使用Jasper或BIRT等报表工具时,常会碰到一些非常规的统计,用报表工具本身或SQL都难以处理,比如交叉表的行组和列组都是分段区间,测度(measurem)来自其他数据库表。集算器具有结构化强计算引擎,集成简单,可以协助报表工具方便地实现此类需求。下面通过一个例子来说明双区间交叉表的实现过程。
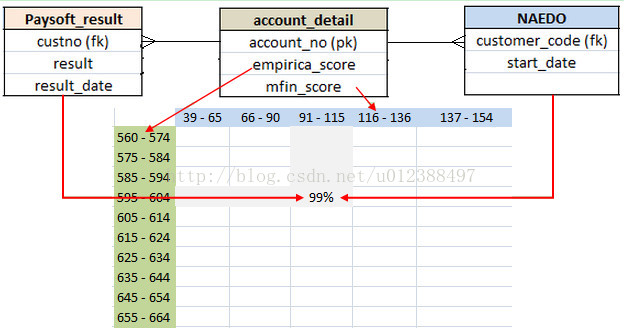
表account_detail的主键为account_no,与表Paysoft_result和NAEDO都是1对多关系。Paysoft_result的外键是custno,NAEDO的外键是customer_code。报表要求将account_detail的字段empirica_score按照外部参数分段,作为行组,字段mfin_score同样按照外部参数分段,作为列组。测度的算法是:分组交叉处account_no对应的Paysoft_result表的记录数除以account_no对应的NAEDO表的记录数。
下图是库表间关系,以及字段和报表的关系:
先用集算器准备数据,代码如下:
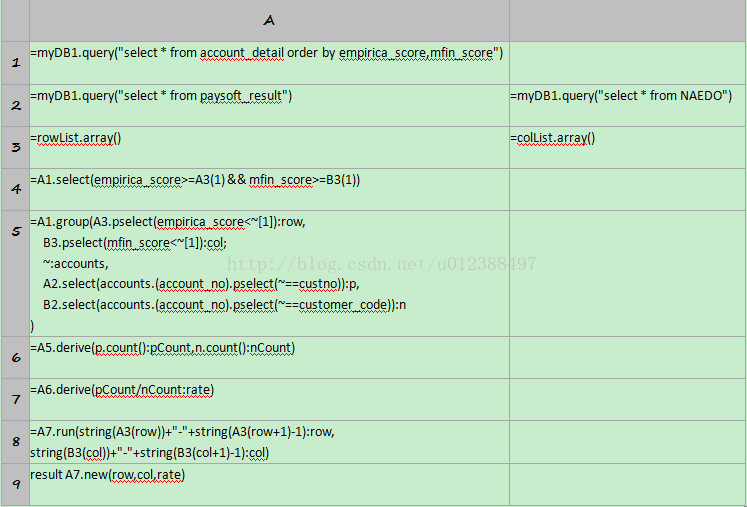
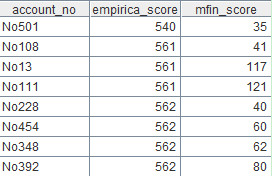
A1=myDB1.query("select * from account_detail orderby empirica_score,mfin_score")
上述代码可以从account_detail表取出数据。myDB1是数据源的名字,指向数据库。函数query执行SQL查询。A1的计算结果如下:
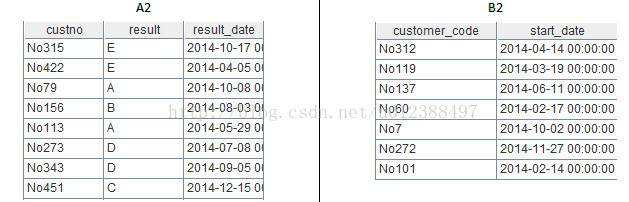
A2=myDB1.query("select * from paysoft_result")
B2=myDB1.query("select * from NAEDO")
类似地,A2和B2分别从paysoft_result表和NAEDO表取出数据,结果如下:
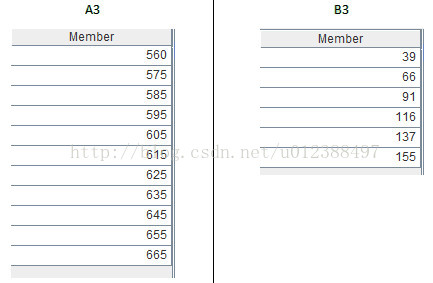
A3=rowList.array()
B3=colList.array()
这两句代码将来自报表的参数转为集算器序列。参数rowList表示行组,比如”560,575,585,595,605,615,625,635,645,654,665”是10个连续区间,参数colList表示列组,比如“39,66,91,116,137,155”是5个连续区间。函数array可将逗号分割的字符串转为序列,转换结果如下:
A4=A1.select(empirica_score>=A3(1) &&mfin_score>=B3(1))
本案例的数据超出了区间范围,比如“No501”号客户的empirica_sore等于540,比区间下限560还要小。为了提高性能并简化表达式,可以在A4中过滤掉小于区间下限的数据。
函数select可以进行数据查询或过滤,empirica_score是A1中的字段,A3(1)表示A3的第1个成员,即区间下限560,逻辑运算符“&&”表示“与”。A4的计算结果如下:

A5=A4.group(A3.pselect(empirica_score<~[1]):row,
B3.pselect(mfin_score<~[1]):col;
~:accounts,
A2.select(accounts.(account_no).pselect(~==custno)):p,
B2.select(accounts.(account_no).pselect(~==customer_code)):n
)
这句代码对A4(account_detail)按照A3(rowList)和B3(colList)中的区间进行分组,并找出各组数据在A2(paysoft_result)和B2(NAEDO)中对应的记录。
函数group可对数据按照多个字段(或分组标准)进行分组,形如A.group(field1,field2…),也可对分组后的每组数据进行统计或再计算,形如A.group(field1,field2… ; subtotal1,subtotal2…)。分组后各字段可用“:new name”进行重命名,上述分组结果就有5个字段,分别为row,col,accounts,p,n。结果如下:
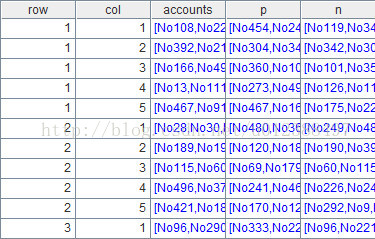
分组标准row的算法:对A4中的empirica_score字段按照A3中的区间进行分组,代码为:A3.pselect(empirica_score<~[1])。函数pselect可以选出A3中符合条件的成员序号,其中符号“~”表示A3的当前成员,上一个成员用~[-1]来表示,下一个成员用~[1]来表示。当前区间应当是(empirica_score>=~ && empirica_score<~[1]),由于A4已经在区间下限之上,因此表达式可以简化为empirica_score<~[1]。比如”560,575,585,595,605,615,625,635,645,654,665”可以将A1分到10个区间:560-574,575-584,585-594,595-604,605-614,615-624,625-634,635-644,645-654,655-664,组号分别是1到10。
分组标准col的算法类似:对A4中的mfin_score字段按照B3中的区间进行分组,代码为B3.pselect(mfin_score<~[1])。比如“39,66,91,116,137,155”可将A1分到5个区间:39-65,66-90,91-115,116-136,137-154,组号分别是1到5。
汇总字段account直接取出分组后的各组数据,其中~表示当前组的成员。点击accounts列的蓝色字体可以看到组内成员,其中“row=1,col=1”表示双区间“560-574,39-65”,“row=2,col=5”表示双区间“575-584,137-154”,如下图:
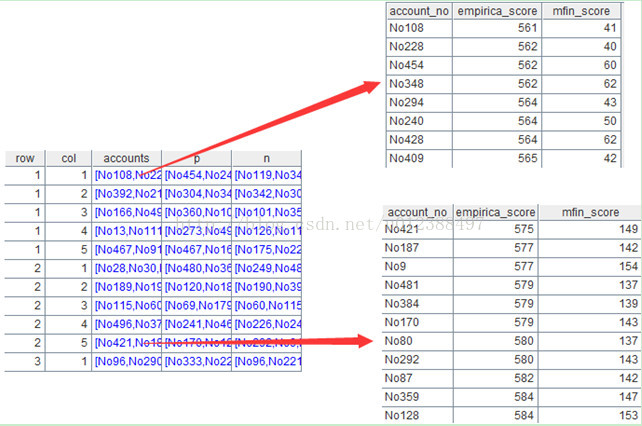
汇总字段P的算法:从A2中找出accounts里对应的记录,代码为:A2.select(accounts.(account_no).pselect(~==custno))。函数select可以按照条件对A2进行查询,找到符合条件的记录。其中“row=1,col=1”、“row=2,col=5”时p列对应的记录如下(accounts和A2是1对多的关系):
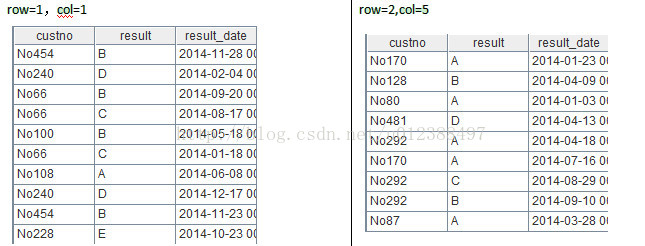
汇总字段n的算法类似:从B2中找出accounts里对应的记录,代码为:B2.select(accounts. (account_no).pselect(~==customer_code))。其中“row=1,col=1”、“row=2,col=5”时n列对应的记录如下:
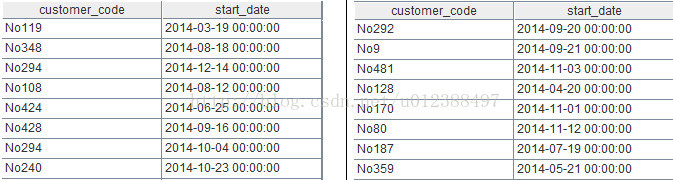
A6=A5.derive(p.count():pCount,n.count():nCount)
这句代码在A5中增加新列pCount,nCount,用来计算每组数据中p和n的记录数,计算结果如下:
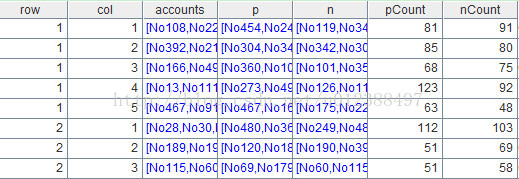
A7=A6.derive(pCount/nCount:rate)
这句代码在A6中增加新列rate,算法是pCount除以nCount,计算结果如下:
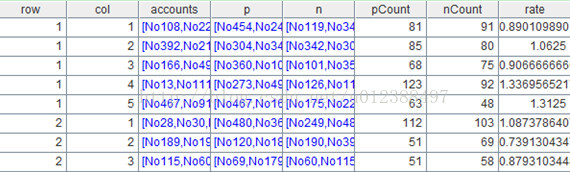
A8=A7.run(string(A3(row))+"-"+string(A3(row+1)-1):row,string(B3(col))+"-"+string(B3(col+1)-1):col)
这句代码将row和col中的组号反显为区间,函数run表示对A6中的每个成员(比如row=1,col1=1这一行就是一个成员)进行相同的计算。函数string可将数字转为字符串。表达式“A3()”可以根据序号从A3中取出成员,比如A3(1)等于560。A7的计算结果如下:
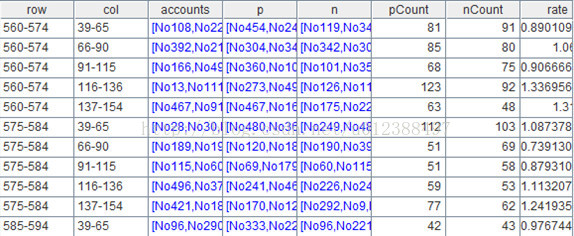
A8中已经包含了报表需要的三个字段,下面只需将row、col、rate组成新的二维表,并通过JDBC接口返回报表工具,即A9中的代码: result A8.new(row,col,rate)。
函数new可以从A8取出指定的列或计算列,并组成新的二维表,A8.new(row,col,rate)的计算结果如下:
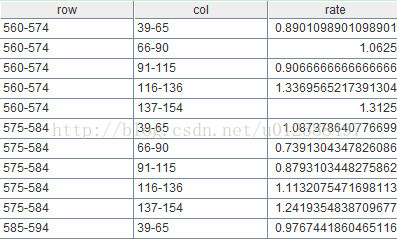
值得注意的是:集算器具有括号运算符,可以对逗号分隔的表达式依次计算,并返回最后一个表达式的值。利用括号运算符,可以将A4-A7精简为一句代码:
A4=A1.select(empirica_score>=A3(1)&& mfin_score>=B3(1)).group(
A3.pselect(empirica_score<~[1]):row,
B3.pselect(mfin_score<~[1]):col;
(accounts=~,A2.count(accounts.(account_no).pselect(~==custno))/
B2.count(accounts.(account_no).pselect(~==customer_code))):rate
)
计算结果如下:
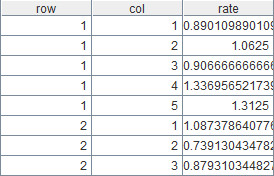
A9就是报表工具需要的数据集,接下来以JasperReport为例设计简单的交叉表,模板如下:
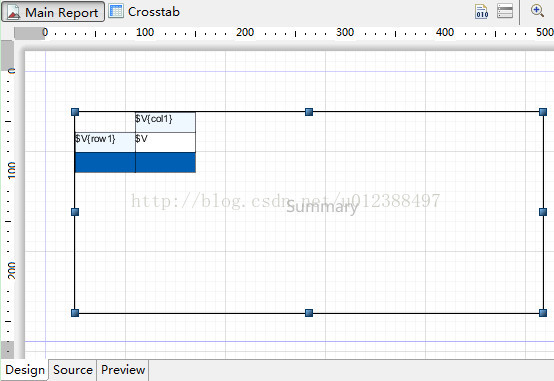
有三点需要注意:交叉表不能放在detailband中,Data Pre Sorted属性需要设置为true,在报表中需要定义集算器对应的参数,比如pRowList,pColList。报表预览如下:
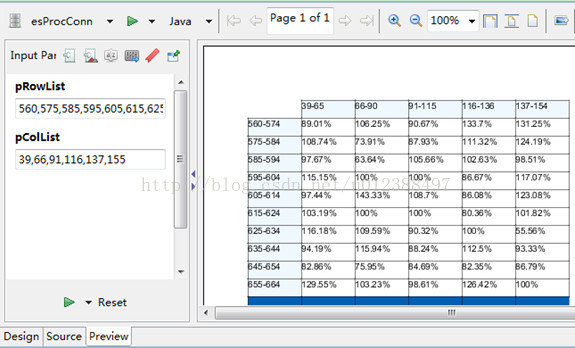
报表调用集算器的方法和调用存储过程一样,比如将本脚本保存为unregul.dfx,则在的JasperReport的SQL设计器中可以用unregul $P{pRowList},$P{pColList}来调用。具体集成方案请参考相关文档。