文献阅读:A Survey on Transfer Learning(2009)
2018-12
文章的作者是Sinno Jialin pan 与 Qiang Yang
关键词:迁移学习(transfer learning);Survey,ML,Data Mining
1.介绍
- 背景:机器学习和数据挖掘已经取得了很大的成功
- 现有缺陷:众多机器学习模型有一个基本的假设:训练集和测试集是来源于同分布的同样的特征空间。
- 需要迁移学习应用的例子:
:(1).网络文件分类:我们有一个大学网站,每个网页都属于某种类型之一,并且我们已经有了一些人工标记了的网页,由此我们可以训练得到一个用于网页分类的模型。但是对于一个新的针对另一个网站的分类问题,也许我们没有足够的带标签的数据来训练模型,此时,如果能做到将原来网站的分类知识迁移到新的网站中是十分有用的。
:(2).数据容易过时的情况,此时,我们不能假设各个时间获取的数据是同分布的。具体的一个例子是:室内WIFI定位问题,目的是基于前期收集的wifi数据监测用户的位置。首先,对数据的标记代价很大:一个标记的数据代表着要在整个区域测量wifi数据信号。其次,模型是变化的:wifi信号强度各个时间不同,不同的wifi发射器信号不同等等。因此我们希望,为了节约重新测量的代价,能将得到的定位模型应用到新的时间上,或者应用到新的wifi设备上。
:(3).情感分类问题:我们希望能对产品的评价进行情感分类,如分为积极地和消极的。由于不同产品之间的评价数据分布是不同的,因此为了维持好的分类效果,我们需要对每种产品收集大量的带标签数据来进行训练。这里,在不同产品之间模型的迁移能让我们免于获取大量的带标签数据。
本文主要综述迁移学习在有关数据挖掘的分类,回归,聚类上的内容,事实上,现在有很多关于强化学习中的迁移学习的工作。
总览
2.1 迁移学习的历史简述
- 传统机器学习算法:使用通过带标签或者不带标签的数据训练得到的统计模型来进行预测。半监督分类通过使用大量的无标签和少量带标签数据,解决了带标签数据少而不能构建一个好的分类器的问题。人们对有缺陷数据集上的监督和半监督学习的差别进行了分析,但是大部分研究都假设有标签数据和无标签数据来自同分布。
- 迁移学习,相反地,允许用于训练和测试的域,任务以及分布不同。迁移学习的研究源于人类能自觉地将以往的知识用以解决新问题的现象。
- 自从1995年,迁移学习有很多不同的称呼并且越来越受重视:learning to learn,life-long learning,knowledge transfer…。其中的多任务学习框架与现在的迁移学习最接近:同时学习多个任务即使他们是不同的。完成这个目的的典型方式是,寻找出各任务的共同特征。
- 2005年,BAA 给与了迁移学习新的定义:迁移学习目的是为了从源任务中抽取知识来应用到目标任务中。和多任务学习不同,迁移学习更看重目标任务,从此目标任务和源任务的地位不再对等。
- 如今,迁移学习已经出现在各大数据挖掘以及机器学习顶级期刊中。
记号和定义
符号
- domainD^:domain\ \ \hat{D}:domain D^:D^={χ,P}\hat{D}=\{\chi,P\}D^={
χ,P}
其中 χ\chiχ 为特征空间;
P(X)P(X)P(X)为边际密度分布 P(X),X={x1,? ,xn}∈χP(X),X=\{x_1,\cdots,x_n\}\in \chiP(X),X={ x1?,?,xn?}∈χ - taskτtask\ \ \tautask τ: τ={γ,f}\tau=\{\gamma,f\}τ={
γ,f}
其中γ\gammaγ为标签空间;
f()f()f()为客观预测函数(Objective predictive function),概率角度上,f(x)f(x)f(x)可以写为P(y∣x)P(y|x)P(y∣x)。需要从已有数据中学习,可用于预测。 - 约定:本文中为了简洁,只考虑一个源域D^S\hat{D}_SD^S?和一个目标域D^T\hat{D}_TD^T?
源域D^S\hat{D}_SD^S?的数据DS={(xS1,yS1),? ,(xSnS,ySnS)}?χS?γSD_S=\{(x_{S_1},y_{S_1}),\cdots,(x_{S_{n_S}},y_{S_{n_S}})\}\subset\chi_S *\gamma_SDS?={ (xS1??,yS1??),?,(xSnS???,ySnS???)}?χS??γS?
目标域D^T\hat{D}_TD^T?数据DT={(xT1,yT1),? ,(xTnT,yTnT)}?χT?γTD_T=\{(x_{T_1},y_{T_1}),\cdots,(x_{T_{n_T}},y_{T_{n_T}})\}\subset\chi_T *\gamma_TDT?={ (xT1??,yT1??),?,(xTnT???,yTnT???)}?χT??γT?
一般地,0≤nT?nS0\leq n_T \ll n_S0≤nT??nS?
定义
- 迁移学习:
给定一个源域D^S\hat{D}_SD^S?和学习任务τS\tau_SτS?,
一个目标域D^T\hat{D}_TD^T?和学习任务τT\tau_TτT?
迁移学习的目的是:
用源域D^S\hat{D}_SD^S?和τS\tau_SτS?的知识来提高在D^T\hat{D}_TD^T?中的目标预测函数fT()f_T()fT?()的表现
其中D^S≠D^T\hat{D}_S \neq\hat{D}_TD^S???=D^T?或者τS≠τT\tau_S\neq\tau_TτS???=τT? - 当两个域的特征空间之间存在关系时,称两个域是相关的(related)
2.3 迁移学习技术的分类
- 在迁移学习中有三个主要问题:
(1)迁移什么?:知识的哪部分可以在域或者任务之间迁移?
(2)怎么迁移?
(3)什么时候迁移?:什么情况下需要迁移?什么情况不应当迁移?(迁移之后反而不好,负迁移,如何避免负迁移很重要) - 迁移学习的分类(基于任务和域的情况)
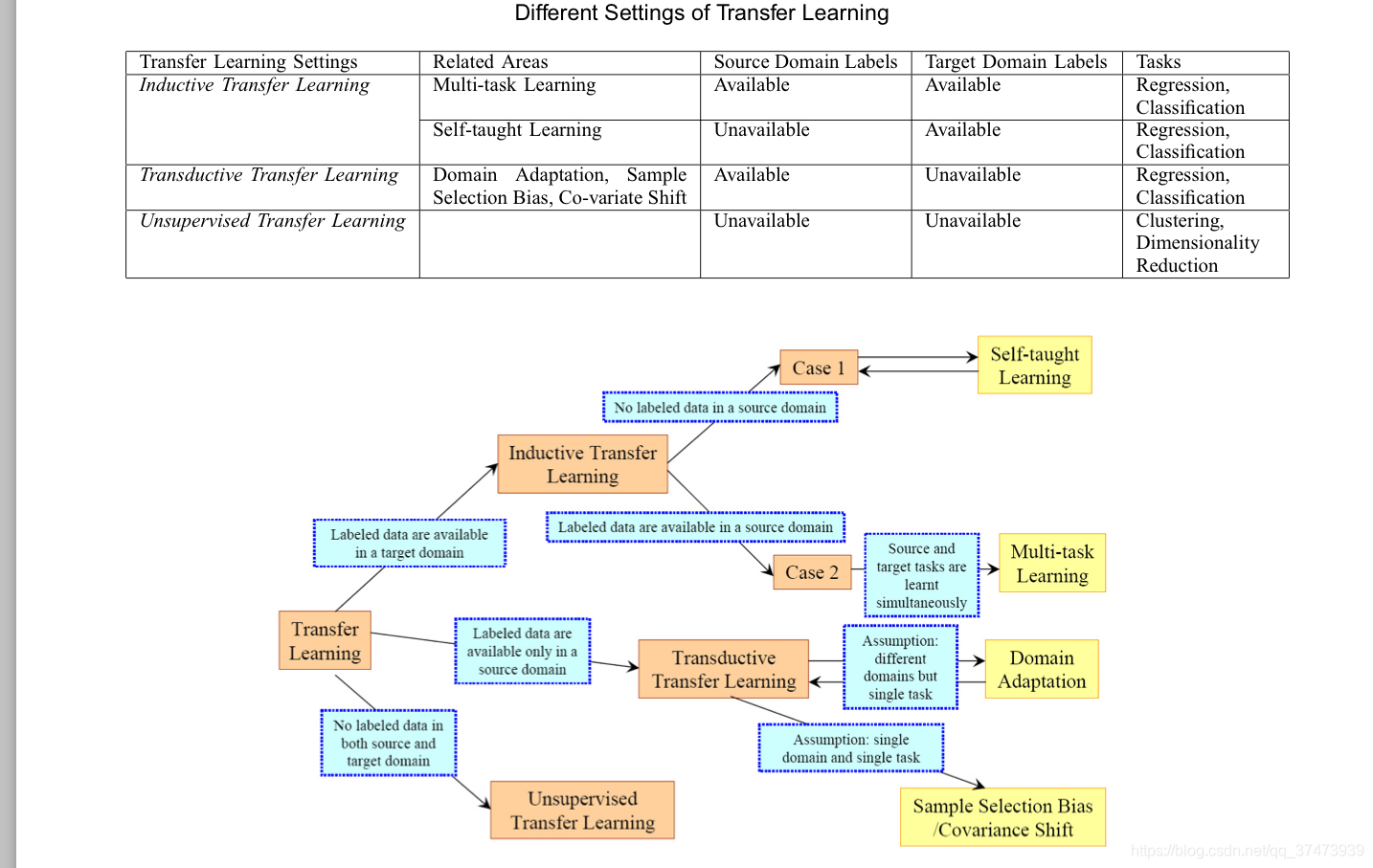
学习方式 | 源和目标域|源和目标任务
-------- | —|---
传统机器学习|相同|相同
迁移学习:1.归纳(Inductive)迁移学习|无要求|不同但是相关(related)
迁移学习:2.无监督迁移学习|无要求|不同但是相关(related)
迁移学习:3.直推(Transductive)迁移学习|不同但是相关(related)|相同
3.归纳迁移学习
- 归纳迁移学习的定义
归纳迁移学习(Inductive transfer learning):
给定一个源域D^S\hat{D}_SD^S?和学习任务τS\tau_SτS?,
一个目标域D^T\hat{D}_TD^T?和学习任务τT\tau_TτT?
归纳迁移学习目的是
用源域D^S\hat{D}_SD^S?和τS\tau_SτS?的知识来提高在D^T\hat{D}_TD^T?中的目标预测函数fT()f_T()fT?()的表现
其中τS≠τT\tau_S\neq\tau_TτS???=τT?
归纳迁移学习又可以分为两种情况:
(1):源域中有带标签数据
(2):源域中没有带标签数据,仅有无标签数据
多数迁移学习方法专注于第一种情况。
3.1 迁移实例知识
如果源域中的数据不能直接使用,我们可以使用部分源域中的数据和目标域中带标签数据来提高模型效果。
算法实例(文章中共写出了四个例子):
TrAdaBoost 算法:
论文
1.是AdaBoost算法的扩展。
2.假设:源域和目标域特征和标签相同,但是数据分布不同
3.算法认为:由于数据分布不同,部分数据有助于目标域的学习而其他有反作用
4.算法思路:通过迭代使得源域中好的数据权重上升,坏的数据权重下降,模型仅评价于目标数据。
5.计算机实验:三个文本数据集和一个非文本数据集上对比SVM,SVMt和TrAdaBoost(SVM)算法的表现:发现当同分布数据量/非同分布数据量<0.05时,TrAdaBoost表现出了明显的优势。当同分布数据较多时,学习效果近似于一半地监督学习(这里是SVM)
Jiang and Zhai提出的启发性方法
论文
思路:根据条件分布P(yT∣xT)P(y_T|x_T)P(yT?∣xT?)和P(yS∣xS)P(y_S|x_S)P(yS?∣xS?)之间的不同,除去有"误导性"的源域数据
3.2 迁移特征表示知识
归纳迁移学习中的特征表示迁移方法目的是找出“好”的特征表示去减小域的divergence和分类、回归模型的误差。
不同的源域数据类型对应不同的寻找“好”特征表示的方法:
(1)源域有大量带标签数据:监督学习模型
(2)源域无带标签数据:非监督学习模型
3.2.1 监督特征构建
和多任务学习类似,基本思路是:学习低维度的相关任务之间的表示。