今天我们来探讨下聚集索引的设计要求。在选择聚集索引键时,有好几点需要考虑的。选择聚集索引键没有硬性规定。多实践,多从网上找问题的答案都会帮你找到正确的索引键。
唯一性(Uniqueness)
SQL Server允许你在非唯一列创建聚集索引,但是唯一性是任何索引最理想的属性,尤其对于聚集索引。即使SQL Server允许在非唯一列创建聚集索引,在内部,SQL Server会为所有聚集索引键的重复值增加4 bytes的值,这个4 bytes 变长列就是所谓的uniquifiers。在这个情况下,SQL Server会聚集键当作在聚集索引上定义的非唯一列和内部生成的uniquifiers列的组合。这个值在每个聚集索引键都会保存。例如在聚集表上定义的非聚集索引的叶子层。
我们来看一个例子,创建SalesOrderDetail表的副本,并在productid 列(包含重复值)上定义一个聚集索引。
1 Use IndexDB2 GO3 SELECT * INTO dbo.SalesOrderDetailDupCI FROM AdventureWorks2008r2.Sales.SalesOrderDetail4 GO5 CREATE CLUSTERED INDEX ix_SalesOrderDetailDupCI ON dbo.SalesOrderDetailDupCI(ProductId)
我们通过DBCC INC命令看看它的分配页,并找出它的根页:
1 DBCC IND('IndexDB','SalesOrderDetailDupCI',1)2 3 TRUNCATE TABLE dbo.sp_table_pages4 INSERT INTO sp_table_pages EXEC('DBCC IND(IndexDB,SalesOrderDetailDupCI,1)')5 GO6 7 SELECT * FROM dbo.sp_table_pages ORDER BY IndexLevel DESC --根节点/索引页

可以看到5650页是根页(indexlevel列值为最大值2),我们用DBCC PAGE命令看下根页的内容。
1 DBCC TRACEON(3604)2 DBCC PAGE(IndexDB,1,5650,3)
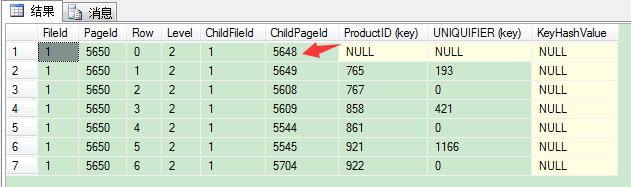
再用DBCC PAGE看看中间页5648的内容:
1 DBCC TRACEON(3604)2 DBCC PAGE(IndexDB,1,5648,3)
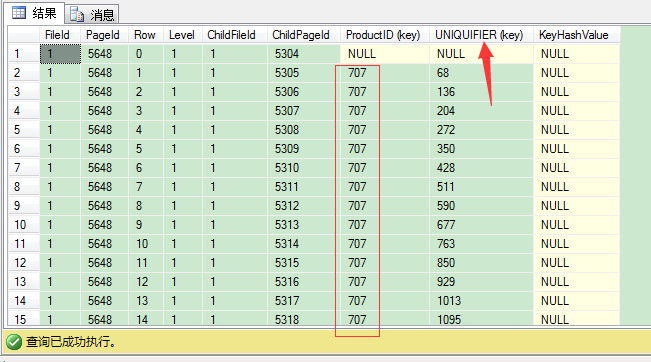
可以看到,我们的中间级的索引页额外增加了UNIQUIFIER列,用来保证聚集索引键productid的唯一性。当聚集索引创建在非唯一列时,SQL Server会为重复出现的聚集键增加4 bytes的随机值,不重复的键不增加(第一条记录productid为NULL,是唯一不重复的,故UNIQUIFIER值也是NULL)。因此定义在非唯一列的聚集索引会额外生成UNIQUIFIER值,也就增加了聚集键的长度。productid列为int,长度为4 bytes,加上4 bytes的UNIQUIFIER,我们聚集键的长度也就变成了8 bytes。这个组合会复制到所有非聚集索引的叶子节点。当在非唯一列的聚集索引上创建非聚集索引时,这个问题会加剧,聚集索引值同样要保存到非叶子层的页里去。(下篇文章我们会讨论在非唯一列的聚集索引上创建非聚集索引的问题)。
如果一个表没有一个唯一键去定义聚集索引,可以考虑再加几个小列让它变成唯一。这样会避免UNIQUIFIER的出现,减少书签查找操作,因为非聚集索引的非页层有更多的列(这额外增加的列是为了保持聚集键的唯一性)。
静态的(Static)
另外一个聚集索引键的属性是静态的。当我们在非静态列定义聚集索引时,会让UPDATE语句更加耗费资源,为了保证记录是按聚集索引的逻辑顺序保存的,它需要把记录移到不同的页,同样非聚集索引的叶子层也要更新。
即使在小表的非静态列上定义聚集索引,且又定义一个非聚集索引在它上面。任何在在聚集索引键上个更改都要改动2个页。一个数据页,还有一个非聚集索引的叶子层页。
聚集索引键大小(Size of the clustered index key)
聚集索引键的大小指的是保存聚集索引键需要的字节数。当聚集索引键大小增加是,需要更多的IO操作来获取数据。这个发生是因为如果聚集索引更宽的话,索引页就只能保存更少的索引行。这就增加了中间层的页树,还有索引的深度(B树结构的层数)。例如,把聚集索引定义在整形列的话,一个包含数百万记录的表可能只需要3层的B树结构。如果把聚集索引定义在更宽的列(包含uniqueidentifier列需要16 bytes),那么索引的深度会增加到4(索引的层数)。任何聚集索引查找需要4个IO操作,原先只要3个IO。
这个问题也会传递到非聚集索引,因为聚集索引键也保存在所有非聚集索引的叶子层,作为指针指向聚集索引。如果非聚集索引定义在非唯一列,聚集键需要保存在非聚集索引的非页层页。同样也会带来更多的中间层页,并增加非聚集索引的深度。这也就增加非聚集索引查找/扫描的IO操作。因为聚集索引的深度增加到4,每个书签查找操作也会需要4个IO操作。
连续性(Sequential)
把聚集索引定义在自增长列(连续的)是个最佳做法。因为这个原因我们经常看到聚集索引定义在标识列(identity column)。聚集索引定义在非连续列会带来碎片。一个非连续的聚集索引列会强制SQL Server把记录插在中间(in between)用来保持数据的逻辑顺序。这会导致页分裂,也是造成外部和内部碎片的原因。
总结
我们已经讨论聚集索引设计的属性要求,还有它们背后的原因。在我们决定聚集索引键时,上述讨论的几点通常是最佳做法。除此之外,数据访问模式(data access pattern)也会影响我们聚集索引键的选择。
在我们没有完全理解数据访问模式前,我们需要用不同的方法测试下性能先。