报表在数据源准备阶段往往要根据实际业务进行各种判断计算以后才能得到最终的报表数据源,而使用SQL在这种情况下则难于编写,http://bbs.csdn.net/topics/390938280中提到的考勤问题就是其中之一,这个计算看起来是给财务或人力部门的考勤报表服务的。计算逻辑并不算复杂,但使用SQL却很难做,用存储过程(要取首尾记录)也很麻烦,而一般的报表工具由于不具备强计算能力,常常只能写用Java等写自定义数据源实现。
使用润乾集算报表来做则比较简单,这里以上述链接中的实际业务为例,给出集算报表的实现方案。
报表背景
源数据如下:

现需要在报表中以日期和性能统计考勤情况,要求根据:每天7点到12点算上班打卡,16点以后算下班打卡,多次刷卡取最早的打卡时间为上班卡,取最晚时间为下班卡,如果在该时间段未存在打卡记录即显示未打卡,8点30之后打卡算迟到,18点之前下班算早退。得到类似下表结果:

这个报表的难点在于用SQL或存储过程写起来很困难,而一般报表工具则不具备数据源计算能力,根本无法实现。
集算报表本身内置了适合结构化计算的脚本,可以方便地写出数据准备的计算(相当于一种更使用更简单的自定义数据集)。上述报表需求使用集算报表可以这样完成:
编写集算脚本
首先使用集算脚本编辑器,新建集算脚本,设置脚本参数,如刷卡起止时间范围:
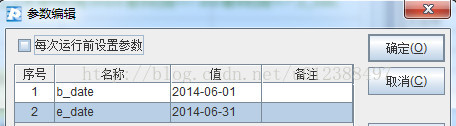
编写脚本完成数据计算,为报表输出计算后结果集。
| A | B |
|
1 | =connect("kaoqin") |
|
|
2 | =A1.query("select * from 考勤表 where 刷卡时间>=? and 刷卡时间<=?",b_date,e_date order by 员工工号,刷卡时间) | ||
3 | =A2.group(员工姓名,date(刷卡时间)) | ||
4 | =create(日期,员工姓名,上班,下班,是否迟到,是否早退) | ||
5 | for A3 | =A5(1).刷卡时间 | =string(time(B5)) |
6 |
| =A5.m(-1).刷卡时间 | =string(time(B6)) |
7 |
| =if(C5>="07:00:00" && C5<="12:00:00",B5,"未打卡") | |
8 |
| =if(C6>="16:00:00",B6,"未打卡") | |
9 |
| =if(C5>="08:30:00" && C5<="12:00:00","迟到",if(C5<="08:30:00","","未打卡")) | |
10 |
| =if(C6>="16:00:00"&& C6<="18:00:00","早退",if(C6>="18:00:00","","未打卡")) | |
11 |
| >A4.insert(0,date(A5.刷卡时间),A5.员工姓名,B7,B8,B9,B10) | |
12 | result A4 |
|
|
A1:连接数据源;
A2:根据指定时间范围,执行sql查询考勤表数据,查询结果按照员工和刷卡时间排序,排序是为了便于后续取得首尾记录;
A3:按照员工和刷卡日期分组,与SQL不同,集算脚本中的分组结果保留了分组成员;
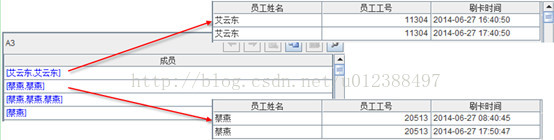
A4:创建空结果序表;
A5-C11:循环A3中的分组,根据最早和最晚刷卡时间通过判断计算员工的出勤情况,最后将结果写回到A4结果序表中;
其中,B6通过A5.m(-1)取得了最后一条记录,集算报表中的集合都是有序的,所以很容易通过序号取得相应成员,这与SQL的集合无序有很大区别;
A12:为报表返回结果集。
编辑报表模板
使用集算报表编辑器,编辑报表模板,用于数据展现。首先新建参数,并设置默认值。

新建报表并设置集算器数据集,调用上述编辑好的脚本文件。
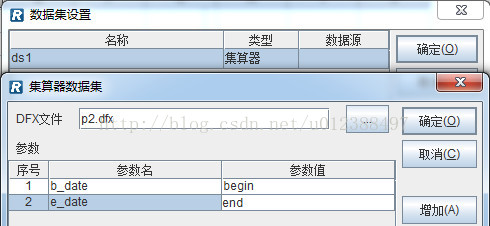
其中,dfx文件路径既可以是绝对路径,也可以是相对路径,相对路径是相对选项中配置的dfx主目录的;参数b_date和e_date为脚本参数,begin和end为报表模板参数,事实上二者可以同名。
编辑报表表达式,直接使用集算脚本返回的结果集,完成报表制作。

报表展现结果如下:
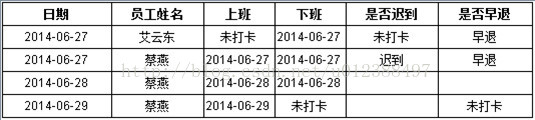
可以看到,使用集算器脚本可以快速完成这类带有多重判断的情况。而且外置的集算脚本具有可视化的编辑调试环境,编辑好的脚本还可以复用(被其他报表或程序调用)。不过,如果脚本已经调试好,而且不需要复用的时候,要维护两个文件(集算脚本和报表模板)的一致性会比较麻烦,这时候直接使用集算报表的脚本数据集就比较简单了。
在脚本数据集中可以分步编写脚本完成计算任务,语法与集算器一致,还可以直接使用报表定义好的数据源和参数。本例使用脚本数据集可以这样完成:
1. 在数据集设置窗口中点击“增加”按钮,弹出数据集类型对话框,选择“脚本数据集”;
2. 在弹出的脚本数据集编辑窗口中编写脚本;
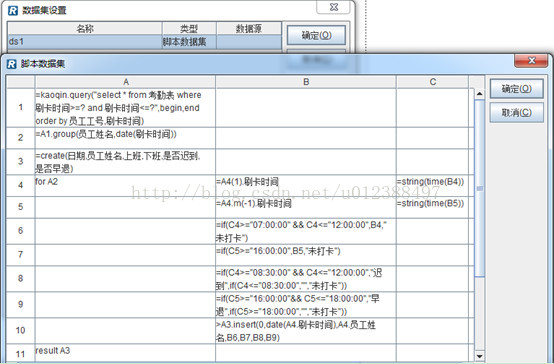
这里可以看到,在脚本数据集中直接使用了报表中定义好的数据源kaoqin和参数begin和end,比起单独的集算脚本更加简单、直接。
3. 报表模板和表达式与使用集算器数据集方式一致,不再赘述。