**写在前面的话通常很重要
对于行为分析任务,可以分为视频帧分类和依据人体关键点判定两个解决方向
而依据人体关键点判定又可以分为单人检测和多人检测
多人检测又可以分为top-down和bottom-up两种形式的解决方法,也就决定了关键点生成部分存在思路差异很大的两种方案
总之要分清这三个层级,在相同的层级之间进行对比才有意义。
另外找到一篇很优秀的综述:https://zhuanlan.zhihu.com/p/69042249
视频帧分类和依据人体关键点判定
视频帧分类的方法以TSM为主:TSM网络是在视频中抽取视频帧进行分类这种方法的代表。TSM解决的问题是“捕获时间维度的关系”。TSM在时间维度上交换了部分通道,从而在时间维度上促进了信息的交流。基本上是以零时间成本完成了对时间维度信息的建模。但直接进行这种简单的操作势必会带来一定的精度上的损失。所以文章提出了借鉴残差结构,以残差结构的形式完成通道的交换与迁移。
直接使用视频帧进行分类这个细分方向有着很庞大的理论体系,但实际落地工程中使用的比较少,因此有机会我们再说,这篇博客主要说的还是关键点生成部分。
单人检测和多人检测
单人姿态估计主要都是针对MPII数据集的工作,经典模型包括
1.Convolutional Pose Machines(2016)
2.Learning Feature Pyramids for Human Pose Estimation (ICCV2017)
3.Stacked Hourglass Networks for Human Pose Estimation(2017)
4.Multi-Context Attention for Human Pose Estimation(2018)
5.A Cascaded Inception of Inception Network with Attention Modulated Feature Fusion for Human Pose Estimation(2018)
6.Deeply Learned Compositional Models for Human Pose Estimation(2018ECCV)
7.Human Pose Estimation with Spatial Contextual Information(2019)
8.Cascade Feature Aggregation for Human Pose Estimation(2019)
9.Toward fast and accurate human pose estimation via soft-gated skip connections(2020)
但由于(1)多人检测任务是包含担任检测任务的 (2)MPII单人检测数据集的效果以接近饱和 (3)多人检测任务的准确率在近两年飞速提升 (4)实际工程中多是多人任务4个原因,单纯的单人检测任务这几年的工作寥寥无几,我们重点论述多人检测任务。
top-down和bottom-up的区别
简单说
自顶向下方式(如HRNet、Lite-HRNet)是首先检测人,然后对每个检测到的人进行单人的姿态估计。 自下而上方式要么直接回归属于同一个人的关键点位置,要么检测和分组关键点,例如affinity linking、associative embedding、HGG和HigherHRNet。由于额外的人形检测过程,自上而下方式更准确但成本(计算)更高。而自下而上方式(high-HRNet、HRNet-DEKR),则效率(计算)更高。
详细说
自上而下(Top-Down)的人体骨骼关键点检测算法主要包含两个部分,目标检测和单人人体骨骼关键点检测,对于目标检测算法,这里不再进行描述,而对于关键点检测算法,首先需要注意的是关键点局部信息的区分性很弱,即背景中很容易会出现同样的局部区域造成混淆,所以需要考虑较大的感受野区域;其次人体不同关键点的检测的难易程度是不一样的,对于腰部、腿部这类关键点的检测要明显难于头部附近关键点的检测,所以不同的关键点可能需要区别对待;最后自上而下的人体关键点定位依赖于检测算法的提出的Proposals,会出现检测不准和重复检测等现象,大部分相关论文都是基于这三个特征去进行相关改进。
自下而上(Bottom-Up)的人体骨骼关键点检测算法主要包含两个部分,关键点检测和关键点聚类,其中关键点检测和单人的关键点检测方法上是差不多的,区别在于这里的关键点检测需要将图片中所有类别的所有关键点全部检测出来,然后对这些关键点进行聚类处理,将不同人的不同关键点连接在一块,从而聚类产生不同的个体。而这方面的论文主要侧重于对关键点聚类方法的探索,即如何去构建不同关键点之间的关系。
详细讲讲人体关键点生成的那些算法
根据上面提到的自上而下(Top-Down)方法的需要解决的问题,有以下工作
1.RMPE: Regional Multi-Person Pose Estimation(2018)
本论文主要考虑的是自上而下的关键点检测算法在目标检测产生Proposals的过程中,可能会出现检测框定位误差、对同一个物体重复检测等问题。检测框定位误差,会出现裁剪出来的区域没有包含整个人活着目标人体在框内的比例较小,造成接下来的单人人体骨骼关键点检测错误;对同一个物体重复检测,虽然目标人体是一样的,但是由于裁剪区域的差异可能会造成对同一个人会生成不同的关键点定位结果。本文提出了一种方法来解决目标检测产生的Proposals所存在的问题,即通过空间变换网络将同一个人体的产生的不同裁剪区 (Proposals)都变换到一个较好的结果,如人体在裁剪区域的正中央,这样就不会产生对于一个人体的产生的不同Proposals有不同关键点检测效果。
2.Cascaded Pyramid Network for Multi-Person Pose Estimation(CPN)(2018)
这篇文章是由Face++团队发表的COCO17个关键点检测的冠军方案,本论文主要关注的是不同类别关键点的检测难度是不一样的,整个结构的思路是先检测比较简单的关键点、然后检测较难的关键点、最后检测更难的或不可见的关键点。分为两个stage,GlobalNet和RefineNet其中GlobalNet主要负责检测容易检测和较难检测的关键点,对于较难关键点的检测,主要体现在网络的较深层,通过进一步更高层的语义信息来解决较难检测的关键点问题;RefineNet主要解决更难或者不可见关键点的检测,这里对关键点进行难易程度进行界定主要体现在关键点的训练损失上,使用了常见的Hard Negative Mining策略,在训练时取损失较大的top-K个关键点计算损失,然后进行梯度更新,不考虑损失较小的关键点。
3.Rethinking on Multi-Stage Networks for Human Pose Estimation(MSPN)(2019)
时隔一年,Face++团队又拿下了COCO18个关键点检测冠军。提出了多阶段姿态估计网络(MSPN)有三个新的技术。首先,当前多阶段方法中的单级模块远非最优。例如,沙漏在所有块中使用相等宽度的通道用于向下和向下提取。这种设计与当前网络架构设计(ResNet)不一致。作者发现采用现有良好的网络结构进行下采样路径和简单的上采样路径要好很多。其次,由于重复的向下和向上采样步骤,信息更容易丢失,优化变得更加困难。作者建议在不同阶段汇总特征以加强信息流动并减轻培训的难度。最后,观察姿势定位精度逐渐提高。在多阶段,作者采取粗到细的多监督方式。
4.Spatial Shortcut Network for Human Pose Estimation(SSN)(2019)
现有的基于姿态估计的方式,是通过逐像素分类实现的,这种方式是考虑不到大范围的空间信息的。举例来说:由于肘关节的外观与膝关节非常相似,对于一个感受野仅能覆盖肘关节本身的小特征提取器,很难将两者区分开来。但如果感受野能同时看到附近的手腕或肩膀,那么将其归类为肘部就容易得多。在涉及姿态估计的方法中,需要抑制非主要人体部位的检测。对卷积网络而言,只要将网络变的更深,或者增大卷积核,就能够促进空间信息流动,我们就可以增加最终特征的感受野。感受野增加了,上述提到的问题能够被较好的解决。然而不论是大卷积核还是深网络,这对计算和训练都带来了较大的挑战。为了空间信息能够低成本的流动,本文提出了一种针对于姿态估计任务的空间连接网络,使信息在空间上的流动更容易。本文提出的网络为spatial shortcut network (SSN)。该网络将特征映射移动和注意机制结合在一个称为特征移动模块feature shifting module(FSM)中。该模块在参数数量和计算成本上都与普通卷积层一样轻量,并可以插入到网络的任何部分来补充空间信息。
5.Deep High-Resolution Representation Learning for Human Pose Estimation (2019cvpr)
HRNet的体系结构。它由并行的高到低分辨率子网组成,并在多分辨率子网之间进行重复的信息交换(多尺度融合)。即模型是通过在高分辨率特征图主网络中逐渐并行的加入低分辨率特征图子网络,不同网络实现多尺度融合与特征提取实现的。
自下而上(Bottom-Up)方式的比较出色的网络包括
1.OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields(IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE2019)
目前,已经有了许多关于检测的工作。许多的检测方式都是先想办法检测出身体的部位的关节点,然后再连接这些部位点得到人的姿态骨架。 本文的工作差不多也是这个套路,但是为了快速的把点连到一起,提出了Part Affinity Fields这个概念来实现快速的关节点连接。
openpose的人体关键点部分是基于Convolutional Pose Machine(CPM)和realtime multi-person pose estimation这2篇paper的模型做出来的
CPM的模型采用的大卷积核来获得大的感受野,这对于推断被遮挡的关节是很有效的。网络结构如下
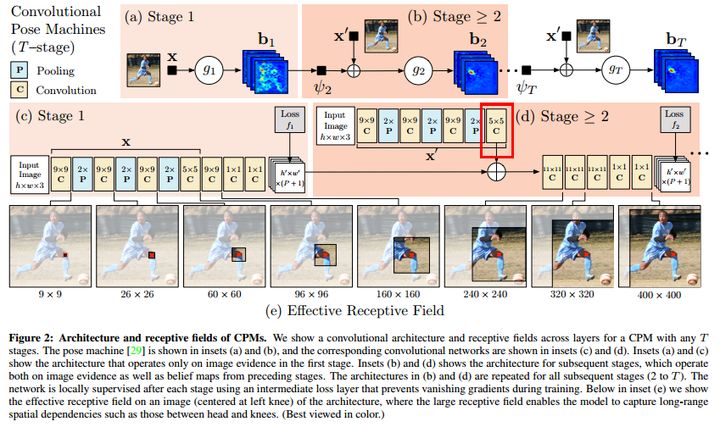
整个算法的流程是:
1)首先对图像的所有出现的人进行回归,回归各个人的关节的点
2)然后根据center map来去除掉对其他人的响应
3)最后通过重复地对预测出来的heatmap进行refine得到最终的结果
在进行refine的时候,需要引入中间层的loss,从而保证较深的网络仍然可以训练下去,不至于梯度弥散或者爆炸。这种思路很好,通过coarse to fine来逐渐提升回归的准确度。
2.realtime multi-person pose estimation的算法思想(多人姿态估计)

该网络的结构与CPM其实很类似,也是通过CPM的方式先将一幅图中所有人的关节点都回归出来,此外还同时回归出part affine field(PAF),什么是part affine field?看了下面的图你就明白了。

实际上就是两个关节之间的连接所产生的heatmap。为什么要提PAF?因为本文的方法使用的是自底向上的方法即先回归出所有人的关节点,然后再对这些关节点进行划分,这样就可以把关节分配到每个人。至于怎么划分,就是通过PAF来进行划分。
最后具体流程为:
(a)输入图像 --> (b)预测关键点置信度 & (c)关键点亲和度向量 --> (d)关键点聚类 --> (e)骨架组装
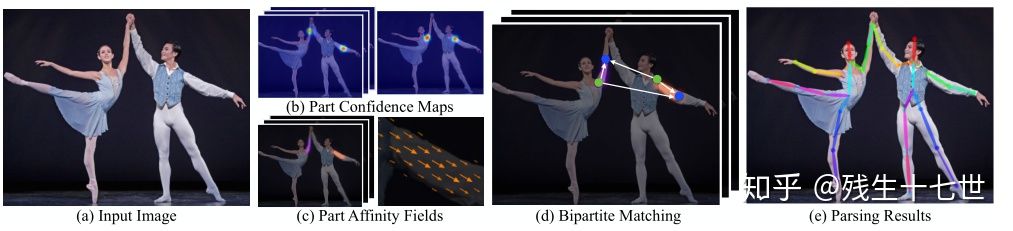
最后这个流程很重要,代表了Bottom-Up方法的一般思路
两个很好的接到OpenPose的回答:https://www.zhihu.com/question/59750782/answer/207238452和
3.DEKR的提出:我习惯于称它为HRNet-DEKR,你可以在我之前的文章中找到他(之前的文章:行为分析(二):姿态估计部分(二):HRNet-DEKR)
DEKR模式的详解:https://mp.weixin.qq.com/s?__biz=MzU2NjU3OTc5NA==&mid=2247531425&idx=1&sn=ff45ac9cbb454201821b4e51778ff11d&chksm=fca87c9ccbdff58a8275a0084ca9c8bf85653384e73eeb526be0250c025777a2b0f9d752a810&scene=21#wechat_redirect
轻量级网络系
现在有些网络直接拿轻量级网络作为backbone去回归heatmap,有机会再聊
参考
链接1:https://zhuanlan.zhihu.com/p/69042249
链接2:知乎问题:“如何评价卡内基梅隆大学的开源项目 OpenPose?”