文章目录
-
- ReLU
- Leaky ReLU
- PReLU
- ELU
- Softplus
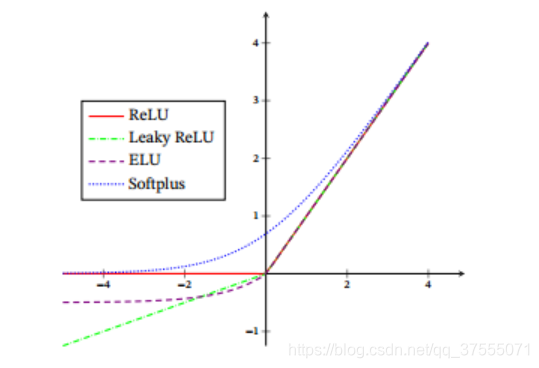
ReLU
ReLU(Rectified Linear Unit,修正线性单元),也叫Rectifier 函数,它的定义如下:
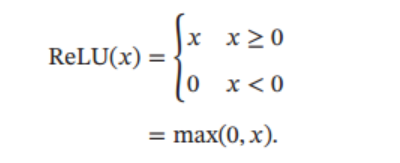
Relu可以实现单侧抑制(即把一部分神经元置0),能够稀疏模型, Sigmoid 型活tanh激活函数会导致一个非稀疏的神经网络,而Relu大约 50% 的神经元会处于激活状态,具有很好的稀疏性。

Relu函数右侧线性部分梯度始终为1,具有 宽兴奋边界的特性 (即兴奋程度可以非常高),不会发生神经网络的梯度消失问题, 能够加速梯度下降的收敛速度。而tanh和sigmoid在离0点近的时候梯度大,在远离0点的时候梯度小,容易出现梯度消失。
在生物神经网络中, 同时处于兴奋状态的神经元非常稀疏. 人脑中在同一时刻大概只有 1% ? 4% 的神经元处于活跃状态
Relu的缺点:ReLU 函数不是在0周围, 相当于给后一层的神经网络引入偏置偏移,会影响梯度下降的效率。另外,在训练时, 如果参数在一次不恰当的更新后, 某个 ReLU 神经元输出为0,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活, 这种现象称为死亡 ReLU 问题 (Dying ReLU Problem)
ReLU 神经元指采用 ReLU 作为激活函数的神经元。
Leaky ReLU
Leaky ReLU(带泄露的 ReLU )在输入 x<0x < 0x<0 时, 保持一个很小的梯度 γ\gammaγ. 这样当神经元输出值为负数也能有一个非零的梯度可以更新参数, 避免永远不能被激活,Leaky ReLU定义如下:
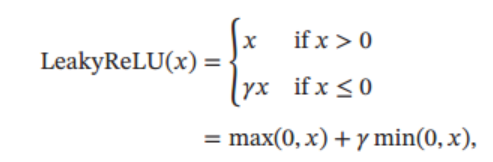
其中 γ\gammaγ 是一个很小的常数, 比如 0.01. 当 γ\gammaγ < 1 时, Leaky ReLU 也可以写为
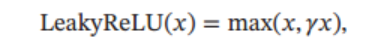
max(0.1x,x)max(0.1x,x)max(0.1x,x)的图像如下所示:

PReLU
PReLU(Parametric ReLU, PReLU,即带参数的 ReLU)引入一个可学习的参数, 不同神经元可以有不同的参数。 对于第 ? 个神经元,ReLU 的定义为:
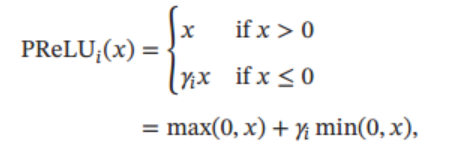
γi\gamma_iγi?是x≤0x \le 0x≤0时的梯度, 如果γi\gamma_iγi? = 0, 那么PReLU 就退化为 ReLU. 如果 γi\gamma_iγi? 为一个很小的常数, 则 PReLU 可以看作Leaky ReLU。 PReLU 可以允许不同神经元具有不同的参数, 也可以一组神经元共享一个参数。
ELU
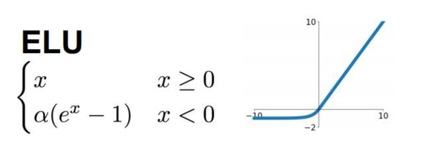
ELU(Exponential Linear Unit, 指数线性单元)定义为:
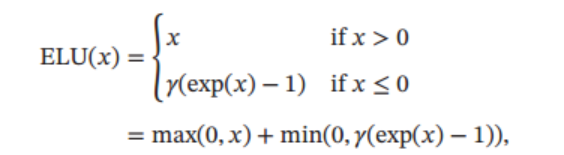
其中 γ\gammaγ ≥ 0 是一个超参数,图像如下所示:
Softplus
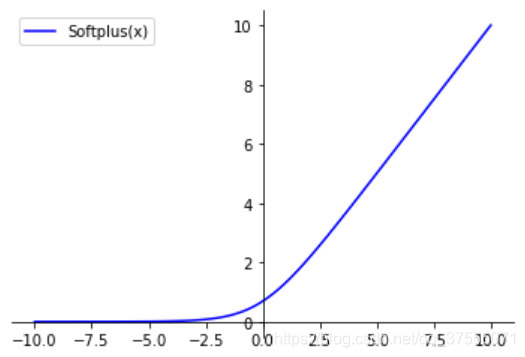
Softplus 函数 可以看作 Relu 函数的平滑版本,其定义为
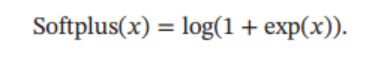
Softplus 函数其导数刚好是 Logistic 函数。 Softplus 函数虽然也具有单侧抑制、 宽兴奋边界的特性, 却没有稀疏激活性,不会稀疏模型。 图像如下:
这几个函数的图像如下: