大家好,我是雷恩Layne,这是《深入浅出flink》系列的第七篇文章,我旨在用最直白的语言写好flink,希望能让所有看到的人一目了然。如果大家喜欢,欢迎点赞、关注,也欢迎留言,共同交流flink的点点滴滴 O(∩_∩)O
文章目录
-
- 1. keyBy
- 2. broadcast
- 3. rebalance
- 4. rescale
- 5. shuffle
- 6. global
- 7. partitionCustom
flink任务在执行过程中,一个流(stream)包含一个或多个分区(Stream partition)。TaskManager中的一个slot的subtask就是一个stream partition(流分区),一个Job的流(stream)分布在多个不同的Slot上执行。每一个算子可以包含一个或多个子任务(subtask),这些subtask执行在不同的分区中,本质是在不同的线程、不同的物理机或不同的容器中彼此互不依赖地执行。
flink中的重分区算子定义上下游subtask之间数据传递的方式。SubTask之间进行数据传递模式有两种,一种是one-to-one(forwarding)模式,另一种是redistributing的模式。
- One-to-one:数据不需要重新分布,上游SubTask生产的数据与下游SubTask受到的数据完全一致,数据不需要重分区,也就是数据不需要经过IO,比如上图中source->map的数据传递形式就是One-to-One方式。常见的map、fliter、flatMap等算子的SubTask的数据传递都是one-to-one的对应关系。类似于spark中的窄依赖。
- Redistributing:数据需要通过shuffle过程重新分区,需要经过IO,比如上图中的map->keyBy。创建的keyBy、broadcast、rebalance、shuffle等算子的SubTask的数据传递都是Redistributing方式,但它们具体数据传递方式是不同的。类似于spark中的宽依赖。
flink中的重分区算子除了keyBy以外,还有broadcast、rebalance、shuffle、rescale、global、partitionCustom等多种算子,它们的分区方式各不相同。需要注意的是,这些算子中除了keyBy能将DataStream转化为KeyedStream外,其它重分区算子均不会改变Stream的类型。
现在就让我们来一探究竟。
1. keyBy
keyBy :DataStream -> KeyedStream,按照key的hashcode将一个流划分为不相交的分区。具有相同 Keys 的所有记录在同一分区。
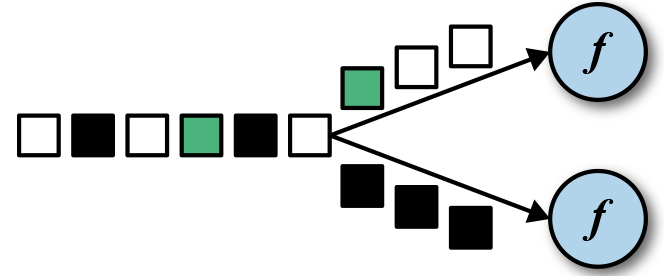
KeyBy主要有三种分区方法:
//1. 根据Tuple第fields个元素的hashcode分区
keyBy(int... fields)//2.根据Bean的fields的hashcode分区
keyBy(String... fields)//3.自定义keySelector提取key来分区,T是传入的数据类型,K是提取key的数据类型
keyBy(KeySelector<T, K> key)
具体示例在之前的文章详细梳理flink中常见的dataSteam算子已介绍过。
2. broadcast
broadcast :DataStream -> DataStream,给下游算子所有的subtask都广播一份数据。
举例:设置并行度为3,打印broadcast下游subtask的数据
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);DataStream<String> dataStream = env.fromElements("hello", "world", "flink");
DataStream<String> broadcast = dataStream.broadcast();broadcast.print();
env.execute();
执行输出:
3> hello
3> world
3> flink
2> hello
2> world
2> flink
1> hello
1> world
1> flink
并行度为3,每一个算子都有三个subtask,所以经过broadcast后,下游每一个subtask就会接收到所有上游任务发送过来的数据。
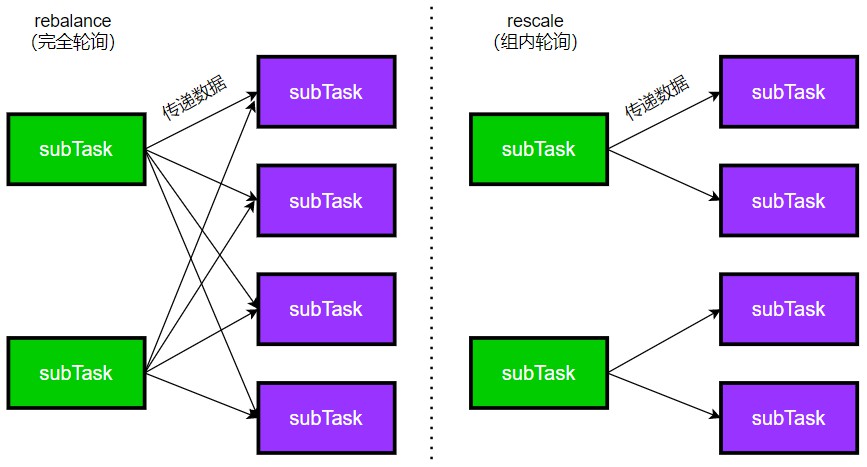
3. rebalance
rebalance :DataStream -> DataStream,随机轮询发送数据。
举例来说,假如A算子作为上游算子,有3个SubTask,并行度为3;下游B算子,有2个SubTask,并行度为2,数据传递方式是rebalance。数据具体传递形式:首先生成一个随机数,决定第一个数据发往下游的哪个subtask,假如生成随机是i,下游的任务数是n,则A的SubTask1中第一个数据发送到B的第(i+1)%n的subtask,执行i=(i+1)%n, A的SubTask1第二个数据发送到B的第(i+1)%n的subtask,i=(i+1)%n,从而轮询发送数据。同理,A的SubTask2也是如此。
当上下游算子并行度不一样时,默认的数据传递方式是rebalance,当下游算子并行度一样时,默认的数据传递方式是forward。
forward也是flink中的算子,因为它只是让数据在当前的分区进行上下游传递,并没有进行shuffle,所以不属于shuffle类的算子。
看一段简单的代码:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStream<String> dataStream = env.fromElements("hello", "world", "flink");
dataStream.print();
env.execute();
在该代码中,我们设置了程序并行度为3,但实际执行过程中是fromElements算子并行度为1,print并行度3。那为什么fromElements的并行度不是3呢?这是因为这个source没有实现ParallelSourceFunction 接口or 继承RichParallelSourceFunction,具体可参考我的博客:flink常见的单并行度和多并行度Source。
将上述代码打包上传到flink集群,可以查看执行计划如下:

可以看到,上下游subtask的数据传递方式为rebalance,这就我们就能推测数据的执行结果,即Sink的每个subtask都会接收到一个数据:
1> hello
2> world
3> flink
将上述代码修改如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);DataStream<String> dataStream = env.fromElements("hello", "world", "flink");
DataStream<String> rebalance = dataStream.rebalance();rebalance.print();
env.execute();
此时,相当于人为将fromElements和print之间数据传递方式定义为rebalance,也就是说,无论它们的并行度是否相同,数据传递方式都为rebalance。
4. rescale
rescale :DataStream -> DataStream,重新分组,在组内进行rebalance(轮询),数据传输的范围小一点。
如下图所示,假如上游有2个分区(即两个subtask),下游4个分区,rebalance是让每一个上游subtask对下游轮询发送数据,而rescale是将上下游分区的任务平均划分为2组,在每个分组内rebalance发送数据。
5. shuffle
shuffle :DataStream -> DataStream,完全随机发送数据,也就是说,上游任务发送给下游任务的数据是随机发送的。
shuffle的底层是ShufflePartitioner,实现方式如下:
public class ShufflePartitioner<T> extends StreamPartitioner<T> {
private static final long serialVersionUID = 1L;private Random random = new Random();@Overridepublic int selectChannel(SerializationDelegate<StreamRecord<T>> record) {
return random.nextInt(numberOfChannels);}@Overridepublic StreamPartitioner<T> copy() {
return new ShufflePartitioner<T>();}@Overridepublic String toString() {
return "SHUFFLE";}
}
selectChannel决定了将数据发往下游哪一个分区中,可以看到,代码中是通过random.nextInt生成的,也就是随机发送数据。
6. global
global :DataStream -> DataStream,数据传递给下游第一个分区(或下游第一个slot或下游算子的第一个并行子任务),一般将所有数据汇总在一起时使用。
示例:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);DataStream<String> dataStream = env.fromElements("hello", "world", "flink");
DataStream<String> global = dataStream.global();global.print();
env.execute();
执行输出:
1> hello
1> world
1> flink
可以看到,虽然global的并行度为3,但是只有第一个子任务输出了数据。
7. partitionCustom
partitionCustom :DataStream -> DataStream,用户自定义重分区方式。
示例:自定义分区,按照传入数据的hashcode分区
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
DataStream<Tuple2<String, Long>> dataStream = env.fromElements(new Tuple2<>("hello", 1L),new Tuple2<>("world", 3L),new Tuple2<>("flink", 5L),new Tuple2<>("world", 99L));DataStream<Tuple2<String, Long>> tuple2DataStream = dataStream.partitionCustom(new Partitioner<String>() {
@Overridepublic int partition(String key, int numPartitions) {
//key是分区的字段,numPartitions下游分区数return key.hashCode() % numPartitions;}
}, 0);//0将Tuple2的第一个字段作为分区字段tuple2DataStream.print();
env.execute();
执行输出:
1> (world,3)
1> (world,99)
2> (hello,1)
2> (flink,5)