SparseKernelMachine
ǰ��
������Ҫ�ڽ�SVM�������˺ܶ�ʱ�䣬���д����ο��˸��ֹ����ⲩ�ͣ���ΪӢ��ˮƽ������IJο������ԣ�ͬʱ���������������⣬��������������ѧ��Ҫѧϰ���϶��������⣬ϣ��ָ����֮���о����ν���һ���ġ�
SVM
svm�������������ż�˼��ɡ�svm�൱��һ���б������Ǵ�����б�ģ�ͣ�Ѱ��һ����ƽ��ָ����ݵ㡣ͨ������������һ�ֶ������ģ�ͣ������ģ�Ͷ���Ϊ�����ռ��ϵļ���������Է���������֧����������ѧϰ���Ա��Ǽ��������տ�ת��Ϊһ�����ι滮�������⡣
hard-margin
���ǽ����������������Ģ٢ڢۢܢ������⡣
ǰ��֪ʶ��������������μ���Ľ���
�۲�����ͼ��
��ͼ��x0x_0x0? �� xxx �ڳ�ƽ���ϵ�ͶӰ����\omega�� �dz�ƽ����Tx+b=0\omega^Tx+b=0��Tx+b=0�ķ����������Եõ���
x?x0=�æءΦء�x-x_0=\gamma \frac{\omega}{\Vert \omega\Vert}x?x0?=����������?
Ҳ����˵��
��=��Tx+b�Φء�\gamma = \frac{\omega^Tx+b}{\Vert \omega \Vert}��=��������Tx+b?
ȡ���������ǵõ����μ��Ϊ��
��~=�Φ�Tx+b�ΡΦء�\tilde{\gamma} = \frac{\Vert \omega^Tx+b \Vert}{ \Vert \omega \Vert}��~?=����������Tx+b��?
���������
��^=��Tx+b��\hat{\gamma} = \Vert \omega^Tx+b \Vert��^?=����Tx+b��
��������Ϊ��������Ǽ��μ��û�г���||w||�ı�����μ���Ǻ��������һ���Ľ����
���ǿ���֪��ÿ���㵽ȷ���ij�ƽ��ļ��μ����ȷ���ģ���ÿ���㵽ȷ���ij�ƽ��ĺ������ȴ������������Ϊ��Tx+b=0\omega^Tx+b=0��Tx+b=0��10��Tx+10b=010\omega^Tx+10b=010��Tx+10b=0����ͬ�ij�ƽ�档���ǵ�һ���㵽��ƽ��ĺ������ȷ���ˣ���ô�������е�Ҳ��ȷ���ˡ�
ǰ��֪ʶ��QP���ι滮����
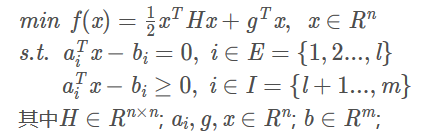
��HHHΪ�����������xxx,�������Ϊ�ϸ�����ι滮���⡣���ι滮������������Բ����ֹ���⣬���Ӷ���Ҫ������xxx������
ǰ��֪ʶ��ǿ����ż�Ľ����Լ�KKT����
-
KKT����
���Ƕ���һ���Ż�����
min?xf(x)s.t.gi(x)��0,i=1,?,khj(x)=0,j=1,?,l\min_{x}f(x)\\ s.t. g_i(x)\leq0,i=1, \cdots,k\\ h_j(x)=0,j=1, \cdots,l xmin?f(x)s.t.gi?(x)��0,i=1,?,khj?(x)=0,j=1,?,l
KKT�Ǹ����õģ�ԭ��KKT���Ż�����ȡ�ü�ֵ�ı�Ҫ���������һ���Ż���������һ��Լ�������ǿ���ʹ��KKT��⼫ֵ����������KKT����⼫ֵ��һ�ַ������Ż�����������ЩԼ������ʹ��KKT����ֵ�أ���ЩԼ���淶��wiki������ϸ�Ŀ�������������ֻ��Ҫ֪����SVM��һ�����ι滮���⣬���Կ϶�����KKT������ֵ��KKT�ľ�����ʽ���£�
{ԭʼ�������:gi(x)?0,i=1,2...khj(x)=0,j=1,2...l��ż�������:��i?0,i=1,2...k�����ɳ�:��igi(x)=0��������ƽ����:?xL(x,��,��)=0\begin{cases} ԭʼ�������: & g_i(x) \leqslant 0,i=1,2...k \;\\ &{h_{j}(x) = 0},j=1,2...l \\ ��ż�������: & \alpha_i \geqslant 0,i=1,2...k \\ �����ɳ�: & \alpha_i g_i(x) = 0 \\ ��������ƽ����: & \nabla_{x}\mathcal{L}(x, \boldsymbol{\alpha}, \boldsymbol{\beta}) = 0 \end{cases} ????????????????ԭʼ��������:��ż��������:��������:��������ƽ����:?gi?(x)?0,i=1,2...khj?(x)=0,j=1,2...l��i??0,i=1,2...k��i?gi?(x)=0?x?L(x,��,��)=0? -
�������KKT��������ֵ��
���ֻ�е�ʽԼ����������ͨ���������ճ���������ô���ڲ���ʽԼ�������ǵļ�ֵ���ܴ�����������֡������ŵ� ��x?��x^?��x? �������� (����ͼ��gi(x)<0g_i(x)<0gi?(x)<0 ) ����ʽԼ����û����Լ�������á�������ʽԼ���ȼ�����i=0\alpha_i = 0��i?=0�������ŵ�x?x^?x?������߽��� (����ͼ��gi(x)=0g_i(x)=0gi?(x)=0 ),����ʽԼ����ȼ���һ����i>0\alpha_i > 0��i?>0�ĵ�ʽ�������ۺ����ֿ�����
{��i?0,i=1,2...k��igi(x)=0,i=1,2...k\begin{cases} \alpha_i \geqslant 0,i=1,2...k \\ \alpha_i g_i(x) = 0,i=1,2...k \\ \end{cases} { ��i??0,i=1,2...k��i?gi?(x)=0,i=1,2...k?

-
ԭ������ԭ�������
���������Ż����⣬���dz�֮Ϊԭ���⡣ԭ�����Ŀ�꺯���ǹ���xxx�ġ�
min?xf(x)s.t.gi(x)��0,i=1,?,khj(x)=0,j=1,?,l\min_{x}f(x)\\ s.t. g_i(x)\leq0,i=1, \cdots,k\\ h_j(x)=0,j=1, \cdots,l xmin?f(x)s.t.gi?(x)��0,i=1,?,khj?(x)=0,j=1,?,l
�����������ճ����������ǵõ������������պ������ⲽ��Ϊ�˵õ�ԭ����ĵȼ���ʽ��
L(x,��,��)=f(x)+��i=1k��igi(x)+��j=1l��jhj(x)��i��0,i=1,?,k\mathcal{L}(x, \boldsymbol{\alpha},\boldsymbol{\beta}) = f(x)+\sum^k_{i=1}\alpha_ig_i(x)+\sum^l_{j=1}\beta_jh_j(x)\\ \alpha_i\geq0,i=1, \cdots,k L(x,��,��)=f(x)+i=1��k?��i?gi?(x)+j=1��l?��j?hj?(x)��i?��0,i=1,?,k
ԭ����ȼ���������ʽ���Ż����⣬���dz�֮Ϊԭ�����
min?xmax?��,��L(x,��,��)��i��0,i=1,?,k\min _{x} \max _{\boldsymbol{\alpha}, \boldsymbol{\beta}} \mathcal{L}(x, \boldsymbol{\alpha}, \boldsymbol{\beta}) \\ \alpha_i\geq0,i=1, \cdots,k xmin?��,��max?L(x,��,��)��i?��0,i=1,?,k -
��ԭ�����ԭ������Ƶ�
�ȼ۵�ԭ�����Ǵ�ԭ�����ĽǶȳ������Ƶ���ԭ���⡣ԭ�������Եȼ���������ʽ���������ҳ�֮Ϊ�м���ʽ��
min?x(f(x)+max?��,��(��i=1m��igi(x)+��j=1n��jhj(x)))��i��0,i=1,?,k\min _{x}\left(f(x)+\max _{\boldsymbol{\alpha}, \boldsymbol{\beta}}\left(\sum_{i=1}^{m} \alpha_{i} g_{i}(x)+\sum_{j=1}^{n} \beta_{j} h_{j}(x)\right)\right) \\ \alpha_i\geq0,i=1, \cdots,k xmin?(f(x)+��,��max?(i=1��m?��i?gi?(x)+j=1��n?��j?hj?(x)))��i?��0,i=1,?,k
���Ƕ��������������
xxx����Լ��:gi(x)��0,i=1,?,k����hj(x)=0,j=1,?,lg_i(x)\leq0,i=1, \cdots,k����h_j(x)=0,j=1, \cdots,lgi?(x)��0,i=1,?,k����hj?(x)=0,j=1,?,l
xxx������Լ��:����gi(x)>0,����hj(x)��0g_i(x)>0,����h_j(x)\neq0gi?(x)>0,����hj?(x)??=0
��ô����i��0,i=1,?,k\alpha_i\geq0,i=1, \cdots,k��i?��0,i=1,?,kǰ���£����м���ʽ�����ǿ��Եõ���������:
min?x(f(x)+{0,��x����Լ����,��x������Լ��)\min_{x}\left(f(x)+\left\{\begin{array}{l}{0}\,, & �� x \,����Լ�� \\ {\infty}\,, & �� x \,������Լ��\end{array}\right.\right) xmin?(f(x)+{ 0,��,?��x����Լ����x������Լ��?)
�ɴ��������ǿ��Խ����м���ʽ�ȼ���ԭ���⣺
min?xf(x)s.t.gi(x)��0,i=1,?,khj(x)=0,j=1,?,l\min_{x}f(x)\\ s.t. g_i(x)\leq0,i=1, \cdots,k\\ h_j(x)=0,j=1, \cdots,l xmin?f(x)s.t.gi?(x)��0,i=1,?,khj?(x)=0,j=1,?,l -
��ż����
���ǿ��Եõ���ż�������£���ż�����Ŀ�꺯���ǹ�����,��\alpha,\beta��,���ġ���
max?��,��min?xL(x,��,��)��i��0,i=1,?,k\max_{\boldsymbol{\alpha}, \boldsymbol{\beta}}\min_{x}\mathcal{L}(x,\boldsymbol{\alpha}, \boldsymbol{\beta})\\ \alpha_i\geq0,i=1, \cdots,k ��,��max?xmin?L(x,��,��)��i?��0,i=1,?,k
��ǿ��ż���������㣬ԭ��������Ž��ͬ�ڶ�ż��������Ž⡣
��ԭ��������slater������ǿ��ż������
slater�������ǣ�������һ���Ż����⣨f,gf,gf,gΪ������hhh�Ƿ��亯������������ٴ��ھ���һ�����Կ��е㣨ʲô�о��Կ��е㣬���Ǵ���һ����x?x^*x?,����gi(x?)<0,i=0,1...kg_i(x*)<0,i=0,1...kgi?(x?)<0,i=0,1...k�����ɵ�slater�����ǣ�gi(x),i=0,1...kg_i(x),i=0,1...kgi?(x),i=0,1...k����mmm�����亯������ôֻ��Ҫ����һ�����е�ʹ��ʣ���k?mk-mk?m������ʽ�ϸ���������ǵ�SVM�����ι滮������slater������ -
��ż����ļ�������
���Ǽ���һ�����Ż����⡣ԭ���⣺
min?xf(x)s.t.m(x)��0\min_{x}f(x)\\ s.t. \quad m(x)\leq0 xmin?f(x)s.t.m(x)��0
��ô��ż����Ϊ��
max?��min?xL(x,��)�ˡ�0\max _{\alpha} \min _{x} \mathcal{L}(x,\lambda) \\ \lambda\geq0 ��max?xmin?L(x,��)����0
������t=f(x),u=m(x),(u,t)��Gt=f(x),u=m(x), (u,t)\in \mathcal{G}t=f(x),u=m(x),(u,t)��G
p?=inf?{t�O(u,t)��G,u��0}g(��)=inf?{t+��u�O(u,t)��G}d?=sup?{g(��)�O�ˡ�0}p^{\ast}=\inf\lbrace t\mid (u,t)\in \mathcal{G}, u\leq0\}\\ g(\lambda)= \inf \{t+\lambda u\mid (u,t)\in \mathcal{G}\}\\ d^{\ast}= \sup\{g(\lambda) \mid \lambda\geq0\} p?=inf{ t�O(u,t)��G,u��0}g(��)=inf{ t+��u�O(u,t)��G}d?=sup{ g(��)�O����0}

�ٺ�������
����һ�����ݼ�{xi}im\{x_i\}_{i}^{m}{
xi?}im?��xi?Rpx_i\epsilon \mathbb{R}^{p}xi??Rp��yi?{+1,?1}y_i\epsilon\{+1,-1\}yi??{
+1,?1}�����ݼ��е�������ȫ�ɷ֡�������Ҫ�ҵ�һ����ƽ������ȫ�ָ������ݣ������ƽ����������ǵ�ģ��margin(��,b)margin(\omega,b)margin(��,b)��Ҳ������������ģ�͡����������Ѿ��ҵ��������ƽ�棬���ǽ������������������ݳ�Ϊ֧����������ʵ���Ǿ��볬ƽ������ĵ㡣
arg?min?x�Φ�Tx+b�ΡΦء�\argmin_{x} \quad \frac{\Vert \omega^Tx+b \Vert}{\Vert \omega \Vert} xargmin?����������Tx+b��?
�������ǻ�û���ҵ���ƽ�棬����Ѱ�ҳ�ƽ���ԭ��Ҳ�����أ������ҵ���֧����������ƽ��ľ������ij�ƽ�档Ҳ������������ʽ�ӵij�ƽ�棬��ƽ�����(��,b)(\omega,b)(��,b)��
max?��,bmin?xi,i=1,2..m�Φ�Txi+b�ΡΦء�\max_{\omega,b} \min_{x_i,i=1,2..m} \quad \frac{\Vert \omega^Tx_i+b \Vert}{\Vert \omega \Vert} ��,bmax?xi?,i=1,2..mmin?����������Txi?+b��?
��Ϊ���������С�������ǿ��Լ���һ��������˼�����������⡣����Ҫ�������ǿ�ʼ�����������ȫ�ɷ֡�
yi(��Txi+b)?0,i=1,2,...,m\quad y_i(\omega^T x_i + b) \geqslant 0 ,\quad i=1,2,...,m yi?(��Txi?+b)?0,i=1,2,...,m
�������ǵó���������Ż�Ŀ������,��ʱ�ǵ�����������Ҫ����ģ��margin(��,b)margin(\omega,b)margin(��,b)�еIJ���(��,b)(\omega,b)(��,b)������ͨ������Ż�Ŀ�����õ����������
{max?��,bmin?xi,i=1,2..m�Φ�Txi+b�ΡΦء�s.t.yi(��Txi+b)?0,i=1,2,...,m\left \{ \begin{matrix} \max_{\omega,b} \min_{x_i,i=1,2..m} \quad \frac{\Vert \omega^Tx_i+b \Vert}{\Vert \omega \Vert} \\ s.t. \quad y_i(\omega^T x_i + b) \geqslant 0 ,\quad i=1,2,...,m \end{matrix} \right. {
max��,b?minxi?,i=1,2..m?����������Txi?+b��?s.t.yi?(��Txi?+b)?0,i=1,2,...,m?
���������������ݼ��������Կɷ֣����ǿ��Խ����ӵľ���ֵ�滻������һ��һ���Ż�Ŀ�ꡣ
{max?��,bmin?xi,i=1,2..myi(��Txi+b)�Φء�s.t.yi(��Txi+b)?0,i=1,2,...,m\left \{ \begin{matrix} \max_{\omega,b} \min_{x_i,i=1,2..m} \quad \frac{y_i ( \omega^Tx_i+b )}{\Vert \omega \Vert} \\ s.t. \quad y_i(\omega^T x_i + b) \geqslant 0 ,\quad i=1,2,...,m \end{matrix} \right. {
max��,b?minxi?,i=1,2..m?������yi?(��Txi?+b)?s.t.yi?(��Txi?+b)?0,i=1,2,...,m?
���������ڷ����Ǻ����������������������ţ����ǽ�֧�������ĺ�������趨Ϊ1��Ҳ����
min?xi,i=1,2..myi(��Txi+b)=1\min_{x_i,i=1,2..m} y_i ( \omega^Tx_i+b ) = 1xi?,i=1,2..mmin?yi?(��Txi?+b)=1
��ô�Ż�Ŀ����Խ�һ������Ϊ��
{max?��,b1�Φء�s.t.yi(��Txi+b)?1,i=1,2,...,m\left \{ \begin{matrix} \max_{\omega,b} \quad \frac{1}{\Vert \omega \Vert} \\ s.t. \quad y_i(\omega^T x_i + b) \geqslant 1 ,\quad i=1,2,...,m \end{matrix} \right. {
max��,b?������1?s.t.yi?(��Txi?+b)?1,i=1,2,...,m?
���ǽ��Ż�Ŀ����һ�λ���,12\frac{1}{2}21?ֻ��Ϊ�˷���������ӡ�
{min?��,b12��T��s.t.1?yi(��Txi+b)?0,i=1,2,...,m\left \{ \begin{matrix} \min_{\omega,b} \quad \frac{1}{2} \omega^T\omega \\ s.t. \quad 1-y_i(\omega^T x_i + b) \leqslant 0 ,\quad i=1,2,...,m \end{matrix} \right. {
min��,b?21?��T��s.t.1?yi?(��Txi?+b)?0,i=1,2,...,m?
������ݼ�С�������ݵ�ά��p�ͣ���ô��ʱ����һ���Ķ��ι滮���⣨QP����
��������ʵ�����������⣬1�������ݵ�ά��Ҳ���ܸܺߣ�ͬʱ���Բ��ɷ֣�1�������ݼ�̫��������Ҫ���õĽ������������������������ṹ��������ͨ���������ն�ż�ԣ�Lagrange Duality���任����ż���� (dual variable) ���Ż����⣬��ͨ�������ԭ����ȼ۵Ķ�ż���⣨dual problem���õ�ԭʼ��������Ž⣬��������Կɷ�������֧���������Ķ�ż�㷨�����������ŵ����ڣ�һ�߶�ż����������������⣬������ݵ�ά�ȸ����⣻���߿�����Ȼ������˺����������ƹ㵽�����Է�����������ż��ʽ�����ö��ι滮������⣬�����ܵ����ݼ���С�����ơ������������SMO�㷨��������ݼ�̫������ż�㷨�����ѵ����⡣
��������������ձ��������ż��ʽ
����������ʹ���������ճ���������Լ�����Ż�Ŀ�껯ת��Ϊ����Լ�����Ż�Ŀ�ꡣ����ʹ����\alpha�������1...��m\alpha_1...\alpha_m��1?...��m?���������պ����������Ϊ��
L(��,b,��)=12�Φء�2+��i=1m��i[1?yi(��Txi+b)]L(\omega,b,\alpha)=\frac{1}{2}\|\omega\|^2 + \sum_{i=1}^m\alpha_i\Big[1-y_i(\omega^Tx_i+b)\Big] L(��,b,��)=21?������2+i=1��m?��i?[1?yi?(��Txi?+b)]
���ǿ���д��ԭ����Ķ�ż���⣺
{max?��min?��,bL(��,b,��)s.t.��i?0,i=1,2,...,m\left \{ \begin{matrix} \max_{\alpha} \min_{\omega,b} L(\omega,b,\alpha) \\ s.t. \alpha_i \geqslant 0 ,\quad i=1,2,...,m \end{matrix} \right. {
max��?min��,b?L(��,b,��)s.t.��i??0,i=1,2,...,m?
Ŀ���Ƕ��εģ�Լ�������Եģ������������Ż����⣬��ô����ǿ��ż������ǿ��ż��ζ������KKT������
�������,b\omega,b��,b
�������ǰ���\alpha�����������������min?��,bL(��,b,��)\min_{\omega,b} L(\omega,b,\alpha)min��,b?L(��,b,��)�õ���,b\omega,b��,b��
?L(��,b,��)?��=��?��i=1m��iyixi=0\frac{\partial L(\omega,b,\alpha)}{\partial \omega}=\omega-\sum_{i=1}^{m}\alpha_iy_ix_i=0?��?L(��,b,��)?=��?i=1��m?��i?yi?xi?=0
?L(��,b,��)?b=��i=1m��iyi=0\frac{\partial L(\omega,b,\alpha)}{\partial b}=\sum_{i=1}^{m}\alpha_iy_i=0?b?L(��,b,��)?=i=1��m?��i?yi?=0
ͨ�������ʽ�ӣ���ʱ����\omega���õ��˽⣬�������KKT������֪��ʵ��xix_ixi?����֧����������ô��i=0\alpha_i=0��i?=0��������\omega������֧������������
��?=��i=1m��iyixi\omega^*=\sum_{i=1}^{m}\alpha_iy_ix_i��?=i=1��m?��i?yi?xi?
��ôbbbҪͨ��KKT�����е��ɳڻ���������á��������ǿ�һ�����������KKT�������¡�
{?L(��,b,��)?��=0?L(��,b,��)?b=0��i?0,i=1,2,...,m1?yi(��Txi+b)?0,i=1,2,...,m��i[yi(��Txi+b)?1]=0,i=1,2,...,m\left \{ \begin{matrix} \frac{\partial L(\omega,b,\alpha)}{\partial \omega}=0 \\ \frac{\partial L(\omega,b,\alpha)}{\partial b}=0 \\ \alpha_i\geqslant 0,\quad i=1,2,...,m \\ 1-y_i(\omega^Tx_i+b)\leqslant 0,\quad i=1,2,...,m \\ \alpha_i[y_i(\omega^Tx_i+b)-1]=0,\quad i=1,2,...,m \end{matrix} \right. ?????????????��?L(��,b,��)?=0?b?L(��,b,��)?=0��i??0,i=1,2,...,m1?yi?(��Txi?+b)?0,i=1,2,...,m��i?[yi?(��Txi?+b)?1]=0,i=1,2,...,m?
����KKT�ɳڻ�������Ҳ����������������������֪��{��i}i=1m\{\alpha_i\}_{i=1}^m{
��i?}i=1m?��ֵ,��ȡ��k>0\alpha_k>0��k?>0ͬʱȡ�ö�Ӧ��xk,ykx_k,y_kxk?,yk?,��ôyk(��?Txk+b)?1=0y_k(\omega^{*T}x_k+b)-1=0yk?(��?Txk?+b)?1=0,Ҳ����ζ��xkx_kxk?Ϊ֧����������֪��
��?=��i=1m��iyixi\omega^*=\sum_{i=1}^{m}\alpha_iy_ix_i��?=i=1��m?��i?yi?xi?
��ôb?b^*b?Ҳ�����õ���
b?=yk?��?Txk=yk?��i=1m��iyixiTxkb^*=y_k-\omega^{*T}x_k=y_k-\sum_{i=1}^{m}\alpha_iy_ix_i^Tx_kb?=yk??��?Txk?=yk??i=1��m?��i?yi?xiT?xk?
ģ��Ҳ�����õ���margin(��,b)=sign(��?Tx+b?)margin(\omega,b)=sign(\omega^{*T}x+b^*)margin(��,b)=sign(��?Tx+b?)
�������Dz���֪��{��i}i=1m\{\alpha_i\}_{i=1}^m{ ��i?}i=1m?��������Ҫ���{��i}i=1m\{\alpha_i\}_{i=1}^m{ ��i?}i=1m?֮����ܵõ�b?����?b^*��\omega^*b?����?
�������\alpha��
��Ȼ�����{��i}i=1m\{\alpha_i\}_{i=1}^m{
��i?}i=1m?ǰ�����õ�b?����?b^*��\omega^*b?����?��������֪�����½���:
?L(��,b,��)?��=��?��i=1m��iyixi=0\frac{\partial L(\omega,b,\alpha)}{\partial \omega}=\omega-\sum_{i=1}^{m}\alpha_iy_ix_i=0?��?L(��,b,��)?=��?i=1��m?��i?yi?xi?=0
?L(��,b,��)?b=��i=1m��iyi=0\frac{\partial L(\omega,b,\alpha)}{\partial b}=\sum_{i=1}^{m}\alpha_iy_i=0?b?L(��,b,��)?=i=1��m?��i?yi?=0
���ǰ�������ֵ����L(��,b,��)L(\omega,b,\alpha)L(��,b,��)�����min?��,bL(��,b,��)\min_{\omega,b}L(\omega,b,\alpha)min��,b?L(��,b,��)
min?��,bL(��,b,��)=12�Φء�2+��i=1m��i[1?yi(��Txi+b)]=12�Ρ�i=1m��iyixi��2+��i=1m��i?��T��i=1m��iyixi=��i=1m��i+12��T��i=1m��iyixi?��T��i=1m��iyixi=��i=1m��i?(��i=1m��iyixiT)(��i=1m��iyixi)=��i=1m��i?��i=1m��j=1m��i��jyiyjxiTxj\min_{\omega,b}L(\omega,b,\alpha)=\frac{1}{2}\|\omega\|^2 + \sum_{i=1}^m\alpha_i\Big[1-y_i(\omega^Tx_i+b)\Big] \\ = \frac{1}{2}\left\| \sum_{i=1}^{m}\alpha_iy_ix_i \right\|^2 + \sum_{i=1}^{m}\alpha_i - \omega^T\sum_{i=1}^{m}\alpha_iy_ix_i \\ =\sum_{i=1}^{m}\alpha_i + \frac{1}{2}\omega^T\sum_{i=1}^{m}\alpha_iy_ix_i- \omega^T\sum_{i=1}^{m}\alpha_iy_ix_i \\ =\sum_{i=1}^{m}\alpha_i - \left(\sum_{i=1}^{m}\alpha_iy_ix_i^T\right)\left(\sum_{i=1}^{m}\alpha_iy_ix_i\right) \\ =\sum_{i=1}^{m}\alpha_i - \sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j ��,bmin?L(��,b,��)=21?������2+i=1��m?��i?[1?yi?(��Txi?+b)]=21?����������?i=1��m?��i?yi?xi?����������?2+i=1��m?��i??��Ti=1��m?��i?yi?xi?=i=1��m?��i?+21?��Ti=1��m?��i?yi?xi??��Ti=1��m?��i?yi?xi?=i=1��m?��i??(i=1��m?��i?yi?xiT?)(i=1��m?��i?yi?xi?)=i=1��m?��i??i=1��m?j=1��m?��i?��j?yi?yj?xiT?xj?
���յ�
min?��,bL(��,b,��)=��i=1m��i?��i=1m��j=1m��i��jyiyjxiTxj\min_{\omega,b}L(\omega,b,\alpha) =\sum_{i=1}^{m}\alpha_i - \sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j��,bmin?L(��,b,��)=i=1��m?��i??i=1��m?j=1��m?��i?��j?yi?yj?xiT?xj?
�������ǵ��Ż�Ŀ��ת��Ϊ���£����ı���Ϊ��\alpha����
{max?����i=1m��i?��i=1m��j=1m��i��jyiyjxiTxjs.t.��i=1m��iyi=0��i?0,i=1,2,...,m\left \{ \begin{matrix} \max_{\alpha} \quad \sum_{i=1}^{m}\alpha_i - \sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jx_i^Tx_j \\ s.t. \sum_{i=1}^{m}\alpha_iy_i=0 \\ \alpha_i \geqslant 0,\quad i=1,2,...,m \end{matrix} \right. ????max��?��i=1m?��i??��i=1m?��j=1m?��i?��j?yi?yj?xiT?xj?s.t.��i=1m?��i?yi?=0��i??0,i=1,2,...,m?
��ʱ�����ǿ������ö��ι滮�����\alpha������ʱ��Ķ��ι滮�����Ѿ�һ���̶Ƚ����ԭ����ά�ȴ�����⣬�������ݷ�������Ҫ����˺�����������Ż�Ŀ��תΪ���£�
{max?����i=1m��i?��i=1m��j=1m��i��jyiyjK(xi,xj)s.t.��i=1m��iyi=0��i?0,i=1,2,...,m\left \{ \begin{matrix} \max_{\alpha} \quad \sum_{i=1}^{m}\alpha_i - \sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jK(x_i,x_j) \\ s.t. \sum_{i=1}^{m}\alpha_iy_i=0 \\ \alpha_i \geqslant 0,\quad i=1,2,...,m \end{matrix} \right. ????max��?��i=1m?��i??��i=1m?��j=1m?��i?��j?yi?yj?K(xi?,xj?)s.t.��i=1m?��i?yi?=0��i??0,i=1,2,...,m?
�����ʱ���ι滮���Ӷ���Ҫ�������ݼ���С������������ݼ�̫��������Ҫ���õĽ��������SMO�㷨��
��SMO�㷨�������\alpha������һ���㷨��
SMO��һ������ʽ�㷨�����ص��Dz��ϵؽ�ԭ���ι滮����ֽ�Ϊֻ�����������Ķ��ι滮�����⣬������������н�����⣬ֱ�����б�������KKT����Ϊ��http://cs229.stanford.edu/notes2019fall/cs229-notes3.pdf��https://blog.csdn.net/ACM_hades/article/details/90701030����Ϊ�����
���ǻ���soft-margin�㷨������SMO�㷨�����Ƚ���SMO�㷨������,֮����ϸ���ܹ��̣�
- �����ʼ��{��iold}i=1m��bold=0\{\alpha_i^{old}\}_{i=1}^{m}��b^{old}=0{ ��iold?}i=1m?��bold=0����ô���Լ���{Eiold}i=1m\{E_i^{old}\}_{i=1}^{m}{ Eiold?}i=1m?
- ����ָ������ѡ����1old����2old\alpha_1^{old}��\alpha_2^{old}��1old?����2old?
- �����µ���2new\alpha_2^{new}��2new?��
��2new,unclip=��2old+y2(E1old?E2old)K11+K22?2K12��2new={H��2new,unclip>H��2new,unclipL�ܦ�2new,unclip��HL��2new,unclip<L\alpha_2^{new,unclip} = \alpha_2^{old} + \frac{y_2(E_1^{old}-E_2^{old})}{K_{11} +K_{22}-2K_{12}} \\ \alpha_2^{new}= \begin{cases} H& { \alpha_2^{new,unclip} > H} \\ \alpha_2^{new,unclip}& {L \leq \alpha_2^{new,unclip} \leq H}\\ L& {\alpha_2^{new,unclip} < L} \end{cases} ��2new,unclip?=��2old?+K11?+K22??2K12?y2?(E1old??E2old?)?��2new?=??????H��2new,unclip?L?��2new,unclip?>HL����2new,unclip?��H��2new,unclip?<L? - �����µ���1new\alpha_1^{new}��1new?����1new=��1old+y1y2(��2old?��2new)\alpha_1^{new} = \alpha_1^{old} +y_1y_2(\alpha_2^{old}-\alpha_2^{new})��1new?=��1old?+y1?y2?(��2old??��2new?)
- ����{��1new,��2new,��iold}i=3m\{\alpha_1^{new},\alpha_2^{new},\alpha_i^{old}\}_{i=3}^{m}{ ��1new?,��2new?,��iold?}i=3m?������bnew,{Einew}i=1mb^{new},\{E_i^{new}\}_{i=1}^{m}bnew,{ Einew?}i=1m?
- �������������1��{��iend}i=1m\{\alpha_i^{end}\}_{i=1}^{m}{ ��iend?}i=1m?��Υ��KKT�������ߣ�2��Ŀ�꺯����������С��һ��ֵW(��end)?W(��end?1)W(��end?1)<T\frac{W(\alpha^{end})-W(\alpha^{end-1})}{W(\alpha^{end-1})}<TW(��end?1)W(��end)?W(��end?1)?<T��ôֹͣ�����صڶ�����
�������ҽ�������ϸ��ÿһ����
- �����ʼ��{��iold}i=1m��bold=0\{\alpha_i^{old}\}_{i=1}^{m}��b^{old}=0{
��iold?}i=1m?��bold=0����ô���Լ���{Eiold}i=1m\{E_i^{old}\}_{i=1}^{m}{
Eiold?}i=1m?��
�ⲽ����һ����ʼ��������Ϊ�������������֪{��iold}i=1m��bold=0\{\alpha_i^{old}\}_{i=1}^{m}��b^{old}=0{ ��iold?}i=1m?��bold=0����ô���Լ���{Eiold}i=1m\{E_i^{old}\}_{i=1}^{m}{ Eiold?}i=1m?��Eiold=g(xi)?yi=��j=1myj��joldK(xi,xj)+bold?yiE_i^{old}=g(x_i)-y_i=\sum\limits_{j=1}^{m}y_j\alpha^{old}_jK(x_i,x_j) +b^{old}-y_iEiold?=g(xi?)?yi?=j=1��m?yj?��jold?K(xi?,xj?)+bold?yi? - ����ָ������ѡ����1old����2old\alpha_1^{old}��\alpha_2^{old}��1old?����2old?��
���ѡ����1old����2old\alpha_1^{old}��\alpha_2^{old}��1old?����2old?����������һ����ѡ���һ���㣺ԭ����ѡȡΥ��KKT���������ص������㡣����ķ���KKT����ָ��������ʽ��(������һ��soft-margin��KKT�����Ƴ�)������ѡ��Υ��0<��i<C?yi(��Txi+b)=10 < \alpha_{i} < C \Leftrightarrow y_i (\omega^T x_i+b) =10<��i?<C?yi?(��Txi?+b)=1�ĵ㣬��ѡ��Υ��������������ĵ㡣�ڶ���ѡ��ڶ����㣺ԭ��Ϊѡ�����OE1old?E2old�O|E_1^{old}-E_2^{old}|�OE1old??E2old?�O���ĵ㡣��ѡ����һ���������Ѿ�֪��E1oldE_1^{old}E1old?����ô���Ը����OE1old?E2old�O|E_1^{old}-E_2^{old}|�OE1old??E2old?�OѰ�ҵڶ����㣬ԭ������2new\alpha_2^{new}��2new?�������OE1old?E2old�O|E_1^{old}-E_2^{old}|�OE1old??E2old?�O����һ���ῴ������Ϊ������2old\alpha_2^{old}��2old?����2new\alpha_2^{new}��2new?�仯�����������������ѡ��
��i=0?yi(��Txi+b)��10<��i<C?yi(��Txi+b)=1��i=C?yi(��Txi+b)��1\alpha_{i} =0 \Leftrightarrow y_i(\omega^T x_i+b) \geq1 \\ 0 < \alpha_{i} < C \Leftrightarrow y_i(\omega^T x_i+b) =1 \\ \alpha_{i}= C\Leftrightarrow y_i(\omega^T x_i+b) \leq 1 ��i?=0?yi?(��Txi?+b)��10<��i?<C?yi?(��Txi?+b)=1��i?=C?yi?(��Txi?+b)��1 - �����µ���2new\alpha_2^{new}��2new?���ټ����µ���1new\alpha_1^{new}��1new?��
�ⲽ����ӵġ���εó����µ���2new\alpha_2^{new}��2new?�������£�
��������2new,��1new\alpha_2^{new},\alpha_1^{new}��2new?,��1new?Ϊ��������2new?,��1new?\alpha_2^{new*},\alpha_1^{new*}��2new??,��1new??Ϊ��������2new?,��1new?\alpha_2^{new*},\alpha_1^{new*}��2new??,��1new??�����ⲽ���ո��µ���2new,��1new\alpha_2^{new},\alpha_1^{new}��2new?,��1new?��ֵ��
����ѡ���������������1new,��2new\alpha^{new}_{1},\alpha^{new}_{2}��1new?,��2new?����������{��iold}i=3m\{\alpha^{old}_{i}\}_{i=3}^m{ ��iold?}i=3m?�ǹ̶��ģ���ô���DZ���������SMO�����Ż�����������⾭����������д�ɣ�
min?��1new,��2newW(��1new,��2new)=12K11��1new2+12K22��2new2+y1y2K12��1new��2new?(��1new+��2new)+y1��1new��i=3myi��ioldKi1+y2��2��i=3myi��ioldKi2+Bs.t.��1newy1+��2newy2=��1oldy1+��2oldy2=?��i=3myi��iold=?0�ܦ�inew��Ci=1,2\;\;\min _{\alpha^{new}_1, \alpha^{new}_2} W(\alpha^{new}_1,\alpha^{new}_2)=\frac{1}{2}K_{11}\alpha_1^{new2} + \frac{1}{2}K_{22}\alpha_2^{new2} \\ +y_1y_2K_{12}\alpha^{new}_1 \alpha^{new}_2 -(\alpha^{new}_1 + \alpha^{new}_2) +y_1\alpha^{new}_1\sum\limits_{i=3}^{m}y_i\alpha^{old}_iK_{i1} + y_2\alpha_2\sum\limits_{i=3}^{m}y_i\alpha^{old}_iK_{i2}+B \\ s.t. \;\;\alpha^{new}_1y_1 + \alpha^{new}_2y_2 =\alpha^{old}_1y_1 + \alpha^{old}_2y_2= -\sum\limits_{i=3}^{m}y_i\alpha^{old}_i = \varsigma \\ 0 \leq \alpha^{new}_i \leq C \;\; i =1,2 ��1new?,��2new?min?W(��1new?,��2new?)=21?K11?��1new2?+21?K22?��2new2?+y1?y2?K12?��1new?��2new??(��1new?+��2new?)+y1?��1new?i=3��m?yi?��iold?Ki1?+y2?��2?i=3��m?yi?��iold?Ki2?+Bs.t.��1new?y1?+��2new?y2?=��1old?y1?+��2old?y2?=?i=3��m?yi?��iold?=?0����inew?��Ci=1,2
����B,?B, \varsigmaB,?�dz����ǰ��������1new,��2new\alpha^{new}_{1},\alpha^{new}_{2}��1new?,��2new?�����Ż�����ǹ۲쵽����Ŀ�����Ż�����������ͬʱ����һ����ʽԼ����һ������ʽԼ����ָ�����ǵ�˼����ǣ��Ȱѵ�ʽ��������������1new\alpha^{new}_{1}��1new?�����ڲ���ʽ���������ҵ����DZ�����2new\alpha^{new}_{2}��2new?�����Ž⣬������õ�ʽ�õ�����һ��������1new\alpha^{new}_{1}��1new?�Ľ⡣
Ϊ����ʽ�ӿ������������࣬��������vi=��j=3myj��joldK(xi,xj)=g(xi)?��j=12yj��joldK(xi,xj)?boldv_i = \sum\limits_{j=3}^{m}y_j\alpha^{old}_jK(x_i,x_j) = g(x_i) - \sum\limits_{j=1}^{2}y_j\alpha^{old}_jK(x_i,x_j) -b^{old}vi?=j=3��m?yj?��jold?K(xi?,xj?)=g(xi?)?j=1��2?yj?��jold?K(xi?,xj?)?bold,������g(xi)=��j=1myj��joldK(xi,xj)+boldg(x_i)=\sum\limits_{j=1}^{m}y_j\alpha^{old}_jK(x_i,x_j) +b^{old}g(xi?)=j=1��m?yj?��jold?K(xi?,xj?)+bold,��ô�Ż�Ŀ��д����ʽ��
W(��1new,��2new)=12K11��12new+12K22��22new+y1y2K12��1new��2new?(��1new+��2new)+y1��1newv1+y2��2newv2W(\alpha^{new}_1,\alpha^{new}_2) = \frac{1}{2}K_{11}\alpha_1^{2new} + \frac{1}{2}K_{22}\alpha_2^{2 new}+y_1y_2K_{12}\alpha^{new}_1 \alpha^{new}_2 -(\alpha^{new}_1 + \alpha^{new}_2) \\+y_1\alpha^{new}_1v_1 + y_2\alpha^{new}_2v_2 W(��1new?,��2new?)=21?K11?��12new?+21?K22?��22new?+y1?y2?K12?��1new?��2new??(��1new?+��2new?)+y1?��1new?v1?+y2?��2new?v2?
������1newy1+��2newy2=?��i=3myi��iold=?\alpha^{new}_1y_1 + \alpha^{new}_2y_2 = -\sum\limits_{i=3}^{m}y_i\alpha^{old}_i = \varsigma��1new?y1?+��2new?y2?=?i=3��m?yi?��iold?=?�Լ�yi2=1y_i^2=1yi2?=1,��ʽ��ϵд����1new=y1(??��2newy2)\alpha^{new}_1 = y_1(\varsigma - \alpha^{new}_2y_2)��1new?=y1?(??��2new?y2?)�������Ż�Ŀ����Ԫ��������Ż�Ŀ���Լ�Լ�����£�
W(��2new)=12K11(??��2newy2)2+12K22��22new+y2K12(??��2newy2)��2new?(??��2newy2)y1?��2new+(??��2newy2)v1+y2��2newv2s.t.0�ܦ�2new��C0��y1(??��2newy2)��CW(\alpha^{new}_2) = \frac{1}{2}K_{11}(\varsigma - \alpha^{new}_2y_2)^2 + \frac{1}{2}K_{22}\alpha_2^{2 new}+y_2K_{12}(\varsigma - \alpha^{new}_2y_2) \alpha^{new}_2 \\ -(\varsigma - \alpha^{new}_2y_2)y_1 - \alpha^{new}_2 +(\varsigma - \alpha^{new}_2y_2)v_1 + y_2\alpha^{new}_2v_2\\ s.t. \;\;0 \leq \alpha^{new}_2 \leq C \\ 0 \leq y_1(\varsigma - \alpha^{new}_2y_2) \leq C W(��2new?)=21?K11?(??��2new?y2?)2+21?K22?��22new?+y2?K12?(??��2new?y2?)��2new??(??��2new?y2?)y1??��2new?+(??��2new?y2?)v1?+y2?��2new?v2?s.t.0����2new?��C0��y1?(??��2new?y2?)��C
��������һ��֪����ô���ˣ�һ��������0��Ѱ�Ҽ�ֵ�㣺
?W?��2new=K11��2new+K22��2new?2K12��2new?K11?y2+K12?y2+y1y2?1?v1y2+y2v2=0\frac{\partial W}{\partial \alpha^{new}_2} = K_{11}\alpha^{new}_2 + K_{22}\alpha^{new}_2 -2K_{12}\alpha^{new}_2 - K_{11}\varsigma y_2 + K_{12}\varsigma y_2 +y_1y_2 -1 -v_1y_2 +y_2v_2 = 0 \\ ?��2new??W?=K11?��2new?+K22?��2new??2K12?��2new??K11??y2?+K12??y2?+y1?y2??1?v1?y2?+y2?v2?=0
��ô�õ���û����Լ������������ֵ��
��2new,unclip=��2old+y2(E1old?E2old)K11+K22?2K12\alpha_2^{new,unclip} = \alpha_2^{old} + \frac{y_2(E_1^{old}-E_2^{old})}{K_{11} +K_{22}-2K_{12}} ��2new,unclip?=��2old?+K11?+K22??2K12?y2?(E1old??E2old?)?
���������ǽ�����Լ���ҵ���2new?\alpha_2^{new*}��2new??��һЩ���Ͱ����γ̳���ͼ������Լ�����и������������⣬�������뵥���Ƶ����ó������
{0�ܦ�2new��C0��y1(??��2newy2)��C\begin{cases} 0 \leq \alpha^{new}_2 \leq C \\ 0 \leq y_1(\varsigma - \alpha^{new}_2y_2) \leq C \end{cases} { 0����2new?��C0��y1?(??��2new?y2?)��C?
������1oldy1+��2oldy2=?\alpha_1^{old}y_1 + \alpha_2^{old}y_2 = \varsigma��1old?y1?+��2old?y2?=?�õ�
{0�ܦ�2new��Cy1y2��1old+��2old?Cy1y2�ܦ�2new��y1y2��1old+��2old\begin{cases} 0 \leq \alpha_2^{new} \leq C \\ \frac{y_1}{y_2}\alpha_1^{old}+\alpha_2^{old}- \frac{C}{y_1y_2} \leq \alpha_2^{new} \leq \frac{y_1}{y2}\alpha_1^{old}+\alpha_2^{old} \end{cases} { 0����2new?��Cy2?y1??��1old?+��2old??y1?y2?C?����2new?��y2y1??��1old?+��2old??
Ҳ����
max{0,y1y2��1old+��2old?Cy1y2}�ܦ�2new��min{C,y1y2��1old+��2old}max\{0,\frac{y_1}{y_2}\alpha_1^{old}+\alpha_2^{old}- \frac{C}{y_1y_2}\} \leq \alpha_2^{new} \leq min\{C, \frac{y_1}{y2}\alpha_1^{old}+\alpha_2^{old}\} max{ 0,y2?y1??��1old?+��2old??y1?y2?C?}����2new?��min{ C,y2y1??��1old?+��2old?}
Ϊ�˱����������L=max{0,y1y2��1old+��2old?Cy1y2},H=min{C,y1y2��1old+��2old}L=max\{0,\frac{y_1}{y_2}\alpha_1^{old}+\alpha_2^{old}- \frac{C}{y_1y_2}\},H=min\{C, \frac{y_1}{y2}\alpha_1^{old}+\alpha_2^{old}\}L=max{ 0,y2?y1??��1old?+��2old??y1?y2?C?},H=min{ C,y2y1??��1old?+��2old?}���ǵõ�����2new?\alpha_2^{new*}��2new??��
��2new?={H��2new,unc>H��2new,uncL�ܦ�2new,unc��HL��2new,unc<L\alpha_2^{new*}= \begin{cases} H& { \alpha_2^{new,unc} > H}\\ \alpha_2^{new,unc}& {L \leq \alpha_2^{new,unc} \leq H}\\ L& {\alpha_2^{new,unc} < L} \end{cases} ��2new??=??????H��2new,unc?L?��2new,unc?>HL����2new,unc?��H��2new,unc?<L?
���������1oldy1+��2oldy2=��1newy1+��2newy2\alpha_1^{old}y_1 + \alpha_2^{old}y_2 =\alpha_1^{new}y_1 + \alpha_2^{new}y_2��1old?y1?+��2old?y2?=��1new?y1?+��2new?y2?���Եõ�
��1new?=��1old+y1y2(��2old?��2new?)\alpha_1^{new*} = \alpha_1^{old} +y_1y_2(\alpha_2^{old}-\alpha_2^{new*})��1new??=��1old?+y1?y2?(��2old??��2new??)
�������ǽ���1new,��2new\alpha_1^{new},\alpha_2^{new}��1new?,��2new?����Ϊ��1new?,��2new?\alpha_1^{new*},\alpha_2^{new*}��1new??,��2new?? - ����{��1new,��2new,��iold}i=3m\{\alpha_1^{new},\alpha_2^{new},\alpha_i^{old}\}_{i=3}^{m}{
��1new?,��2new?,��iold?}i=3m?������bnew,{Einew}i=1mb^{new},\{E_i^{new}\}_{i=1}^{m}bnew,{
Einew?}i=1m?��
��һ����Ҫ��Ϊ����һ�ε�ѭ�������������Ǹ���bnewb^{new}bnew,ÿ�����Ǹ�����һ����1new,��2new\alpha_1^{new},\alpha_2^{new}��1new?,��2new?�����Ƕ���Լ������0�ܦ�inew��Ci=1,20 \leq \alpha^{new}_i \leq C \;\; i =1,20����inew?��Ci=1,2,ͬʱ����KKT�������ȼ���yi(��Txi+b)?1=0i=1,2y_i(\omega^T x_i+b) -1=0 \;\;i=1,2yi?(��Txi?+b)?1=0i=1,2����ʱ���ǵõ�
y1?��i=1m��iyiKi1?b1=0y2?��i=1m��iyiKi2?b2=0y_1 - \sum\limits_{i=1}^{m}\alpha_iy_iK_{i1} -b_1 = 0 \\ y_2 - \sum\limits_{i=1}^{m}\alpha_iy_iK_{i2} -b_2 = 0 y1??i=1��m?��i?yi?Ki1??b1?=0y2??i=1��m?��i?yi?Ki2??b2?=0
�Ӷ��õ���
b1new=y1?��i=3m��iyiKi1?��1newy1K11?��2newy2K21b2new=y2?��i=3m��iyiKi2?��1newy1K12?��2newy2K22b_1^{new} = y_1 - \sum\limits_{i=3}^{m}\alpha_iy_iK_{i1} - \alpha_{1}^{new}y_1K_{11} - \alpha_{2}^{new}y_2K_{21}\\ b_2^{new} = y_2 - \sum\limits_{i=3}^{m}\alpha_iy_iK_{i2} - \alpha_{1}^{new}y_1K_{12} - \alpha_{2}^{new}y_2K_{22} b1new?=y1??i=3��m?��i?yi?Ki1??��1new?y1?K11??��2new?y2?K21?b2new?=y2??i=3��m?��i?yi?Ki2??��1new?y1?K12??��2new?y2?K22?
�����õ�
E1new=g(x1)?y1=��i=3m��iyiKi1+��1oldy1K11+��2oldy2K21+bold?y1E2new=g(x2)?y2=��i=3m��iyiKi2+��1oldy1K12+��2oldy2K22+bold?y2E_1^{new} = g(x_1) - y_1 = \sum\limits_{i=3}^{m}\alpha_iy_iK_{i1} + \alpha_{1}^{old}y_1K_{11} + \alpha_{2}^{old}y_2K_{21} + b^{old} -y_1 \\ E_2^{new} = g(x_2) - y_2 = \sum\limits_{i=3}^{m}\alpha_iy_iK_{i2} + \alpha_{1}^{old}y_1K_{12} + \alpha_{2}^{old}y_2K_{22} + b^{old} -y_2 E1new?=g(x1?)?y1?=i=3��m?��i?yi?Ki1?+��1old?y1?K11?+��2old?y2?K21?+bold?y1?E2new?=g(x2?)?y2?=i=3��m?��i?yi?Ki2?+��1old?y1?K12?+��2old?y2?K22?+bold?y2?
һ����˵���bnew=12(b1new+b2new)b^{new}=\frac{1}{2}(b_1^{new}+b_2^{new})bnew=21?(b1new?+b2new?) - �������������1��{��iend}i=1m\{\alpha_i^{end}\}_{i=1}^{m}{ ��iend?}i=1m?��Υ��KKT�������ߣ�2��Ŀ�꺯����������С��һ��ֵW(��end)?W(��end?1)W(��end?1)<T\frac{W(\alpha^{end})-W(\alpha^{end-1})}{W(\alpha^{end-1})}<TW(��end?1)W(��end)?W(��end?1)?<T��ôֹͣ�������������ǿ�����1new,��2new,bnew,E1new,E2new\alpha_1^{new},\alpha_2^{new},b^{new},E_1^{new},E_2^{new}��1new?,��2new?,bnew,E1new?,E2new?����Ϊ��1old,��2old,bold,E1old,E2old\alpha_1^{old},\alpha_2^{old},b^{old},E_1^{old},E_2^{old}��1old?,��2old?,bold,E1old?,E2old?,���صڶ�����
soft-margin
����֮ǰ�Ǽ��������Կɷֵģ������˺˼��ɶ������Բ��ɷ�Ҳ���˴�������������������������������ǿӲ�Ľ�������Dz�����ģ�͵ĵģ���������soft-marginģ�͡���־����ʦ����ô˵�ģ�ÿһ��������һ���ɳڱ������������������ݲ�����Լ��(yi(��Txi+b)��1)( y_i(\omega^T x_i + b) \geq 1 )(yi?(��Txi?+b)��1)�����������C��im��iC\sum_{i}^{m} \xi_iC��im?��i?���Կ���һ����ʧ��Ҳ���Կ���һ��L1����C����ͷ����ӣ�CԽ��Խ�����ɳ����ӵĴ�С���ݴ��ռ�ԽС��CԽС��Խ�������ɳ����ӣ��ݴ��ռ�Խ�����Cȡ������ȼ�ΪHard Margin SVM��
ԭ�������£�
{min?��,b12��T��+C��im��is.t.yi(��Txi+b)?1?��i,i=1,2,...,m��i��0,i=1,2,...,m\left \{ \begin{matrix} \min_{\omega,b} \quad \frac{1}{2} \omega^T\omega+C\sum_{i}^{m} \xi_i \\ s.t. \quad y_i(\omega^T x_i + b) \geqslant1-\xi_i ,\quad i=1,2,...,m \\ \xi_i \geq0,i=1,2,...,m \end{matrix} \right. ????min��,b?21?��T��+C��im?��i?s.t.yi?(��Txi?+b)?1?��i?,i=1,2,...,m��i?��0,i=1,2,...,m?
��ż���������\alpha�������������ʽ��
{max?����i=1m��i?��i=1m��j=1m��i��jyiyjK(xi,xj)s.t.��i=1m��iyi=00?��i?C,i=1,2,...,m\left \{ \begin{matrix} \max_{\alpha} \quad \sum_{i=1}^{m}\alpha_i - \sum_{i=1}^{m}\sum_{j=1}^{m}\alpha_i\alpha_jy_iy_jK(x_i,x_j) \\ s.t. \sum_{i=1}^{m}\alpha_iy_i=0 \\ 0\leqslant \alpha_i \leqslant C,\quad i=1,2,...,m \end{matrix} \right. ????max��?��i=1m?��i??��i=1m?��j=1m?��i?��j?yi?yj?K(xi?,xj?)s.t.��i=1m?��i?yi?=00?��i??C,i=1,2,...,m?
KKT�����ǣ�

��֧���������йصĻع��㷨
LSSVM
SVR
min12�O�Ow�O�O2+C��i=1l(��i+��i?)s.t.{yi?(wTxi+b)<?+��i(wTxi+b)?yi<?+��i?��i,��i?��0min \ \ \frac{1}{2}||w||^2+C\sum_{i=1}^{l}(\xi_i+\xi^*_i)\\ s.t. \ \ \left\{ \begin{aligned} &y_i-(w^Tx_i+b)<\epsilon+\xi_i \\ &(w^Tx_i+b)-y_i<\epsilon+\xi^*_i \\ &\xi_i,\xi^*_i\geq 0 \\ \end{aligned} \right. min 21?�O�Ow�O�O2+Ci=1��l?(��i?+��i??)s.t. ???????yi??(wTxi?+b)<?+��i?(wTxi?+b)?yi?<?+��i??��i?,��i??��0?
�ⲿ����Ҫ��svr�������Լ�Ŀ�꺯�����Ƴ�����������ο������顣
https://blog.csdn.net/Mbx8X9u/article/details/78153868
RVM
SVM��code
�����
ǰ��֪ʶ��https://blog.csdn.net/L_15156024189/article/details/85182766��https://blog.csdn.net/the_lastest/article/details/78461566��https://en.wikipedia.org/wiki/Slater%27s_condition,https://en.wikipedia.org/wiki/Karush%E2%80%93Kuhn%E2%80%93Tucker_conditions��https://zhuanlan.zhihu.com/p/36621652
SVM:https://blog.csdn.net/macyang/article/details/38782399,https://www.cnblogs.com/wangyanphp/p/5498858.html,https://blog.csdn.net/m0_37687753/article/details/80964487,
https://blog.csdn.net/u014433413/article/details/78427574��https://blog.csdn.net/v_july_v/article/details/7624837��https://blog.csdn.net/weixin_44264662/article/details/97952385
SMO:https://blog.csdn.net/ACM_hades/article/details/90701030,https://www.cnblogs.com/pinard/p/6111471.html,https://www.bilibili.com/video/av70839977?p=31,https://zh.wikipedia.org/wiki/%E5%BA%8F%E5%88%97%E6%9C%80%E5%B0%8F%E4%BC%98%E5%8C%96%E7%AE%97%E6%B3%95,
http://cs229.stanford.edu/notes2019fall/cs229-notes3.pdf
SVR:https://blog.csdn.net/promisejia/article/details/81477439?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task,https://blog.csdn.net/qq_25037903/article/details/84789736?depth_1-utm_source=distribute.pc_relevant.none-task&utm_source=distribute.pc_relevant.none-task