GhostNet: More Features from Cheap Operations翻译笔记
-
- 摘要
- 1. Introduction
- 2. Approach
-
- 2.1 Ghost Module for More Features
- 2.2 Building Efficient CNNs
- 3. 结论
摘要
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,论文思想十分值得参考与学习。
1. Introduction
目前,神经网络的研究趋向于移动设备上的应用,一些研究着重于模型的压缩方法,比如剪枝,量化,知识蒸馏等,另外一些则着重于高效的网络设计,比如MobileNet,ShuffleNet等。

如上图所示,ResNet-50中,将经过第一个残差块处理后的特征图,会有出现很多相似的“特征图对”――它们用相同颜色的框注释。
这样操作,虽然能实现较好的性能,但要更多的计算资源驱动大量的卷积层,来处理这些特征图。“特征图对”中的一个特征图,可以通过廉价操作(上图中的扳手)将另一特征图变换而获得,则可以认为其中一个特征图是另一个的“幻影”。
这是不是意味着,并非所有特征图都要用卷积操作来得到?“幻影”特征图,也可以用更廉价的操作来生成?
于是就有GhostNet的基础――**Ghost模块,用更少的参数,生成与普通卷积层相同数量的特征图,其需要的算力资源,要比普通卷积层要低,**集成到现有设计好的神经网络结构中,则能够降低计算成本。
训练好的网络一般都有丰富甚至冗余的特征图信息来保证对输入的理解,如图1 ResNet-50的特征图,相似的特征图类似于对方的ghost。冗余的特征是网络的关键特性,论文认为与其避免冗余特征,不如以一种cost-efficient的方式接受,获得很不错的性能提升,论文主要有两个贡献:
- 提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图,Ghost模块的整体的参数量和计算量就已经降低了。
- 基于Ghost模块提出GhostNet,将原始的卷积层替换为Ghost模块
2. Approach
2.1 Ghost Module for More Features

Ghost模块


class GhostModule(nn.Module):def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):super(GhostModule, self).__init__()self.oup = oupinit_channels = math.ceil(oup / ratio) # 参考论文m = n/snew_channels = init_channels*(ratio-1) # n(s-1)/sself.primary_conv = nn.Sequential(nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),nn.BatchNorm2d(init_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)self.cheap_operation = nn.Sequential(nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),nn.BatchNorm2d(new_channels),nn.ReLU(inplace=True) if relu else nn.Sequential(),)def forward(self, x):x1 = self.primary_conv(x)x2 = self.cheap_operation(x1)out = torch.cat([x1,x2], dim=1)return out[:,:self.oup,:,:]
primary_conv是预先卷积,他的输出通道数为 output_channel / ratio,然后是简单的线性变换cheap_operation,他是对预先卷积模块的每张特征图都做一遍卷积,因此他的groups就是init_channels,他输出通道数是new_channels。
这两个模块加在一起生成的通道数就是init方法里面定义的self.oup。前向传播部分就是先对输入张量预先卷积,然后对特征图做变换,最后concat到一起输出。
Difference from Existing Methods.
与目前主流的卷积操作对比,Ghost模块有以下不同点:
- 对比Mobilenet、Squeezenet和Shufflenet中大量使用1×11\times 11×1 pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量;Ghost模块中的初始卷积是点卷积(Pointwise Convolution)
- 目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征;
- 目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性;
- Ghost模块同时使用identity mapping来保持原有特征。
Analysis on Complexities
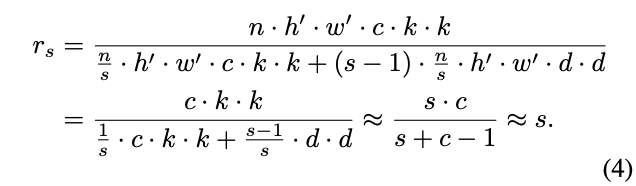
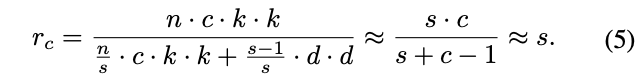
2.2 Building Efficient CNNs
Ghost Bottlenecks

Ghost Bottleneck(G-bneck)与residual block类似,主要由两个Ghost模块堆叠二次,第一个模块用于增加特征维度,增大的比例称为expansion ration,而第二个模块则用于减少特征维度,使其与shortcut一致。G-bneck包含stride=1和stride=2版本,对于stride=2,shortcut路径使用下采样层,并在Ghost模块中间插入stride=2的depthwise卷积。为了加速,Ghost模块的原始卷积均采用点(pointwise)卷积。
class GhostBottleneck(nn.Module):def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):super(GhostBottleneck, self).__init__()assert stride in [1, 2]self.conv = nn.Sequential(# pwGhostModule(inp, hidden_dim, kernel_size=1, relu=True),# dwdepthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),# Squeeze-and-ExciteSELayer(hidden_dim) if use_se else nn.Sequential(),# pw-linearGhostModule(hidden_dim, oup, kernel_size=1, relu=False),)if stride == 1 and inp == oup:self.shortcut = nn.Sequential()else:self.shortcut = nn.Sequential(depthwise_conv(inp, inp, 3, stride, relu=True),nn.Conv2d(inp, oup, 1, 1, 0, bias=False),nn.BatchNorm2d(oup),)def forward(self, x):return self.conv(x) + self.shortcut(x)GhostNet

基于Ghost bottleneck,GhostNet的结构如图7所示,将MobileNetV3的bottleneck block替换成Ghost bottleneck,部分Ghost模块加入了SE模块。
Width Multiplier
尽管表7的结构已经很高效,但有些场景需要对模型进行调整,可以简单地使用α \alphaα对每层的维度进行扩缩,α\alphaα称为width multiplier,模型大小与计算量大约为α2\alpha^2α2 倍。
3. 结论
为了降低目前深度神经网络的计算成本,提出了一种新的用于构建高效神经体系结构的Ghost模块。基本的Ghost模块将原始卷积层分成两部分,并使用更少的滤波器来生成几个固有的特征映射。然后,将进一步应用一定数量的廉价变换操作来高效地生成重影特征图。在基准模型和数据集上进行的实验表明,该方法是一个即插即用的模块,用于将原始模型转换为紧凑模型,同时保持相当的性能。此外,使用提议的新模块构建的GhostNet在效率和准确性方面优于最先进的便携式神经架构。