在上一个文章里,我们理解了有聚集索引表和没有聚集索引表之间的区别。有聚集索引的表叫聚集表。没有聚集索引的表叫堆表(heap table)。
堆表(heap table)
- 没有聚集索引的表
- 堆表在sys.partitions里有1条index_id = 0 的记录
- 数据存储没有任何的顺序,插入数据也没顺序
- 由于数据没有任何顺序,查询数据会非常慢
- 数据页之间没有相互链接
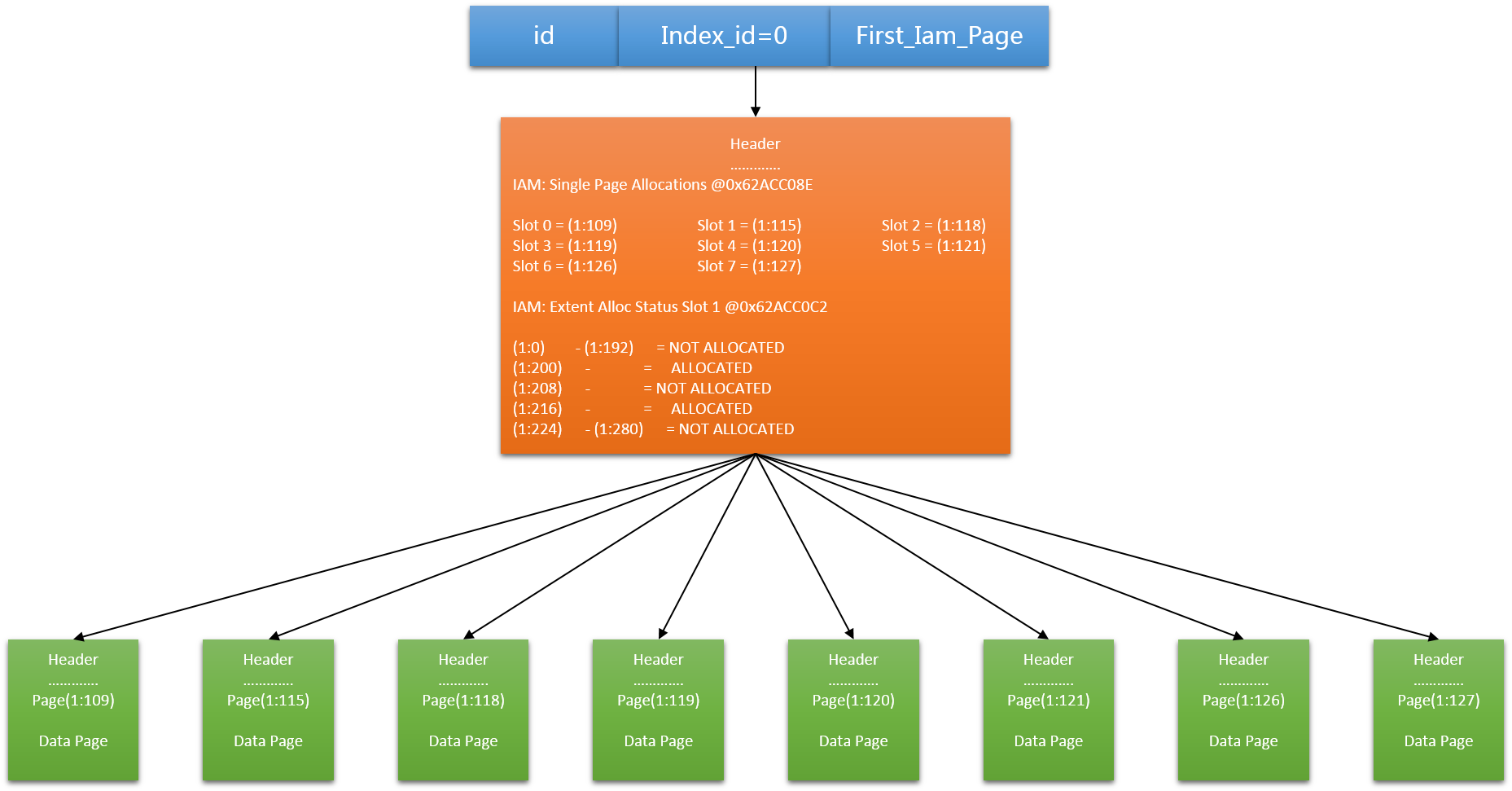
- 从数据页读取数据,需要从IAM(Index Allocation Map)页里找页号
- 在sys.system_internals_allocation_units系统视图里,first_iam_page列,指向IAM页链中的第一个IAM页,它用来管理堆表的空间分配
- 因为没有聚集索引,碎片不能通过重建索引(rebuilding the index)处理
- SQL Server使用IAM页在堆结构里导航。分配给堆的页没有任何的顺序,且不相互链接。数据页之间唯一的逻辑关联是存在IAM页里的信息。
每个IAM页存储单个对象的分配(单个页或区分配)信息。堆表的表扫描是通过扫描IAM页,找到保存堆表数据的对应页或区来完成。
使用下列命令可以获得IAM页。
1 DBCC IND('databasename','Tablename',-1)
上述查询的输出结果里,Page Type列值为10的记录就是IAM页。
堆的结构如下图所示: