��Դ�ļ��ĵ�һ�л�ڶ������ӣ��������ڵ�һ�л��ߵڶ�����
# -*- coding:utf-8 -*-
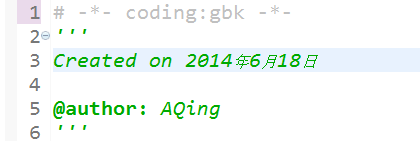
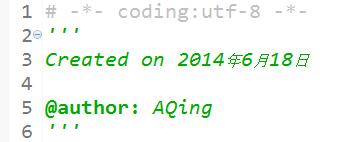
��ϸ��Ϣ��������ͣ�
Python����decode��encode�����Ĭ�ϴ�����ʽΪstrict��Ҳ����ֱ�ӱ�������javaʹ��replace�ķ�ʽ�������ˣ����java���������������ӡ���ܶ�"??"�����⣬Python��Ĭ�ϵ�encoding��ASCII����java��Ĭ��encoding������ϵͳ��encoding��һ�µġ�����һ���ϣ��Ҿ���java��Ϊ�����������Գ���Ա��Ϊ�Ѻã�Ҳ������newbies��ʼʱ�Ĵ��۸У������������Ե��ƹ�ġ����ǣ�PythonҲ�����ĵ������Ͼ�ASCII��Ψһ��ȫ��������ƽ̨��֧�ֵ��ַ�������������ʼ�������⣬ʼ�ջ���ֵģ��ӱ�������������������
����֮ǰ��������Ҫ�˽�Python���������ַ������ֱ���һ����ַ�����ÿ���ַ���8bits��ʾ����Unicode�ַ�����ÿ���ַ���һ�����߶���ֽڱ�ʾ�������ǿ����ת��������Unicode��Joel Spolsky �� The Absolute Minimum EverySoftware Developer Absolutely, Positively Must Know About Unicode and CharacterSets (No Excuses!) ����������˵����Jason Orendorff �� Unicode for programmers ���Ÿ�Ϊȫ����������ڴ��ҾͲ��ٶ�˵ʲô�ˡ���������Ĵ��룺
s = u"�������"
print s
�����������룬Python���������Ĵ�����ʾ:
SyntaxError:Non-ASCII character '\xd6' in fileD:\Users\Administrator\workspace\Python27_guan\src\knn_algorithms\test.py online 1, but no encoding declared; see http://www.python.org/peps/pep-0263.htmlfor details
˵��������ASCII�ַ��ˣ��������Dzο�pep-0263��PEP-0263��Python Enhancement Proposal������˵�ú�����ˣ����½�ͼ��

�ο���ַ��http://legacy.python.org/dev/peps/pep-0263/
����������ʵ��:
ExamplesThese are some examples to clarify the different styles for defining the source code encoding at the top of a Python source file: 1. With interpreter binary and using Emacs style file encoding comment: #!/usr/bin/python # -*- coding: latin-1 -*- import os, sys ... #!/usr/bin/python # -*- coding: iso-8859-15 -*- import os, sys ... #!/usr/bin/python # -*- coding: ascii -*- import os, sys ... 2. Without interpreter line, using plain text: # This Python file uses the following encoding: utf-8 import os, sys ... 3. Text editors might have different ways of defining the file's encoding, e.g. #!/usr/local/bin/python # coding: latin-1 import os, sys ... 4. Without encoding comment, Python's parser will assume ASCII text: #!/usr/local/bin/python import os, sys ... 5. Encoding comments which don't work: Missing "coding:" prefix: #!/usr/local/bin/python # latin-1 import os, sys ... Encoding comment not on line 1 or 2: #!/usr/local/bin/python # # -*- coding: latin-1 -*- import os, sys ... Unsupported encoding: #!/usr/local/bin/python # -*- coding: utf-42 -*- import os, sys ... |
PythonҲ��ʶ���˹��ʻ����⣬������˽������������������Ҫ�����������´�����в��ԣ�

�������еĽ�����£�
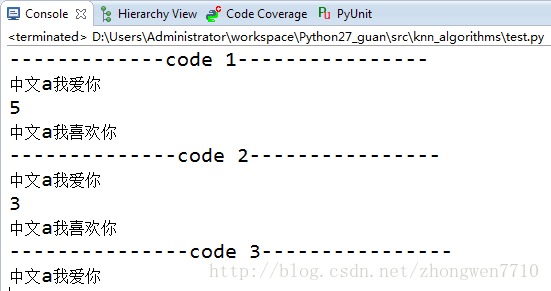
�ο����룺 # -*- coding:gb2312 -*- print "-------------code 1----------------" a = "����a�Ұ���" print a print a.find("��") b = a.replace("��","ϲ��") print b print "--------------code 2----------------" x = "����a�Ұ���" y = unicode(x,"gb2312") print y.encode("gb2312") print y.find(u"��") z = y.replace(u"��", u"ϲ��") print z.encode("gb2312") print "---------------code 3----------------" print y |
���ǿ��Կ�����ͨ������������������ǿ�����������ʹ�������ˣ�������code 1��2�У�����̨Ҳ����ȷ�İ����Ĵ�ӡ���������ǣ������ԣ�����Ĵ���Ҳ��ӳ���˲��ٵ����⣺
1��code 1 �� 2��ʹ��printʱ�����˲�ͬ�ķ�ʽ��1��ֱ��print����2��print֮ǰ�Ƚ��б���
2��code 1 �� 2����ͬ�����ַ�������ͬһ���ַ����ҡ����ó��Ľ����һ�����ֱ���5��3��
Ϊʲô��Ϊʲô�����ǿ��������Ժ���ģ��һ������ʹ��Python��������
���ȣ��������ñ༭����д��Դ���룬������ļ������Դ�������б������������õı༭��֧�ָ������ô���ļ�������Ӧ�ı��뷽ʽ�����ڴ����С�ע�⣺����������Դ�ļ��ı��벻һ����һ�µģ�����ȫ�����ڱ�����������������ΪUTF-8��������GB2312������Դ�ļ�����Ȼ�����Dz�������Ѱ���գ�����д�������Һõ�IDEҲ��ǿ�Ʊ�֤���ߵ�һ���ԣ����ǣ���������ü��±�����EditPlus�ȱ༭������д����Ļ���һ��С�ľͻ������������ġ�
�õ�һ��.py�ļ������ǾͿ����������ˣ����ǾͰѴ��뽻��Python����������ɽ��������������������ļ�ʱ���Ƚ����ļ��еı������������Ǽ����ļ��ı���Ϊgb2312����ô�Ƚ��ļ��е�������gb2312ת����Unicode��Ȼ���ٰ���ЩUnicodeת��ΪUTF-8格ʽ���ֽڴ��������һ�������������ЩUTF-8�ֽڴ��ֶΣ��������������ʹ��Unicode�ַ�������ô��ʹ����Ӧ��UTF-8�ֽڴ�����Unicode�ַ��������������ʹ�õ���һ����ַ�������ô�������Ƚ�UTF-8�ֽڴ�ͨ��Unicodeת������Ӧ���루�������gb2312���룩���ֽڴ��������䴴��һ����ַ�������Ҳ����˵��Unicode�ַ�����һ���ַ������ڴ��еĴ��格ʽ�Dz�һ���ģ�ǰ��ʹ��UTF-8��格ʽ������ʹ��GB2312格ʽ��
���ˣ��ڴ��е��ַ������格ʽ����֪���ˣ���������Ҫ�˽�print�Ĺ�����ʽ��print��ʵֻ�Ǹ�����ڴ�����Ӧ���ֽڴ���������ϵͳ���ò���ϵͳ��Ӧ�ij���Ʃ��cmd���ڣ�������ʾ�����������������
1�����ַ�����һ����ַ�������ôprintֻ����ڴ�����Ӧ���ֽڴ���������ϵͳ���������е�code1��
2������ַ�����Unicode�ַ�������ôprint������֮ǰ�Ƚ�����Ӧ��encode�����ǿ�����ʾʹ��Unicode��encode����ʹ�ú��ʵı��뷽ʽ�����루������code 2��������Pythonʹ��Ĭ�ϵı��뷽ʽ���б��룬Ҳ����ASCII�������е�code 3������ȻASCII�Dz�������ȷ�������ĵģ����Python��������ʵ�����ڲ��Գ����ʱ��y = unicode(x,"gb2312")
��似y = u'����a�Ұ���'�ģ����õط�����eclipse+Python��д�ģ������ܳ����еĽ����û�б�������������Python�Դ��ļ��ɹ��߲�����Ϣ���£�
���ˣ�������������������Ѿ����Խ�����һ�͵������ˡ����ڵڶ������⣬��ΪPython���������ַ�����һ���ַ�����Unicode�ַ��������߶��и��Ե��ַ���������������ǰ�ߣ����������ֽڵķ�ʽ���еģ�������GB2312�У�ÿ������ռ�������ֽڣ���˵õ��Ľ����5�����ں��ߣ�Ҳ����Unicode�ַ����������ַ�����ͳһ�����ģ���˵õ�3��
��Ȼ����ֻ�ᵽ�˿���̨������������⣬�����ļ���д�Լ����紫���г��ֵ�����������ԭ���϶�����似�ġ�Unicode�ij��ֿ��Ժܴ�̶��Ͻ�������Ĺ��ʻ����⣬ͬʱPythonΪUnicode�ṩ�˼�Ϊ���õ�֧�֣���ˣ��ҽ������ڱ�дPython�ij���ʱ����ͳһʹ��Unicode��ʽ�������ļ�ʱʹ��UTF-8�ı��뷽ʽ��How to Use UTF-8 with Python����ϸ����������ҿ��Բο�һ�¡�
Python���ܵ��³�����������ĵط����ܶ࣬Ʃ���ļ��Ķ�д���������ݵĴ���ȣ�ϣ������ܶ�ཻ������ͬ�����Щ���⡣
ʵ��Ӧ�������������Eclipse+pydev2.2+python2.7 ������������
Eclipse������
window->preferences->general->editors->texteditors->spelling->encoding->UTF-8
window->preferences->workspace->text fileencoding->UTF-8
��eclipse��װĿ¼->eclipse.ini��ĩ�м��ϡ�-Dfile.encoding=UTF-8��
�ļ�����
py�ļ��ǵñ����UTF-8���ļ����м��ϡ�#coding=utf-8��
runʱ����
run-->run configurations->python run->Common-> Encoding ->UTF-8
�ο����ף�
http://hi.baidu.com/neutblue/item/a636f83f8483adf6e7bb7aa0
http://legacy.python.org/dev/peps/pep-0263/
http://legacy.python.org/dev/peps/
http://www.cnblogs.com/linyawen/archive/2011/09/28/2194106.html