����Ŀ¼
-
- ���������
- (��Ϣ��+��Ϣ����)&ID3
- (����+����ϵ��)&CART
- ��Ϣ������&C4.5
- ���־������Ƚ����ܽ�
- ���������ʵս
-
- ����sklearn��ʵ�ֻع������
- �ֶ�ʵ��ID3������
- ʹ��sklearn��ع������Ԥ��boston����
- ʹ��sklearn������������iris����
���������
�������������˽���ʲô�Ǿ�������

��ͼ����һ�Ŵ��о��ߵ����������������¶ȵȳ�Ϊ�����������ʺŵ�λ�ó�Ϊ��ֵ�����¶�=35�㣬����ֵΪ35��
- ��������һ�ֻ����ķ�����ع鷽����������Ҫ���۾��������ڷ��ࡣ
- �������Ľ�������߷ֱ��ʾ
- �ڲ�����ʾһ�������������ԡ�
- Ҷ�ӽ���ʾһ�����ࡣ
- ����ߴ�����һ�����ֹ���
- �������Ӹ���㵽�ӽ��ĵ�����ߴ�����һ��·����
- ��������·���ǻ��Ⲣ�����걸�ġ�
- �þ���������ʱ���Ƕ�������ij���������в��ԣ����ݲ��Խ������������
- ������������䵽�������ӽ���ϣ�ÿ���ӽ���Ӧ��������һ��ȡֵ��
- ���������ŵ㣺�ɶ���ǿ�������ٶȿ졣
- ������ѧϰͨ������3�����裺
- ���ݱ�ע
- ����ѡ��
- ���������ɡ�
- �����ʶ��
������ģ�Ϳ�����Ϊ��if-then����ļ��ϡ�������ѧϰ���㷨ͨ���DZ���ѡ����������������ֵ�������ݸ�������ѵ�����ݽ��зָʹ�öԸ��������ݼ���һ����õķ��࣬��һ���̶�Ӧ�������ռ�Ļ��֣�Ҳ��Ӧ�ž������Ĺ�����
(��Ϣ��+��Ϣ����)&ID3
��Ϣ��(Entropy)����������ȷ���Եģ�����Խ����Ϣ�IJ�ȷ����Խ���ڻ���ѧϰ�еķ������⣬��ô����ǰ������Խ�����IJ�ȷ���Ծ�Խ��
H(D)����һ�����������أ��ص���ѧ��ʽ���£�
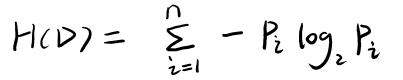
n�Ƿ������Ŀ��pip_ipi?�ǵ�ǰ������ĸ��ʡ�
ϸ��һ�£����10��Ӳ�ң���������10�����棬û�з��棬��ô��Ϣ��Ϊ0��������ʾ��
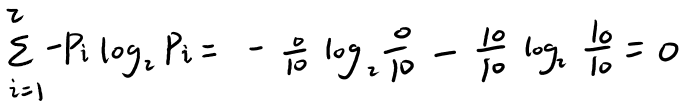
��Ϣ��Ϊ0������ζ����Ϣȷ��������ζ�ŷ�������ˡ�
��ԭ�������� H(D) ������һ�����ѽڵ㣬ʹ���ر����H(D|A)����**��Ϣ����(Information Gain��IG)**Ϊ��
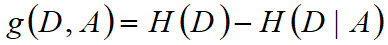
A��ѡ����Ϊ�������ݵ�������g(D,A)Ҳ��Ϊ������
����Ϣ���� = ����ǰ����Ϣ��-���Ѻ����Ϣ��
Ҳ�и���ȷ�Ķ��巽����
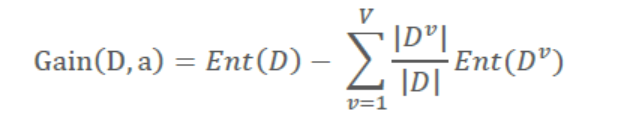
V��ʾ��������a��������D����(����)��õ��ܹ��������(һ���Ƕ�����)��DvD^vDv��ʾÿһ�������������������Ent(D)��H(D)�ĺ�����ͬ����ʾ��Ϣ��
�������ж�ѧ���û��İ�����������Ϣ�غ���Ϣ���棺

��1���ڳ�ʼ״̬�£���10��ѧ����7���Ǻ�ѧ����3�����Ǻ�ѧ��������������Ϣ��(��ʱֻ��һ�����ڵ�) H(D)=0.88��������ʾ��
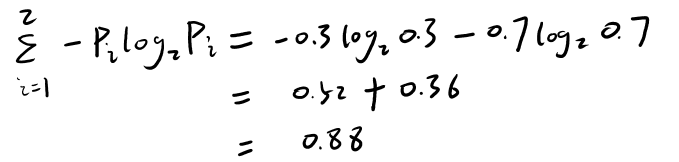
��2�����Ǹ��ݷ�����������������з��ѣ����÷�������ֵΪ70��������Ѻ�������Ϣ��H(D|A1)=0.4344��������ʾ��

��3����(2)�������з�����Ϊ�����ʣ����ó�������ֵΪ75%��������Ѻ�������Ϣ��H(D|A2)=0.79��������ʾ��

������ļ����У����ǵõ���3���أ�
- �ڳ�ʼ״̬�£���Ϣ��Ϊ0.88��
- ���÷�����ֵΪ70���з��ѣ���Ϣ��Ϊ0.4344
- ���ó�������ֵΪ75%���з��ѣ���Ϣ��Ϊ0.79
ֻҪ���ӷ��ѽڵ����ر�֮ǰ����С����ô�Ϳ�����Ϊ���η�������Ч�ģ�����(2)��(3)�ķ��Ѷ���Ч�������ĸ������أ�
�����÷�����ֵΪ70���ر����ó�������ֵΪ75%����ҪС����ǰ�߷��Ѻ����ݱȽϴ�һЩ���������ݵ�ȷ���Դ��ˣ�������÷�����ֵΪ70���ѷ�ʽЧ�����ã����������Ը÷�ʽΪ�����з��ѡ�
������������Ϣ���棬��Ϣ���� = ����ǰ����Ϣ��-���Ѻ����Ϣ��������������ʾ��
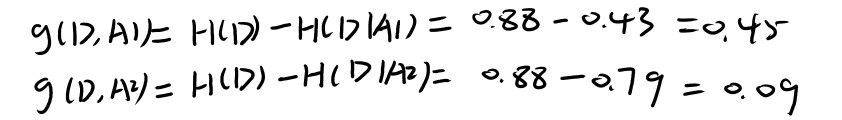
A1���Է�������������з��ѣ�A2���Գ���������������з���
���Կ����������÷�����ֵΪ70���з��ѣ���Ϣ�������
��Ϣ�����ھ������㷨��������ѡ��������ָ�꣬��Ϣ����Խ�������������ѡ����Խ�ã����������и�ǿ�ķ������������һ����������Ϣ����Ϊ0�����ʾ������û��ʲô����������
ID3��ԭ����
�������ݱ�ע����Ϣ�����Լ��������������һ���������е���������ֵ��ѡ��(�õ������Ϣ�������������ֵ)������������(��ע����Ϣ���桢����)�Ϳ������һ���������ߵ������������������㷨����ID3()�㷨��˼��
ID3(Iterative Dichotomisor 3) ��������������������Ϣ������ѡ���������ж������������ܣ��Ӷ�����������
������������ӣ����Եõ����½��ۣ�
- ֻҪ����������Ϊ0����ô�������ѵ�����ˣ�Ҳ���Ƿ������ˣ�
- ���ھ������е����ã��жϷ������û�дﵽ���ǵ������Ŀ�ģ�Ҳ���������Dz��Ǹ��Ӵ��ˣ�����ȷ���ˡ���������������Ϣ���ص�ֵ����С�ˣ���ô��η��������Ч�ġ�
- ��Խ��ȷ����Խ����δ���ʱ���ز�Ϊ0
- ��ԽС���ֵ�Խ�ã��������ʱ����Ϊ0
��������˼�룬�����������һ������

(����+����ϵ��)&CART
������������У��������þ�����������ģ���ô���ع��ʱ�����ô���أ� ���ڰ������ķ������ɺ�ѧ�������Ƿ�Ϊ��ѧ���ĸ��ʣ�������ʾ��

����Ľ���Ǹ��ʣ��Ǹ������ı�������������Ϣ�غ���Ϣ�����ˣ����ʱ����ô���أ�
Ϊ�˽��������⣬�����˴��ȵĸ��
���ȵĶ������£�

?_? ��?_r �ǰ���ijһ�������Ѻ������������ѽ�����ռ�ı�����Var�Ƿ�����Ǽ��������Ҳಿ�ֵķ��y_i�Ǿ����ֵ(�����Ǻ�ѧ���ĸ���)
�������� = ����ǰ�Ĵ��� - ���Ѻ�Ĵ���
���Կ��������Ⱥͷ���Ķ������һ��(����Ĵ���û�г���n������Ķ�����Ҫ����n)�����е�������Ҳ��Ϊƫ���ʵ���嶼һ����������ʾ���ݵ���ɢ�̶�
ϸ��һ�£��������10��ѧ�����Ǻ�ѧ���ĸ��ʶ�һ��(���綼��0.9)����ô����(����)��0��˵��������ȫû����ɢ�ԣ��dz���ȷ����
���Կ��������Ⱥ���Ϣ���������ĺ�����һ���ģ�ֻ�����ر�ʾ������Ϣ�IJ�ȷ���ԣ����ȱ�ʾ���ݵ���ɢ�̶ȣ����漴��Ҫ���ܵĻ���ϵ������ʾ��Ҳ�Ƿ���(CART�ķ���)��Ϣ��ȷ����
��1���ڳ�ʼ״̬�£��������Ĵ���(��ʱֻ��һ�����ڵ�) ����=0.4076��������ʾ��
import numpy as np
a = [0.9,0.9,0.8,0.5,0.3,0.8,0.85,0.74,0.92,0.99]
a = np.array(a)
a_mean = np.mean(a)
# ����n
a_va = np.sum(np.square(a-a_mean))
a_va
# ��� 0.4076000000000001
(2) ���÷�����ֵΪ70���з��ѣ���������=0.2703��������ʾ��

(3) ���ó�������ֵΪ75%���з��࣬���㴿�ȣ�

������ļ����У����ǵõ���3�����ȣ�
- �ڳ�ʼ״̬�£�����Ϊ0.4076��
- ���÷�����ֵΪ70���з��ѣ�����Ϊ0.2703
- ���ó�������ֵΪ75%���з��ѣ�����0.1048
�����������ȿ��Ե�֪�������ַ�ʽ�ķ��Ѿ���Ч�����ճ�������ֵ=75%����Ĵ��ȸ�С��˵�����ѵ�Ч�����ã���Ϣ��ȷ���ˡ�
Ҳ���Լ�������ȵ����棺
- ���÷�����ֵΪ70���з��ѣ����ȵ�����Ϊ
0.4079 - 0.2703 = 0.1376 - ���ó�������ֵΪ75%���з��ѣ����ȵ�����Ϊ
0.4079 - 0.1048 =0.3031
���ó�������ֵΪ75%���з��ѵõ������������˵����Ч������(�������Ϣ�ؼ���Ϣ�����ԭ����һ����)
˼����Ϊʲô����������ͻع�Ľ����ͬ��
��Ϊ���ǵı�ע��ͬ��֮ǰ��ע���Ǻ�ѧ���뻵ѧ�����������±�ע���Ǻ�ѧ���ĸ��ʣ���ע��ͬ������ģ��ѵ���������Ͳ�ͬ����ɵĽ���Ͳ�ͬ��
˼������ģ��ѵ����֮����ôȥ�õ�����ع���Ǹ�ֵ�أ�
������ֻ��һ����㣬����ָ�������ֵ���������ж����㣬��Ӧ����ƽ��ֵ
�������ݱ�ע�ʹ����Լ��������������һ���������е���������ֵ��ѡ��(�õ������Ϣ�������������ֵ)������������(��ע�����ȡ�����)�Ϳ������һ���������ߵ������ع����������㷨����CART�Ļع��㷨
CART���ع�ʱ�õ��Ǵ��ȣ�������ʱ�õ��ǻ���ϵ����
����ϵ��
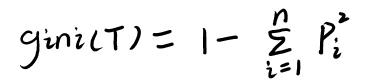
n����n���࣬pip_ipi?��ʾ��ͬ���ĸ���
����ijһ�������Ѻ�Ļ���ϵ��Ϊ��
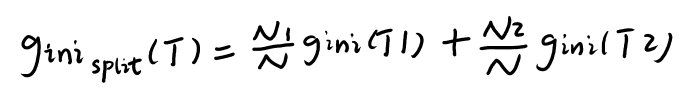
�������� = ����ǰ�Ļ��� - ���Ѻ�Ļ���
������Ӳ���������ӽ��ͻ���ϵ��������10��Ӳ���������࣬10�������棬û�з��棬��ô����ϵ��Ϊ��
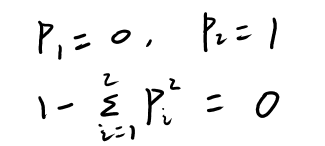
���10��Ӳ���������࣬5�������棬5���Ƿ��棬��ô����ϵ��Ϊ
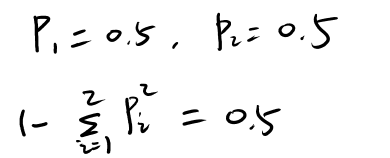
���Կ��������������ʱ������ϵ��Ϊ0����˻���ϵ������Ϣ�ĺ������ƣ�����ϵ��Խ����Ϣ�IJ�ȷ���Ծ�Խ��
ע�⣺����ϵ������Ϣ�ض������ڷ����
Ȼ����ijһ�������з��ѣ����簴��Ӳ�ҵĴ�С(����ֵ)���з��ѣ�������Ѻ�Ļ���ϵ����������������棬�õ��Ļ�������������������ֵ��������Ҫ�ҵķ��ѷ�ʽ��
�������桢�������桢��Ϣ�����ԭ����ȫһ��
CART��classification and regression tree������ͻع�����������ʹ�û���ϵ���ж������������ܣ��ع�ʱʹ�ô����ж�������������
��Ϣ������&C4.5
��Ϣ������Կ�ȡֵ��Ŀ�϶����������ƫ����Ϊ�˼�������ƫ�ÿ��ܴ����IJ���Ӱ�죬C4.5�������㷨ʹ���ˡ������ʡ���
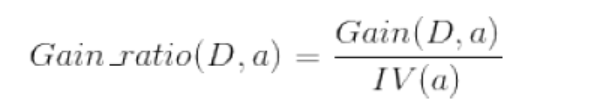
����IV(a)��Ϊ����a�ġ�����ֵ������Ϊ����a�ķ�����Ϣ��������ʵ��������a����Ϣ��(ע�⣺�������Ϣ�����ȥ�İ�����a���Ѻ����Ϣ�ز�һ������������������пɿ���)
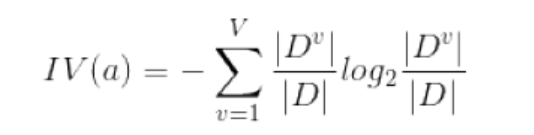
��Ҫע����ǣ���Ϣ�����ʶԿ�ȡֵ��Ŀ���ٵ���������ƫ�ã���ˣ�C4.5�㷨������ֱ��ѡ����Ϣ�����������������з��ѣ�����ʹ����һ������ʽ�����ҳ���Ϣ�������ƽ��ˮƽ���������ٴ���ѡ����������ߵġ� ���Կ�����ʹ����Ϣ�����ʿ��Խ�����Ѻ�Ҷ�ӽ���������⣬�Ӷ���������
��������������Ӽ�����Ϣ������(��Ǹ��û�ҵ���������ͼƬ)

��1����һ��������������D����Ϣ��
Ent(D) = -9/14*log2(9/14) �C 5/14*log2(5/14) = 0.940
Ent(D)��ʾ�أ�Ҳ����H(D)��ʾ
��2���ڶ���������ÿ����������������D��������ÿ������������������D����Ϣ��
- Ent(����) =
5/14*[-2/5*log2(2/5)-3/5*log2(3/5)] + 4/14*[-4/4*log2(4/4)] + 5/14*[-3/5log2(3/5) �C 2/5*log2(2/5)] = 0.694 - Ent(�¶�) = 0.911
- Ent(ʪ��) = 0.789
- Ent(����) = 0.892
��3����������������Ϣ����
- Gain(����) = Ent(D) - Ent(����) = 0.246
- Gain(�¶�) = Ent(D) - Ent(�¶�) = 0.029
- Gain(ʪ��) = Ent(D) - Ent(ʪ��) = 0.150
- Gain(����) = Ent(D) - Ent(����) = 0.048
��4�����IJ�����������(����)������Ϣ����
- IV(����) =
-5/14*log2(5/14) �C 4/14*log2(4/14) �C 5/14*log2(5/14) = 1.577 - IV(�¶�) = 1.556
- IV(ʪ��) = 1.000
- IV(����) = 0.985
��5�����岽��������Ϣ������
- Gain_ratio(����) = 0.246 / 1.577 = 0.155
- Gain_ratio(�¶�) = 0.0187
- Gain_ratio(ʪ��) = 0.151
- Gain_ratio(����) = 0.048
���Կ�������������Ϣ��������ߣ�ѡ������Ϊ�������ԡ����ַ�����֮�������ǡ������������£�����ǡ������ģ�����������ΪҶ�ӽڵ㣬ѡ�������Ľ��������ѡ�
������ID3��CART�е���������ֵ����ɢ�ģ�������ֵ��һ������ֵ�����DZ����е�������������������������û����ֵ��ѡ��ֱ�Ӱ��������������з��ѣ����籾���а������Ѿ��������ѳ��硢������������㡣
˼����Ϊʲô˵��Ϣ������Կ�ȡֵ��Ŀ�϶����������ƫ����
���籾���е��������������Ŀ�ȡֵ����Ϊ3�����硢�����꣬������������Ŀ�ȡֵ��Ŀ���ӵ�5������ô�����������Ѻ����Ϣ�ؾͻή�͵ĸ��࣬������Ϣ�����Խ����Ϊ���������Ŀ�ȡֵ��ĿԽ�࣬���ѵľ���������������������Ŀ�ȡֵ��Ŀ���ӵ���������һ������ô���Ѻ����Ϣ�ؾ���0�ˣ�����˵��Ϣ������Կ�ȡֵ��Ŀ�϶����������ƫ�á�
˼����Ϊʲô˵��Ϣ�����ʶԿ�ȡֵ��Ŀ���ٵ���������ƫ����
���ñ����е�����������˵�����Ŀ�ȡֵ����Ϊ3�����硢�����꣬������������Ŀ�ȡֵ��Ŀ���ٵ�һ������ô��������(����)������Ϣ������Ϊ0�ˣ���ʱ����Ϣ�����ʾ�������������Ϣ�����ʶԿ�ȡֵ��Ŀ���ٵ���������ƫ�á�
���־������Ƚ����ܽ�
ID3��CART��C4.5�Ƚ�
��Ϣ�������Ϣ������ͨ��������ɢ�͵��������֣�ID3��C4.5ͨ������¶��Ƕ������Ҳ���Ǹ�����ɢ������ȡֵ�Ὣ���ݷֵ���������У���Ȼ������Ϣ�������Ϣ�����ʵ�ʱ��Ҳ���Զ������������л��ֲ��������ŵ㣬�������жϺû�ѧ�������ӡ�CART��Ϊ��������ʹ�û���ָ����Ϊ����������ɢ���������������������ܺܺõĴ�����
��ɢ�͵�������ָ�������Ƿ��࣬���������硢�����꣬����������ֵ
�����͵�������ָ��������һ����ֵ������������ߵȣ����Ƿ���
�������IJ�����ѵ��������
- �������IJ�����ѡ������������Ӧ����ֵ�������������˽ṹ
- ѵ�����������DZ����ķ������ô��ȡ�����ϵ������Ϣ�ء���Ϣ�������Ϣ����������ʾ
- �������ȿ��������࣬Ҳ�������ع飬�ȿ����������࣬Ҳ�����������
�������еķ�������

�������������
����������ʵ���Ͼ�����������(���ÿ����������ֵ)���������£�
- �趨һ�����۷������ĺû�����(��Ϣ���桢����ϵ�������ȡ���Ϣ������)
- �ñ����ķ������
���������ʵս
����sklearn��ʵ�ֻع������
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from sklearn import linear_model# Data set
x = np.array(list(range(1, 11))).reshape(-1, 1)
y = np.array([5.56, 5.70, 5.91, 6.40, 6.80, 7.05, 8.90, 8.70, 9.00, 9.05]).ravel()# Fit regression model
model1 = DecisionTreeRegressor(max_depth=1)
model2 = DecisionTreeRegressor(max_depth=3)
model3 = linear_model.LinearRegression()
model1.fit(x, y)
model2.fit(x, y)
model3.fit(x, y)# Predict
X_test = np.arange(0.0, 10.0, 0.01)[:, np.newaxis]
y_1 = model1.predict(X_test)
y_2 = model2.predict(X_test)
y_3 = model3.predict(X_test)# Plot the results
plt.figure()
plt.scatter(x, y, s=20, edgecolor="black",c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=1", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=3", linewidth=2)
plt.plot(X_test, y_3, color='red', label='liner regression', linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()
���

�ֶ�ʵ��ID3������
#coding:utf-8
import torch
import pdb# ������������ÿ�����������߸�����
feature_space=[[1., 3., 2., 2., 3., 0.,3.],
[2., 0., 2., 5., 1., 2.,3.],
[3., 2., 3., 3., 2., 3.,2.],
[4., 0., 3., 3., 2., 0.,1.],
[3., 1., 2., 2., 5., 1.,3.],
[1., 4., 3., 3., 1., 5.,2.],
[3., 3., 3., 3., 1., 0.,1.],
[5., 1., 1., 4., 2., 2.,2.],
[6., 2., 3., 3., 2., 3.,0.],
[2., 2., 2., 2., 5., 1.,4.]]def get_label(idx):label= idxreturn label# ������ij������ij����ֵ���з���ʱ����Ϣ�أ���������
def cut_by_node(d,value,feature_space,list_need_cut):# �ֱ�����ij������ij����ֵ���Ѻ�����Ҳ�������right_list=[]left_list=[]for i in list_need_cut:if feature_space[i][d]<=value:right_list.append(i)else:left_list.append(i)left_list_t = list2label(left_list,[0,0,0,0,0,0,0,0,0,0])right_list_t = list2label(right_list,[0,0,0,0,0,0,0,0,0,0])e1=get_emtropy(left_list_t) e2=get_emtropy(right_list_t) n1 = float(len(left_list))n2 = float(len(right_list))e = e1*n1/(n2+n1) + e2*n2/(n1+n2)return e,right_list,left_list# ���ֵ�������תΪone-hot��ʽ�����������Ϣ��
def list2label(list_need_label,list_label):for i in list_need_label:label=get_label(i)list_label[label]+=1return list_labeldef get_emtropy(class_list):E = 0sumv = float(sum(class_list))if sumv == 0:sumv =0.000000000001for cl in class_list:if cl==0:cl=0.00000000001p = torch.tensor(float(cl/sumv))# log��2��E += -1.0 * p*torch.log(p)/torch.log(torch.tensor(2.))return E.item()
def get_node(complate,d,list_need_cut):# ��ʼʱ����Ϣ�أ���Ϊ���(���ڵ����֮ǰ����Ϣ��)e = 10000000# node �������Ǹ�ά�ȵ��Ǹ�����ֵ���з���node=[]# list_select:�����Ѻõ�һ����������У��������Ѿ�����ÿ���ʶ��Ľ��list_select=[]# ��ſ���ʶ��Ľ��complate_select=[]# 0~8����ѡ�����ֵfor value in range(0,8):complate_tmp=[]etmp=0list_select_tmp=[]# �������ܵij���sumv=0.000000001# Ҫ���з��ѵ����н������for lnc in list_need_cut:# ���������أ������ء������������㣬�Ҳ����������etmptmp,r_list,l_list=cut_by_node(d,value,feature_space,lnc)# ���д����etmp/sumv ��������Ѻ�����أ������Ǹ�pl*H1+pr*H2�Ĺ�ʽetmp+=etmptmp*len(lnc)sumv+=float(len(lnc))# ��ſ���ʶ��Ľ��if len(r_list)>1:list_select_tmp.append(r_list)if len(l_list)>1:list_select_tmp.append(l_list)if len(r_list)==1:complate_tmp.append(r_list)if len(l_list)==1:complate_tmp.append(l_list)# print('������child:��ÿ�������ĵ�{}������������ֵ��СΪ{}����{}�����У��õ�����Ϊ{}'.format(d,value,lnc,etmptmp)) etmp = etmp/sumvsumv=0# print('������All����ÿ�������ĵ�{}������������ֵ��СΪ{}����{}���У��õ�������Ϊ{}'.format(d,value,list_need_cut,etmp)) # �õ���n��������ijһ��ֵ���Ѻ����С��Ϣ�أ�����ʱ���Ѻ�����if etmp<e:e=etmpnode=[d,value]list_select=list_select_tmpcomplate_select=complate_tmpfor ll in complate_select:complate.append(ll)return node,list_select,complate
import pdb
def get_tree():
# pdb.set_trace()# 10��������0, 1, 2, 3, 4, 5, 6, 7, 8, 9��ע���������Ƕ�ά����## ��ά������տ�ʼֻ��һ�����У�����ʼʱֻ��һ�����ڵ�all_list=[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]] # complate�ĺ����ǣ���������ij�����ֻ��һ����������ô��ŵ�complate��## ��complate��ŵ����Ѿ�����õĿ���ʶ��Ľ��complate=[]# ����������7��������������о��DZ������Ⱥ�˳��## d ���ȱ���ÿ�������ĵ�3���������ѷ���Ľ������for d in [3,4,2,5,0,1,6]:# node �������Ǹ�ά�ȵ��Ǹ�����ֵ���з���# all_list:�����Ѻõ�һ����������У��������Ѿ�����ÿ���ʶ��Ľ��node,all_list,complate=get_node(complate,d,all_list)print("node=%s,complate=%s,all_list=%s"%(node,complate,all_list))if __name__=="__main__":get_tree()
�����

ʹ��sklearn��ع������Ԥ��boston����
decision_sklearn_tree_regressor_boston
ʹ��sklearn������������iris����
decision_sklearn_tree_classify_iris
�ο��ĵ�
��Ϣ���桢��Ϣ����ȡ�����ָ���ıȽ�
��Уר�ľ�����
����ѧϰ������-��Ϣ�أ������أ���Ϣ���棬��Ϣ����ȣ�����ϵ��