�����ֻ�����˵��ֻ�ô�iΪ���Ŀ�ʼö�٣��������i,����p[i]�����ij��ȣ����䵽�Գ�λ�ã�Ȼ���ٿ�ʼ�������ݡ�
_(:�١���)_���������Ļ������������Ľ̴̳�Ŷ������˵���Ͻ���������࣬���Ծ�˵һ��Manacher Algorithm������Ҫ��˼��ɡ���
Ϊ�˷���ش����桢ż���Ĵ��б����������������Ƚ�ԭ���������ַ�֮������һ��ԭ���в������ֵ��ַ������Ǽٶ�Ϊ��#������
Ʃ��˵��abaaba����������ͱ���� #a#b#a#a#b#a��
��������#Ϊ���ĵĻ��Ĵ�����ԭ���о���ż���Ĵ���
Ȼ�������ٹ涨���������뼸������������:
����Ma[i]�����������ˡ�#������ַ�����
����Mp[i]���������ַ�����iλΪ���ĵĻ��Ĵ�����ȡ�
����Mx ��������ǰ���Ѿ�ƥ����ϵĽ�β��Զ�Ļ��Ĵ���������Ma[]����ĵ�Mxλ��
����ID ��������ǰ���Ѿ�ƥ����ϵĽ�β��Զ�Ļ��Ĵ�������ΪMa[]����ĵ�IDΪ��
���ѷ��֣�p[i]-1���Ǹû��Ĵ��ij��ȡ���
�ڴˡ�������һ��
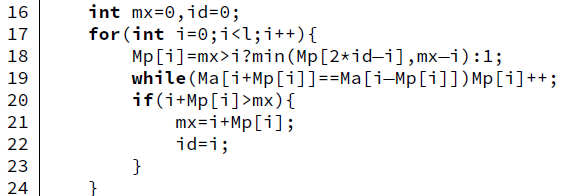 �����������
�����������
16�оͲ���˵����
��17�У�ѭ������i�����˵�ǰ�����ж�Ma���ĵ�iλΪ���ĵĻ����Ӵ�����ȡ�
��ʮ���У��������㷨����ĵIJ��֣�Ҳ��O(n)ʱ�临�Ӷȵı��ϡ�
���ǿ��ǵ������統ǰ��i�Ѿ����������������жϹ��Ļ��Ĵ��ڣ���Mx>i)����ô����������Ĵ������Ӧ���Ǹ��ַ�Ma[2*ID-i]��Ӧ���Ѿ������������Ϊ���ĵĻ��Ĵ������ж�ˡ�
��ô�������Ե�iλΪ���ĵĻ��Ĵ����ȣ������˵�һ������Mp[2*ID-i]��
���ǣ����ǿ��ǵ�����Ma[2*ID-i]Ϊ���ĵĻ��Ĵ�����������չ������Ma[ID]Ϊ���ĵĻ��Ĵ�֮�⡣���������ǾͲ��ܱ�֤��Ma[i]Ϊ���ĵĻ��Ĵ���������Ma[ID]Ϊ���ĵĻ��Ĵ�֮��IJ��֡�
�������ŵõ��˵ڶ�������Mx-i
���ϣ���Mx>iʱ�����Ǿ͵õ���Mp[i]=min(Mp[2*id-i],mx-i);
��19�У����ǵ���18������ֻ�õ���һ�����������ޣ�����
����Ҫ��������Ļ����ϼ���������չ��
�����������������������ƥ����ô��֤���ӶȻ���O(n)�أ���( �� �� ��|||)����
������һ�����㷨���Ӷȷ��������ǿ��Է�Ϊ���������
���ǵ�ǰ��һλi���ڵ�18�е�λ����ִ�еIJ���
��Mp[i]=1��˵��Mxû�и��dz���i����ôMx�Ă�����һ��ִ�к�һ�������ӡ�
��Mp[i]=Mx-i��˵����Ma[i]Ϊ���ĵĻ��Ĵ����ٵ�����Mx����ôMx�Ă�����֮����١�
��Mp[i]=Mp[ID*2-i]��˵��������Ma[i]ֻ����ô���Ѿ�ƥ�䲻��ȥ�ˡ���T_T
���ǵ���Mx�Ă��ǵ����ģ�����ʼ�ղ��ᳬ���ַ�������Len����ô�������е�i���١����������ִ��ʱ���ܺͲ��ᳬ��Len�������ʱ�临�Ӷ�������O(n)��