数据归一化及两种常用归一化方法
min-max标准化(Min-Max Normalization)
也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0 , 1]之间。转换函数如下:
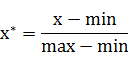
其中max为样本数据的最大值,min为样本数据的最小值。这种方法有个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
min-max标准化python代码如下:
import numpy as nparr = np.asarray([0, 10, 50, 80, 100])
for x in arr:x = float(x - np.min(arr))/(np.max(arr)- np.min(arr))print x# output
# 0.0
# 0.1
# 0.5
# 0.8
# 1.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Z-score标准化方法
也称为均值归一化(mean normaliztion), 给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1。转化函数为:
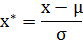
其中 μ 为所有样本数据的均值,σ为所有样本数据的标准差。
import numpy as nparr = np.asarray([0, 10, 50, 80, 100])
for x in arr:x = float(x - arr.mean())/arr.std()print x# output
# -1.24101045599
# -0.982466610991
# 0.0517087689995
# 0.827340303992
# 1.34442799399【ML】数据预处理
前言
对于数据的预处理,没有固定的步骤。
下文写的仅仅的常规的一些小步骤。
具体的预处理,还需要根据数据以及需求来自行处理。
====================================
Python
STEP1、导入依赖包
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
- 1
- 2
- 3
把np作为numpy的缩写,后面可以直接使用np来调用各种方法。
==>
numpy系统是python的一种开源的数值计算扩展。
这种工具可用来存储和处理大型矩阵,比python自身的嵌套列表结构要高效的多。
你可以理解为凡是和矩阵有关的都用numpy这个库。
==>
matplotlib.pyplot是用来做数据的展示。也就是数据的可视化。
==>
pandas该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
pandas提供了大量能使我们快速便捷地处理数据的函数和方法。它是使python成为强大而高效的数据分析环境的重要因素之一。
========
选择好这三行代码,敲下shift+return组合键。

如果结果如下,说明库已经导入了。
我们的环境配置也完全没有问题。
如果环境的配置有问题,参考博客:
http://blog.csdn.net/wiki_su/article/details/78404808
STEP2、读取数据
原始数据在云盘,有需要的自行下载吧。
链接:http://pan.baidu.com/s/1eRHXACU
密码:4q8c
在Spyder中,设置好文件路径。千万不要忘了。

输入下面的代码。然后选择这行代码,敲下shift+return组合键。
#import dataset
dataset = pd.read_csv('Data.csv')
- 1
- 2
我们在explorer中会看到我们命名的dataset。

双击打开

根据上面的dataset的那个图我们可以看出,我们的目的是想要通过地区,年龄,薪资来看购买力。
那我们把country,age,salary作为X,purchased作为Y。
得到二者之间的关系,就得到了country,age,salary和purchased之间的某种关系。
#取出所有的行,(去掉最后一列 purchased)
X = dataset.iloc[:,:-1].values取出结果
Y = dataset.iloc[:,3].values
- 1
- 2
- 3
- 4
- 5
运行结果如下:

然后我们双击打开X,会发现打不开。这个是因为数据类型的原因。

我们可以在代码中输入X,然后选中运行。

STEP3、遗失数据的处理
我们回过头在看上面的dataset的图。
我们会发现数据缺少几个。他用了nan来标记缺失的数据。
注意:
对于缺失的数据,我们大体上有3中处理方法:
1、通过数据中的最大值和最小值,我们把中间值赋值给缺失的数据;
2、通过所有数据的平均值来赋值给缺失的数据;
3、删除有空缺数据项;
择优排队的结果是:1 > 3 、 2 > 3
因为在大部分的时候,我们的数据会非常稀少。每一个数据都来之不易。我们不能轻易的删掉。
============
导入库。这个库就是专门做数据预处理的。
#预处理impoter
from sklearn.preprocessing import Imputer#做遗失的部分的处理 用NaN的方式填补上来
#axis:传0或者。0代表处理列 ,1代表处理行。
#strategy的值有mean,median,most_frequent ,分别代表:平均数 中间值 最常出现的数值
imputer = Imputer(missing_values = 'NaN',strategy = 'mean', axis = 0)#1-3行缺失的部分补上
imputer = imputer.fit(X[:,1:3])#返回处理好的数据
X[:,1:3] = imputer.transform(X [:,1:3])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
对于这个方法,我们不熟悉可以通过Help来查看。不过前提是
from sklearn.preprocessing import Imputer这行代码运行过。

然后我们运行下,会发现缺失的数据已经被我们填充好了。

STEP4、数据明确化
数据明确就是为了提高运行的速度和准确性。
当然我们不进行数据明确也可以…为了更好,还是加上这步吧。
我们看country 和 purchased ,如果都变成用数字表示。那我们运行的效率就提升上去了。
热编码的优点:
1.能够处理非连续型数值特征。
2.在一定程度上也扩充了特征。
#数据明确
#提高运行的速度和准确性
#把数据明确化,变成数字
#OneHotEncoder 热编码
from sklearn.preprocessing import LabelEncoder,OneHotEncoder#把城市数据进行数字明确化
labelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])#热编码,拿出来做数组的编排
onehotencoder = OneHotEncoder()
X = onehotencoder.fit_transform(X).toarray()#把结果数据进行城市化
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
运行,然后我们看下结果:


STEP5、数据分割
数据分割。是把数据分为两组。一组A用来训练,一组B是用来测试。
然后通过测试数据的Y,用训练组的模型得到的Y值进行比较。
就是比较B.Y 和 ResultA (B.X) 的值是否一样,如果一样或者差别不大,那么我们做出来的模型就是可靠的。
#数据分割
from sklearn.cross_validation import train_test_split#0 取一次就好了,不要每次都取两组随机的数字
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size = 0.2,random_state = 0)
- 1
- 2
- 3
- 4
- 5
我们就可以看到分割好的两组数据。
X_train、Y_train
X_test 、Y_test

STEP6、数据缩放
数据缩放把这些数据,规范在一个范围中。
如果不这么做的话,比如 0 ,0.001, 0.2, 99… 这类数据非常不易看。
from sklearn.preprocessing import StandardScaler#缩放
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
Y_train = sc_X.fit_transform(Y_train)
Y_test = sc_X.fit_transform(Y_test)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

我们打开X_train,然后format调成小数一位。结果如下。

以上就是数据预处理的几步了。
END 完整代码
#数据预处理 data preprocessingimport numpy as np
import matplotlib.pyplot as plt
import pandas as pd#import dataset
dataset = pd.read_csv('Data.csv')#Matrix of feature
X = dataset.iloc[:,:-1].values
Y = dataset.iloc[:,3].values#预处理impoter
from sklearn.preprocessing import Imputerimputer = Imputer(missing_values = 'NaN',strategy = 'mean', axis = 0)
imputer = imputer.fit(X[:,1:3])
#返回处理好的数据
X[:,1:3] = imputer.transform(X [:,1:3])#数据明确
from sklearn.preprocessing import LabelEncoder,OneHotEncoderlabelencoder_X = LabelEncoder()
X[:,0] = labelencoder_X.fit_transform(X[:,0])onehotencoder = OneHotEncoder()
X = onehotencoder.fit_transform(X).toarray()labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)#数据分割
from sklearn.cross_validation import train_test_split#0 取一次就好了,不要每次都取两组随机的数字
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size = 0.2,random_state = 0)#缩放X
from sklearn.preprocessing import StandardScalersc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)
Y_train = sc_X.fit_transform(Y_train)
Y_test = sc_X.fit_transform(Y_test)