在理解统计信息(2/6):直方图 中,我们讨论了直方图,密度,还有SQL Server如何用统计信息做基数预估(cardinality estimation)。这篇文章会讨论统计信息如何被创建,还有统计信息在性能调优中的重要性。
有2类统计信息,索引统计信息和列统计信息。索引统计信息是索引创建的一部分(建立索引会自动创建索引统计信息)。在where条件列被引用或查询的group by子句里包含列,列统计信息都会由SQL Server自动创建。
有数据库属性设置里,可以设置数据库是否自动创建统计信息并自动更新统计信息(数据库属性->选项->自动)。
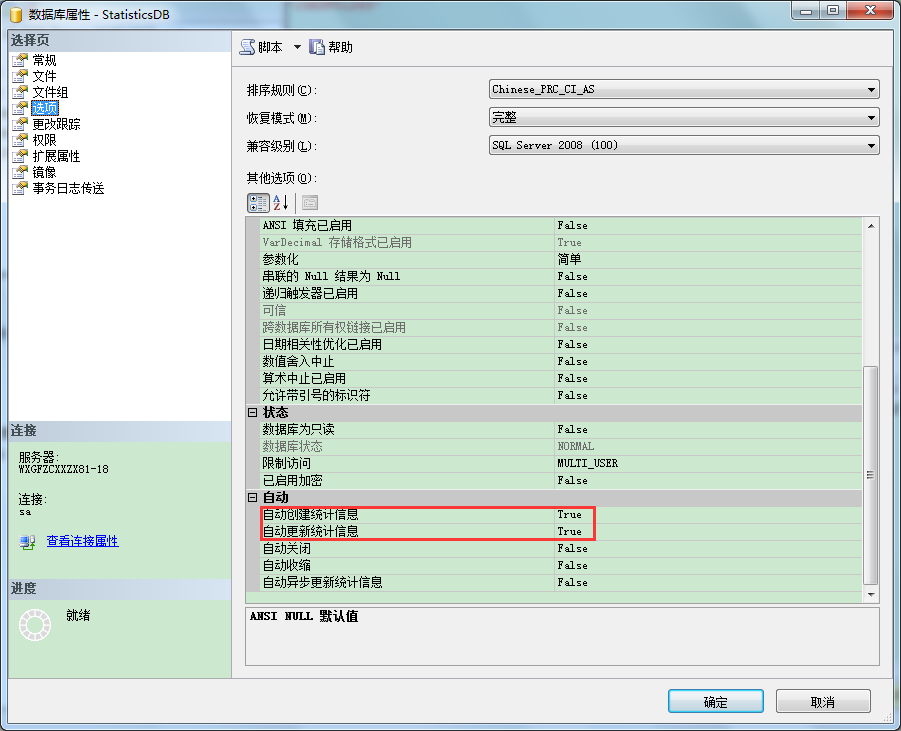
自动创建统计信息默认是启用的,它帮助查询优化器在需要更好的进行查询预估时,创建列统计信息。为了更好的性能,建议保留启用。
自动更新统计信息默认也是启用的,它帮助查询优化器在统计信息过期的时候自动更新。当数据有明显变化时,统计信息就需要更新。这里有个阀限(threshold limit)来标记统计信息是否过期。
自动异步更新统计信息默认是不启用的。当自动异步更新统计信息被启用的时候,会有2种方式进行自动更新。异步模式(默认模式),如果统计信息已经过期,查询优化器会等到计划生成完成才更新统计信息。同步模式,查询优化器会初始化统计信息,不会等到计划的生成完成。通过改变更新统计信息为同步模式可以使性能上一些工作量始终受益。SQL Server在自动创建/更新统计信息的时候,不会进行完全扫描。它只会在可接受的时间内采样数据来计算统计信息。
在理解统计信息(1/6):密度里,我们看到,当引用的列在group by或where条件里时,统计信息会自动创建。我们来看看当自动创建统计信息关掉的时候,SQL Server如何进行预估。我们运行下面的语句并看看输出结果。
1 ALTER DATABASE StatisticsDB SET AUTO_CREATE_STATISTICS OFF2 GO3 DROP TABLE SalesOrderDetail_NoStats4 SELECT * INTO SalesOrderDetail_NoStats FROM AdventureWorks2008r2.Sales.SalesOrderDetail5 GO6 SELECT ProductID,COUNT(*) FROM dbo.SalesOrderDetail_NoStats GROUP BY ProductID7 GO8 EXEC SP_HELPSTATS 'SalesOrderDetail_NoStats', 'ALL'
第1句,我们关掉了StatisticsDB数据库的自动更新统计信息。第2句,我们创建了salesOrderDetail表的副本。现在我们对ProductId进行group 扮演操作,点击工具栏的 显示包含实际的执行计划。
显示包含实际的执行计划。
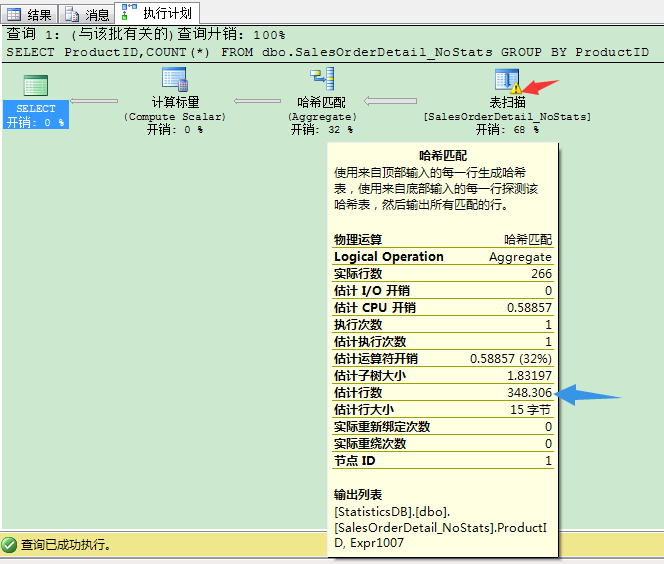
在执行计划里,我们在表扫描运算符里看到一个黄色的惊叹号。具体来说,它是警告我们没有可用的统计信息。在聚集运算符里,我们看到优化器的估计行数是348.306。没有统计信息,优化器要如何估计行数呢? 这里的值是拿记录总数开方而来。这个表有121317条记录,如果你对它开方,即 ,我们就得到348.306。如果你对这个表group by的其他任何列,预估行数还是一样的。 请注意,自动创建统计信息只控制列统计信息的自动创建。它不控制索引创建时,统计信息的自动创建。
,我们就得到348.306。如果你对这个表group by的其他任何列,预估行数还是一样的。 请注意,自动创建统计信息只控制列统计信息的自动创建。它不控制索引创建时,统计信息的自动创建。
我们来看下统计信息如何影响查询性能。来看下面2个查询,记得在最后的查询语句执行前点击工具栏的显示包含实际的执行计划。
1 USE StatisticsDB 2 GO 3 /* Part 1 WITH AUTO STATS UPDATE ON */ 4 5 ALTER DATABASE StatisticsDB SET AUTO_CREATE_STATISTICS ON 6 ALTER DATABASE StatisticsDB SET AUTO_UPDATE_STATISTICS ON 7 SET STATISTICS IO ON 8 DROP TABLE SalesOrderDetail_NoStats 9 SELECT * INTO SalesOrderDetail_NoStats FROM SalesOrderDetail10 CREATE INDEX ix_productid ON SalesOrderDetail_NoStats (productid)11 UPDATE dbo.SalesOrderDetail_NoStats SET ProductID=775 WHERE SalesOrderDetailID<>112 SELECT * FROM dbo.SalesOrderDetail_NoStats WHERE ProductID=77613 SELECT * FROM dbo.SalesOrderDetail_NoStats WHERE ProductID=77514 15 /* Part 2 WITH AUTO STATS UPDATE Off */16 17 ALTER DATABASE StatisticsDB SET AUTO_CREATE_STATISTICS OFF18 ALTER DATABASE StatisticsDB SET AUTO_UPDATE_STATISTICS OFF19 SET STATISTICS IO ON20 DROP TABLE SalesOrderDetail_NoStats 21 SELECT * INTO SalesOrderDetail_NoStats FROM SalesOrderDetail22 CREATE INDEX ix_productid ON SalesOrderDetail_NoStats (productid)23 UPDATE dbo.SalesOrderDetail_NoStats SET ProductID=775 WHERE SalesOrderDetailID<>124 --Disabling the auto update stats25 ALTER DATABASE StatisticsDB SET AUTO_UPDATE_STATISTICS OFF26 SELECT * FROM dbo.SalesOrderDetail_NoStats WHERE ProductID=77627 SELECT * FROM dbo.SalesOrderDetail_NoStats WHERE ProductID=775
上述2组语句我们都在productid列创建了索引(统计信息也会自动创建),然后我们更新productid为775,只留1条还是不同的productid值。更新后,表里只有2个不同的productid值775和776。第1组语句,我们进行了自动更新统计信息启用的SELECT查询。第2组语句我们进行了自动更新统计信息停用的SELECT查询。我们来看看2者执行计划和IO统计信息的不同。
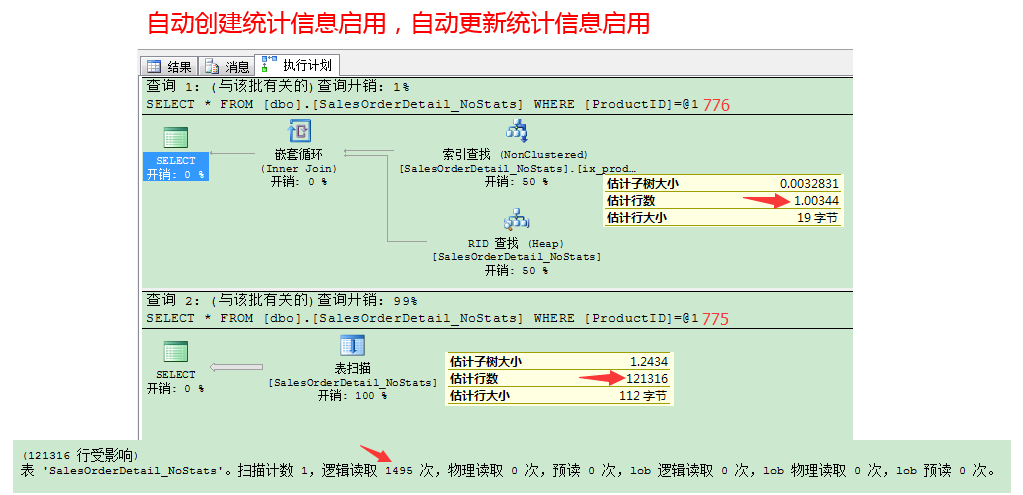
我们来看看启用的执行计划。第1个where条件是productid=776的查询估计行数是1,000348,优化器进行的是索引查找。第2个where条件是productid=775的查询估计行数是121316,优化器选择的是表扫描,而不是非聚集索引查找和书签查找。对优化器来说表扫描更有效,相比使用索引查找和书签查找来获取表里的所有记录(只有一条记录productid是776)。完成这个操作只需要1495个逻辑读。
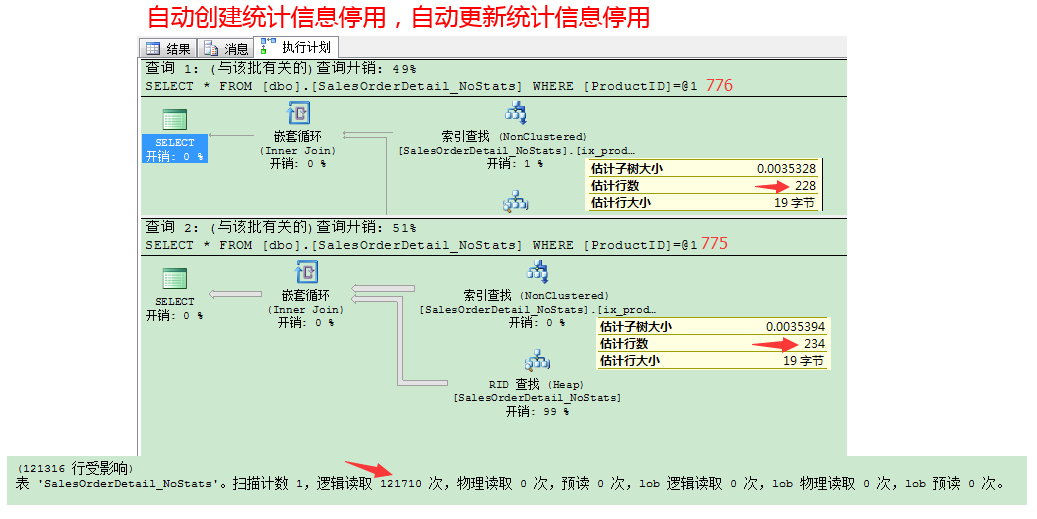
我们来看看停用的执行计划。第1个where条件是productid=776的查询估计行数是228,优化器进行的是索引查找。这个是基于索引创建是的统计信息来预估的,这个信息在update后已经过期了。第2个where条件是productid=775的查询估计行数是234,这就严重误导了查询优化器使用了非聚集扫描和书签查找来操作,而不是表扫描来获取表的所有记录(只有一条记录productid是776)。完成这个操作需要121710个逻辑读,相比启用情况下仅1495个逻辑读是非常非常高了。
从上面的例子,我们清楚的看到优化器需要更新的统计信息来选择最优执行计划,即使你有了必须的索引。在处理性能问题时,我们也需要关注下统计信息。把估计行数与实际行数的区别当作一个好指标,用来深入了解下统计信息,或统计信息的人为更新。
自动更新统计信息可以在以下3个级别进行关闭:
- 数据库级别,使用修改数据库命令:ALTER DATABASE StatisticsDB SET AUTO_UPDATE_STATISTICS OFF
- 索引级别,在创建或重建索引时使用STATISTICS_NORECOMPUTE 选项。这有点令人迷惑。这个选项默认是关闭的。就是说自动更新属性是启用的。
- 统计信息级别,当创建或更新统计信息时使用NORECOMPUTE 选项。
使用sp_autostats 存储过程可以查看表的对应统计信息的自动更新统计信息设置情况。如果在数据级别设置自动更新统计信息为停用,那表级别也会停用。可以使用sp_autostats存储过程修改表级别的自动更新统计信息设置情况。