����
Towards Discriminative Representation Learning for Unsupervised Person
Re-identification
���յ�λ��iccv2021
��Ҫ����
- CCL�������ǶԱ���ʧ����������ȡֵ��Щ��ͬ
- PDA���Ż�����ʧ����������ʽ����ѵ������������epoch�����Ӽ���Դ���lossȨ������Ŀ�����lossȨ��
- FA�����븵��Ҷ��ǿ�ķ�ʽ������ȡ������ʹ�ø���Ҷ��ǿȻ�����CE������ʧ
CCL
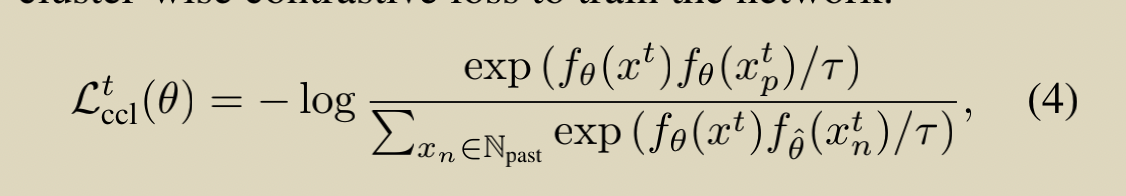
- ?�ȣ�MMA���µ��������?�� �� m?�� + (1-m) ��
- f�ȣ�����Ϊ�ȵı�������
- xt����ǰѡ�е�����
- xtp����ǰѡ�е������ڵ�ǰbatch�е�������
- xtn��Dynamic Queue�д����������������������ǰѡ�������Ǹ�������������Ϊ������
CCL�������Ա���ʧ�Ƚϣ�
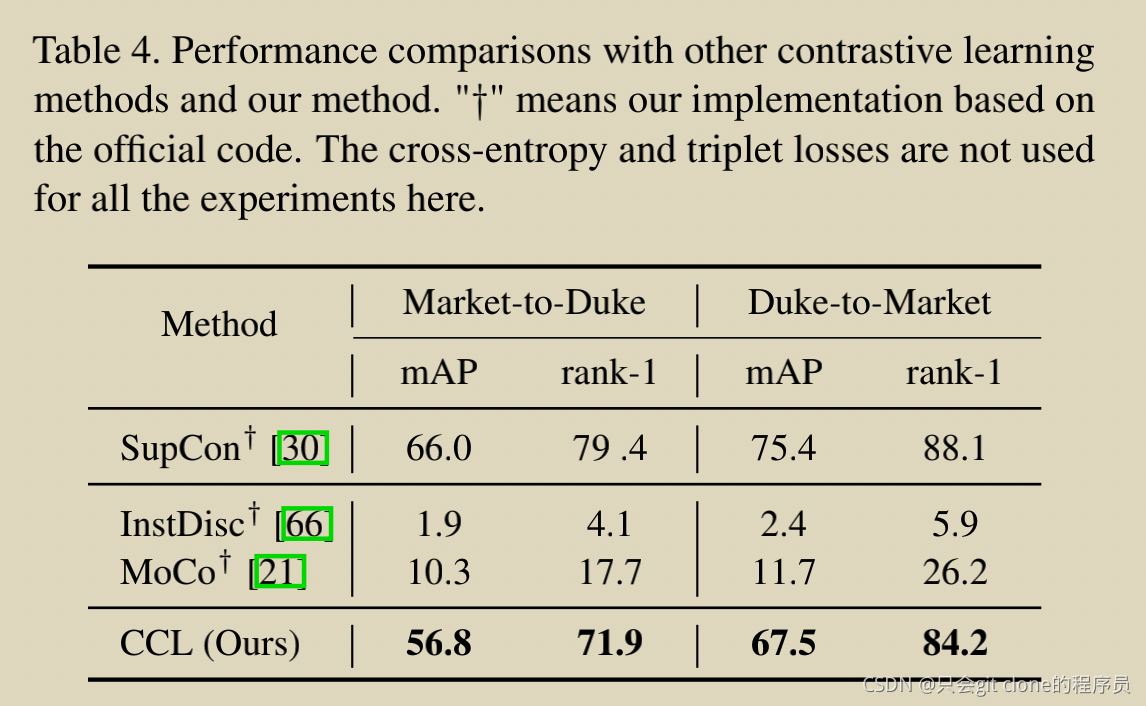
PDA
������ʧ������
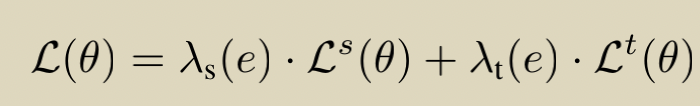
- ��ΪȨ�أ�s��t�ֱ��ӦԴ���Ŀ����
- LΪ��ʧ��s��t�ֱ��ӦԴ���Ŀ����
- eΪ�ڼ���epoch
��������Ħ�Ȩ�ر仯���ԣ�
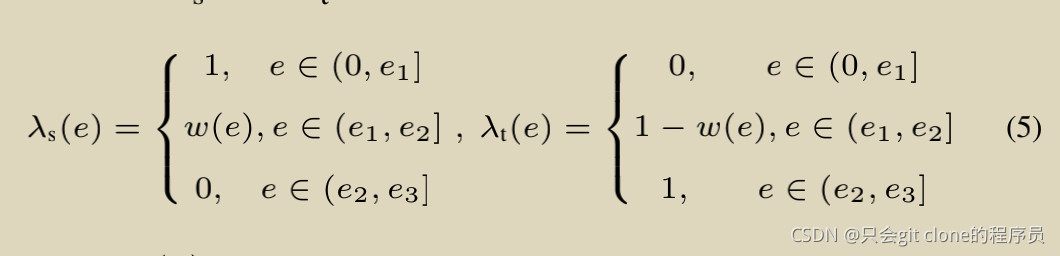
��Ծ��ʾ��ͼ��

�ܶ���֮��ǰ����ʧ��Ȩ��Դ��ߣ�������ʧ��Ȩ��Ŀ����ߡ�
FA
���ȿ�һ��FFT�ĵ�ͼ����ʾ��ͼ��
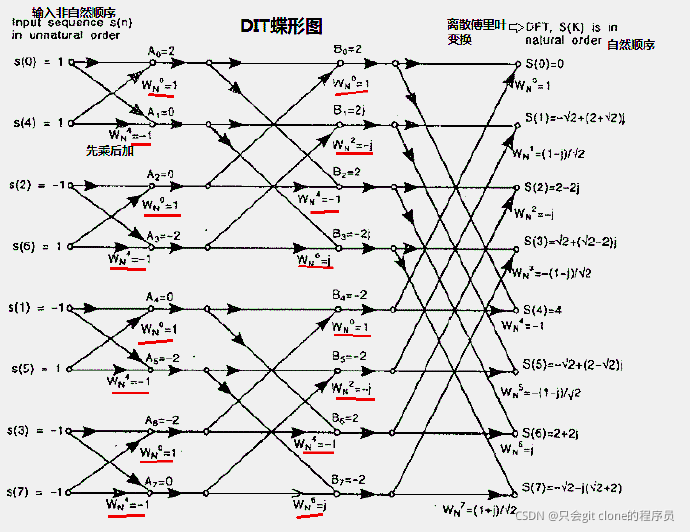
����������м���ô���㣬��ͼ����֪������ʵ��s(n)���ݵ�ͼ���Եõ���Ӧ����������������8��ʵ�����Ҳ��8�������������������FFT����������ͼƬ���������Ӧ��������Ȼ��Ը�����������������磺����a=3+4j���Ϊ(3^2 + 4^2) ^ 0.5 = 5����ͨ�������ļ����൱�ڶ�cnn������������������һ��������ǿ�����߽��������Ҷ��ǿ�����������������ǿ�������ټ�����һ��������ʧ��
����Ҷ������ǿ������
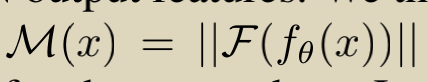
������ǿ��ʽ��
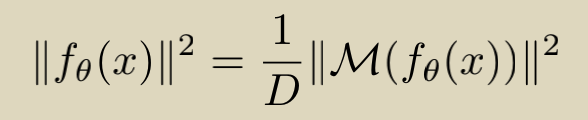
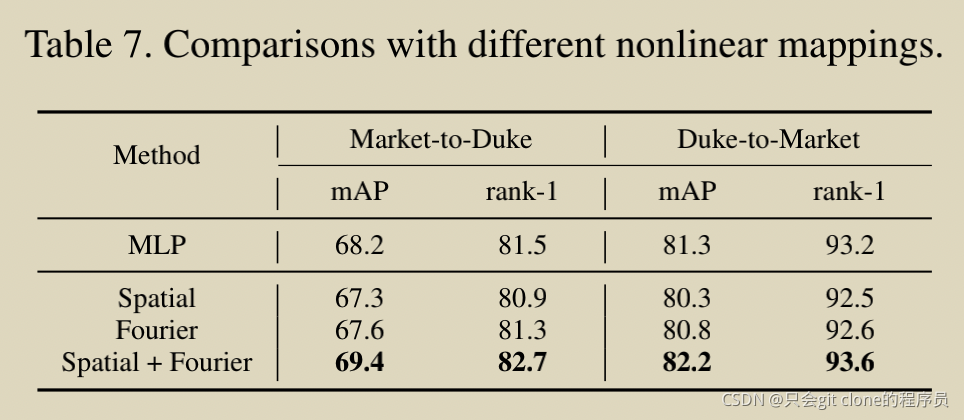
���ߵ�ʵ��֤��������Ч���������ڳ��õ�FC�㣺
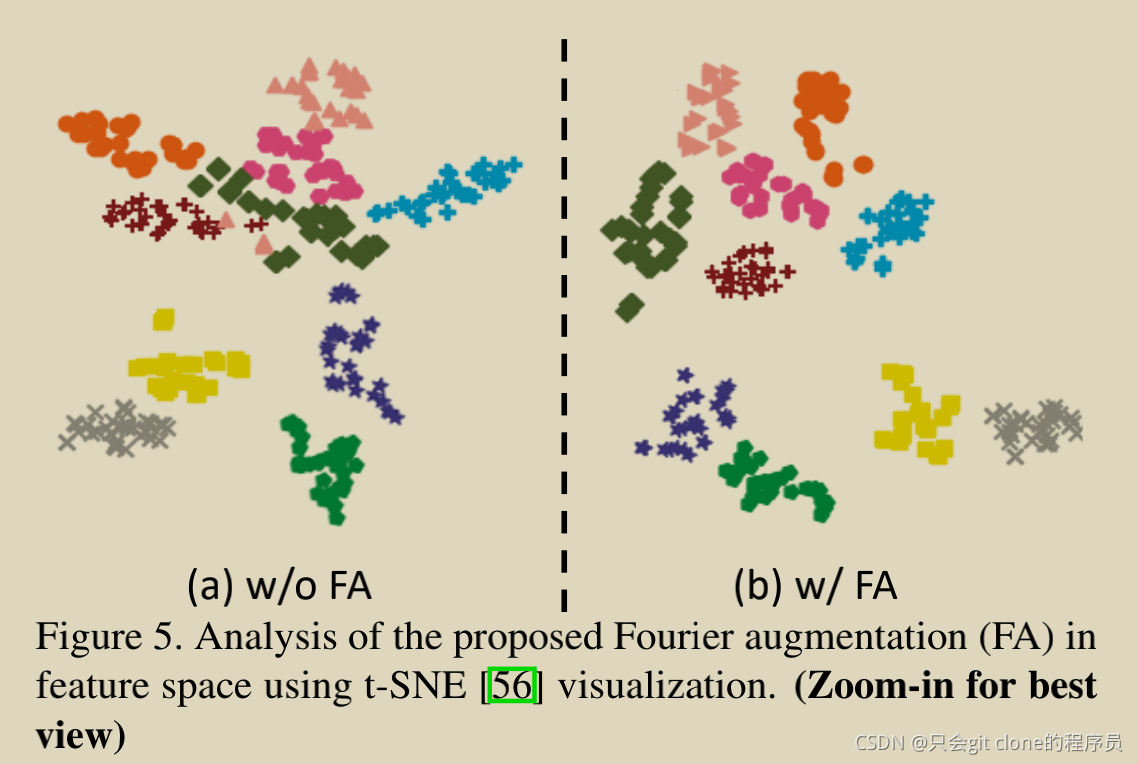
���ӻ�����FA��Ч��������ͬ����õķֿ��ˣ���
��