вЛЬѕИќаТгяОфжДааЕФЫГађ
update T set c=c+1 where ID=2;
a. жДааЦїЯШевв§ЧцШЁ ID=2 етвЛааЁЃID ЪЧжїМќЃЌв§ЧцжБНггУЪїЫбЫїевЕНетвЛааЁЃШчЙћ ID=2 етвЛааЫљдкЕФЪ§ОнвГБОРДОЭдкФкДцжаЃЌОЭжБНгЗЕЛиИјжДааЦїЃЛЗёдђЃЌашвЊЯШДгДХХЬЖСШыФкДцЃЌШЛКѓдйЗЕЛиЁЃ
b. жДааЦїФУЕНв§ЧцИјЕФааЪ§ОнЃЌАбетИіжЕМгЩЯ 1ЃЌБШШчдРДЪЧ NЃЌЯждкОЭЪЧ N+1ЃЌЕУЕНаТЕФвЛааЪ§ОнЃЌдйЕїгУв§ЧцНгПкаДШыетаааТЪ§ОнЁЃ
c. в§ЧцНЋетаааТЪ§ОнИќаТЕНФкДцжаЃЌЭЌЪБНЋетИіИќаТВйзїМЧТМЕН redo log РяУцЃЌДЫЪБ redo log ДІгк prepare зДЬЌЁЃШЛКѓИцжЊжДааЦїжДааЭъГЩСЫЃЌЫцЪБПЩвдЬсНЛЪТЮёЁЃ
d. жДааЦїЩњГЩетИіВйзїЕФ binlogЃЌВЂАб binlog аДШыДХХЬЁЃ
e. жДааЦїЕїгУв§ЧцЕФЬсНЛЪТЮёНгПкЃЌв§ЧцАбИеИеаДШыЕФ redo log ИФГЩЬсНЛЃЈcommitЃЉзДЬЌЃЌИќаТЭъГЩЁЃ
1.binlog
binlogЪєгкMySQL ServerВуУцЃЌГЦЮЊЙщЕЕШежОЃЌвдЖўНјжЦаЮЪНМЧТМгяОфЕФдЪМТпМЃЌbinlogЪЧУЛгаcrash-safeФмСІ
binlog гУгкМЧТМЪ§ОнПтжДааЕФаДШыадВйзї(ВЛАќРЈВщбЏ)аХЯЂЃЌвдЖўНјжЦЕФаЮЪНБЃДцдкДХХЬжаЁЃbinlog ЪЧ mysqlЕФТпМШежОЃЌВЂЧвгЩ Server ВуНјааМЧТМЃЌЪЙгУШЮКЮДцДЂв§ЧцЕФ mysql Ъ§ОнПтЖМЛсМЧТМ binlog ШежОЁЃ
- ТпМШежОЃКПЩвдМђЕЅРэНтЮЊМЧТМЕФОЭЪЧsqlгяОф ЁЃ
- ЮяРэШежОЃК
mysqlЪ§ОнзюжеЪЧБЃДцдкЪ§ОнвГжаЕФЃЌЮяРэШежОМЧТМЕФОЭЪЧЪ§ОнвГБфИќ ЁЃ
binlog ЪЧЭЈЙ§зЗМгЕФЗНЪННјаааДШыЕФЃЌПЩвдЭЈЙ§max_binlog_size ВЮЪ§ЩшжУУПИі binlogЮФМўЕФДѓаЁЃЌЕБЮФМўДѓаЁДяЕНИјЖЈжЕжЎКѓЃЌЛсЩњГЩаТЕФЮФМўРДБЃДцШежОЁЃ
binlog ЪЙгУГЁОА
дкЪЕМЪгІгУжаЃЌ binlog ЕФжївЊЪЙгУГЁОАгаСНИіЃЌЗжБ№ЪЧ жїДгИДжЦ КЭ Ъ§ОнЛжИД ЁЃ
- жїДгИДжЦ ЃКдк
MasterЖЫПЊЦєbinlogЃЌШЛКѓНЋbinlogЗЂЫЭЕНИїИіSlaveЖЫЃЌSlaveЖЫжиЗХbinlogДгЖјДяЕНжїДгЪ§ОнвЛжТЁЃ - Ъ§ОнЛжИД ЃКЭЈЙ§ЪЙгУ
mysqlbinlogЙЄОпРДЛжИДЪ§ОнЁЃ
binlog ЫЂХЬЪБЛњ
Ждгк InnoDB ДцДЂв§ЧцЖјбдЃЌжЛгадкЪТЮёЬсНЛЪБВХЛсМЧТМbiglog ЃЌДЫЪБМЧТМЛЙдкФкДцжаЃЌФЧУД biglogЪЧЪВУДЪБКђЫЂЕНДХХЬжаЕФФиЃП
mysql ЭЈЙ§ sync_binlog ВЮЪ§ПижЦ biglog ЕФЫЂХЬЪБЛњЃЌШЁжЕЗЖЮЇЪЧ 0-NЃК
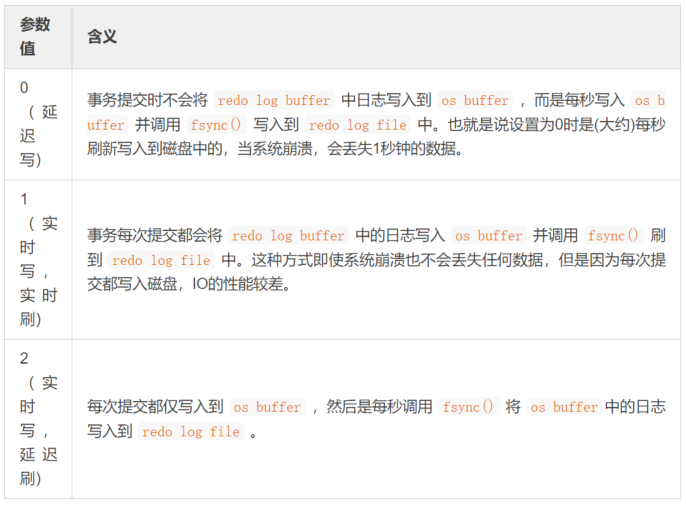
- 0ЃКВЛШЅЧПжЦвЊЧѓЃЌгЩЯЕЭГздааХаЖЯКЮЪБаДШыДХХЬЃЛ
- 1ЃКУПДЮ
commitЕФЪБКђЖМвЊНЋbinlogаДШыДХХЬЃЛ - NЃКУПNИіЪТЮёЃЌВХЛсНЋ
binlogаДШыДХХЬЁЃ
ДгЩЯУцПЩвдПДГіЃЌ sync_binlog зюАВШЋЕФЪЧЩшжУЪЧ 1 ЃЌетвВЪЧMySQL 5.7.7жЎКѓАцБОЕФФЌШЯжЕЁЃЕЋЪЧЩшжУвЛИіДѓвЛаЉЕФжЕПЩвдЬсЩ§Ъ§ОнПтадФмЃЌвђДЫЪЕМЪЧщПіЯТвВПЩвдНЋжЕЪЪЕБЕїДѓЃЌЮўЩќвЛЖЈЕФвЛжТадРДЛёШЁИќКУЕФадФмЁЃ
binlog ШежОИёЪН
binlog ШежОгаШ§жжИёЪНЃЌЗжБ№ЮЊ STATMENT ЁЂ ROW КЭ MIXEDЁЃ
дк
MySQL 5.7.7жЎЧАЃЌФЌШЯЕФИёЪНЪЧSTATEMENTЃЌMySQL 5.7.7жЎКѓЃЌФЌШЯжЕЪЧROWЁЃШежОИёЪНЭЈЙ§binlog-formatжИЖЈЁЃ
-
STATMENTЃКЛљгкSQLгяОфЕФИДжЦ(statement-based replication, SBR)ЃЌУПвЛЬѕЛсаоИФЪ§ОнЕФsqlгяОфЛсМЧТМЕНbinlogжа ЁЃ**гХЕуЃК**ВЛашвЊМЧТМУПвЛааЕФБфЛЏЃЌМѕЩйСЫ binlog ШежОСПЃЌНкдМСЫ IO , ДгЖјЬсИпСЫадФмЃЛ
**ШБЕуЃК**дкФГаЉЧщПіЯТЛсЕМжТжїДгЪ§ОнВЛвЛжТЃЌБШШчжДааsysdate() ЁЂ slepp() ЕШ ЁЃ -
ROWЃКЛљгкааЕФИДжЦ(row-based replication, RBR)ЃЌВЛМЧТМУПЬѕsqlгяОфЕФЩЯЯТЮФаХЯЂЃЌНіашМЧТМФФЬѕЪ§ОнБЛаоИФСЫ ЁЃ**гХЕуЃК**ВЛЛсГіЯжФГаЉЬиЖЈЧщПіЯТЕФДцДЂЙ§ГЬЁЂЛђfunctionЁЂЛђtriggerЕФЕїгУКЭДЅЗЂЮоЗЈБЛе§ШЗИДжЦЕФЮЪЬт ЃЛ
ШБЕуЃКЛсВњЩњДѓСПЕФШежОЃЌгШЦфЪЧalter tableЕФЪБКђЛсШУШежОБЉеЧ -
MIXEDЃКЛљгкSTATMENTКЭROWСНжжФЃЪНЕФЛьКЯИДжЦ(mixed-based replication, MBR)ЃЌвЛАуЕФИДжЦЪЙгУSTATEMENTФЃЪНБЃДцbinlogЃЌЖдгкSTATEMENTФЃЪНЮоЗЈИДжЦЕФВйзїЪЙгУROWФЃЪНБЃДцbinlog
2.redo log
2.1ЮЊЪВУДашвЊredo log
ЮвУЧЖМжЊЕРЃЌЪТЮёЕФЫФДѓЬиадРяУцгавЛИіЪЧ ГжОУад ЃЌОпЬхРДЫЕОЭЪЧжЛвЊЪТЮёЬсНЛГЩЙІЃЌФЧУДЖдЪ§ОнПтзіЕФаоИФОЭБЛгРОУБЃДцЯТРДСЫЃЌВЛПЩФмвђЮЊШЮКЮдвђдйЛиЕНдРДЕФзДЬЌ ЁЃ
ФЧУД mysqlЪЧШчКЮБЃжЄвЛжТадЕФФиЃП
зюМђЕЅЕФзіЗЈЪЧдкУПДЮЪТЮёЬсНЛЕФЪБКђЃЌНЋИУЪТЮёЩцМАаоИФЕФЪ§ОнвГШЋВПЫЂаТЕНДХХЬжаЁЃЕЋЪЧетУДзіЛсгабЯжиЕФадФмЮЪЬтЃЌжївЊЬхЯждкСНИіЗНУцЃК
- вђЮЊ
InnodbЪЧвдвГЮЊЕЅЮЛНјааДХХЬНЛЛЅЕФЃЌЖјвЛИіЪТЮёКмПЩФмжЛаоИФвЛИіЪ§ОнвГРяУцЕФМИИізжНкЃЌетИіЪБКђНЋЭъећЕФЪ§ОнвГЫЂЕНДХХЬЕФЛАЃЌЬЋРЫЗбзЪдДСЫЃЁ - вЛИіЪТЮёПЩФмЩцМАаоИФЖрИіЪ§ОнвГЃЌВЂЧветаЉЪ§ОнвГдкЮяРэЩЯВЂВЛСЌајЃЌЪЙгУЫцЛњIOаДШыадФмЬЋВюЃЁ
вђДЫ mysql ЩшМЦСЫ redo log ЃЌ ОпЬхРДЫЕОЭЪЧжЛМЧТМЪТЮёЖдЪ§ОнвГзіСЫФФаЉаоИФЃЌетбљОЭФмЭъУРЕиНтОіадФмЮЪЬтСЫ(ЯрЖдЖјбдЮФМўИќаЁВЂЧвЪЧЫГађIO)ЁЃ
2.2 redo log ЛљБОИХФю
УПДЮЖдМЧТМЕФаоИФаДШыЛКГхГиЕФЪБКђЃЌЯШНВМЧТМаДШыredo log bufferЃЈМЧТМзХФФвЛвГаоИФСЫЪВУДЪ§ОнЃЉЃЌКѓајдкЬиЖЈЪБПЬНЋЖрИіВйзїЫЂХЬЕНredo log fileжа(ЗХдкДХХЬ)ЃЌетжжЯШаДШежОЃЌдйаДДХХЬЕФММЪѕОЭЪЧMySQLРяЕФWAL(Write-Ahead Logging)ММЪѕЁЃ
дкВйзїЯЕЭГжаЃЌгУЛЇПеМфЯТЕФЛКГхЧјЪЧЮоЗЈжБНгаДШыДХХЬЕФЃЌжаМфБиаыОЙ§ВйзїЯЕЭГФкКЫПеМф(kernal space)ЛКГхЧјЃЌШЛКѓЭЈЙ§ЯЕЭГЕїгУfsync()ЫЂЕНredo log fileжаЁЃ
MySQLжЇГжШ§жжНЋredo log bufferаДШыredo log fileЕФЪБЛњЃЌПЩвдЭЈЙ§ innodb_flush_log_at_trx_commit ВЮЪ§ХфжУЃЌЯрЙиКЌвхШчЯТЃК
ПЩвдЗЂЯжаДШыredo log fileвВЪЧДХХЬIOЃЌЕЋЫќЪЧЫГађIOЃЌБШДгЛКГхГиНЋЪ§ОнвГЫцЛњIOЕНДХХЬПьКмЖрЁЃ 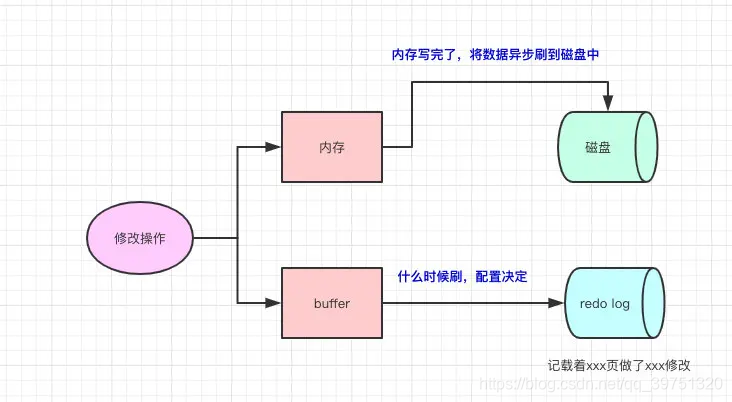
2.3 redo log МЧТМаЮЪН
дкИќаТвЛЬѕгяОфЪБЃЌInnoDBЛсАбИќаТМЧТМаДЕНredo logжаЃЌШЛКѓИќаТФкДцЃЌШЛКѓдкПеЯаЕФЪБКђЛђЪЧАДееЩшЖЈЕФИќаТВпТдНЋredo logжаЕФФкШнИќаТЕНДХХЬЁЃredo logШежОДѓаЁЪЧЙЬЖЈЕФЃЌМДМЧТМТњСЫКѓОЭДгЭЗбЛЗаДЁЃCheckpoint вдЧАБэЪОвбОИќаТЕНДХХЬЕФЮФМўЃЌwrite posБэЪОЕБЧАаДЕФЮЛжУЃЌШчЙћСНИіжИеыЯргіСЫЃЌБэЪОredo logвбОТњСЫЃЌашвЊЭЌВНЕНДХХЬжаЁЃ
ЧАУцЫЕЙ§ЃЌ redo log ЪЕМЪЩЯМЧТМЪ§ОнвГЕФБфИќЃЌЖјетжжБфИќМЧТМЪЧУЛБивЊШЋВПБЃДцЃЌвђДЫ redo logЪЕЯжЩЯВЩгУСЫДѓаЁЙЬЖЈЃЌбЛЗаДШыЕФЗНЪНЃЌЕБаДЕННсЮВЪБЃЌЛсЛиЕНПЊЭЗбЛЗаДШежОЁЃШчЯТЭМЃК
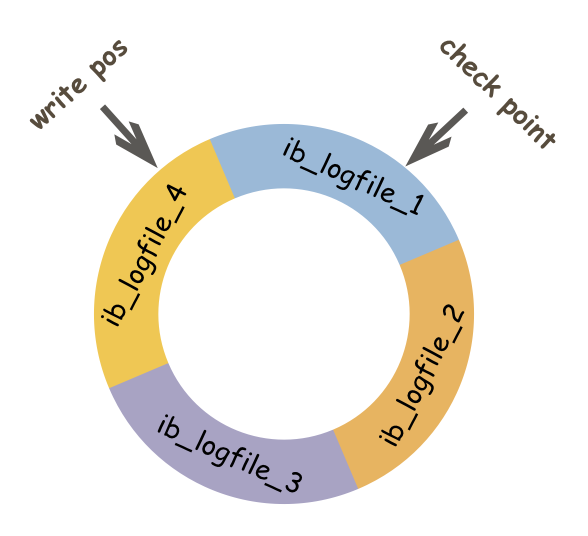
ЭЌЪБЮвУЧКмШнвзЕУжЊЃЌ дкinnodbжаЃЌМШгаredo log ашвЊЫЂХЬЃЌЛЙга Ъ§ОнвГ вВашвЊЫЂХЬЃЌ redo logДцдкЕФвтвхжївЊОЭЪЧНЕЕЭЖд Ъ§ОнвГ ЫЂХЬЕФвЊЧѓ ** ЁЃ
дкЩЯЭМжаЃЌ write pos БэЪО redo log ЕБЧАМЧТМЕФ LSN (ТпМађСаКХ)ЮЛжУЃЌ check point БэЪО Ъ§ОнвГИќИФМЧТМ ЫЂХЬКѓЖдгІ redo log ЫљДІЕФ LSN(ТпМађСаКХ)ЮЛжУЁЃ
write pos ЕН check point жЎМфЕФВПЗжЪЧ redo log ПезХЕФВПЗжЃЌгУгкМЧТМаТЕФМЧТМЃЛcheck point ЕН write pos жЎМфЪЧ redo log Д§ТфХЬЕФЪ§ОнвГИќИФМЧТМЁЃЕБ write posзЗЩЯcheck point ЪБЃЌЛсЯШЭЦЖЏ check point ЯђЧАвЦЖЏЃЌПеГіЮЛжУдйМЧТМаТЕФШежОЁЃ
ЦєЖЏ innodb ЕФЪБКђЃЌВЛЙмЩЯДЮЪЧе§ГЃЙиБеЛЙЪЧвьГЃЙиБеЃЌзмЪЧЛсНјааЛжИДВйзїЁЃвђЮЊ redo logМЧТМЕФЪЧЪ§ОнвГЕФЮяРэБфЛЏЃЌвђДЫЛжИДЕФЪБКђЫйЖШБШТпМШежО(Шч binlog )вЊПьКмЖрЁЃ
жиЦєinnodb ЪБЃЌЪзЯШЛсМьВщДХХЬжаЪ§ОнвГЕФ LSN ЃЌШчЙћЪ§ОнвГЕФLSN аЁгкШежОжаЕФ LSN ЃЌдђЛсДг checkpoint ПЊЪМЛжИДЁЃ
ЛЙгавЛжжЧщПіЃЌдкхДЛњЧАе§ДІгкcheckpoint ЕФЫЂХЬЙ§ГЬЃЌЧвЪ§ОнвГЕФЫЂХЬНјЖШГЌЙ§СЫШежОвГЕФЫЂХЬНјЖШЃЌДЫЪБЛсГіЯжЪ§ОнвГжаМЧТМЕФ LSN ДѓгкШежОжаЕФ LSNЃЌетЪБГЌГіШежОНјЖШЕФВПЗжНЋВЛЛсжизіЃЌвђЮЊетБОЩэОЭБэЪОвбОзіЙ§ЕФЪТЧщЃЌЮоашдйжизіЁЃ
2.4 redo logКЭbinlogЧјБ№
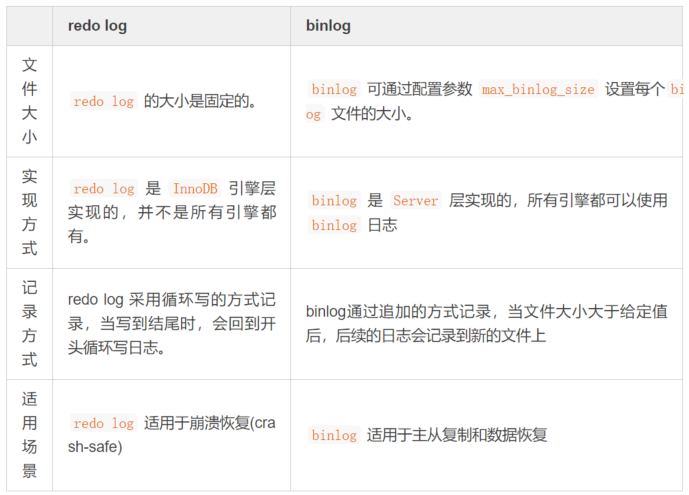
гЩ binlog КЭ redo log ЕФЧјБ№ПЩжЊЃКbinlog ШежОжЛгУгкЙщЕЕЃЌжЛвРПП binlog ЪЧУЛга crash-safe ФмСІЕФЁЃ
ЕЋжЛга redo log вВВЛааЃЌвђЮЊ redo log ЪЧ InnoDBЬигаЕФЃЌЧвШежОЩЯЕФМЧТМТфХЬКѓЛсБЛИВИЧЕєЁЃвђДЫашвЊ binlogКЭ redo logЖўепЭЌЪБМЧТМЃЌВХФмБЃжЄЕБЪ§ОнПтЗЂЩњхДЛњжиЦєЪБЃЌЪ§ОнВЛЛсЖЊЪЇЁЃ
3. undo log
Ъ§ОнПтЪТЮёЫФДѓЬиаджагавЛИіЪЧ дзгад ЃЌОпЬхРДЫЕОЭЪЧ дзгадЪЧжИЖдЪ§ОнПтЕФвЛЯЕСаВйзїЃЌвЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЃЌВЛПЩФмГіЯжВПЗжГЩЙІЕФЧщПіЁЃ
ЪЕМЪЩЯЃЌ дзгад ЕзВуОЭЪЧЭЈЙ§ undo log ЪЕЯжЕФЁЃundo logжївЊМЧТМСЫЪ§ОнЕФТпМБфЛЏЃЌБШШчвЛЬѕ INSERT гяОфЃЌЖдгІвЛЬѕDELETE ЕФ undo log ЃЌЖдгкУПИі UPDATE гяОфЃЌЖдгІвЛЬѕЯрЗДЕФ UPDATE ЕФ undo log ЃЌетбљдкЗЂЩњДэЮѓЪБЃЌОЭФмЛиЙіЕНЪТЮёжЎЧАЕФЪ§ОнзДЬЌЁЃ
ЭЌЪБЃЌ undo log вВЪЧ MVCC(ЖрАцБОВЂЗЂПижЦ)ЪЕЯжЕФЙиМќЁЃ
УПЬѕЪ§ОнаоИФ(insertЁЂupdateЛђdelete)ВйзїЖМАщЫцвЛЬѕundo logЕФЩњГЩ,ВЂЧвЛиЙіШежОБиаыЯШгкЪ§ОнГжОУЛЏЕНДХХЬЩЯ
BinlogЯъНт - МђЪщ
MySQL БиаыеЦЮеЕФШ§ДѓШежО-binglogЁЂredo logвдМАundo log_ГЬађдБЕєЭЗЗЂЕФВЉПЭ-CSDNВЉПЭ_binglog