一、ego-motion的概念
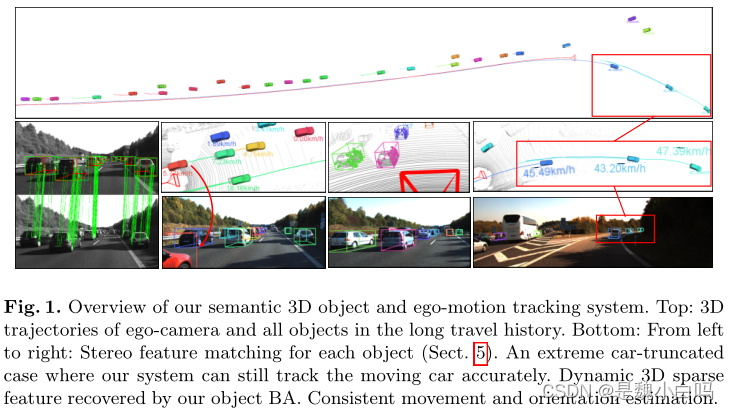
总览
ego-motion 指的是相机自身的运动,具体描述为相机与其所感知的环境的相对运动。ego-motion的概念常出现于机器人或者自动驾驶汽车的状态估计中。因相机与机器人或者汽车处于固定状态,所以相机的ego-motion与机器人的状态估计只需要一个坐标系转换即可换算。
更详细的解释是
估计相机的自我运动的目的是使用相机拍摄的一系列图像来确定相机在环境中的3D运动。估计环境中摄像机运动的过程涉及在移动摄像机捕获的图像序列上使用视觉测距技术。通常,这是通过特征检测从两个图像帧构建光流来完成的,这些图像帧是从单个摄像机或立体摄像机生成的序列。对每帧使用立体图像对有助于减少误差,并提供更多的深度和比例信息。在第一帧中检测特征,然后在第二帧中进行匹配。然后,此信息用于为那两个图像中的检测到的特征建立光流场。光流场说明了特征如何从单个点发散,即扩展的焦点。可以从光流场检测扩展焦点,该光流场指示摄像机的运动方向,从而提供摄像机运动的估计。还有从图像中提取自我运动信息的其他方法,包括避免特征检测和光流场并直接使用图像强度的方法。
二、摘要
1.提出一种基于双目视觉的在动态自动驾驶场景下追踪相机和3D语义物体的方法。
2.代替使用端到端的方法直接生成物体的3D检测框,利用易于标记的2D检测结果和离散的观测点分类,并通过一个轻量级的语义推断方法得到物体粗略的3D测量。
3.基于在动态环境中鲁棒的物体感知辅助相机位姿跟踪。
4.结合新提出的动态物体集束调整(BA)方法将时序的稀疏特征关联和语义3D测量模型融合到一个统一的优化框架中。
5.获得了具有实例精度和时间一致性的3D物体姿态、速度和锚定动态点云估计。
6.提出的方法的性能在不同的场景中得到证明。相机运动估计和目标定位的性能都与最先进的解决方案进行了比较。
三、方法
语义追踪系统有三个主要的模块
第一个模块执行2D物体检测和观测点分类,利用这两个输出并借助2D检测框的边与3D检测框上的点之间的约束粗略的推断物体的位姿。
第二个模块是特征提取和匹配,将所有推断出来的3D检测框投影到2D图像上得到物体轮廓和遮挡掩模,以此引导的特征匹配被用于在立体图像和时序图像上获取鲁棒的特征关联。
在第三个模块中,所有的语义测量和特征测量被紧耦合到一个优化方法中,用于相机和物体位姿的求解。

第一部分展示的视点分类与3D box的推断
过程是将原始图像统一依次送入Conv layers/ROI Pooling中后,分别送入一个FC层中
而后各自经过2D Box的回归操作和视点的Softmax操作
最终结合这两个分支的结果进行那个3D Box的推断(Inference)
第一部分的细节包括
2D box和viewpoint的生成
利用Faster R-CNN进行2D图像的目标检测。由于实时性的需求,仅在双目的左图上进行检测。
如图所示,本文在传统的网络结构基础上在最后一个全卷积层添加子分类,不仅可以回归2D检测结果,还可以标记出物体的水平和垂直观测点。

对于水平和垂直观测点的解释:其实就是16个类别的区分过程,作者认为水平方向连续的8个观测位置和垂直方向的两个位置的16种组合足以包括目标在相机中的状态。
图3b展示了由其中的两个观测方向组合而成的观察及其状态。
这部分还要有一个假设,即生成的3D box中的4个角点是与回归得到的2D box中的某些边贴合的。
这样,在得到观测点后,就可以基于2D box中的边和3box中的顶点之间的关联,以及3D的重投影假设,生成初步的3D box。
但其实多数时候2D box的边与3D box的顶点之间是不完全贴合的,因此这部分生成的结果只能作为之后优化部分的初始化。但有这个初始化就已经很不错了。
3D Box的推断
为了推断3D检测框,这里做了一种假设:3D检测框在图像上的的投影会紧密贴合2D检测框,如图2(b)所示。我们现在得到了归一化平面上的2D检测框 [umin, vmin, umax, vmax]和观测点,接下来推断3D检测框。物体的3D检测框由下面三个值统一表示:中心点位置 p = [px, py, pz]^T,物体相对于相机的水平方向 θ,物体的先验尺寸 d = [dx, dy, dz]^T。其中,前两个变量 p, θ 用于表示物体的4自由度位姿。为了推断物体的3D检测框或者说物体的位姿,我们可以在图2(b)中得到4个约束关系,即3D检测框的四个点被投影到2D检测框边界上:
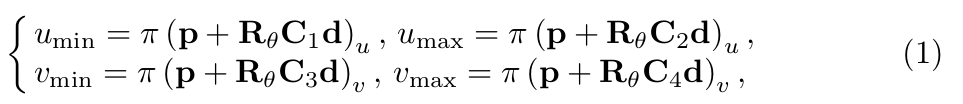
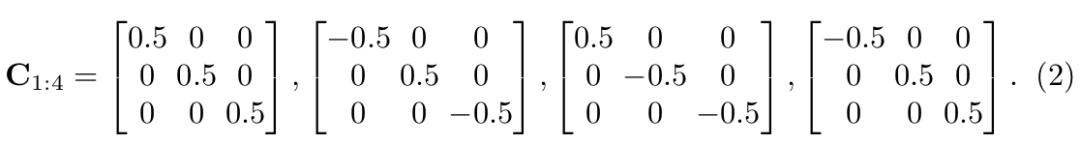
π是从相机坐标系到归一化平面的投影矩阵,Rθ表示从物体坐标系转化到相机坐标系,由θ参数化。公式(2)中,C1:4表示对角选择矩阵描述3D检测框中心点和与2D检测框边界相交的4个点①②③④之间的位置关系。当全卷积层输出了观测点,我们也就得到了对应的C1:4。例如上面给出的C1:4即为图2(b)中观测点下对应的选择矩阵。公式(1)中,第一个解释为以中心点为起点,向xyz三个方向的正方向各增加对应维度先验尺寸的一半得到点①,第二个解释为以中心点为起点,向x, z的反方向增加先验尺寸dx, dz的一半,向y的正方向增加先验尺寸dy的一半得到点②,这其中包含着由Rθ决定的从物体坐标系向相机坐标系的转换,再将点①②从相机坐标系转化到归一化平面正好和2D检测框边界相交,其余两个同理。这样,我们就得到了公式(1),用这四个等式就可以求解物体的4自由度位姿,同时也得到了3D检测框。
第二部分是特征提取与匹配过程
首先接收第一部分生成的物体轮廓与遮挡淹膜(Object Contour and Occlusion Mask Generation)
然后还需要获取物体在时间上的关联,经由ORB特征提取后得到特征的时序和立体的匹配。
特征提取与匹配
首先,在2D检测框内和背景分别提取特征点,由于只有左图被检测,所以需要将左图推断出来的3D检测框投影到右图得到物体的轮廓。这里的特征匹配包含两部分:用于双目的立体匹配计算视差和深度值,用于时序匹配的数据关联。
立体匹配通过极线搜索进行,由于物体的粗略位姿已知,物体上的特征点深度范围是已知的,所以我们可以在进行极线搜索的时候将搜索区域限制到一个很小的范围内,提高立体匹配的鲁棒性。
时序匹配通过对连续帧的2D检测框的相似性进行判断,首先通过帧间转换矩阵将上一帧的检测框转到下一帧坐标系并和下一帧原有的2D检测框进行相似性判断,相似性分数通过中心点距离和形状的相似性共同决定,以此进行帧间的数据关联。
第三部分展示的是将前两个阶段生成的信息放入同一个紧耦合的框架中优化
可以看到这个过程是首先将Background Feature进行Camera BA操作,然后将结果与Object Feature/Semantic Info/Motion Model/Camera Pose一起
继续Object BA操作。
相机和物体的运动追踪
在一个通常的自动驾驶场景中,我们的目标有三个:
(1) 连续估计相机的运动
(2) 连续追踪3D物体的位置
(3) 恢复动态稀疏特征点的3D位置
在这里,k表示物体序号,k=0表示背景;n表示第k个物体上的特征点序号;t表示时间或者帧的序号。部分符号可视化如图4所示。
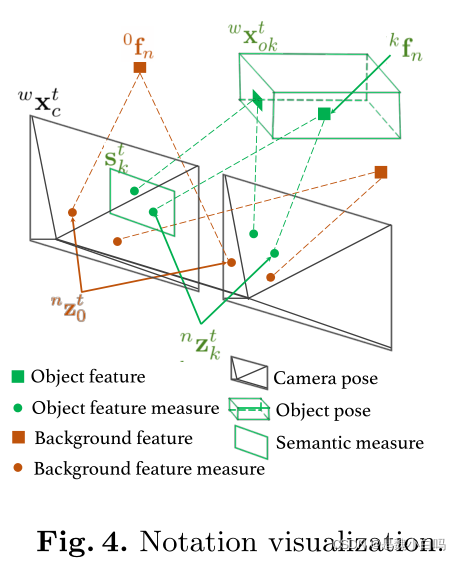
首先针对目标(1),利用背景特征点的重投影误差来构建优化的最小二乘。由于没有先验信息可以利用,我们直接计算目标函数的最大似然,并假设观测模型服从高斯分布,将最大似然问题转化为马氏距离的BA问题。在这里,我们要求解的是相机的位姿和背景特征点的位置。
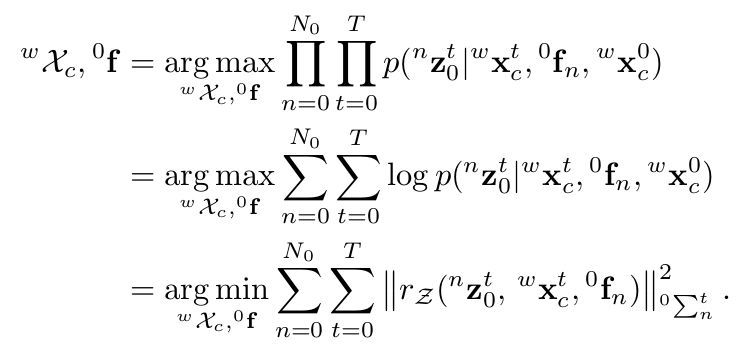
针对目标(2)和目标(3),我们需要求解出物体的位姿和物体上特征点的位置。在这里,我们假设物体为刚体,即物体上的特征点相对于物体坐标系是固定不动的,因此,如果我们有了对物体上特征点的连续观测,那么物体的时序状态也是与之相关的。
我们有了对物体的先验尺寸,因此建立一个最大后验估计问题并转化为似然和先验之积。
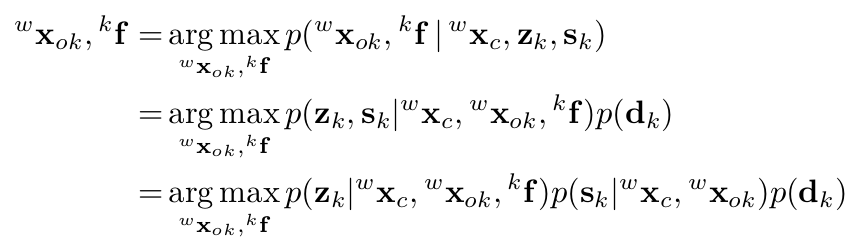
接下来,我们将似然函数分解出三部分,并将最大后验问题转化为基于马氏距离的最小二乘问题,如公式(10)所示。公式中包含四部分误差项,下面分别介绍:

第一项为物体上特征点的重投影误差。仔细比较发现它与计算相机位姿时的最小二乘公式形式 (背景点的重投影误差) 十分相似。区别在于这里将静态特征和相机位姿扩展为动态特征和物体位姿。如下面公式所示,该误差项分为两部分,分别是左右两图上的重投影误差,两部分形式相似。左图上的重投影误差定义为:将第k个物体上的第n个特征点通过估计的物体位姿从物体坐标系转换到世界坐标系,再投影到相机坐标系,再通过π函数转换到归一化平面,计算投影的点坐标和观测值之差作为重投影误差。

第二项为物体的尺寸先验。第三项为运动模型误差,通过该运动模型能够从t-1时刻车的状态推断k时刻车的状态,还能连续追踪车的速度和方向。该项误差定义为通过运动模型预测的t时刻状态减去估计的t时刻状态。

第四项为物体的语义观测误差。我们在前面通过公式(1)的四个等式关系求得一个粗略的物体位姿,现在则要将前面的等式关系构建为一个关于待优化的物体位姿的最小二乘误差项,原理和前面相同。
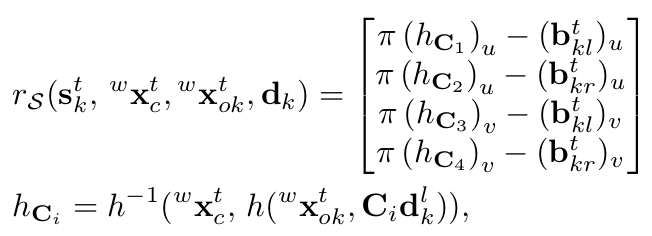
最小化所有误差后,我们得到最大后验估计的物体位姿。但是,由于物体尺寸的差异,位姿会有一定的偏差,因此需要将3D 检测框和恢复的物体稀疏点云进行对齐。