完整文章移步:https://www.guyuehome.com/34677
论文
Improved Mutual Mean-Teaching for Unsupervised Domain Adaptive Re-ID
主要贡献
- 提出了一个集合了伪标签和域翻译(gan)的方法。
- 优化MMT方法,把标注了的源域图像和目标域的无标签图像结合起来训练。
Pipeline
- 用SDA将源域的图像风格转换到目标域。
- 使用MMT+框架对转换的图像以及目标域的图像训练。
SDA细节
SDA主体是一个CircleGAN的过程,不同的地方在于风格转换的图像在目标域编码的时候将该特征拿出来和风格转换前的特征计算triplet loss。这样的目的是让风格转换后的图像正样本对和正负样本对间的距离与风格转换前收敛到一致,这样的话不仅实现了源域图像风格迁移到目标域,还实现了源域图像和目标域图像的分布一致。

finetune with MMT+
如果是MMT的话加上SDA大致流程如下:

对原始图像使用SDA迁移风格到目标域,然后使用迁移后的图像pretrain网络Net1和Net2(用不同的参数以及数据增强)。这时候Net1和Net2有一定的对目标域图像编码的能力。然后对目标域图像聚类得到伪标签,根据MMT框架的原理训练reid模型。
作者在比赛中升级了MMT框架,升级后的流程如下:

改进点:
- 之前MMT框架仅仅使用目标域的图像训练,MMT+将源域图像也加入了训练,但是两个域有领域差异,所以提出的解决办法是对两组数据使用不同的bn处理。bn完再混在一起用。
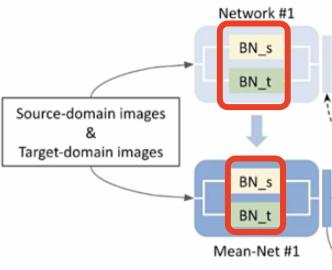
- 可能是因为gan生成图片以及在训练MMT时加入了source domain的图片的原因,作者实验发现伪标签因为噪声数据集ID分布的影响数据集的噪声更多了,对实验的结果影响较大,因此加入了MoCo loss进行训练。

MoCo loss细节

- x_q:代表某一图片(定义为P_q)的图像增强操作(旋转、平移、剪切等)后的一个矩阵;
- x_k:代表多张图片(定义为P_K, 其中P_K包含P_q)的图像增强操作后的多个矩阵的矩阵集;
- encoder,momentum encoder:分别代表两个编码网络,这两个网络的结构相同,参数不同;
- q:x_q经过encoder网络编码后的一个向量;
- k:x_k经过momentum encoder网络编码后的多个向量;
- contrastive loss(即L_q):
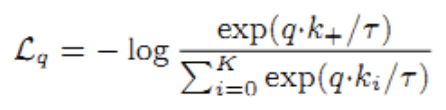
Lq趋于0
则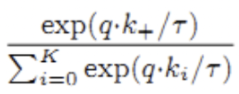 趋于1
趋于1
则负样本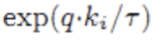 趋于0
趋于0
则负样本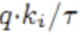 趋于负无穷
趋于负无穷
所以负样本之间的夹角趋于180度。
所以最终的优化目标是正样本的夹角趋于0负样本间的夹角趋于180度。
注意这里优化的是点乘的结果其实就是优化余弦夹角,因为q和k都进行了l2 normal。
其他涨点技巧
1、在二三阶段作者分别训练了以ResNetSt50、ResNetSt101、DenseNet169-IBN和ResNetXt101-IBN为主干网络的四个模型,最终的比赛结果是用四个模型输出的特征向量concat然后再L2-normalized得到。

2、图片风格迁移部分,使用SDA涨点情况:

3、MMT+相对于MMT涨点情况:

相对于MMT的改进
- MMT网络的pretrain数据来自SDA生成的。
- 把源域和目标域的图像都拿来训练MMT+,用不同的BN解决了领域差异大的问题。
- 加上了MoCo对比损失来减少目标域噪声ID的影响。