随机森林算法
RandomForest
1.概念
随机森林算法把分类树组合成随机森林,即在变量(列)的使用和数据(行)的使用上进行随机化,生成很多分类树,再汇总分类树的结果。随机森林在运算量没有显著提高的前提下提高了预测精度。随机森林对多元共线性不敏感,结果对缺失数据和非平衡的数据比较稳健,可以很好地预测多达几千个解释变量的作用。
2.优缺点
RF的主要优点有:
1) 训练可以高度并行化,对于大数据时代的大样本训练速度有优势。
2) 由于可以随机选择决策树节点划分特征,这样在样本特征维度很高的时候,仍然能高效的训练模型。
3) 在训练后,可以给出各个特征对于输出的重要性
4) 由于采用了随机采样,训练出的模型的方差小,泛化能力强。
5) 相对于Boosting系列的Adaboost和GBDT, RF实现比较简单。
6) 对部分特征缺失不敏感。
7) 对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化
8) 在创建随机森林的时候,对generlization error使用的是无偏估计
9) 训练过程中,能够检测到feature间的互相影响
RF的主要缺点有:
1) 在某些噪音比较大的样本集上,RF模型容易陷入过拟合。
2) 取值划分比较多的特征容易对RF的决策产生更大的影响,从而影响拟合的模型的效果。
3.随机森林算法原理
1).每棵树的生成:①如果训练集大小为N,对于每棵树而言,随机且有放回地从训练集中的抽取N个训练样本(这种采样方式称为bootstrap sample方法),作为该树的训练集。从这里我们可以知道:每棵树的训练集都是不同的,而且里面包含重复的训练样本(理解这点很重要)。②如果每个样本的特征维度为M,指定一个常数m<
2).随机抽样训练集的目的:如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的,这样的话完全没有bagging的必要。
3).有放回地抽样的目的:如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是”有偏的”,每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决,这种表决应该是”求同”,因此使用完全不同的训练集来训练每棵树这样对最终分类结果是没有帮助的。
4).两个随机性的引入对随机森林的分类性能至关重要。由于它们的引入,使得随机森林不容易陷入过拟合,并且具有很好得抗噪能力。
5).随机森林分类效果(错误率)与两个因素有关:①森林中任意两棵树的相关性:相关性越大,错误率越大;②森林中每棵树的分类能力:每棵树的分类能力越强,整个森林的错误率越低。
6).减小特征选择个数m,树的相关性和分类能力也会相应的降低;增大m,两者也会随之增大。所以关键问题是如何选择最优的m(或者是范围),这也是随机森林唯一的一个参数。
4.袋外错误率(oob-error,out-of-bag error)
随机森林有一个重要的优点就是,没有必要对它进行交叉验证或者用一个独立的测试集来获得误差的一个无偏估计。它可以在内部进行评估,也就是说在生成的过程中就可以对误差建立一个无偏估计。在构建每棵树时,我们对训练集使用了不同的bootstrap sample(随机且有放回地抽取)。所以对于每棵树而言(假设对于第k棵树),大约有1/3的训练实例没有参与第k棵树的生成,它们称为第k棵树的oob样本。
oob估计计算方式:
1).对每个样本,计算它作为oob样本的树对它的分类情况(约1/3的树)
2).然后以简单多数投票作为该样本的分类结果
3).最后用误分个数占样本总数的比率作为随机森林的oob误分率
oob误分率是随机森林泛化误差的一个无偏估计,它的结果近似于需要大量计算的k折交叉验证。
5.应用举例
随机森林利用某一个人的年龄(Age)、性别(Gender)、教育情况(Highest Educational Qualification)、工作领域(Industry)以及住宅地(Residence)共5个字段来预测他的收入层次。
收入层次 :
Band 1 : Below $40,000
Band 2: $40,000 – 150,000
Band 3: More than $150,000
随机森林中每一棵树都可以看做是一棵CART(分类回归树),这里假设森林中有5棵CART树,总特征个数N=5,我们取m=1(这里假设每个CART树对应一个不同的特征)。
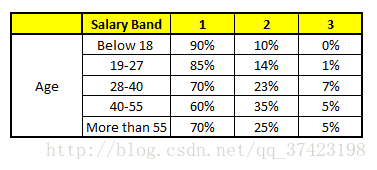
CART 1 : Variable Age
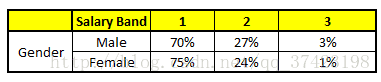
CART 2 : Variable Gender
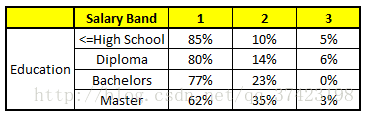
CART 3 : Variable Education
CART 4 : Variable Residence

CART 5 : Variable Industry
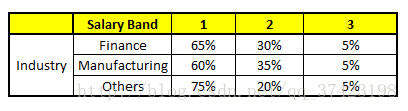
特征向量信息:1. Age : 35 years ; 2. Gender : Male ; 3. Highest Educational Qualification : Diploma holder; 4. Industry : Manufacturing; 5. Residence : Metro.
算法结果:
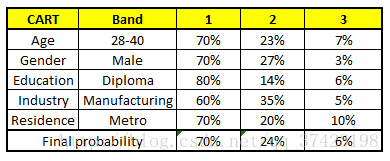
我们得出结论,这个人的收入层次70%是一等,大约24%为二等,6%为三等,所以最终认定该人属于一等收入层次(小于$40,000)。
5.通过sklearn来实现
数据集鸢尾花数据集
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import numpy as npiris = load_iris()df = pd.DataFrame(iris.data, columns=iris.feature_names)
拆分数据集,为训练集,测试集(按3:1的比例)
df['is_train'] = np.random.uniform(0, 1, len(df)) <=0.75
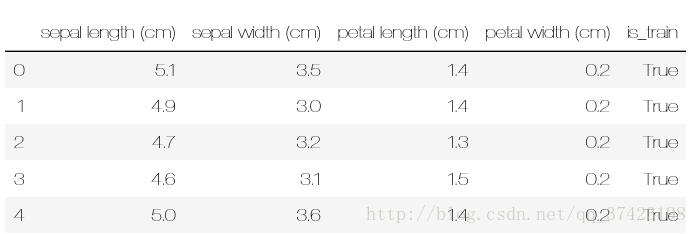
df.head()
演示操作
df['is_train'] = np.random.uniform(0, 1)
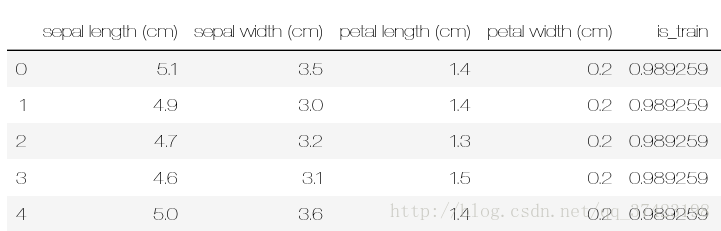
df['is_train'] = np.random.uniform(0, 1, len(df))

df['is_train'] = np.random.uniform(0, 1, len(df)) >= 0.9

pandas.Categorical.from_codes用法
根据数据来合成特征列
print iris.target
print iris.target_names
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 22 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 22 2]
['setosa' 'versicolor' 'virginica']
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
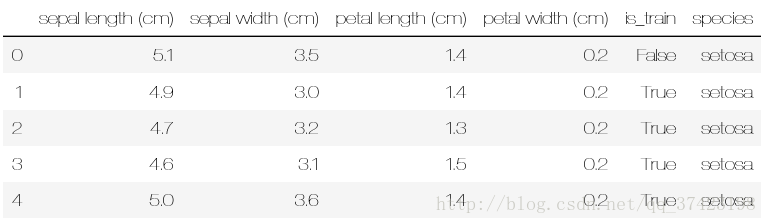
df.head()
train, test = df[df['is_train']==True], df[df['is_train']==False]
pandas.factorize()把文本标注的属性列还原特征化
features = df.columns[:4]
clf = RandomForestClassifier(n_jobs=2)
y, _ = pd.factorize(train['species'])
clf.fit(train[features], y)
pandas.crosstab()生成交叉列表
predict_result = iris.target_names[clf.predict(test[features])]pd.crosstab(test['species'], predict_result, rownames= ['actual'],colnames=['preds'])
分类结果:
