ЮФЯзЗвы3ЃКFCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
- FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
-
- Abstract
- Introduction
- Related Works
-
- Anchor-base methods
- Anchor-free methods
- FCOSR
-
- Network outputs
- Ellipse center sampling
- Fuzzy sample label assignment
- Multi-level sampling
- Target loss
- Experiments
-
- Datasets
- Implement Details
- Ablation Studies
- More Backbones
- Speed VS Accuracy
FCOSR: A Simple Anchor-free Rotated Detector for Aerial Object Detection
Zhonghua Li, Biao Hou, Zitong Wu, Licheng Jiao, Bo Ren, Chen Yang
Abstract
Anchor-basedРрЫуЗЈдкoriented object detectionжавбШЁЕУСЫОЊШЫаЇЙћЃЌЕЋЪЧШдШЛвЊЪжЖЏЩшжУдЄЩшЕФanchorЃЌвђДЫШдШЛЛсв§ШыЖюЭтЕФГЌВЮЪ§КЭМЦЫуСПЁЃЖјЯжгаЕФanchor-freeЫуЗЈЭЈГЃКмИДдгЧвФбвдВПЪ№ЁЃБОЮФжМдкЬсГівЛжжМђЕЅЧввзгкВПЪ№ЕФвЃИаЭМЯёМьВтЫуЗЈЁЃБОЮФзїепЬсГіСЫвЛжжЛљгкFCOSЕФone-stageЕФanchor-freeЫуЗЈFCOSRЁЃFCOSRЪЧМђЕЅЕФШЋОэЛ§НсЙЙЁЃБОЮФЕФжиЕуЙЄзїдкгкбЕСЗНзЖЮЕФБъЧЉЗжХфВпТдЁЃБОЮФжаЪЙгУСЫвЛжжЭждВжааФВЩбљЗНЗЈЮЊOBBЖЈвхвЛИіКЯЪЪЕФе§бљБОЧјгђЁЃеыЖдФПБъжиЕўЮЪЬтдђЬсГіСЫвЛжжФЃК§бљБОЗжХфВпТдЁЃеыЖдВЩбљВЛзуЮЪЬтдђЩшМЦСЫвЛжжЖрМЖВЩбљФЃПщЁЃНсКЯЩЯЪіЕФШ§жжЗНАИЮЊбЕСЗЗжХфИќКЯЪЪЕФбљБОЁЃ
DOTA1.0: 79.25% mAP
DOTA1.5: 75.41% mAP
HRSC2016: 90.15% mAP
Introduction
гЩгкHBBЫуЗЈдквЃИаЭМЯёжаУцСйШЮвтНЧЖШЁЂУмМЏХХСаКЭЗжБ№ТЪВювьЕШЮЪЬтЃЌЕБЧАвбОзЊЛЛЮЊOBBРраЭЕФвЃИаЭМЯёФПБъМьВтЫуЗЈЁЃ
ФПЧАЕФOBBЫуЗЈЛљБОЖМЪЧДгHBBЫуЗЈИФНјЖјРДЃЌжївЊПЩвдЗжЮЊanchor-basedКЭanchor-freeСНРрЁЃAnchor-basedРрЫуЗЈашвЊдЄЩшanchorЃЌвђДЫЛсв§ШыЖюЭтЕФГЌВЮЪ§КЭМЦЫуСПЃЌЖјЧввВЛсЖдЫуЗЈадФмВњЩњгАЯьЁЃЖјanchor-freeРрЫуЗЈВЛЛсв§ШыГЌВЮЪ§КЭЖюЭтМЦЫуСПЃЌвђДЫИќОпЪЪгІадЁЃвђДЫБОЮФЛљгкFCOSКЭЖўЮЌИпЫЙЗжВМЬсГіСЫFCOSRЁЃFCOSRжБНгдЄВтФПБъЕФжааФЕуЁЂПэЁЂИпвдМАа§зЊНЧЖШЁЃ
БОЮФОлНЙгкбЕСЗНзЖЮЁЃЪмвцгкжиаТЩшМЦЕФБъЧЉЗжХфВпТдЃЌFCOSRПЩвддкЖдFCOSНјааКмЩйЕФаоИФЯТжБНгЕиЁЂзМШЗЕидЄВтOBBЁЃгыОЋжТЕФtwo-stageЗНЗЈЯрБШЃЌFCOSRВЛНіИќМђЕЅЖјЧвИќвзгкВПЪ№ЃЈвђЮЊжЛгаОэЛ§ВуЃЉЁЃБОЮФНјааСЫвЛЯЕСаЪЕбщбщжЄЫуЗЈЕФгааЇадЁЃ
змНсРДЫЕЃЌБОЮФЕФЙБЯздкгкЃК
- ЬсГіСЫвЛжжone-stageЕФanchor-freeЕФвЃИаЭМЯёФПБъМьВтЫуЗЈЃЌЦфМђЕЅЧввзгкВПЪ№ЁЃ
- ЛљгкЖўЮЌИпЫЙЗжВМКЭвЃИаЭМЯёЕФЬиадЃЌЩшМЦСЫвЛЬзБъЧЉЗжХфВпТдЃЌЮЊбЕСЗбљБОЗжХфИќКЯЪЪЕФФПБъЁЃ
- дкDOTA1.0ЁЂDOTA1.5КЭHRSC2016Ъ§ОнМЏЩЯЗжБ№ДяЕНСЫИпадФмЁЃгыЦфЫћЕФanchor-freeЫуЗЈЯрБШЃЌFCOSRДяЕНСЫSOTAЃЌЫѕаЁСЫгыanchor-basedЫуЗЈЕФВюОрЁЃFCOSRдкЫйЖШКЭОЋЖШЩЯБэЯжГіЩЋЃЌГЌдНСЫФПЧАЕФжїСїЫуЗЈЁЃ
- НЋвЛИіЧсСПЕФFCOSRФЃаЭзЊЛЛЕНTensorRTИёЪНЃЌВЂГЩЙІЧЈвЦЕНJetson Xavier NXЩЯЃЌдкDOTA1.0ЩЯДяЕНСЫ73.93% mAPЁЃ
Related Works
ЕБЧАЕФжїСїOODЫуЗЈПЩвдЗжЮЊСНИіжївЊЕФРраЭЃКanchor-freeКЭanchor-basedЁЃгаВЮПМЮФЯз
Anchor-base methods
Anchor-baseЗНЗЈашвЊЪжЖЏдЄЩшвЛЯЕСаanchorНјааБпНчЛиЙщКЭЯИЛЏЁЃдчЦкЕФЗНЗЈЪЙгУОпгаЖрИіНЧЖШКЭЖрИізнКсБШЕФУЊЕуРДМьВтЖЈЯђЖдЯѓЁЃЕЋЪЧЃЌдЄЩшНЧЖШЕФдіМгЕМжТanchorsКЭМЦЫуСПЕФПьЫйдіМгЃЌЪЙЕУФЃаЭФбвдбЕСЗЁЃзїЮЊtwo-stageЗНЗЈЃЌRoI TransformerЭЈЙ§RRoI learnerФЃПщНЋhorizontal proposalзЊЛЛЮЊoriented proposalsЃЌШЛКѓЬсШЁoriented proposalsжаЕФЬиеїЃЌгУгкКѓајЕФЗжРрКЭЛиЙщЁЃетжжЗНЗЈЭЈЙ§ЭјТчИјГіНЧЖШжЕРДДњЬцдЄЩшЕФНЧЖШЃЌДѓДѓМѕЩйСЫanchorЪ§СПКЭМЦЫуСПЁЃГЄЦквдРДЃЌГіЯжСЫаэЖрЛљгкRoI-transformerЕФЗНЗЈВЂШЁЕУСЫСМКУЕФаЇЙћЁЃ ReDetдкећИіФЃаЭжав§ШыСЫа§зЊВЛБфОэЛ§(E2CNN)ЃЌВЂЭЈЙ§ЪЙгУ RiRoI ЖдЦыРДЬсШЁа§зЊВЛБфЬиеїЁЃ Oriented R-CNN гУИќЧсСПЁЂИќМђЕЅЕФorientation RPNЬцЛЛСЫ RoI-transformerжаЕФ RRoI learnerФЃПщЁЃ R3DetЪЧвЛжжИФНјЕФЕЅНзЖЮУцЯђЖдЯѓМьВтЗНЗЈЃЌЭЈЙ§ЬиеїДДаТФЃПщ(Feature Refinement Module, FRM)ЮЂЕїHBBИёЪНЕФanchorЕУЕНOBBНсЙћЁЃ S2ANetгЩЬиеїЖдЦыФЃПщ(Feature Alignment Module, FAM)КЭЖЈЯђМьВтФЃПщ(Oriented Detection Module, ODM)зщГЩЃЌЦфжа FAMгУгк ЩњГЩИпжЪСПЕФoriented anchorЃЌODMВЩгУТЫВЈЦїЩњГЩЗНЯђУєИаКЭЗНЯђВЛБфЕФЬиеїЃЌвдЛКНтЗжРрЗжЪ§КЭЛиЙщОЋЖШМфЕФВЛвЛжТадЁЃCSLНЋЛиЙщЮЪЬтзЊЛЏЮЊЗжРрЮЪЬтвдНтОіНЧЖШЕФВЛСЌајадЁЃDCLдкCSLЕФЛљДЁЩЯВЩгУУмМЏБрТыРДгХЛЏбЕСЗЫйЖШЃЌВЂЧвВЩгУНЧЖШОрРыКЭзнКсБШУєИаМгШЈ(Angle Distance and Aspect Radio Sensitive Weighting, ADARSW)РДЬсИпОЋЖШЁЃ
Anchor-free methods
ФПЧАanchor-freeЫуЗЈвЛАуЖМЪЧone-stageЕФЁЃIENetВЩгУСЫвЛИіОпгазгзЂвтСІЛњжЦЕФЗжжЇНЛЛЅФЃПщЃЌгУгкШкКЯЗжРрЗжжЇКЭЛиЙщЗжжЇЕФЬиеїЁЃAnchor-freeЫуЗЈжБНгдЄВтФПБъЕФbounding boxЃЌетЪЙЕУЛиЙщШЮЮёЕФlossЩшМЦОпгавЛЖЈЕФОжЯоадЁЃGWDЁЂKLDКЭProbIoUЪЙгУСНИіИпЫЙЗжВМжЎМфЕФОрРыЖШСПРДБэЪОlossЃЌЮЊanchor-freeЗНЗЈЬсЙЉСЫвЛжжаТЕФlossЗНАИЁЃPIoUЛљгкЯёЫиЭГМЦЮЊOBBЩшМЦСЫвЛИіIoU lossЁЃBBAVectorsКЭPolarDetЗжБ№гУbbavЪИСПКЭМЋзјБъЖЈвхOBBЁЃCenterRotгУDCNРДШкКЯЖрГпЖШЬиеїЁЃAROAРћгУзЂвтСІЛњжЦдкone-stageЕФanchor-basedЭјТчжагУЬсИпадФмЁЃ
FCOSR
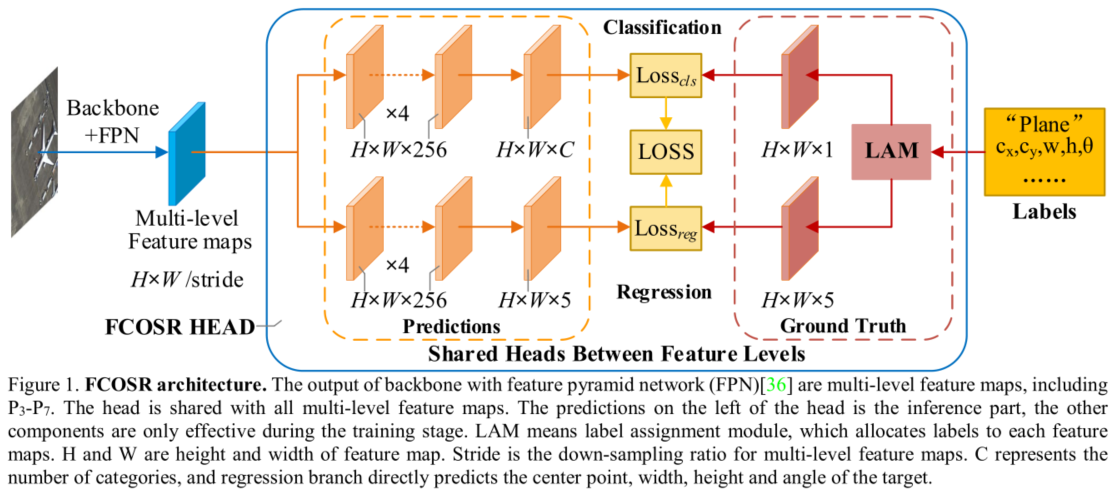
ШчЩЯЭМЫљЪОЃЌFCOSRвдFCOSЮЊЛљДЁЁЃЭјТчжБНгдЄВтжааФЕуЁЂГЄЁЂПэКЭа§зЊНЧЖШЃЈOpenCVИёЪНЕФНЧЖШЃЉЁЃЫуЗЈЭЈЙ§БъЧЉЗжХфФЃПщ(Label Alignment Module, LAM)ШЗЖЈЬиеїЭМЕФЪеСВФПБъЁЃFCOSRВЛЛсдкFCOSПђМмжав§ШыЖюЭтЕФзщМўЃЌВЂЧвЩОГ§СЫcenternessЗжжЇЃЌЪЙЕУЭјТчВПЪ№ИќМђЕЅШнвзЁЃБОЮФЕФЙЄзїжаЕуЪЧбЕСЗНзЖЮЕФБъЧЉЗжХфЁЃ
Network outputs
ЭјТчЪфГіАќКЌСЫвЛИіCCCЮЌЕФЗжРрЗжжЇЯђСПКЭвЛИі5ЮЌЕФЛиЙщЗжжЇЯђСПЁЃгыFCOSВЛЭЌЃЌзїепЯЃЭћЛиЙщЕФУПИізщМўЕФЪфГігаВЛЭЌЕФЗЖЮЇЃЈПЩФмвтЫМЪЧУПИіЬиеїВуЕФЛиЙщЗжжЇгаВЛЭЌЕФЗЖЮЇЃЉЁЃOffsetПЩвдЮЊИКЃЌГЄКЭПэБиаыЮЊе§ЃЌЧвНЧЖШangleЁЪ[0,90]angle\in{[0,90]}angleЁЪ[0,90]ЁЃетИіМђЕЅЕФЙ§ГЬгЩЯТЪНЖЈвхЃК
offsetxy=Regxy?k?swh=(Elu(Regwh?k)+1)?sІШ=Mod(RegІШ,Іа/2)offset_{xy}=Reg_{xy}\cdot{k}\cdot{s} \\ wh=({\rm{Elu}}(Reg_{wh}\cdot{k})+1)\cdot{s} \\ \theta={\rm{Mod}}(Reg_{\theta},\pi/2) offsetxy?=Regxy??k?swh=(Elu(Regwh??k)+1)?sІШ=Mod(RegІШ?,Іа/2)
ЦфжаRegxyReg_{xy}Regxy?ЃЌRegwhReg_{wh}Regwh?КЭRegІШReg_{\theta}RegІШ?ЗжБ№БэЪОЛиЙщЗжжЇзюКѓвЛВуЕФжБНгЪфГіЃЌkkkЪЧПЩбЇЯАЕФЕїећвђзгЃЌsssЪЧЖрВуЬиеїЕФЯТВЩбљВНГЄЁЃElu\rm{Elu}EluЪЧReLuReLuReLuЕФИФНјЁЃ
ЭЈЙ§ЩЯЪНЕФМЦЫуЃЌЭјТчЕФЪфГіБЛзЊЛЛЮЊвЛИі5ЮЌЕФЯђСП(offsetx,offsety,w,h,angle)(offset_{x},offset_{y},w,h,angle)(offsetx?,offsety?,w,h,angle)ЁЃВЩбљЕуЕФзјБъМгЩЯзјБъЦЋвЦСПОЭЕУЕНСЫOBBЕФзјБъЁЃ
Ellipse center sampling
жааФВЩбљжИЕФЪЧНЋВЩбљЕуМЏжадкФПБъжааФИННќЃЌгажњгкМѕЩйЕЭжЪСПМьВтВЂЬсИпФЃаЭадФмЁЃетжжВпТддкFCOSЁЂYOLOXКЭвЛаЉЦфЫћЭјТчжаБЛВЩгУЃЌЮШЖЈЕиЬсИпСЫОЋЖШЁЃЕЋЪЧШчЙћжБНгНЋhorizontalжааФВЩбљЧЈвЦЕНODDжаЛсГіЯжСНИіЮЪЬтЃКЕквЛЃЌhorizontalжааФВЩбљвЛАуЪЧвЛИі5ЁС55\times{5}5ЁС5Лђ3ЁС33\times{3}3ЁС3ЕФЗНаЮЧјгђЃЌвђДЫНЧЖШЛсгАЯьВЩбљЧјгђЕФаЮзДЃЛЕкЖўЃЌЖЬБпНјвЛВНМѕЩйСЫДѓзнКсБШЕФФПБъЕФжааФВЩбљЕуЪ§СПЁЃзюжБЙлЕФжааФВЩбљгІИУЪЧФПБъжааФвЛЖЈЗЖЮЇФкЕФдВаЮЧјгђЃЌЕЋЪЧЖЬБпЯожЦСЫжааФВЩбљЕФЗЖЮЇЁЃЮЊСЫМѕЩйетаЉИКУцгАЯьЃЌБОЮФЬсГіСЫвЛжжЛљгкЖўЮЌИпЫЙЗжВМЕФЭждВжааФВЩбљ(Elliptical Center Sampling, ECS)ВпТдЁЃБОЮФгУOBBЕФЮхИіВЮЪ§(cx,cy,w,h,ІШ)(cx,cy,w,h,\theta)(cx,cy,w,h,ІШ)РДЖЈвхвЛИіЖўЮЌИпЫЙЗжВМЃК
ІВ=RІШ?ІВ0?RІШTІЬ=(cx,cy)RІШ=[cosІШ?sinІШsinІШcosІШ]ІВ0=112[w200h2]\begin{aligned} \Sigma &=& R_{\theta}\cdot{\Sigma_{0}\cdot{R_{\theta}^T}} \\ \mu &=& (cx,cy) \\ R_{\theta} &=& \begin{bmatrix} {\rm{cos}\theta} & -{\rm{sin}\theta} \\ {\rm{sin}\theta} & {\rm{cos}\theta} \end{bmatrix} \\ \Sigma_{0} &=& \frac{1}{12}\begin{bmatrix} w^2 & 0 \\ 0 & h^2 \end{bmatrix} \end{aligned} ІВІЬRІШ?ІВ0??====?RІШ??ІВ0??RІШT?(cx,cy)[cosІШsinІШ??sinІШcosІШ?]121?[w20?0h2?]?
ЦфжаІВ\SigmaІВЪЧаЗНВюОиеѓЃЌІВ0\Sigma_0ІВ0?ЪЧНЧЖШЮЊ0ЪБЕФаЗНВюОиеѓЃЌІЬ\muІЬЪЧОљжЕЃЌR0R_0R0?ЪЧа§зЊБфЛЛОиеѓЁЃЖўЮЌИпЫЙЗжВМЕФИХТЪУмЖШКЏЪ§ЕФТжРЊЪЧЭждВЧњЯпЁЃЯТЪНЪЧвЛАуЧщПіЯТЕФИХТЪУмЖШКЏЪ§ЃК
f(X)=12ІаЈOІВЈO1/2exp(?12(X?ІЬ)TІВ?1(X?ІЬ))f(X)=\frac{1}{2\pi|\Sigma|^{1/2}}{\rm{exp}}(-\frac{1}{2}(X-\mu)^T\Sigma^{-1}(X-\mu)) f(X)=2ІаЈOІВЈO1/21?exp(?21?(X?ІЬ)TІВ?1(X?ІЬ))
ЦфжаXXXЪЧЖўЮЌзјБъЯђСПЃЌБОЮФШЅЕєСЫЙцдђЛЏЯюЕУЕНСЫg(X)g(X)g(X)ЃК
g(X)=exp(?12(X?ІЬ)TІВ?1(X?ІЬ))g(X)={\rm{exp}}(-\frac{1}{2}(X-\mu)^T\Sigma^{-1}(X-\mu)) g(X)=exp(?21?(X?ІЬ)TІВ?1(X?ІЬ))
g(X)ЁЪ(0,1])g(X)\in{(0,1])}g(X)ЁЪ(0,1])ЖўЮЌИпЫЙЗжВМЕФЭждВТжРЊПЩвдБэЪОЮЊg(X)=Cg(X)=Cg(X)=CЁЃЕБC=C0=exp(?1.5)C=C_0={\rm{exp}}(-1.5)C=C0?=exp(?1.5)ЪБЃЌЭждВТжРЊИеКУФкНггкOBBЁЃЭждВТжРЊЕФЗЖЮЇЫцзХCCCЕФМѕаЁЖјРЉДѓЃЌвђДЫCЁЪ[C0,1]C\in[C_0,1]CЁЪ[C0?,1]ЁЃПМТЧЕНвЃИаЭМЯёжаЕФФПБъЭљЭљНЯаЁЃЌБОЮФШЁC=0.23C=0.23C=0.23вдБмУтВЩбљУцЛ§Й§аЁЕМжТВЩбљВЛзуЁЃФПБъЕФжааФВЩбљЧјгђгЩg(X)ЁнCg(X)\ge{C}g(X)ЁнCШЗЖЈЃЌШєg(X)>Cg(X)>Cg(X)>CдђЫЕУїXXXдкВЩбљЧјгђФкЁЃгЩгкзнКсБШДѓЕФФПБъЪЎЗжЯИГЄЃЌЪЙЕУГЄжсЗНЯђЕФВПЗждЖРыжааФЧјгђЁЃЮЊНтОіетвЛЮЪЬтЃЌзїепЭЈЙ§аоИУИпЫЙЗжВМРДЫѕаЁВЩбљЧјгђЁЃЯТЪНЖЈвхСЫаТЕФаЗНВюОиеѓЃК
ІВ0=min(w,h)12[w00h]\Sigma_0=\frac{
{\rm{min}}(w,h)}{12}\begin{bmatrix} w & 0 \\ 0 & h \end{bmatrix} ІВ0?=12min(w,h)?[w0?0h?]

ЭЈЙ§аоИФаЗНВюОиеѓЃЌЭждВЕФГЄжсБфЮЊwh\sqrt{wh}wh?ЃЌЖјЖЬжсБЃГжВЛБфЁЃЩЯЭМеЙЪОСЫOBBЕФЭждВжааФВЩбљЧјгђЁЃгыЫЎЦНжааФВЩбљЯрБШЃЌЭждВжааФВЩбљИќЪЪКЯOBBЃЌВЂЧвЭЈЙ§ЫѕаЁГЄжсМЏжаСЫДѓзнКсБШЕФФПБъЕФВЩбљЧјгђЁЃ
Fuzzy sample label assignment
FCOSЭЈЙ§НЋВЛЭЌГпДчЕФФПБъЗжХфИјВЛЭЌВНГЄЕФЬиеїЭМРДМѕЩйЖўвхадбљБОЁЃЖдгкГпЖШЯрЫЦЕФФПБъЃЌFCOSНЋНЯаЁЕФФПБъБъЧЉЗжХфИјВЛУїШЗЕФВЩбљЕуЁЃЯдШЛЃЌетжжЛљгкзюаЁУцЛ§ддђЕФФЃК§бљБОЗжХфЗНЗЈФбвдДІРэИДдгЕФГЁОАЁЃБОЮФЩшМЦСЫвЛжжЛљгкЖўЮЌИпЫЙЗжВМЕФбљБОБъЧЉЗжХфЗНЗЈ(Fuzzy sample Label Assignment, FLA)РДЗжХфФЃК§БъЧЉЁЃИпЫЙЗжВМГЪжгаЮЃЌППНќжааФЮЛжУЕФЯргІИќИпЁЃЫцзХВЩбљЕудЖРыжааФЃЌЦфЯьгІжЕж№НЅБфаЁЁЃБОЮФЭЈЙ§НќЫЦЕиНЋЖўЮЌИпЫЙЗжВМзїЮЊВЩбљЕугыФПБъжааФжЎМфЕФОрРыЖШСПЁЃжааФОрРыJ(X)J(X)J(X)гЩЯТЪНИјГіЃК
J(X)=wh?f(X)J(X)=\sqrt{wh}\cdot{f(X)} J(X)=wh??f(X)
Цфжаf(X)f(X)f(X)ЖўЮЌИпЫЙЗжВМЕФИХТЪУмЖШКЏЪ§ЁЃ
ЖдгкШЮвтФПБъЃЌМЦЫуУПвЛИіВЩбљЕуЕФJ(X)J(X)J(X)ЁЃДѓЕФJ(X)J(X)J(X)втЮЖзХXXXгыФПБъИќНќЁЃЕБвЛИіВЩбљЕуЭЌЪББЛЖрИіФПБъАќКЌЪБЃЌНЋJ(X)J(X)J(X)зюДѓЕФБъЧЉЗжХфИјВЩбљЕуЁЃвЛИіМђЕЅЕФФЃК§бљБОЗжХфШчЯТЭМЫљЪОЁЃ

Multi-level sampling
знКсБШДѓЕФФПБъЕФВЩбљЗЖЮЇжївЊЪмЖЬБпгАЯьЁЃШчЯТЭМЫљЪОЃЌЕБЬиеїЭМЕФВНГЄДѓгкЖЬБпЪБЃЌФПБъПЩФмгЩгкЬЋеЖјЮоЗЈгааЇВЩбљЁЃвђДЫЃЌеыЖдВЩбљВЛзуЮЪЬтЃЌзїепЬэМгСЫвЛИіМђЕЅЕФВЙГфЗНАИЃКЭЈЙ§БШНЯЖЬБпКЭВНГЄРДШЗЖЈЪЧЗёдкЕЭВуЬиеїжаЗжХфБъЧЉЁЃЗжХфБъЧЉвЊТњзувдЯТСНИіЬѕМўЃКЕквЛЃЌЖЬБпгыВНГЄжЎБШаЁгк2ЃЛЕкЖўЃЌФПБъзюаЁЭтНгОиаЮЕФГЄБпДѓгкЬиеїЭМЕФНгЪмЗЖЮЇЁЃ

ЖрМЖВЩбљ(Multi-Level Sampling, MLS)ВпТдЪЙЕУФмЙЛНЋвЛаЉЮоЗЈгааЇВЩбљЕФФПБъЬэМгЕНЕЭВуЬиеїжаЁЃЕЭВуЬиеїгЩИќУмМЏЕФВЩбљЕуЃЌДгЖјЛКНтСЫВЩбљВЛзуЮЪЬтЁЃ
Target loss
FCOSRЕФЫ№ЪЇАќКЌЗжРрЫ№ЪЇКЭЛиЙщЫ№ЪЇЁЃQuality Focal Loss(QFL)гУзїЗжРрЫ№ЪЇЃЌжївЊЪЧДгдЪМFCOSжавЦГ§СЫcenternessЗжжЇЁЃЛиЙщВЩгУProbIoU lossЁЃ
QFLЪЧGFL(General Focal Loss)ЕФвЛВПЗжЃЌЭЈЙ§гУground truthКЭдЄВтНсЙћМфЕФIoUЬцЛЛone-shotБъХфРДЭГвЛбЕСЗКЭВтЪдЙ§ГЬЁЃQFLвжжЦСЫЕЭжЪСПЕФдЄВтНсЙћЃЌЬсИпСЫФЃаЭадФмЁЃЯТЪНИјГіСЫQFLЕФЖЈвхЃК
QFL(Ів)=?ЈOy?ІвЈOІТ((1?y)log(1?Ів)+ylog(Ів))QFL(\sigma)=-|y-\sigma|^{\beta}((1-y){\rm{log}}(1-\sigma)+y{\rm{log}}(\sigma)) QFL(Ів)=?ЈOy?ІвЈOІТ((1?y)log(1?Ів)+ylog(Ів))
ЦфжаyyyБэЪОгУгкЬцЛЛЕФIoUЃЌВЮЪ§ІТ\betaІТЃЈНЈвщШД2ЃЉгУгкЦНЛЌПижЦНЕШЈТЪЁЃ
ProbIoU lossЪЧеыЖдOBBЩшМЦЕФвЛжжIoU lossЁЃЦфжївЊЭЈЙ§ЖўЮЌИпЫЙЗжВМжЎМфЕФОрРыРДБэЪОOBBжЎМфЕФIoUЃЌгыGWDКЭKLDЯрЫЦЁЃзмЫ№ЪЇЖЈвхШчЯТЃК
Loss=1NposІВzQFL+1ІВz1{cz?>0}IoU?ІВz1{cz?>0}IoU?LossProbIoULoss=\frac{1}{N_{pos}}\Sigma_{z}{QFL}+\frac{1}{\Sigma_{z}{
{\rm{1}}_{\{c_z^*>0\}}IoU}}\cdot{\Sigma_{z}{
{\rm{1}}_{\{c_z^*>0\}}IoU\cdot{Loss_{ProbIoU}}}} Loss=Npos?1?ІВz?QFL+ІВz?1{
cz??>0}?IoU1??ІВz?1{
cz??>0}?IoU?LossProbIoU?
ЦфжаNposN_{pos}Npos?БэЪОе§бљБОЪ§ЁЃзмЕФКЭЪЕдкЖрВуЬиеїЩЯЕФЫљгаЮЛжУzzzЩЯМЦЫуЕФ1{cz?>0}{\rm{1}}_{\{c_z^*>0\}}1{
cz??>0}?ЪЧжИЪОКЏЪ§ЃЌcz?>0c_z^*>0cz??>0ЮЊ1ЗёдђЮЊ0ЁЃ
Experiments
Datasets
- DOTA
БОЮФжазїепгУtrainКЭvalМЏбЕСЗЃЌtestМЏВтЪдЁЃЫљгаЭМЯёБЛВУГЩ1024ЁС10241024\times{1024}1024ЁС1024ЕФpatchesЃЌВНГЄЮЊ512ЁЃЖрГпЖШдіЧПЪБВЮЪ§DOTA1.0ЮЊ{0.5,1.0}\{0.5,1.0\}{ 0.5,1.0}ЃЌDOTA1.0ЮЊ{0.5,1.0,1.5}\{0.5,1.0,1.5\}{ 0.5,1.0,1.5}ЁЃЭЌЪБбЕСЗЪБвВВЩгУСЫrandom flippingЁЂrandom rotationдіЧПЁЃ
- HRSC2016
БОЮФжазїепгУtrainКЭvalМЏбЕСЗЃЌtestМЏВтЪдЁЃЫљгаЭМЯёЖМБЛЫѕЗХЮЊ800ЁС800800\times{800}800ЁС800ЃЌЭЌЪББЃГжзнКсБШЁЃЭЌЪБбЕСЗЪБвВВЩгУСЫrandom flippingЁЂrandom rotationдіЧПЁЃ
Implement Details
BackboneЮЊResNext50-FPNЁЃDOTAбЕСЗ36epochЃЌHRSC2016бЕСЗ40k iterationsЁЃВЩгУSGDгХЛЏЁЃDOTAГѕЪМбЇЯАТЪЮЊ0.01ЃЌдк{24,33}\{24,33\}{ 24,33}epochЪБЫЅМѕЮЊЪЎЗжжЎвЛЁЃHRSC2016ЕФГѕЪМбЇЯАТЪЮЊ0.001ЃЌдк{30k,36k}\{30k,36k\}{ 30k,36k}ЫЅМѕЁЃMomentumКЭweight decayЗжБ№ЮЊ0.9КЭ0.0001ЁЃБОЮФбЕСЗЪЙгУСЫNvidia DGX Station(4 V100 GPUs@32GB)ЃЌзмЕФbatch sizeЮЊ16ЃЌtestЪЙгУвЛеХ2080TiЁЃКЯВЂpatchЪБЕФуажЕЮЊ0.1ЃЌtestЪБЕФжУаХЖШуажЕЮЊ0.1ЁЃЪмrotation-equivariant CNNsЕФЦєЗЂЃЌБОЮФВЩгУСЫвЛжжаТЕФа§зЊдіЧПЗНЗЈЃКЗжСНВНЃЌЕквЛВНвдЕШИХТЪНЋЭМЯёЫцМДа§зЊ{0,90,180,270}\{0,90,180,270\}{ 0,90,180,270}НЧЖШЃЌЕкЖўВПдйвд50%ЕФИХТЪНЋЭМЯёЫцМДа§зЊ30Лђ60ЖШЁЃЛљгкmmdetectionЁЃ
Ablation Studies
БОЮФдкDOTA1.0ЩЯПЊеЙСЫвЛЯЕСаЕФЪЕбщвдЦРЙРЫљЬсГіЗНЗЈЕФгааЇадЁЃВЩгУResNext50ЕФФЃаЭБЛГЦЮЊFCOSR-MЁЃбЕСЗКЭВтЪдЖМдкsingle scaleЩЯЁЃ

ШчЩЯБэЫљЪОЃЌFCOS-MЕФbaselineЮЊ70.4% mAPЃЌЫцзХа§зЊдіЧПЕФЪЙгУЃЌmAPЬсИпСЫ4.03%ЁЃЕБЪЙгУQFLДњЬцFocal LossЪБЃЌадФмгжЬсИпСЫ0.91% mAPЁЃЕБЬэМгСЫECSКЭFLAФЃПщКѓЃЌmAPДяЕНСЫ76.80%ЁЃзюКѓЬэМгСЫMLSКѓЃЌDOTA1.0ЕФЕЅГпЖШадФмДяЕНСЫ77.15% mAPЁЃЭЈЙ§ЬэМгИїжжФЃПщЃЌFCOSR-MЪЕЯжСЫЗЧГЃЯджјЕФадФмЬсЩ§ЁЃетаЉФЃПщдкЭЦРэЙ§ГЬжаУЛгаШЮКЮЖюЭтЕФМЦЫуЃЌЪЙЕУFCOSRГЩЮЊвЛИіЗЧГЃМђЕЅЁЂПьЫйЧввзгкВПЪ№ЕФOBBМьВтЦїЁЃ
More Backbones
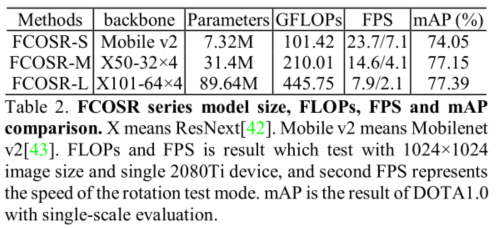
БОЮФгУЦфЫћВЛЭЌЕФbackbonesЬцДњResNext50РДжиаТЙЙНЈFCOSRЁЃВЩгУMobileNetv2ЕФГЩЮЊFCOSR-SЃЌВЩгУResNext101ЕФБЛГЦЮЊFCOSR-LЁЃЦфдкDOTAЩЯЕФФЃаЭГпДчЁЂFLOPsЁЂFPSвдМАmAPШчЯТБэЫљЪОЁЃ
ЮЊСЫЪЙFCOSRФмЙЛдкЧЖШыЪНЦНЬЈЩЯВПЪ№ЃЌзїепЖдЦфНјааСЫЧсСПЛЏДІРэЁЃдкFCOSR-SЕФЛљДЁЩЯЕїећСЫbackboneЕФЪфГіНзЖЮЃКНЋFPNЕФЖюЭтОэЛ§ВуЬцЛЛЮЊpoolingВуЃЌГЦжЎЮЊFCOSR-liteЁЃдкДЫЛљДЁЩЯЃЌзїепгжНЋheadЕФЬиеїЭЈЕРДг256НЕЕЭЕН128ЃЌВЂНЋЦфГЩЮЊFCOSR-tinyЁЃЩЯЪіСНИіФЃаЭБЛзЊЛЛЮЊСЫ16bit TensorRTИёЪНЃЌВЂдкNvidia Jetson Xavier NXЩЯНјааСЫtestЁЃНсЙћШчЯТБэЫљЪОЁЃЧсСПЛЏЕФFCOSRдкJetson Xavier NXЩЯДяЕНСЫЫйЖШКЭОЋЖШЕФЭъУРЦНКтЁЃFCOSR-tinyДяЕНСЫ73.93% mAPКЭ10.68FPSЁЃетЪЧдкБпдЕМЦЫуЩшБИЩЯВПЪ№ИпадФмOBBЕФГЩЙІГЂЪдЁЃ

Speed VS Accuracy
ВтЪдСЫFCOSRЯЕСаФЃаЭКЭЦфЫћвЛЯЕСажїСїФЃаЭ(R3Det, ReDet, S2ANet, Faster RCNN-O, Oriented RCNN, RetinaNet-O)ЕФinferenceЫйЖШЁЃЮЊСЫЗНБуЃЌгУOriented RCNNЕФFaster RCNN-OКЭRetinaNet-OЁЃ