文章目录
- 1:cuda-c
- 2:一个简单的配置流程
- 3:.cu、.cpp的关系
- 4:混合编译.cu、.cpp
- 5:动态链接库(windows、linux)
- 6:NVCC学习笔记
- 7:g++的一些常用命令
1:cuda-c
Cuda-c 极大程度的方便了我们利用GPU并行处理来加快自己程序的运行速度,但是大多情况下我们的程序是一个极为庞大的工程项目,在这个项目中我们只需要利用cuda来加快其中某一块算法的运行效率,所以很多情况下利用cpp文件来调用cu中的kernel函数,从而完成程序的并行运算。虽然cuda5.0之后可以直接从vs中生成现有的cuda项目,但是利用cpp来调用cu文件的项目还是需要我们自己来进行配置的。
2:一个简单的配置流程
从一个例子先简单看一下其实现和调用过程:
1. 首先假定我们已经写好了调用gpu运算的.cu文件,如下图所示。在这个文件中,我们首先定义调用global设备函数的主函数
testghmain();
并在其前面加上extern “C” ,这个文件定义了a、b两个数组, 并利用gpu来实现c=a+b的运算。

2. 在我们的工程中,需要调用上面这个.cu文件中的函数进行并行加速的cpp文件中,对testghmain();函数进行调用,所以在文件前面需要对其进行事先声明。
extern “C” int testghmain();

3. 之后,在上面这个.cpp文件中,需要的地方直接调用testghmain()。

在这里我们声明了一个MFC的控件响应函数OnBnClickedbutton来调用testghmain(),当用户点击这个button时,程序首先调用.cu文件中的testghmain函数,而testghmain函数会调用global设备函数,通过gpu实现c=a+b的运算,并把计算结果最终返回给用户。
3:.cu、.cpp的关系
从上面的例子中就可以看出,.cu其实就是一个函数,但是需要用cuda的命令进行编译,然后用.cpp文件进行调用里面的函数。
即:
项目中用到cuda编程,写了kernel函数,需要nvcc编译器来编译。.c/.cpp的文件,假定用gcc编译。
如何混合编译它们,整体思路是:.cu文件编译出的东西,作为最终编译出的可执行程序的链接依赖。
4:混合编译.cu、.cpp


以inux系统为例子:
1)分别编译各个文件,最后链接
nvcc -c test1.cu
gcc -c test2.c
gcc -o testc test1.o test2.o -lcudart -L/usr/local/cuda/lib64
2)将cuda编译成静态库,gcc编译cpp(不太懂)
nvcc -lib test1.cu -o libtestcu.a
gcc test2.c -ltestcu -L. -lcudart -L/usr/local/cuda/lib64
3)将cuda编译成动态库,gcc编译cpp(不太懂)
all: cc: libtestcu.sogcc test2.c -ltestcu -L. -lcudart -L/usr/local/cuda/lib64 -o testclibtestcu.so: test.cunvcc -o libtestcu.so -shared -Xcompiler -fPIC test1.cu
补充:
4)将cpp编译成动态库.so
g++ -std=c++11 -shared ./3d_interpolation/tf_interpolate.cpp -o ./3d_interpolation/tf_interpolate_so.so
PointNet++例子:
1.将.cu文件进行编译成.o
$CUDA_ROOT/bin/nvcc ./grouping/tf_grouping_g.cu -o ./grouping/tf_grouping_g.cu.o -c -O2 -DGOOGLE_CUDA=1 -x cu -Xcompiler -fPIC
2.将cpp文件编译成动态库.so
g++ -std=c++11 -shared ./3d_interpolation/tf_interpolate.cpp -o ./3d_interpolation/tf_interpolate_so.so -I $CUDA_ROOT/include -lcudart -L $CUDA_ROOT/lib64/ -fPIC ${TF_CFLAGS} ${TF_LFLAGS} -O2
3.将.cpp文件和.o文件编译成动态库.so
g++ -std=c++11 -shared ./grouping/tf_grouping.cpp ./grouping/tf_grouping_g.cu.o -o ./grouping/tf_grouping_so.so -I $CUDA_ROOT/include -L $CUDA_ROOT/lib64/ -fPIC ${TF_CFLAGS} ${TF_LFLAGS} -O2
4.python文件调用动态链接库.so
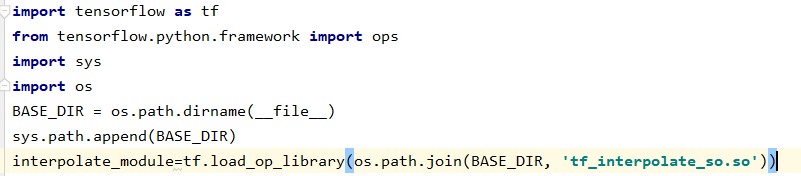
5:动态链接库(windows、linux)
在Linux上,动态库的加载机制和在Windows上完全不一样(其实应该叫做【共享库】才对,动态库是Windows的概念,Windows上为*.dll,Linux上为*.so。dll:dynamic link library,即:动态链接库。so:share object(library),即:共享库。)
1、在Windows上
一个可执行程序会先在当前目录下找需要的动态库(*.dll)文件,如果当前目录下有,则加载。如果当前目录没有,才会去系统的环境变量目录下去找,如果找到了,则加载,如果连环境变量中都找不到,将报错。
2、在Linux上
一个可执行程序会直接去 “环境变量目录下” 找共享库(*.so),如果找不到,则报错。
“环境变量目录下” 打了引号,因为这更像是一个专门用于【共享库】的环境变量,Linux的环境变量应该是PATH(可在终端输入这个查看:echo>$PATH),PATH跟Windows上的环境变量又不一样,PATH描述的是Linux命令的一个路径,而Windows上的环境变量描述的是命令+ 库。Linux的库的加载,由 /etc/ld.so.conf 和 /etc/ld.so.conf.d/*.conf 来进行加载的,不妨一个一个打开看看就一切都明白了。
、
6:NVCC学习笔记
见链接:https://wangpengcheng.github.io/2019/04/17/nvcc_learn_note/
7:g++的一些常用命令
1)引入头文件
当我们只编译一个main.cpp文件时输入:
g++ -o a.out main.cpp
当我们需要编译一个头文件和一个源文件如:common.h和main.cpp文件时:
假设common.h与main.cpp在同一文件夹下:
g++ -o a.out main.cpp -I .
common.h在/home/user/include文件夹下:
g++ -o a.out main.cpp -I /home/user/include/
注:可以在我提供的实例代码中发现,我在引用common.h时使用的是<common.h>其意义是去系统路径下找该文件,所以需要将目录/home/user/include/添加到此次编译的系统路径。如果是“common.h”则先在系统路径下找,再在到当前目录下找。所以如果是“common.h”,则不需要添加 -I /home/user/include/ 只写g++ -o a.out main.cpp即可。
2)编译多个源文件
当我们需要编译一个头文件和两个源文件如:common.h,common.cpp和main.cpp文件时:
g++ -o a.out main.cpp common.cpp -I /home/user/include/
3)调试
想要调试,我们需要生成具有调试信息可执行文件。
当我们需要调试上面的程序时,需要先编译,在编译时要加一个编译器参数(-g)来添加调试信息,命令如下:
g++ -g -o a.out main.cpp common.cpp -I .
4)实例
common.h:
#ifndef COMMON_H
#define COMMON_H#include <iostream>
class A
{
public:void foo();
};#endif
common.cpp:
#include <common.h>void A::foo()
{
std::cout<<"foo..."<<std::endl;
}
main.cpp:
#include <common.h>
int main()
{
A a;a.foo();return 0;
}命令行输入:
g++ -g -o a.out main.cpp common.cpp -I .
https://blog.csdn.net/fb_help/article/details/79248876
参考链接:
https://blog.csdn.net/gh234505/article/details/51182490/
https://www.cnblogs.com/zjutzz/p/10272424.html