“ЗЧОлМЏЫїв§Мќ”жаВЂЧвВЮгыХХађРВЃП
ЯраХКмЖрDBAЕФХѓгбЖМгіЕНетбљЕФЮЪЬтЃЌвЊАДееФГаЉзДЬЌжЕРДВщевЪ§ОнЃЌЖјетаЉзДЬЌжЕЪЧвЛИіКмаЁЕФМЏКЯ(Ъ§СПКмаЁ)ЃЌШчВщевзДЬЌжЕЮЊ1ЕФзюДѓЖЉЕЅКХ
SELECT TOP(1)* FROM dbo.OrdersWHERE OrderState=1ORDER BY OrderID DESC
ЫфШЛOrderIDЮЊжїМќКЭЮЈвЛОлМЏЫїв§ЃЌЕЋАДееOrderIDРДВщевЃЌПЩФмашвЊНјааДѓЗЖЮЇCLUSTERED INDEX SEEKВХФмевЕНТњзуЬѕМўOrderState=1ЕФЪ§ОнЃЌвђДЫОЁЙмOrderStateЕФПЩбЁдёадНЯЕЭЃЌЮвУЧЛЙЪЧЛсЖдЦфНЈСЂЫїв§ЃЌФЧУДЮЪЬтРДСЫЃПЮвУЧЫїв§ИУНЈГЩЪВУДбљФиЃП
ЪЧНЈГЩЃК
CREATE INDEX IDX_OrderStateON dbo.Orders( OrderState)
ЛЙЪЧНЈГЩЃК
CREATE INDEX IDX_OrderStateON dbo.Orders( OrderState, OrderID)
дјОЮвЯыЕБШЛЕиШЯЮЊБиаыНЈГЩЕкЖўжжЗНЪНЃЌвђЮЊЛЙашвЊЖдOrderIDНјааХХађШЁTOP(1),ЕЋОЙ§ВтЪдЃЌЩёЦцЕиЗЂЯжСНжжЗНЪНЕФаЇТЪвЛбљЃЌЮоТл“ЗЧЮЈвЛЗЧОлМЏЫїв§Мќ”РягаУЛгаАќКЌ“ОлМЏЫїв§Мќ”ЃЌЖМЛсЖд“ЗЧЮЈвЛЗЧОлМЏЫїв§Мќ”+“ОлМЏЫїв§Мќ”НјааХХађЁЃ
ЫМПМетбљвЛИіЮЪЬтЃЌМйЩшЖд“ЗЧЮЈвЛЗЧОлМЏЫїв§Мќ”ЃЌНіНіЖдЦфЖЈвхЕФМќНјааХХађЃЌШчOrderStateЃЌЖјТњзуOrderState=0ЕФПЩФмга1вкЪ§ОнЃЌдкНјааЪ§ОнИќаТЕФЪБКђЃЌЪзЯШИќаТОлМЏЫїв§ЃЌВЂвРДЮИќаТЗЧОлМЏЫїв§ЃЌИќаТЫїв§Ъ§ОнЪзЯШвЊЖЈЮЛЪ§ОнааВХФмИќаТЃЌвђДЫашвЊЩЈУшет1вкЪ§ОнВХФмевЕНФПБъааЃЌЯдШЛетЪЧВЛПЩНгЪмЕФЩшМЦЁЃ
Ждгк"ЮЈвЛЗЧОлМЏЫїв§"РДЫЕЃЌвђЮЊПЩвдЭЈЙ§Ыїв§МќБуПЩвдПьЫйЖЈЮЛЕНЫїв§Ъ§ОнааЃЌЧвУПИіМќжЕжЛЛсДцдквЛааЃЌвђДЫЪЇШЅСЫЖд“ОлМЏЫїв§Мќ”НјааХХађЕФвтвхЁЃ
BTW, вВПЩвдЭЈЙ§ЙлВьЯрЭЌМќжЕЯТааЮЛжУ(slotid)КЭВхШыЫГађРДЗЂЯжЪ§ОнАДееОлМЏЫїв§МќХХађЁЃ
--===========================================================================
змНсЃК
1. Ждгк“ЗЧЮЈвЛЗЧОл̏ۿ⧔ЃЌЫїв§Ъ§ОнЪЕМЪЩЯЪЧАДее“ЗЧЮЈвЛЗЧОлМЏЫїв§Мќ”+“ОлМЏЫїв§Мќ”НјааХХађКѓДцЗХЕФЃЛ
2. Ждгк“ЮЈвЛЗЧОл̏ۿ⧔ЃЌЫїв§Ъ§ОнЪЕМЪЩЯЪЧАДее“ЮЈвЛЗЧОлМЏЫїв§Мќ”НјааХХађКѓДцЗХЕФЃЛ
3. ЫљгаЗЧОлМЏЫїв§ЕФвЖзгНкЕуЩЯЖМЛсДцЗХRIDЕФЪ§ОнЃЌЕЋЮЈвЛЗЧОлМЏЫїв§ЕФЗЧвЖзгНкЕуЩЯВЛЛсАќКЌRIDЕФЪ§ОнЃЛ
--===========================================================================
КУКУЖСЪщЁЃЁЃЁЃ

- 1ТЅЭђНЃЦыЗЂ
- ИпДѓЪІбаОПЕУетУДЭэ.ПДСЫБиаыЖЅЦ№.